CLASSIFICATION OF SCIENCE TEXTS FOR DEVELOPMENT THEMATIC SEARCH IN THE SPECIAL SYSTEMS

Олейников Б.В.1, Шалабай А.И.2
1Кандидат философских наук, доцент; 2аспирант, Сибирский федеральный университет
КЛАССИФИКАЦИЯ НАУЧНЫХ ТЕКСТОВ ДЛЯ РЕАЛИЗАЦИИ ТЕМАТИЧЕСКОГО ПОИСКА В СПЕЦИАЛИЗИРОВАННЫХ СИСТЕМАХ
Аннотация
В настоящей статье описан оригинальный алгоритм автоматической классификации научных текстов для задачи реализации тематического поиска и проведен анализ его точности. Основными его преимуществами являются скорость работы при хранении данных в SQL базе данных.
Ключевые слова: тематическая классификация текстов, УДК, алгоритм классификации, SQL
Oleynikov B.V.1, Shalabay A.I.2
1Candidate of philosophical sciences, 2postgraduate student, Syberian federal University
CLASSIFICATION OF SCIENCE TEXTS FOR DEVELOPMENT THEMATIC SEARCH IN THE SPECIAL SYSTEMS
Abstract
This article describes the original algorithm for automatic classification of scientific texts for develop the thematic search. Its main advantages are speed and the ability to store data in a SQL database. The analysis of the accuracy of the algorithm
Keywords: classification of scientific texts, UDC, algorithm of classification, SQL
Современные системы поиска информации в сети Интернет используют технологию полнотекстового поиска, определяя присутствие поисковой фразы в текстах документов, размещенных в открытом доступе. На практике, подобные системы не всегда предоставляют релевантные результаты поиска из-за огромного количества формально соответствующих поисковому запросу документов. Для повышения релевантности дополнительно необходимо внедрять технологию тематического поиска, другими словами осуществлять подбор литературы строго определенной области знаний.
В [1,2] описана концепция и разработка библиотечной Grid-системы, предназначенной для каталогизации научных и образовательных Интернет-ресурсов в частично автоматическом режиме и объединения этого каталога с ресурсами традиционных библиотек. При этом, одним из основных условий для создания подобного каталога является классификация цифровых документов. Его структура позволит осуществлять тематический поиск, указав в поисковом запросе код области знаний в соответствии с выбранным классификатором. В данной работе используется универсальный десятичный классификатор (УДК), но, в общем случае, может быть выбран любой с иерархической структурой.
Существует три основных подхода к классификации текстов:
- Ручная. При поступлении новых книг в библиотеку, сотрудники самостоятельно классифицируют каждый документ.
- Автоматическая, с использованием набора заранее созданных правил. Позволяет довольно точно классифицировать большинство текстов, но требует создания тысяч правил и их дальнейшего изменения грамотным специалистом.
- Автоматическая, с использованием обучающих алгоритмов. Для реализации необходимо создать обучающую выборку: вручную классифицировать относительно небольшое число текстов и использовать один из алгоритмов классификации. Данный подход, как правило, является менее точным и менее быстрым в работе, чем предыдущий. Его главным преимуществом является минимизация человеческих ресурсов для обслуживания системы классификации.
Для использования в указанной Grid-системе важнейшим требованием к классификатору является скорость его работы, даже в ущерб точности: процесс классификации должен происходить при каталогизации новых документов в режиме реального времени.
Для реализации возможности тематического поиска научных текстов можно значительно упростить задачу классификации. Предположим, что каждый научный текст содержит определенные термины, по которым можно сделать вывод о принадлежности информации к определенной тематике.
Для создания обучающей выборки, в каждый класс необходимо включать только термы tk ∈ (Dk \ M), где Dk - множество слов документа, включаемого в выборку, M - множество слов общей лексики, не являющиеся научными терминами. На практике возможно включение в M всех слов, присутствующих в нескольких произведениях классической художественной литературы (в которых практически отсутствуют научные термины).
Так как в дальнейших рассуждениях порядок слов и количество повторов каждого термина в документе не важны, будем считать эквивалентными понятия k-того документа и множества Dk.
