DL- RFR MODEL FOR FINANCIAL MANAGEMENT OF EXCHANGE ASSETS SIM3 ON MOEX
DL- RFR MODEL FOR FINANCIAL MANAGEMENT OF EXCHANGE ASSETS SIM3 ON MOEX
Abstract
The article presents an algorithm for managing an exchange asset – a futures contract for the SiM3 dollar on the Moscow Exchange (MoEx). The algorithm is based on the Random Forest Regression (DL RFR) deep learning model. The developed DL-model makes it possible to obtain a forecast of the closing price of a futures contract for the next timeframe – an hour, which makes it possible to provide support for making a management decision regarding the purchase / sale of an exchange asset SiM3. The scientific novelty of the study lies in the fact that high prediction accuracy is achieved through a combination of hyperparameter settings: the number of decision trees in the "random forest" ensemble, the depth of the decision trees, the method for assessing the quality of the model result (MAE, MSE, RMSD).
1. Введение
Проблема совершенствования подходов в использовании цифровых решений в сфере финансового менеджмента приводит к необходимости применения моделей торговых советников (rob-эдвайзеров), биржевых роботов. Повышение точности прогнозирования остается актуальной проблемой, несмотря на широкомасштабное применение алгоритмической торговли в мире и на Московской бирже, в частности.
Научная новизна состоит в том, что в отличие от большинства алгоритмов, применяемых систем искусственного интеллекта, авторами предложено использование модели глубокого обучения «Случайный лес» в качестве биржевого торгового эдвайзера.
Как известно «Случайным лесом» называется метод ансамблевого обучения, который способен выполнять
1) классификацию,
2) регрессию с помощью ансамбля деревьев решений.
Известно, что если агрегируются прогнозы группы предикторов (классификаторы, регрессоры), то частым результатом будет получение лучших прогнозов, нежели с индивидуальным предиктором. Группа предикторов называется ансамблем; таким образом, этот метод называется ансамблевым обучением. К преимуществу «Случайного леса» относят тот факт, что он имеет меньшую ошибку обобщения, чем одиночные деревья решений, из-за его случайности, которая уменьшает дисперсию модели .
По мнению ряда экспертов, существует определенная связь между алгоритмической торговлей, активностью частных инвесторов на бирже и стабильностью развития финансового сектора экономики. Проблемы, связанные с финансовой стабильностью, были предметом изучения значительного количества западных ученых. Среди них: Джон Чант. Эндрю Крокет, Внм Дуйзенберг, Роджер Фергюсон, Майкл Фут, Сэр Эндрю Лардж, Фредерик Мишкин. Гарри Шинаси и другие.
По мнению ученых Хенгхи (Hengxu), Донг (Dong), Вейквинг (Weiqing) и Джиан (Jiang), нет единой концепции финансовой стабильности ни в российской, ни в зарубежной науке .
Представляется целесообразным для эффективной спекулятивной торговли использовать такой математический аппарат, как случайный лес, важнейшим элементом которого является дерево решений. Деревья решений (DT) основаны на непараметрическом методе обучения с учителем, который используется для классификации и регрессии.
Целью метода является создание модели, предсказывающей значение целевой переменной на основе изучения простых правил принятия решений, которые выводятся из характеристик данных. Дерево можно рассматривать как кусочно-постоянную аппроксимацию. Чем глубже дерево, тем сложнее правила принятия решений и тем точнее модель. Деревья решений используются как для задач классификации, так и для задач регрессии. Понимание важности переменных в лесах случайных деревьев представлено во многих работах, в том числе Louppe G. и других .
Среди современных трендов применения систем искусственного следует отметить следующие тренды. Ритеш Кумар Дубей (Ritesh Kumar Dubey) c коллегами изучая вопросы эффективности алгоритмической торговли и ее влияние на качество рынка, пришел к выводу, что алгоритмическая торговля (АТ) была презираема розничными трейдерами и регуляторами рынка за ее скорость, поскольку приводит к непреднамеренной волатильности .
