Empirical studies of neural network models for voice emotion recognition
Empirical studies of neural network models for voice emotion recognition
Abstract
This article is devoted to empirical research in the field of emotion recognition based on neural networks. The aim of the study is to conduct a comparative analysis of the performance indicators of various neural network models for solving the problem of emotion recognition in human speech. Fully connected neural networks (Deep Neural Network), Convolutional Neural Network and Recurrent Neural Network are studied. For each neural network, the same set of source data is defined, on which they are trained and demonstrate their ability to recognise different types of emotions. The results of the models and their accuracy are analysed using the following methods: feature correlation assessment, principal component analysis (PCA), stochastic neighbourhood embedding with t-distribution (t-SNE) and error matrices. Further prospects for research development are identified.
1. Введение
Современные технологии в области искусственного интеллекта и обработки речи достигли значительных успехов, что привело к разработке голосовых ассистентов. Распознавание эмоций по голосу — это динамично развивающаяся область, находящая широкое применение в различных прикладных задачах. Например, в статье «Распознавание эмоций по голосу: технологии и приложения» уточняется, что интеграция эмоционального анализа позволяет ассистентам адаптировать свои ответы в зависимости от настроения пользователя
. В маркетинге и анализе потребительского поведения компании используют технологии распознавания эмоций для оценки реакции клиентов на продукты или услуги . А медицинская диагностика по голосу позволяет выявлять психические расстройства на раннем этапе и выполнять мониторинг эмоционального благополучия . Распознавание эмоций в голосе может использоваться для выявления стрессовых или подозрительных состояний, что полезно в борьбе с телефонным мошенничеством .Исследования в области распознавания голосовых эмоций активно развиваются. Так, например, в России была создана библиотека Aniemore
, которая обучена распознавать семь эмоций человека по голосу и словам. Компания «Яндекс» представила нейросеть-эмпата , которая по голосу способна определять эмоциональное состояние пользователя.На международном уровне крупные технологические компании, такие как Apple и Amazon, инвестируют в развитие эмоционального искусственного интеллекта
. Apple приобрела компанию Emotient , специализирующуюся на распознавании эмоций. По расчётам специалистов, рынок распознавания эмоций ждёт большой скачок в ближайшем будущем .Но, несмотря на достигнутые успехи в данной сфере, существует немало проблем, которые требуют решения. Одна из основных проблем заключается в обширном разнообразии проявлений эмоций людьми, что усложняет создание универсальных моделей. Кроме того, есть множество факторов, например, языковых, которые также влияют на качество моделей.
Данная статья посвящена эмпирическим исследованиям различных моделей нейронных сетей, решающих задачу распознавания голосовых эмоций, и оценки их эффективности с использованием существующих наборов данных. В дальнейшем полученные результаты будут использованы для создания более эффективной модели, способной решить часть существующих проблем в данной области, что позволит расширить её применение в различных сферах человеческой деятельности.
