COMPARISON OF YOLO V5 AND FASTER R-CNN FOR DETECTING PEOPLE IN THE IMAGE IN STREAMING MODE

DOI: https://doi.org/10.23670/IRJ.2022.120.6.020
СРАВНЕНИЕ YOLOV5 И FASTERR-CNN ДЛЯ ОБНАРУЖЕНИЯ ЛЮДЕЙ НА ИЗОБРАЖЕНИИ В ПОТОКОВОМ РЕЖИМЕ
Научная статья
Тимошкин М.С.1, *, Миронов А.Н.2, Леонтьев А.С.3
1 ORCID: 0000-0003-1842-8331;
1, 2, 3 МИРЭА – Российский технологический университет, Москва, Россия
* Корреспондирующий автор (max030511[at]gmail.com)
Аннотация
С каждым годом проблема очередей становится все острее. Ее решение в условиях текущей эпидемиологической обстановки имеет особую значимость. В работе рассмотрена возможность решения данной проблемы при помощи информационных технологий. В качестве инструмента рассматривается машинное обучение. В данной работе рассматривается сбор и аннотирование подходящего набора данных для обучения, приводится описание наиболее распространенных моделей обнаружения объектов: YOLOv5 и FasterR-CNN, а также проводится их обучение и валидация на собранном наборе данных. Для осуществления сравнительного анализа рассматриваются основные метрики машинного обучения. На основе полученных в ходе эксперимента результатов осуществляется выбор наиболее подходящей для данной проблемы модели.
Ключевые слова: машинное обучение, обнаружение людей, FasterR-CNN, YOLOv5, обнаружение в потоковом режиме, компьютерное зрение.
COMPARISON OF YOLO V5 AND FASTER R-CNN FOR DETECTING PEOPLE IN THE IMAGE IN STREAMING MODE
Research article
Timoshkin M.S.1, *, Mironov A.N.2, Leontev A.S.3
1 ORCID: 0000-0003-1842-8331;
1, 2, 3 MIREA – Russian Technological University, Moscow, Russian Federation
* Corresponding author (max030511[at]gmail.com)
Abstract
The problem of queues becomes more acute with every year. Its solution in the current epidemiological situation is of particular importance. The article analyzes the possibility of its solving with the help of information technologies. Machine learning is considered as a tool. This work studies gathering and annotating of a suitable data set for training, describes the most common object detection models: YOLOv5 and Faster R-CNN, and conducts their training and validation on the collected data set. Basic machine learning metrics are considered for comparative analysis. On the basis of the experimental results, the most appropriate model is selected.
Keywords: machine learning, detection of people, Faster R-CNN, YOLOv5, detection in streaming mode, computer vision.
Введение
Пребывание в очередях – неотъемлемая часть жизни каждого человека. По результатам опроса агентства «Русопрос» было выявлено, что общее время, которое россияне проводят в очередях, в среднем составляет 130 часов в год [1].
В результате проведенного социологического исследования была составлена диаграмма, которая показывает статистику проведенного времени людьми в очередях (см. рисунок 1).
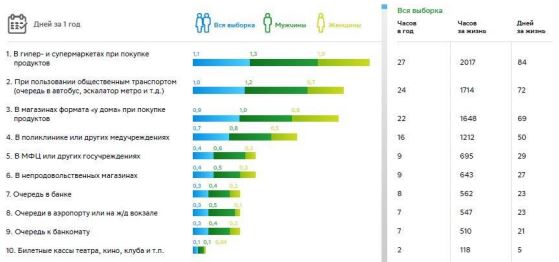
Рис. 1 – Статистика проведенного времени людьми в очередях
Имея возможность отслеживать заполненность помещений или количество людей в очередях, люди могли бы выбирать другое заведение или кассу/стойку, что позволило бы распределить нагрузку. В текущей эпидемиологической ситуации сбор подобной информации и принятие на его основе решений играют особую значимость.
На данный момент в большинстве случаев используют ручной подсчет входящих и выходящих посетителей, что позволяет своевременно открывать и закрывать вход из эпидемиологических соображений, при этом задачи подсчета очередей и информирования посетителей не выполняются.
Использование информационных технологий, машинного обучения, в частности, может решить задачу своевременного информирования о количестве посетителей, сведя участие человека к минимуму.
Технологии отслеживания объектов, основанные на глубоком обучении
Машинное обучение широко применяется в компьютерном зрении и обработке изображений [2]. Уровень развития машинного обучения и наличие разнообразных комплексных моделей могут позволить с достаточной точностью обнаруживать на изображении людей, что обеспечит возможность их подсчета. Видеопоток с заведений может быть получен с систем видеонаблюдения, которых с каждым годом становится все больше.
Точность модели будет являться одним из основных показателей, на основе которого можно сделать вывод о пригодности модели для ее практической эксплуатации. Однако с учетом специфики выявленной задачи, также стоит обратить внимание на скорость работы модели, так как необходима обработка данных в потоковом режиме. Если модель будет обрабатывать данные слишком долго, пользователи могут получить неактуальную информацию о количестве людей в помещении.