Автор Мэтью Ф. Диксон (Matthew F. Dixon) с коллегами ввели фундаментальные концепции машинного обучения для канонического моделирования и рамок принятия решений в области финансов. Представили примеры, упражнения и коды Python для закрепления теоретических концепций и демонстрации применения машинного обучения к алгоритмической торговле, управлению инвестициями, управлению капиталом и управлению рисками .
Любопытным направлением выступает управление таким инвестиционным активом, как NFT. Аббревиатура NFT образована от английского «non-fungible token», что в переводе означает «невзаимозаменяемый токен». По мнению Трубчаниновой К.А. и Коноваловой М.Е., он представляет собой особый вид криптографической учетного сертификата (токена), который является уникальным и не может быть уничтожен, обменен или замещен другим токеном .
Колоссальные изменения наблюдаются в финансовой сфере, что, по мнению Ванцовской А.А., главным образом, связано с появлением технологии блокчейн и криптовалюты, поскольку эти технологии, помимо того, что открывают новые возможности для инвестирования, кардинально трансформируют разного рода договорные отношения
.Исследованию роли систем управления инвестициями при соблюдении нормативных требований, в частности, исследование механизмов вытеснения после финансового кризиса посвятил свои труды Даниэль Гозман (Daniel Gozman) с коллегами .
2. Методы и принципы исследования
В работе использованы такие методы исследования, как теоретический, аналитический, статистический и система искусственного интеллекта на основе глубокого обучения «метод случайного леса».
Метод случайного леса (англ. random forest) – алгоритм машинного обучения, предложенный Лео Брейманом (Breiman Leo) и Адель Катлер (Adele Cutler) , суть которого заключается в использовании ансамбля решающих деревьев. Алгоритм позволяет сочетать в себе два основных подхода: метод бэггинга, предложенный Брейманом и метод случайных подпространств, который был предложен Тин Кам Хо (Tin Kam Ho) . Алгоритм применяется для задач классификации, регрессии и кластеризации. Основная идея заключается в использовании большого ансамбля решающих деревьев . Формирование DL-модели «случайный лес» производилось в «облаке» сервиса Collab на языке Python .
3. Основные результаты
В результате проведенного исследования:
1) сформирована DL-модель «случайный лес»;
2) получены прогнозные значения Pc;
3) исследована точность прогнозирования DL-модель «случайный лес» и качество работы модели;
4) выявлены определенные величины гиперпараметров при настройке DL-модели, которые обеспечивают наименьшие ошибки при прогнозировании цены закрытия (Pc) фьючерса SiM3 на следующий таймфрейм;
5) рассчитана средняя доходность при использовании сигналов модели для поддержки принятия управленческих решений инвестора при проведении спекулятивных операций с фьючерсом SiM3.
Во-первых, DL-модель «случайный лес» была успешно сформирована.
Датасет DL-модели «случайный лес» был получен путем экспорта свечей из торгового терминала QUIK (таблица 1).
Таблица 1 - Датасет DL-модели «случайный лес»
Дата | Время | Цена открытия | Максимальная цена | Минимальная цена | Цена закрытия | Объем |
20230407 | 230000 | 80919 | 81016 | 80919 | 80970 | 6057 |
20230407 | 220000 | 80856 | 80939 | 80838 | 80930 | 6154 |
20230407 | 210000 | 80893 | 80945 | 80847 | 80855 | 6460 |
20230407 | 200000 | 80931 | 80944 | 80833 | 80894 | 13079 |
20230407 | 190000 | 81048 | 81097 | 80932 | 80932 | 14068 |
20230407 | 180000 | 81080 | 81219 | 80951 | 80991 | 43826 |
20230407 | 170000 | 80984 | 81200 | 80801 | 81083 | 98025 |
Примечание: авторская разработка
Для формирования датасета была добавлена колонка «Target» – в которой представлена цена закрытия «close» на следующий тайм-фрейм. Опустим колонку «target» на 1 таймфрейм вниз, чтобы предсказательная цена получилась из последующей (t+1) «Close», заполним появившийся пропук, удалим не полную последнюю строку. Target = цена закрытия на завтра (close на следующий день)
Было сформировано обучающее X-множество и целевое у-множество, проведено обучение модели с использованием библиотеки DecisionTreeRegressor (рисунок 1).