2. Методы исследования
В рамках данного исследования были выбраны такие архитектуры нейронных сетей, как полносвязная нейронная сеть (DNN), нормализованная полносвязная нейронная сеть (NDNN), сверточная нейронная сеть (CNN) и рекуррентная нейронная сеть (RNN). Эти модели нейронных сетей представляют собой базовые и концептуально отличающиеся подходы к обработке данных: от простой линейной передачи информации до захвата пространственных и временных зависимостей. Такой выбор позволяет не только провести сопоставление эффективности разных принципов архитектур, но и заложить основу для дальнейшего анализа более сложных моделей. Кроме того, эти типы сетей хорошо изучены и широко применяются в задачах обработки сигналов и классификации, что делает их обоснованной отправной точкой для эмпирического сравнения
, , .В работе В.В. Киселёва показано, что эмоции в речи распознаются на основе анализа акустических и лингвистических характеристик, которые отражают состояние говорящего
. Следует отметить, что к акустическим характеристикам относятся тональность, громкость, темп и длительность речи, спектральные характеристики. А к лингвистическим характеристикам — лексика, синтаксис, интенсивные слова.Для глубокого понимания характеристик эмоциональной речи и улучшения моделей классификации применяются следующие методы анализа и оценки:
1. Оценка корреляции признаков используется для выявления взаимосвязей между различными характеристиками аудиосигнала. Построение корреляционной матрицы позволяет понять, как сильно связаны между собой признаки
.2. Матрица ошибок — это инструмент визуального анализа, позволяющий оценить, как модель классифицирует объекты каждого класса. В отличие от агрегированных метрик, таких как Precision, Recall и f1-score, матрица ошибок показывает конкретные направления ошибок, т.е. какие классы модель путает между собой
.3. Метод главных компонент (PCA) применяется для уменьшения размерности признаков, при этом сохраняя важные элементы информации, и позволяет выявить признаки, которые наиболее сильно влияют на различие между эмоциями
.4. t-SNE — это инструмент визуализации многомерных данных, который применяется для представления признаков в двумерной или трёхмерной проекции
.Для проведения данного исследования использовался датасет RAVDESS
, предназначенный для решения задач распознавания эмоций. Он состоит из аннотированных аудио- и видеофайлов, отражающих разные эмоциональные состояния человека. Для задачи классификации аудио по эмоциям используется часть датасета, содержащая записи речевых фраз.Ключевые особенности датасета: 1440 аудиофайлов, 24 актёра, 8 категорий эмоций (нейтральность (Neutral), спокойствие (Calm), счастье (Happy), грусть (Sad), гнев (Angry), страх (Fearful), отвращение (Disgust), удивление (Surprised)), два уровня интенсивности.
Для анализа эмоционального окраса речи часто рассматриваются и извлекаются следующие акустические характеристики:
- MFCC, представляющие спектральные особенности речи;
- Chroma, отражающие интонацию;
- Mel Spectrogram, представляющие собой энергораспределение по частотам;
- Spectral Contrast, представляющие различия в энергии между максимальными и минимальными точками спектра;
- Tonnetz, представляющие гармоническое содержание звука.
В процессе подготовки данных к обучению различные архитектуры нейронных сетей сопровождались разным уровнем предобработки. Так, для моделей NDNN, CNN и RNN применялась нормализация признаков методом Z-преобразования с использованием функции StandardScaler. Нормализация позволяет быстрее обучаться моделям и делает вклад каждого признака в обучение равномерным. Балансировка классов была реализована в модели RNN с помощью алгоритма SMOTE — метода синтетического увеличения количества примеров в тех классах, которых изначально меньше, что позволило компенсировать дисбаланс эмоций в датасете. В этой же модели использовалась аугментация аудиоданных: изменение скорости воспроизведения аудиоданных и высоты тона, что значительно увеличило объем обучающей выборки. Такой подход позволил улучшить обобщающую способность модели RNN путем получения эмоций в разных вариантах произношения. В базовой модели DNN предобработка ограничивалась только извлечением признаков без нормализации, балансировки и аугментации, что отражает её роль в исследовании как стартовой контрольной архитектуры.
Для каждой модели оптимальные значения гиперпараметров были определены экспериментальным путем. В таблице 1 представлены виды и гиперпараметры нейронных сетей.
Таблица 1 - Виды и гиперпараметры моделей нейронных сетей
Название | DNN | NDNN | CNN | RNN |
Вид нейронных сетей | Deep Neural Network | Normalized Deep Neural Network | Convolutional Neural Network | Recurrent Neural Network |
Функция активации | ReLU, Softmax | ReLU, Softmax | ReLU, Softmax | ReLU, Softmax |
Оптимизатор | Adam | RMSprop | Adam | Adam |
Нормализация | Нет | StandardScaler | StandardScaler | StandardScaler |
Балансировка классов | Нет | Нет | Нет | SMOTE |
Аугментация | Нет | Нет | Нет | Сдвиг времени, тональности |
Batch size | 4 | 16 | 64 | 32 |
Эпох | 200 | 200 | 180 | 50 |
Нейронов | 400, 200, 100 | 512, 256 | 32, 64, 128, 256, 512 | 64, 128 |
Коэффициент скорости обучения | 0,01 | 0,001 | 0,00095 | 0,001 |
Из таблицы видно, что для каждой из четырех созданных моделей нейронных сетей представлено количество нейронов на каждом скрытом слое, число скрытых слоев можно видеть по количеству нейронов в одном слое (так в первой модели — три скрытых слоя, во второй — 2, в третьей — 5, а в четвертой — 2).