Для первоначального формирования обучающей выборки достаточно выбрать несколько научных текстов разной тематики и присвоить им классификационный код. В дальнейшем, система будет обучаться двумя способами:
- При успешной автоматической классификации система добавляет встретившиеся в классифицированном документе неизвестные термины в соответствующий класс.
- В случае, если подходящий класс не найден, пользователю будет предложено самостоятельно выбрать код для документа из справочника, после чего произойдет создание нового класса и размещение в нем научных терминов
Основным требованием для алгоритма классификации, работающего в режиме реального времени является скорость работы, даже в ущерб точности распознавания тематики. Это связано с тем, что реализация тематического поиска подразумевает работу с большим количеством объемных текстов (сотни тысяч документов, в каждом из которых может содержаться несколько сотен терминов).
Исходя из вышеизложенного предлагается классифицировать документ следующим образом:
- При добавлении k-того документа неизвестной тематики сформировать для него множество Dk \ M, где Dk – множество слов k-того документа.
- Для каждого известного класса
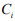 вычислить
вычислить 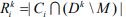 - количество слов научной тематики k-того документа, имеющих отношение к классу
- количество слов научной тематики k-того документа, имеющих отношение к классу 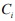 .
.
Очевидно, что чем больше значение 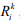 , тем больше терминов класса Ci содержится в k-том документе, а значит и вероятность принадлежности k-того документа к Ci выше. Подобная схема используется в линейном online-классификаторе [4], только вместо удаления слов общей лексики используются вектора весов терминов, содержащие информацию о значимости каждого термина для классификации. Причем, для формирования таких векторов (т.е. обучения алгоритма), следует воспользоваться информацией о правильности проведенной классификации (которой может и не быть).
, тем больше терминов класса Ci содержится в k-том документе, а значит и вероятность принадлежности k-того документа к Ci выше. Подобная схема используется в линейном online-классификаторе [4], только вместо удаления слов общей лексики используются вектора весов терминов, содержащие информацию о значимости каждого термина для классификации. Причем, для формирования таких векторов (т.е. обучения алгоритма), следует воспользоваться информацией о правильности проведенной классификации (которой может и не быть).
К сожалению, классификация документов подобным образом в некоторых случаях может быть ошибочна.
Пусть D1 и D2 – некоторые документы, а C1 и C2 некоторые классы. Рассмотрим два предельных случая при классификации документа только по величине Rik :
- Допустим, что D1 и D2 принадлежат классу C1, но |D1 ∩ C1| > |D2| и D2 ∩ C1 = D2 . В этом случае
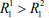 , а значит вероятность принадлежности документа D1 классу C1 выше. Однако, с другой стороны, так как всё множество слов документа D2 содержится в классе C1, вероятность принадлежности D2 к C1 должна быть максимальной.
, а значит вероятность принадлежности документа D1 классу C1 выше. Однако, с другой стороны, так как всё множество слов документа D2 содержится в классе C1, вероятность принадлежности D2 к C1 должна быть максимальной. - Допустим, что D1 принадлежит классу C1, но содержит в себе некоторое количество слов (терминов) из класса C2, то есть в документе присутствует множество терминов A ⊂ C2. В случае, если |A| > |C1| - документ будет классифицирован неправильно.
Ситуации, подобные второму предельному случаю, могут часто встречаться на практике, так как количество терминов, характеризующих ту или иную область знаний, может значительно отличаться. Особенно, ситуация усугубится при обучении системы путем автоматического добавления новых терминов в существующие классы, так как для разных областей знаний их число будет различным (литература различной тематики будет пользоваться неравной популярностью у пользователей). Поэтому предлагается ввести специальную корректирующую функцию
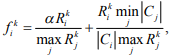
где 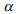 - некоторый коэффициент. Если
- некоторый коэффициент. Если 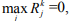 то k-тый документ классифицировать невозможно. Функция может принимать значения
то k-тый документ классифицировать невозможно. Функция может принимать значения 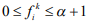 .
.