Чтобы исследовать возможность использования машинного обучения в задаче подсчета людей, были рассмотрены, обучены и протестированы главные представители двух групп моделей распознавания объектов: YOLOv5 (одноэтапный метод) и FasterR-CNN (двухэтапный метод). Была рассмотрена их скорость и точность обнаружения, чтобы определить лучшую модель для решения задачи подсчета посетителей. Обе архитектуры относятся к группе сверточных нейронных сетей.
Сверточные нейронные сети являются наиболее распространенным алгоритмом глубокого обучения, применяющим несколько сверхточных слоев и вычислений [2]. Они предоставляют эффективные способы извлечения признаков, а также являются лучшим выбором для решения проблем обнаружения объектов [2].
Текущие подходы с использованием методов глубокого обучения для задач классификации и регрессии объектов можно разделить на две категории. Первая — это двухэтапные методы, которые представлены такими архитектурами как R-CNN, FastR-CNN и FasterR-CNN. Данные методы выполняются в два этапа. Изначально используется селективный поиск или сеть региональных предположений (англ. RPN) для выделения регионов интереса – областей, с высокой вероятностью содержащих внутри себя объекты. Затем при помощи классификатора определяется класс объекта, а при помощи регрессора определяются ограничивающие рамки. Данный метод обладает высокой точностью, но при этом ограничен в скорости обнаружения. К другой категории относятся одноэтапные алгоритмы, представленные различными версиями YOLO и др. Данные алгоритмы не используют отдельную сеть для генерации регионов и основываются на методах регрессии, просматривая изображения целиком. Так как данные алгоритмы не используют RPN, скорость обнаружения выше, но точность обнаружения, в особенности малых объектов, не такая высокая, как у двухэтапных методов.
FasterR-CNN
FasterR-CNN это алгоритм обнаружения объектов, предложенный Шаоцин Рэном в 2015 году [3], который состоит из четырех частей: сеть извлечения признаков (англ. featureextractionnetwork), сеть региональных предположений (англ. regionproposalnetwork), объединение регионов интереса (англ. RoIPooling) и полносвязный слой. Архитектура модели FasterR-CNN представлена далее (см. рисунок 2).
Рис. 2 – Архитектура модели FasterR-CNN
FasterR-CNN это улучшенная версия алгоритмов R-CNN и FastR-CNN. Различие между ними в том, что алгоритм FasterR-CNN избегает использования вычислительно дорогого алгоритма селективного поиска. Вместо этого использует RPN для создания областей кандидатов. RPN позволяет определять предположения на основе признаков всего изображения за один проход, что позволяет избежать повторных вычислений и увеличивает скорость обнаружения.
YOLOv5
YOLO предлагает новую идею решения задачи обнаружения объектов за счет преобразования задачи в регрессионную [4]. YOLO – одноэтапный алгоритм глубокого обучения, который использует сверхточные нейронные сети для обнаружения объектов. Существуют различные версии данного алгоритма. YOLOv1 делит изображение на ячейки размером n на n одинакового размера. Каждая ячейка сетки отвечает за обнаружение центра объекта внутри ячейки. Каждая ячейка может предсказать фиксированное количество ограничивающих рамок со значением достоверности (англ. confidencescore). Каждая ограничивающая рамка включает в себя 5 значений: координата центра по оси абсцисс, координата центра по оси ординат, высота рамки, ширина рамки и значение достоверности. После определения ограничивающих рамок YOLO использует пересечение над объединением (англ. IoU), чтобы выбрать наиболее подходящие. Для удаления лишних рамок используется немаксимальное подавление (англ. NMS). В YOLOv2 была добавлена пакетная нормализация (англ. batchnormalization) вместе со сверточными слоями для увеличения точности и уменьшения возможности переобучения [5]. В YOLOv3 магистральная сеть извлечения признаков (англ. featureextractionbackbone) Darknet19, которая плохо обнаруживала маленькие объекты, была заменена на Darknet53 для решения это проблемы [6]. В YOLOv4 снова была заменена магистральная сеть извлечения признаков на CSPDarknet53, что значительно улучшило скорость и точность алгоритма [7]. YOLOv5 – самая облегченная версия из предыдущих, которая использует фреймворк PyTorch вместо Darknet [8]. Также в нее был добавлен новый слой фокуса (англ. focuslayer), который заменил первые три слоя магистральной сети YOLOv3, что позволило увеличить скорость при минимальных потерях в точности [9]. Архитектура модели YOLOv5 представлена далее (см. рисунок 3).