3. Основные результаты
Проведен ряд вычислительных экспериментов по решению задачи классификации эмоций в речи человека с использованием четырех моделей нейронных сетей: DNN, NDNN, CNN, RNN.
На рисунке 1 представлены результаты классификации по каждой модели нейронной сети, точность которой определяется с использованием оценки корреляции признаков и представляется отчетом классификации.
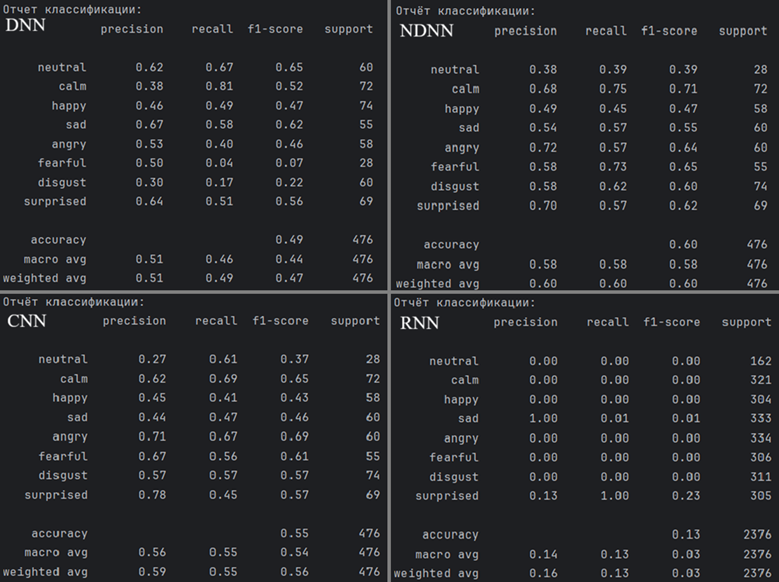
Рисунок 1 - Отчёты классификации для моделей DNN, NDNN, CNN, RNN
- Precision (точность) — доля правильных предсказаний среди всех, которые модель отнесла к определённой категории;
- Recall (полнота) — доля правильно угаданных эмоций среди всех случаев, где эта эмоция действительно присутствовала;
- f1-score — среднее значение между Precision и Recall, которое помогает оценить баланс между ними.
Из отчета классификации можно видеть, что:
- высокие значения метрики f1-score для эмоций нейтральности (0,65) и печали (0,62) для сети DNN; высокий Recall (0,81), но низкий Precision (0,38) для эмоции спокойствие для сети DNN;
- высокие значения метрики f1-score для эмоций спокойствие (0,71), гнев (0,64), страх (0,65), отвращение (0,60), удивление (0,62) для сети NDNN; высокие значения метрики Precision 0,68, 0,70, 0,72 наблюдаются для эмоций спокойствие, удивление, гнев соответственно, Высокие значения метрики Recall 0,62, 0,73, 0,75 определены для эмоций отвращение, страх, спокойствие соответственно;
- высокие значения метрики f1-score для эмоций страх, спокойствие и гнев, равные 0,61, 0,65, 0,69 соответственно для сети CNN, а метрика Precision имеет высокие значения метрики f1-score для эмоций высокое значение, равное 0,78, для эмоции удивление в модели CNN, но низкое значение Recall (0,45);
- модель RNN показала неудовлетворительные результаты классификации эмоций по всем метрикам.
На основе полученных в процессе экспериментов результатов построен график точности классификации эмоций для каждой модели нейронной сети, представленный на рисунке 2.