Рисунок 1 - Скрипт для формирования обучающего «X», целевого «у»-множества и обучение модели
Примечание: авторская разработка
Рисунок 2 - Визуализация «решающего дерева» DL-модели, имеющего 28 уровней
Примечание: авторская разработка
В результате использования DL-модели были сформированы прогнозы на тестовом наборе (таблица 2).
Таблица 2 - Прогнозы, сформированные на тестовом наборе
№ | Actual | Predicted | Delta |
1884 | 60408,0 | 60330,0 | 78,0 |
1389 | 62080,0 | 61816,0 | 264,0 |
639 | 71114,0 | 71118,0 | -4,0 |
965 | 72035,0 | 71932,0 | 103,0 |
1816 | 61182,0 | 61159,0 | 23,0 |
Примечание: авторская разработка
В-третьих, исследована точность прогнозирования DL-модели «случайный лес» и качество ее работы с помощью метрик.
Гистограмма распределения величин параметра «Дельта», рассчитанного как разность между фактическим значением цены «Actual» и прогнозным – «Predicted» показывает, что в более чем 250 случаях из 424 отклонение (ошибка прогноза) составляет от 0 до 500 рублей (рисунок 3).
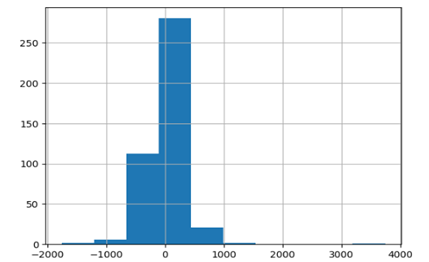
Рисунок 3 - Гистограмма распределения величин параметра «Дельта»
Примечание: авторская разработка
Оценка алгоритма регрессии обычно используются метрики: средняя абсолютная ошибка, среднеквадратичная ошибка и среднеквадратичная ошибка. Библиотека Scikit-Learn содержит функции, которые могут помочь нам вычислить эти значения.
MAE – метрика, которая сообщает нам среднюю абсолютную разницу между прогнозируемыми значениями и фактическими значениями в наборе данных.
Где: Σ – это символ, который означает «сумма»;
- наблюдаемое значение для i -го наблюдения;
- прогнозируемое значение для i -го наблюдения;
n – размер выборки.
Чем ниже MAE, тем лучше модель соответствует набору данных.
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости. MSE рассчитывается по формуле:
Где: n – количество наблюдений по которым строится модель и количество прогнозов,
- фактические значение зависимой переменной для i-го наблюдения,
- значение зависимой переменной, предсказанное моделью.
Среднеквадратичное отклонение (RMSD) или среднеквадратичная ошибка (RMSE) иначе R2 является часто используемой мерой различий между значениями (значениями выборки или совокупности), предсказанными моделью, и наблюдаемыми значениями. RMSD представляет собой квадратный корень из второго момента выборки различий между прогнозируемыми значениями и наблюдаемыми значениями. Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE: (3)
В-четвертых, выявлены определенные величины гиперпараметров при настройке DL-модели, которые обеспечивают наименьшие ошибки при прогнозировании цены закрытия (Pc) фьючерса SiM3 на следующий таймфрейм.
Анализ данных позволяет сделать вывод о высокой точности прогноза, поскольку уровень средней абсолютной ошибки модели не превышает значения 133,52 руб., а уровень MSE при этом составляет 1729,27, при этом RMSE = 41,58 для варианта в котором доля тестовой выборки в датасете составляла 0,20 (таблица 3).
Таблица 3 - Результаты оценки качества модели
| Доля тестовой выборки в датасете, 0,30 | Доля тестовой выборки в датасете, 0,20 |
Параметры качества модели | MAE = 182,6344 MSE = 76864,8 RMSE = 277,24 | MAE = 133,52 MSE = 1729,27 RMSE = 41,58 |
Примечание: авторская разработка
Использование библиотеки GridSearchCV позволило выбрать DL-модель с лучшими параметрами: {'criterion': 'squared_error', 'max_depth': 10, 'n_estimators': 50}. То есть по критерию «'squared_error», с глубиной «'max_depth'» = 10, с количством решающих деревьев - 50.