Рис. 3 – Архитектура модели YOLOv5
Подготовка обучающего набора данных
Для обучения моделей глубокого обучения требуется большая выборка изображений для получения достаточно эффективной модели. Существует множество различных наборов данных с людьми, например, COCO, CrowdHuman и др. Однако решение поставленной задачи заключается в обнаружении людей с камер видеонаблюдения, что предполагает нестандартный ракурс, отличающийся от ракурса в перечисленных выше наборах данных. Поэтому был собран собственный набор данных с камер видеонаблюдения для обучения. Были собраны изображения людей под различным углом, на различной высоте, в различных местах и с разным количеством людей для получения лучших результатов обучения. Всего было собрано 550 изображений для обучения и 105 изображений для валидации. Примеры изображений представлены далее (см. рисунок 4).

Рис. 4 – Примеры изображений обучающего набора данных
Также было собран набор данных из 573 изображений с нового местоположения для окончательной валидации моделей. Примеры изображений с данного набора данных представлены далее (см. рисунок 5).

Рис. 5 – Примеры изображений второго валидационного набора данных
Аннотирование изображений
Так как используемый метод распознавания объектов является разновидностью метода обучения с учителем, необходимо передавать модели информацию о местоположении ограничивающих рамок людей на изображении. Для этого необходимо произвести аннотирование изображений. Для выполнения этой задачи предполагается использовать Roboflow, который позволяет не только размечать изображения, но также позволяет экспортировать аннотированные наборы данных в различных форматах, что ускоряет процесс, так как YOLOv5 и FasterR-CNN имеют различные форматы аннотаций. Процесс аннотирования представлен далее (см. рисунок 6).

Рис. 6 – Процесс аннотирования изображения при помощи RoboFlow
Начальная конфигурация экспериментального стенда
Обучение и валидация моделей производилась на платформе GoogleColab. Данная платформа обладает следующей конфигурацией: ОС Ubuntu 18.04, графический процессор NVIDIATeslaT4, процессор Intel(R) Xeon(R) CPU @ 2.20ГГц. На платформе используется язык программирования Python и фреймворк PyTorch. Для обучения и валидации моделей используются библиотеки yolov5 [10] и detecron2 [11] для YOLOv5 и FasterR-CNN соответственно. Для улучшения результатов обучения были выбраны уже предобученные модели. Библиотекой yolov5 предоставляются 5 различных предобученных на наборе данных COCO моделей, которые отличаются размером, скоростью выполнения и точностью. Была выбрана YOLOv5m, так как она по сравнению с YOLOv5s имеют намного большую точность и не теряет скорости, а по сравнению с YOLOv5l имеет немного меньше точность, теряя при этом в скорости [12]. COCO – один из наиболее используемых наборов данных, включающий 330 тысячи изображений с различными объектами, включая людей. Библиотекой detecron2 предоставляется большое количество предобученных моделей на различных наборах данных. Среди моделей, предобученных на наборе данных COCO, была выбрана R101-FPN, так как она имеет достаточную точность и сохраняет при этом достаточную скорость среди всех остальных моделей [13].
Гиперпараметры обучения моделей представлены далее (см. таблицу 1).
Таблица 1 – Значения гиперпараметров моделей при обучении
| Параметр | Значение |
| Количество эпох (англ. number of epochs) | 20 |
| Размер пакета (англ. batchsize) | 16 |
| Скорость обучения (англ. learningrate) | 0,001 |
| Моментум (англ. momentum) | 0,9 |
| Сокращение веса (англ. weightdecay) | 0,0005 |
Критерии оценки
Для сравнения результатов двух разных моделей глубокого обучения для обнаружения людей был применен ряд стандартных метрик, используемых для оценки моделей машинного обучения. Есть всего 4 возможных исхода при выделении ограничивающих рамок и обнаружении объекта: истинно положительные (англ. TP), истинно отрицательные (англ. TN), ложно положительные (англ. FP) и ложно отрицательные (англ. FN). TP результат означает, что модель корректно определила положительный класс. TN результат означает, что модель корректно определила отрицательный класс. FP результат означает, что модель некорректно определила положительный класс. FN результат означает, что модель некорректно определила отрицательный класс. В данной задаче одноклассового обнаружения положительным классом является человек, а отрицательным задний фон. Таким образом, TP – верное обнаружение человека, TN – верное обнаружение фона (данный показатель не используется, так как область заднего фона не выделяется при аннотировании), FP – некорректное обнаружение человека, FN – отсутствие обнаружения. Графическое объяснение представлено далее (см. рисунок 7).

Рис. 7 – Визуальная демонстрация определений TP, FP, FN
Для определения принадлежности результата к одной из четырех групп используется метрика IoU, которая является отношением области пересечения к области объединения корректной и предсказанной ограничивающих рамок.
На основе полученных результатов TP, FP и FN подсчитываются стандартные показатели: точность (англ. precision), полнота (англ. recall) и средняя точность (англ. AP). Также рассчитывается отдельно количество кадров, которое способна обработать модель за одну секунду (англ. FPS).
Точность определяет отношение числа корректно обнаруженных объектов ко всему количеству обнаруженных объектов и вычисляется по формуле 1.