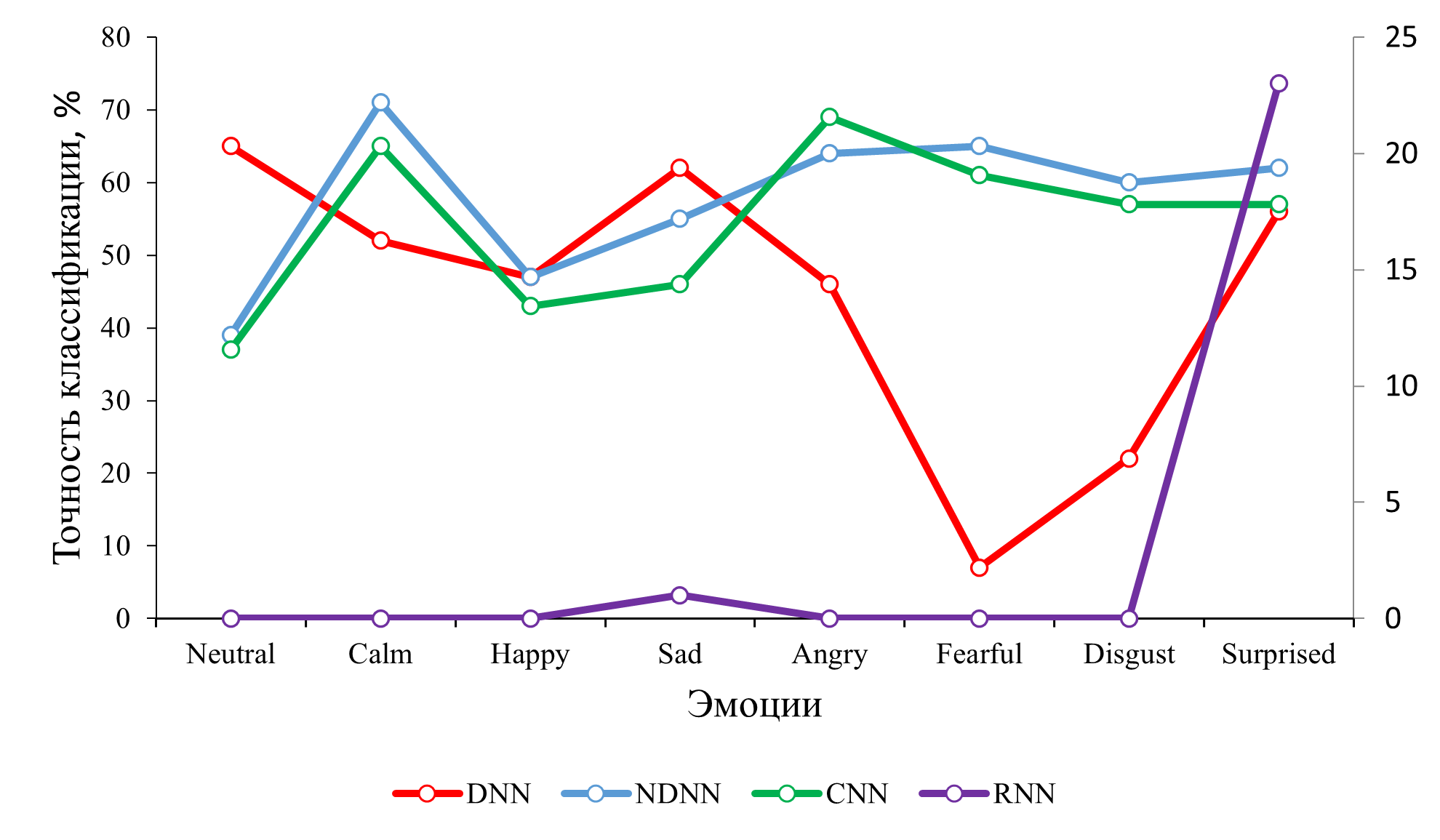
Рисунок 2 - График точности классификации эмоций
На рисунке 3 представлены матрицы ошибок по каждой модели нейронной сети. Значения на главной диагонали показывают верно распознанные эмоции. Если значение равно нулю, то эмоция не распознана. Наибольшая сумма значений главной диагонали характеризует модель нейронной сети, как наилучшую, а наименьшее значение — наихудшую. Наибольшее количество ошибок, которая могла допустить модель нейронной сети при классификации, определяется суммой значений, кроме значений главной диагонали.
