A STUDY OF THE EFFECTIVENESS OF METHODS FOR CLASSIFYING EMOTIONAL STATES FROM FACIAL IMAGES BASED ON MANUAL FEATURES AND CONVOLUTIONAL NEURAL NETWORKS
A STUDY OF THE EFFECTIVENESS OF METHODS FOR CLASSIFYING EMOTIONAL STATES FROM FACIAL IMAGES BASED ON MANUAL FEATURES AND CONVOLUTIONAL NEURAL NETWORKS

Abstract
The work analyses the effectiveness of methods for classifying emotional states from facial images using manual features and convolutional neural networks. Traditional approaches based on descriptor extraction (LBP, HOG) are compared with modern deep learning methods. The aim of the study is to conduct a comparative analysis of classification quality when applying different methods and to identify the most effective approach for solving the problem of emotion recognition. A dataset of facial images annotated with emotional states was used as the experimental basis. The results were evaluated using classification quality metrics. It was found that models based on convolutional neural networks provide higher accuracy compared to methods based on manual features, but require greater computational resources. The feasibility of using hybrid or deep models to improve the performance of emotion recognition systems is demonstrated.
1. Введение
Задача автоматического распознавания эмоций по изображениям лиц остается актуальной для систем человеко-машинного взаимодействия, дистанционного обучения и медицинской диагностики , , . Потребность в таких системах возрастает с развитием интерфейсов, адаптивных образовательных платформ и инструментов психологической поддержки, где анализ мимики позволяет получать обратную связь о состоянии пользователя в реальном времени. Основные трудности связаны с вариативностью мимических проявлений, условиями освещения и шумами, а также дисбалансом классов в реальных данных , .
В настоящее время применяются два основных подхода: ручное извлечение признаков (LBP, HOG) с последующей классификацией и глубокое обучение, автоматически формирующее иерархические признаки. Классические методы отличаются низкими вычислительными затратами, но ограничены в обобщении , . Ряд современных работ указывает на преимущество CNN , , .
Цель работы — сравнительное экспериментальное исследование эффективности LBP+SVM, HOG+SVM и CNN на наборе FER2013 с учетом дисбаланса классов. Научная новизна заключается в сравнительном анализе устойчивости классических и нейросетевых методов к дисбалансу классов в условиях ограниченного разрешения изображений.
2. Материалы и методы
Экспериментальной базой послужил открытый набор данных FER2013 в стандартном разбиении: 28709 изображений для обучения, 3589 — для валидации, 3589 — для тестирования, все изображения в градациях серого размером 48x48 пикселей. Изображения отнесены к семи классам эмоциональных состояний: angry, disgust, fear, happy, neutral, sad, surprise. Распределение классов неравномерно, наиболее представлен класс «happy» (895 примеров в тестовой выборке), наименее — «disgust» (56 примеров). Подобная неравномерность распределения типична для реальных выборок и может приводить к смещению модели в сторону многочисленных классов , . Перед обучением все изображения были нормализованы в диапазон от 0 до 1. Дополнительная предобработка, такая, как выравнивание лиц по глазам или удаление фона не применялась, чтобы сохранить соответствие реальным условиям работы системы, где такие операции не всегда возможны.
В исследовании реализованы три подхода к классификации. Первый подход использует извлечение локальных бинарных шаблонов (LBP), для каждого изображения строилась гистограмма LBP-признаков, которая затем подавалась на вход классификатора опорных векторов (SVM) с линейным ядром. Линейное ядро было выбрано из соображений интерпретируемости и меньшей склонности к переобучению на признаках небольшой размерности. Второй метод использует признаки ориентированных градиентов (HOG): вычислялся вектор HOG-дескриптора, после чего выполнялась классификация линейным SVM. Оба подхода относятся к классическим методам компьютерного зрения и отличаются вычислительной эффективностью, но имеют ограничения при анализе сложных мимических выражений. Аугментация для классических методов не применялась, так как они работают на фиксированных дескрипторах.