В-пятых, рассчитана доходность инвестора при использовании сигналов DL-модели для поддержки принятия управленческих решений при проведении спекулятивных операций с одним фьючерсным контрактом SiM3 (таблица 4).
Таблица 4 - Доходность инвестора при использовании сигналов DL-модели
Data | Pactual | Ppredicted
| Delta | Order |
06.04.23 11:00 | 80343 | 80364,610 | 21,61 | Long |
06.04.23 12:00 | 80860 | 80876,302 | 16,3 | Long |
06.04.23 13:00 | 80989 | 80876,302 | 112,7 | Short |
06.04.23 14:00 | 80989 | 80876,302 | 112,7 | Short |
… | … | … | … | … |
min | 57300,00 | 57689,00 | -2893,00 | - |
max | 80447,00 | 80447,00 | 1211,00 | - |
mean | 67918,09 | 67917,73 | 0,36 | - |
std | 6226,98 | 6237,63 | 332,93 | - |
N=424 | - | - | 141162,32 | - |
Примечание: авторская разработка
Как показывают исследования, за рассматриваемый период с 16 сентября 2022 г. 15:00 по 07 апреля 2023 г. 23:00 имели место 2124 наблюдений (часовых таймфреймов). Количество наблюдений, вошедших в тестовую выборки составило 424, при этом средняя величина Pactual составила 67918.09 рублей, а Ppredicted составила 67917,73 рублей. Поскольку известно, что среднеквадратическое значение параметра «Delta» – профита инвестора, то при общем количестве наблюдений N=424, расчетное значение совокупного профита составляет 141162,32 рублей = 424*332,93.
4. Обсуждение
Анализируя тенденции развития искусственного интеллекта в сфере финансового менеджмента, важно отметить некоторые аспекты, выявленные зарубежными учеными. Практика показывает, что важное значение имеет оценка финансового риска. В перспективе просматриваются следующие направления исследований.
Представляется целесообразным для эффективной спекулятивной торговли использовать такой математический аппарат, как случайный лес в современных интерпретациях. Ломакин Н.И. с коллегами, исследуя цифровизацию и будущее финансовых услуг, анализируя влияние технологических разработок на финансовый сектор, делает вывод о необходимости широкого применения инноваций в сфере цифровых финансов . Ученый Рупали Багате (Rupali Bagate) с коллегами проанализировали текущие достижения в области обработки естественного языка (NLP) ими предпринята попытка использования анализа настроений в алгоритмической торговле .
Дерево бинарной классификации (соответственно регрессии), предложенное в работе Breiman, представляет собой модель ввода-вывода, представленную древовидной структурой T из случайного входного вектора (X1…Xp), принимающего свои значения в (X1*…*Xp)=X в случайную выходную переменную Y 𝜖 𝛶 . Практика показывает, что применение систем искусственного интеллекта позволяет решать широкий круг проблем. В перспективе нейронные сети могут быть использованы для оценки отклонений от намеченной траектории, цены актива.
5. Заключение
Таким образом, на основании вышесказанного можно сделать выводы:
1. Представлен алгоритм управления биржевым активом – фьючерсным контрактом на доллар SiM3 на Московской бирже (MoEx). В основу алгоритма положена модель глубокого обучения «Рандом Форест Регрессия» (DL RFR).
2. Разработанная DL-модель позволяет получать прогноз цены закрытия фьючерсного контракта на следующий таймфрейм – час, что позволяет обеспечить поддержку принятия управленческого решения по поводу покупки/продажи биржевого актива SiM3.
3. Расчеты свидетельствуют о том, что DL-модель показывает высокую точности прогноза, поскольку уровень средней абсолютной ошибки модели не превышает значения 133,52 руб., а уровень MSE при этом составляет 1729,27, при этом RMSE = 41,58 для варианта в котором доля тестовой выборки в датасете составляла 0,20.
4. Применение систем искусственного интеллекта позволяет решать широкий круг проблем, в алгоритмической торговле и обеспечить эффективное управление биржевым активом.