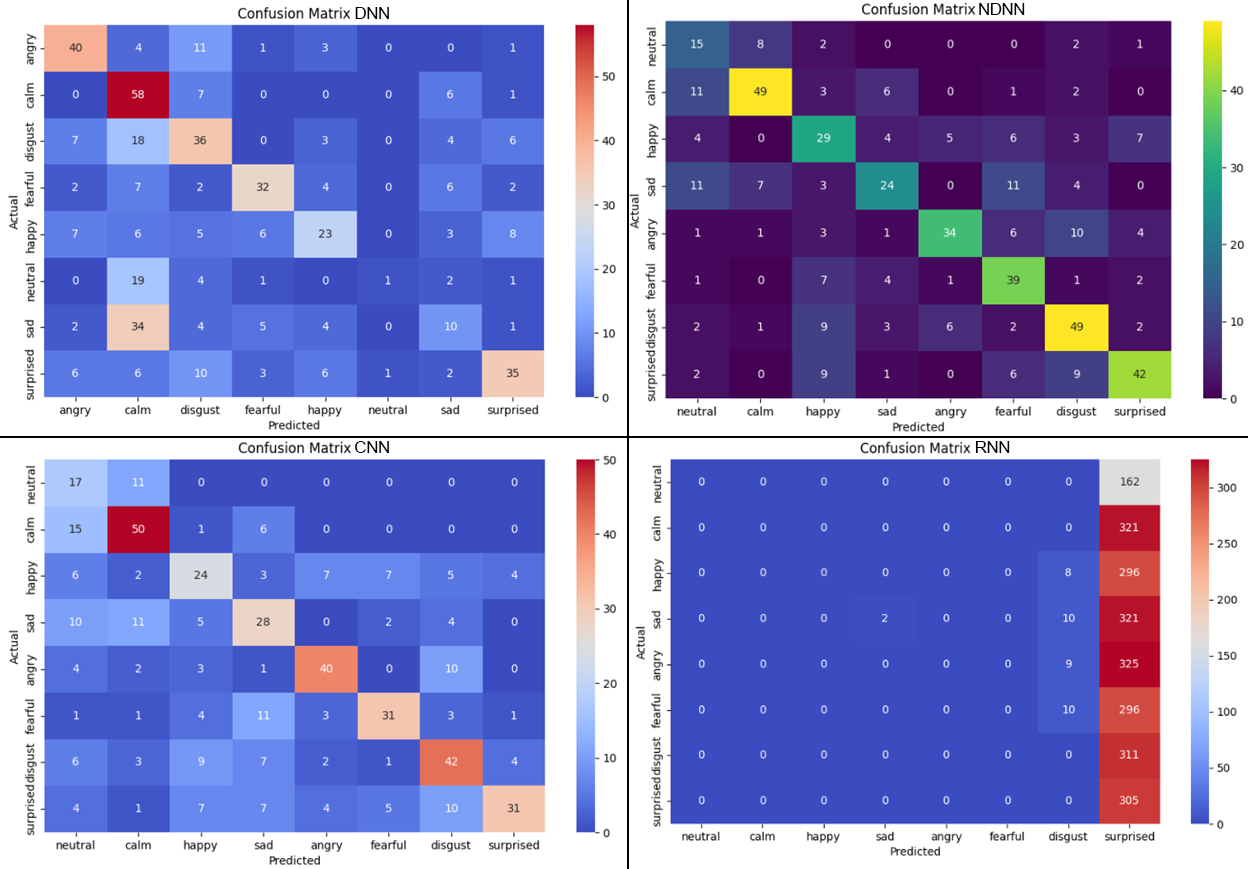
Рисунок 3 - Матрица ошибок для моделей DNN, NDNN, CNN, RNN
На рисунке 4 представлен PCA-анализ по каждой модели нейронной сети.