Данная функция f подобрана авторами экспериментально. Наглядно её действие продемонстрировано в Таб. 1.
Таблица 1 – значение функции f для различных .
|
Класс |
|Ci| |
Rik |
|
|
|
|
|
С1 |
10 |
5 |
0,5 |
0,63 |
0,78 |
1 |
|
С2 |
30 |
7 |
0,23 |
0,41 |
0,62 |
0,93 |
|
С3 |
20 |
10 |
0,5 |
0,75 |
1,05 |
1,5 |
|
С4 |
30 |
10 |
0,33 |
0,58 |
0,88 |
1,33 |
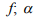 =0
=0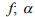 =0,25
=0,25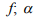 =0,5
=0,5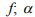 =1
=1Для дальнейшей работы примем =0,25; однако при практическом применении алгоритма коэффициент может принимать другое значение.
Для части документов правильность классификации может быть подтверждена специалистом, в этом случае встречающиеся в нем новые термины необходимо добавить в соответствующий класс.
Для реализации алгоритма предлагается использовать SQL базу данных, которая позволит:
- Хранить не только ключевые слова, но и дополнительные данные о литературе. Таким образом в одной базе можно сосредоточить всю информацию, необходимую для создания полноценной информационной системы.
- Производить с помощью штатных средств SQL быстрые соединения таблиц и при минимальных трудовых затратах получать в результатах поискового запроса все необходимые для классификации данные.
- Легко масштабировать систему хранения данных, выбирая СУБД в соответствии с реальными потребностями (зависит от числа классов, документов, рабочих мест пользователей): при реальном использовании словарь слов всех классов научной тематики может состоять из нескольких сотен тысяч записей (для литературы на разных языках), а количество книг может быть чрезвычайно большим.
Приведем простой пример практической реализации представленного алгоритма на основе использования SQL базы данных:
- Создается таблица Dict_words (code, name), содержащая
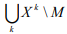 .
. - Создается таблица Dict_docs (code, name, author, class), каждая строка которой содержит библиографическую информацию отдельного документа.
- Создается таблица Link_words_docs(code_dict_words, code_dict_docs) содержащая записи, которые определяют принадлежность слов из Dict_words документу из Dict_docs.
Тогда запрос по конкретному k-тому документу, определяющий 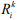 будет выглядеть следующим образом:
будет выглядеть следующим образом:
SELECT count(*) FROM
(SELECT * FROM LINK_WORDS_DOCS lwd1 INNER JOIN DICT_DOCS dd ON lwd.code_dict_docs = dd.code WHERE dd.class = Ci ) t1 INNER JOIN
(SELECT * FROM LINK_WORDS_DOCS lwd2 WHERE lwd2.code_dict_docs = d) t2 ON
t1.code_dict_words = t2.code_dict_words;
Главное преимущество рассматриваемого алгоритма заключается в том, что при подобной реализации возможно исключить использование более медленных соединений типа OUTER JOIN и тем самым значительно повысить скорость выполнения запроса: на стандартном офисном компьютере время выполнения такого запроса по базе данных с использованием таблицы LINK_WORDS_DOCS, содержащей 42 тысячи записей, составляет в среднем 0,045 секунды.
Пусть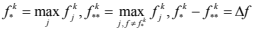 . Очевидно, что чем больше значение ∆f, тем выше вероятность правильности классификации. Следовательно, если при некотором ∆f считать, что классификация не удалась, то за счет сокращения общего числа классифицированных документов возможно повысить её точность.
. Очевидно, что чем больше значение ∆f, тем выше вероятность правильности классификации. Следовательно, если при некотором ∆f считать, что классификация не удалась, то за счет сокращения общего числа классифицированных документов возможно повысить её точность.
Для классификации текстов по кодам УДК предлагается воспользоваться следующей схемой иерархической классификации, показанной на Рис. 1, где N - текущий уровень УДК, Code - текущий код УДК, определенный классификатором, f() - функция автоматической классификации, возвращающая код класса, соответствующего документу Dk.
Следует пояснить, что классификация происходит только по кодам УДК (классам), которые являются дочерними для кода, определенного на предыдущем этапе.