Третий подход представлен сверточной нейронной сетью (CNN), обучаемая непосредственно на исходных изображениях. Архитектура используемой сверточной нейронной сети представлена на рисунке 1. Сеть принимает на вход изображения размером 48x48x1 и состоит из трех последовательных сверточных блоков. Первый блок включает два сверточных слоя с 32 фильтрами размером 3x3 (padding="same", шаг свертки 1), каждый из которых сопровождается функцией активации ReLU, после первого сверточного слоя идет пакетная нормализации, завершающий этап блока — применение слоя подвыборки MaxPooling (2x2) и Dropout с вероятностью 0,25. Второй блок имеет аналогичную структуру, но с увеличением числа фильтров до 64 и Dropout 0,25. Третий блок содержит 128 фильтров и Dropout 0,3. После сверточных блоков используется слой глобального усредняющего объединения (GlobalAveragePooling2D), далее полносвязный слой из 256 нейронов с функцией активации ReLU и Dropout 0,5. Выходной слой реализован с использованием функции softmax и содержит 7 нейронов, соответствующих числу классов. Выбор архитектурных параметров обусловлен особенностями решаемой задачи.
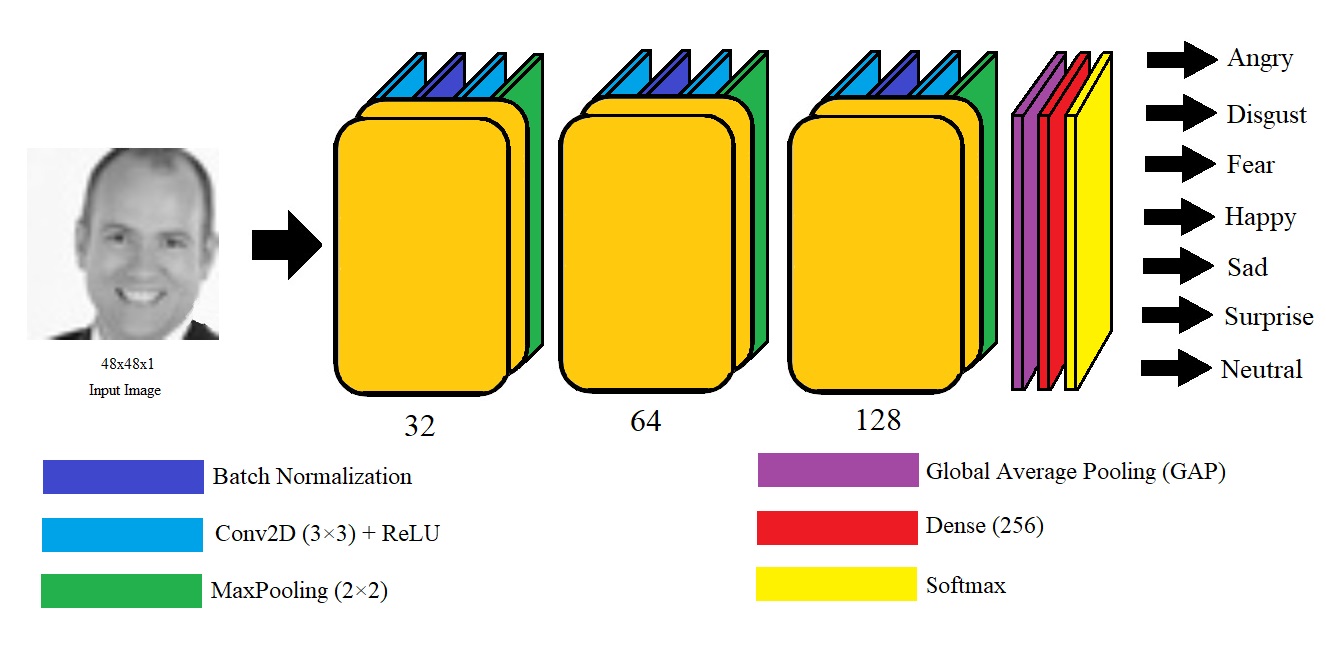
Рисунок 1 - Архитектура сверточной нейронной сети
3. Результаты и обсуждение
LBP+SVM показал точность 0,25. Наибольшее число ошибок наблюдается между эмоциями fear, sad и neutral из-за сходства текстур. Применение HOG+SVM позволило увеличить точность до 0,44 за счет учета геометрии лица, но сохранил чувствительность к дисбалансу и ошибки между визуально схожими классами. Модель CNN была обучена дважды на одной архитектуре, без использования весовых коэффициентов точность составила 0,5453, применение весовых классов увеличило точность до 0,6077. Лучшие показатели — для happy (precision=0,83) и surprise (0,72), самые низкие — для disgust (recall=0,52) из-за малого числа примеров. Fear, sad и neutral частично смешиваются из-за перекрытия признаков. Это указывает на то, что часть ошибок обусловлена не только ограничениями модели, но и объективной близостью визуальных проявлений данных эмоциональных состояний. Применение весов классов повысило recall для редких классов. Результаты сравнительного анализа методов распознавания эмоций представлены в таблице 1.