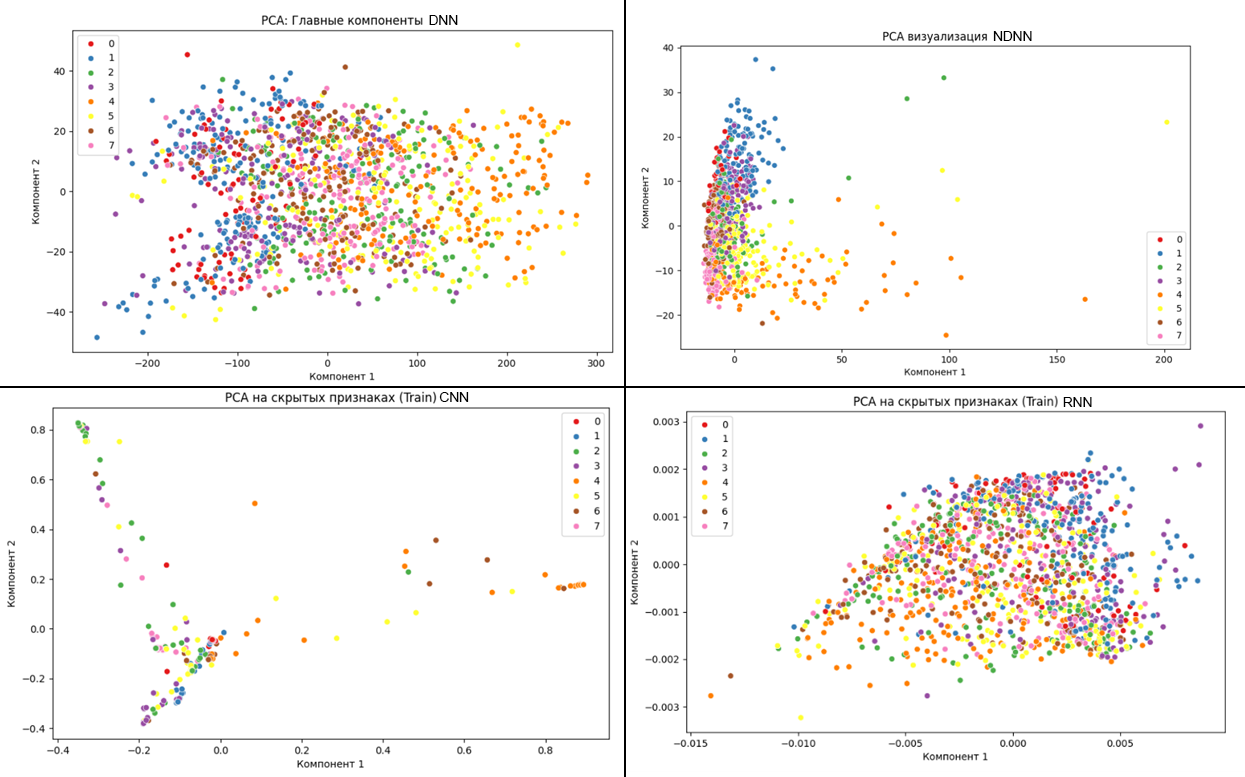
Рисунок 4 - PCA анализ для моделей DNN, NDNN, CNN, RNN
Полученные результаты с использованием метода PCA показывают, что главные признаки, извлекаемые из аудиофайлов недостаточно информативны для четкой классификации.
На рисунке 5 представлены t-SNE анализ по каждой модели нейронной сети.