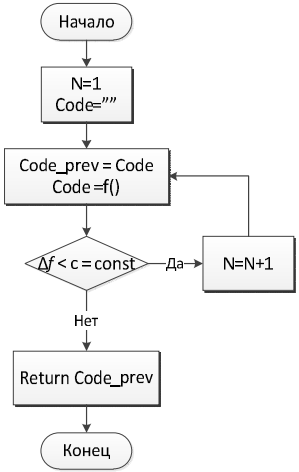
Рис. 1 - Алгоритм иерархической классификации.
Для оценки точности представленного алгоритма был проведен следующий эксперимент: для классификации использованы 200 научных статей из архивов электронных научных журналов («Наука и образование: Электронное научно-техническое издание» и «Политематический сетевой электронный научный журнал Кубанского аграрного университета») (Таб. 2). В качестве множества M использовался набор слов из произведений В.П. Астафьева («Царь-рыба», «Веселый солдат»), в результате количество слов в документах сократилось в среднем на 15%.
Таблица 2 - Точность классификации представленного алгоритма.
|
Уровень УДК |
Оценка по Rik |
Оценка по f |
|
1 |
84% |
93,5% |
|
2 |
67,5% |
76% |
|
3 |
42% |
52% |
Если при ∆f < 0,2 полагать, что документ не был классифицирован, то по первому уровню УДК точность классификации составит 100 %, но будет классифицировано всего 79% документов. Подбирать требуемое минимальное значение ∆f должен специалист, ответственный за классификацию литературы в соответствии с выбранным приоритетом (качества, либо количества). Для сравнения, согласно [3], точность известного метода PrTFIDF (в его иерархическом варианте) для тематической классификации составляет 72% для второго уровня иерархии, и 66% для конечного уровня иерархии.
Следовательно, можно заключить, что представленный оригинальный алгоритм целесообразно использовать для классификации по первому, либо второму уровню УДК. В случаях использования подобной SQL базы данных, представленный алгоритм значительно выигрывает в скорости. При другой организации системы хранения данных сопоставление результатов требует дополнительных исследований.
Если после осуществления классификации сформировать библиографические записи для цифровых документов в общепринятых форматах (например MARC, Mods и т.п.), появляется возможность интегрировать эти записи в каталоги традиционных библиотек (при заполнении и другой информации, в соответствии с библиотечными требованиями). Но, и без подобной интеграции, при использовании информации о тематике в поисковых системах, объединяя технологии полнотекстового и тематического поиска, возможно значительно повысить релевантность поисковых запросов.
References
Олейников Б.В., Шалабай А.И. К вопросу размещения открытых Интернет-ресурсов в классических библиотечных системах. XI международная ФАМЭБ’2012 конференция, С.:293–296.
Олейников Б.В., Шалабай А.И. Программное обеспечение для построения Грид-системы консолидации ресурсов традиционных библиотек и Интернетресурсов. XVI Международная ЭМ конференция по эвентологической математике и смежным вопросам.
Шелестов А.А., Дунаев Е.В. Автоматическая рубрикация web-страниц в интернет-каталоге с иерархической структурой. Интернет-математика 2005.
Ермакова Л.М. Методы классификации текстов и определения качества контента. Вестник Пермского университета, №3 (7), 2011, С.: 47-53.
References
Олейников Б.В., Шалабай А.И. К вопросу размещения открытых Интернет-ресурсов в классических библиотечных системах. XI международная ФАМЭБ’2012 конференция, С.:293–296.
Олейников Б.В., Шалабай А.И. Программное обеспечение для построения Грид-системы консолидации ресурсов традиционных библиотек и Интернетресурсов. XVI Международная ЭМ конференция по эвентологической математике и смежным вопросам.
Шелестов А.А., Дунаев Е.В. Автоматическая рубрикация web-страниц в интернет-каталоге с иерархической структурой. Интернет-математика 2005.
Ермакова Л.М. Методы классификации текстов и определения качества контента. Вестник Пермского университета, №3 (7), 2011, С.: 47-53.