Сравнение точности классификации различных методов
значения метрик приведены в долях от 1
Метод | Признаки | Accuracy, доли | Precision (macro), доли | Recall (macro), доли | F1-score (macro), доли |
SVM | LBP | 0,25 | 0,1418 | 0,1452 | 0,0647 |
SVM | HOG | 0,44 | 0,3923 | 0,3888 | 0,3830 |
CNN | Автоматически извлекаемые | 0,6077 | 0,5566 | 0,6152 | 0,5677 |
Результаты для метода LBP+SVM характеризуются крайне низкими значениями F1-score (0,0647), что связано с выраженным смещением модели в сторону наиболее представленного класса (happy). Это указывает на высокую чувствительность метода к дисбалансу классов и ограниченную способность LBP-признаков описывать сложную мимику. В противовес, HOG+SVM демонстрирует более сбалансированные значения метрик (F1-score = 0,3830), что объясняется учетом пространственной структуры изображения. Прирост accuracy от HOG к CNN составляет более 16%, что свидетельствует о более высокой эффективности автоматического извлечения признаков. Полученные значения соответствуют диапазону 55–65%, указанным в обзоре Li и Deng . Классические методы LBP и HOG, несмотря на свою интерпретируемость, уступают нейросетевым из-за неспособности моделировать сложные нелинейные зависимости в мимике.
Проблема дисбаланса классов сохраняет существенное влияние: recall для класса disgust почти на 30% ниже, чем для happy. Применение весовых коэффициентов смягчило, но не устранило полностью этот эффект. Дополнительный анализ показал, что даже после балансировки модель часто путает disgust с fear и angry, что может быть связано с анатомическим сходством отдельных мимических паттернов. Ограничение достигнутой точности CNN может быть связано с низким пространственным разрешением изображений (48×48 пикселей), что приводит к потере мелких мимических деталей, критичных для различения сходных эмоциональных состояний. Дополнительным ограничением является использование датасета FER2013, содержащего изображения низкого качества и шумные метки, что может ограничивать верхнюю границу достигаемой точности моделей. С практической точки зрения, даже 60% точности может быть достаточно для некоторых приложений, но для индивидуальной диагностики требуется дальнейшее повышение надёжности. Перспективными направлениями являются генеративные методы дообучения (синтез редких классов) и использование метрического обучения для улучшения разделения визуально сходных эмоций (fear, sad, neutral). Также многообещающим выглядит применение трансформеров для анализа мимики и интеграция с видео-последовательностями, где доступна временная динамика выражений.
4. Заключение
В рамках работы выполнено экспериментальное исследование трёх подходов к классификации эмоций по лицам. Классические методы (LBP, HOG) обеспечивают базовый уровень точности (0,25-0,44), но их эффективность ограничена при сложной мимике и дисбалансе данных. Сверточная нейронная сеть с аугментацией и весами классов достигла accuracy 0,6077, что указывает на целесообразность применения глубокого обучения для данной задачи. Результаты сопоставимы с современными работами , , , . Перспективными направлениями являются разработка более сложных стратегий балансировки выборки и архитектурных модификаций CNN.