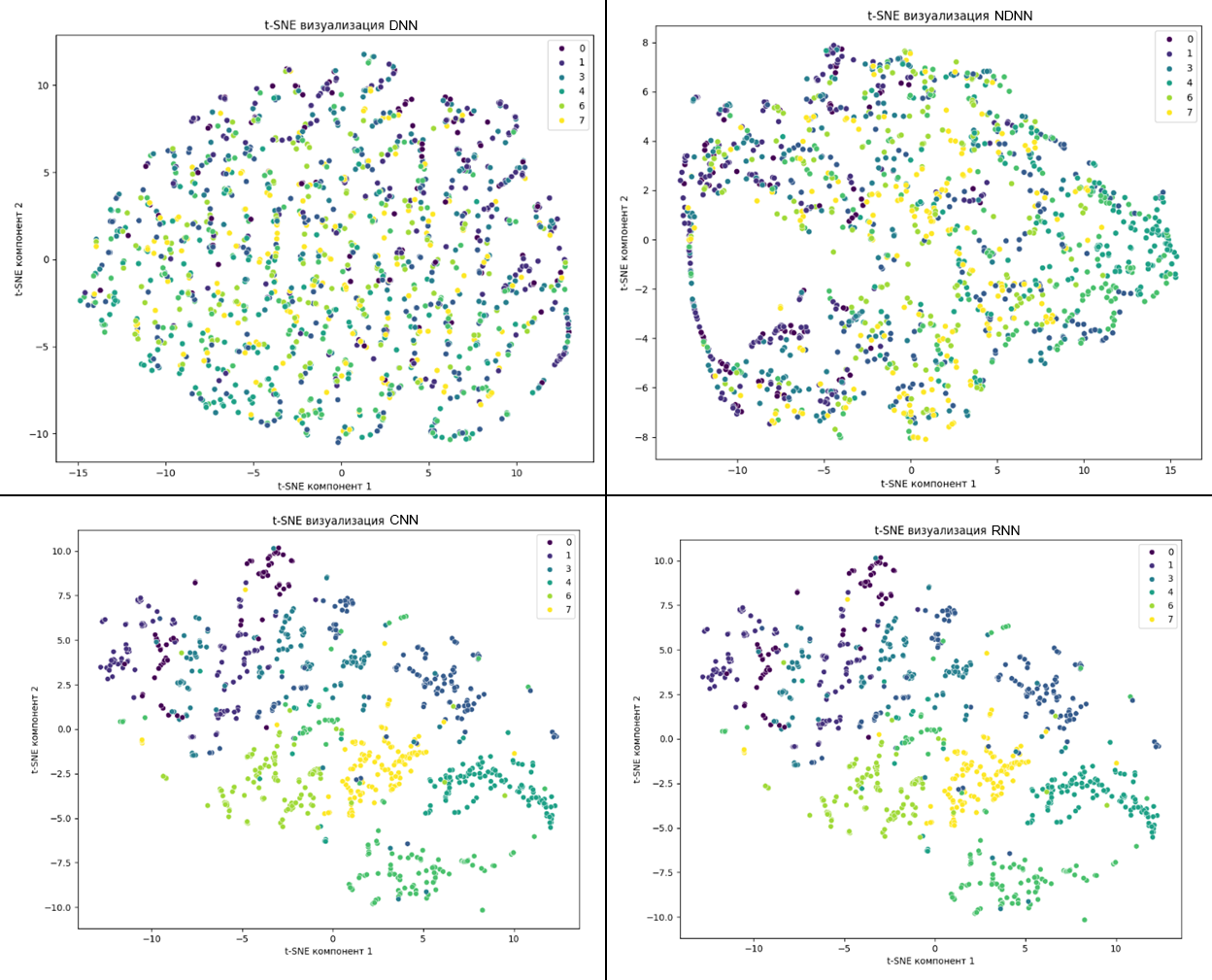
Рисунок 5 - t-SNE-анализ для моделей DNN, NDNN, CNN, RNN
На графиках t-SNE-анализа видно, что точность классификации признаков растет от модели DNN к модели CNN через NDNN, но резко падает в модели RNN. Таким образом, все модели кроме RNN демонстрируют точность классификации эмоций в речи человека от 47% до 71%, что можно считать приемлемым результатом.
4. Обсуждение
Данное исследование проводилось для предварительного анализа различных нейронных сетей для решения задачи распознавания эмоциональной окраски речи человека. Было рассмотрено четыре модели: DNN, NDNN, CNN, RNN. В работе был использован англоязычный датасет RAVDESS, содержащий 8 эмоций, семь из которых отражают ярко выраженную эмоцию, например, счастье, гнев, удивление и т.д., а один является нейтральным. Более того, использовалось два уровня интенсивности: аудиозаписи нормальной и повышенной громкости.
Оценка моделей определялась с помощью четырех методов. Так, отчет классификации является результатом реализации метода оценки корреляции (метод 1) и определяет точность классификации такими параметрами, как precision, recall, f1-score, а также параметром support, определяющий количество примеров для проверки точности.
Наилучший результат продемонстрировала модель NDNN для таких эмоций, как спокойствие, гнев, страх, отвращение, удивление со значениями 0,71, 0,64, 0,65, 0,60, 0,62 соответственно, Они представляют параметр f1-score, который является средним значением параметров precision и recall, Наихудший результат показала модель RNN, Результат по всем четырем моделям демонстрирует график на рисунке 2,
Модель CNN хорошо распознала эмоции гнева по сравнению с моделью NDNN (значение параметра f1-score 0,69 против 0,64) Это объясняется способностью свёрточных слоёв эффективно извлекать пространственные паттерны из спектральных признаков, Однако её результат был менее устойчивым по сравнению с NDNN в отношении эмоций спокойствия и страха.
Модель RNN показала крайне низкие значения параметра f1-score. Возможной причиной может быть сложность архитектуры и избыточное число эпох обучения. Такой вывод сделан на основе экспериментов, в которых точность модели возрастала при уменьшении количества скрытых слоев (т.е. упрощения топологии рекуррентной сети) и эпох обучения.
При анализе матрицы ошибок выявлено, что наибольшее число верно распознанных эмоций у модели NDNN (281) и CNN (269). А наибольшее число ошибок при распознавании эмоций было у моделей RNN (414) и DNN (235).
Матрицы ошибок подтверждают, что все модели испытывают трудности при распознавании схожих по акустическим признакам эмоций, таких как:
- нейтральность ↔ спокойствие;
- счастье ↔ удивление;
- страх ↔ отвращение;
- печаль ↔ нейтральность.
Это связано с тем, что эмоции перекликаются между собой по акустическим паттернам, что приводит к путанице у моделей. Также следует отметить, что отсутствие временного контекста снижает точность распознавания. И возможно, различный шумы, присутствующие в аудиозаписях, например, различия в интонации, мешают четкому распознаванию эмоций схожего спектра.
Визуализация данных с помощью методов PCA и t-SNE показала, что классы эмоций частично пересекаются в признаковом пространстве. Особенно это выражено у моделей DNN и RNN, где отчётливо прослеживаются проблемы с разделимостью классов. Модели NDNN и CNN продемонстрировали наиболее чёткую дифференциацию признаков, в особенности CNN.
По результатам анализа можно сделать вывод, что модели NDNN и CNN пригодны для задач распознавания эмоций. Модель RNN, в свою очередь, в данной конфигурации не может выполнить поставленную задачу. Модель DNN справляется с этой задачей, но не так эффективно, как модели NDNN и CNN.
5. Заключение
Данное исследование является основой для создания более эффективной модели для решения задачи распознавания голосовых эмоций. В дальнейших исследованиях необходимо:
- расширить текущий подход путём применения гибридных нейросетевых архитектур, объединяющих преимущества таких моделей, как NDNN и CNN;
- применить многомодальные системы, в которых аудиоданные дополняются визуальной информацией (например, выражением лица или движением губ)
, что позволит существенно повысить точность распознавания эмоций, особенно в сложных или неоднозначных случаях;- применить механизмы внимания и трансформерные архитектуры, которые позволят модели автоматически фокусироваться на наиболее значимых участках входных данных и будут эффективны в условиях сложной семантики и высокой изменчивости речи.
Таким образом, дальнейшее исследование в указанных направлениях может существенно улучшить качество классификации голосовых эмоций и расширить возможности использования подобных систем в реальных прикладных задачах.