Кривая точности-полноты показывает зависимость изменения точности при изменении полноты для разных пороговых значений. В данном исследовании графики кривых точности-полноты построены на основе широко используемого порогового значения IoU равного 0.6.
Средняя точность является одной из наиболее используемых метрик для определения качества модели обнаружения объектов. При этом средняя точность может включать в себя различные метрики в зависимости от IoU. Наиболее используемыми является значение AP при IoU не меньше 0.5 и среднее значение AP при пороговых значениях IoU в диапазоне от 0.5 до 0.95 c шагом 0.5, которые обозначаются AP@.5 и AP@.5:.95 соответственно.
Количество кадров в секунду — это основной показатель быстроты модели. В основном считается, что показатель FPS выше 30 достаточен для выполнения обнаружения в потоковом режиме.
Сра0внение результатов моделей
Размер обученных моделей YOLOv5 и FasterR-CNN составил 40.2 МБ и 230.8 МБ соответственно. После обучения модели были протестированы на первом валидационном наборе. Результаты представлены далее (см. таблицу 2, рисунки 8, 9).
Таблица 2 – Результаты валидации моделей на первом наборе данных
| Архитектура | Точность, % | Полнота, % | AP@.5, % | AP@.5:.95, % | FPS, к/c |
| YOLOv5 | 93,6 | 93,7 | 96 | 50,2 | 56,5 |
| Faster R-CNN | 94,2 | 92,8 | 95,1 | 51 | 6,56 |

Рис. 8 – Кривые точности-полноты моделей после валидации на первом наборе данных

Рис. 9 – Результаты обнаружения двух моделей на первом валидационном наборе
YOLOv5 имеет показатели AP@.5 и FPS выше на 0.9% и 49.94 к/c соответственно, чем у FasterR-CNN. При этом FasterR-CNN имеет показатель AP@.5:.95 выше на 0.8%, чем у YOLOv5. Из этого можно сделать вывод, YOLOv5 быстрее справляется с обнаружением и имеет большую точность при небольшом пороговом значение IoU, а FasterR-CNN сохраняет большую точность при предсказании более совпадающих рамок.
Далее модели были протестированы на втором валидационном наборе. Результаты представлены далее (см. таблицу 3, рисунки 10, 11).
Таблица 3 – Результаты валидации моделей на втором наборе данных
| Архитектура | Точность, % | Полнота, % | AP@.5, % | AP@.5:.95, % | FPS, к/c |
| YOLOv5 | 89,3 | 79,9 | 86,1 | 34,1 | 100 |
| Faster R-CNN | 89,2 | 81,4 | 87,7 | 40,9 | 6,1 |
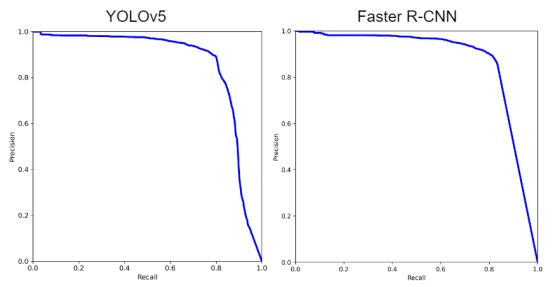
Рис. 10 – Кривые точности-полноты моделей после валидации на втором наборе данных
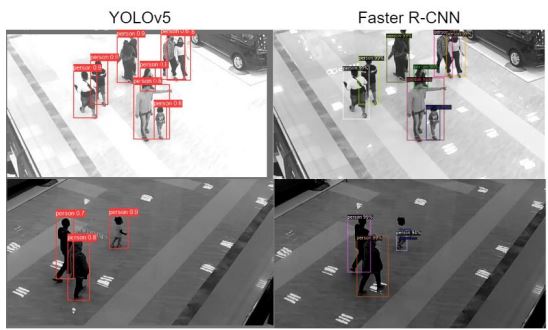
Рис. 11 – Результаты обнаружения двух моделей на втором валидационном наборе
Получив изображения с нового местоположения точность двух моделей уменьшилась, однако FasterR-CNN имеет показатель средней точности выше, чем YOLOv5 на 1.6% и 6.8% для AP@.5 и AP@.5:.95 соответственно. Из этого можно сделать вывод, что FasterR-CNN имеет более глубокое обучение, которое позволяет не так сильно терять точность при получении изображения с новой средой.
FasterR-CNN не удовлетворяет требованиям обнаружения в потоковом режиме, однако позволяет достаточно точно определять объекты в новой среде без дообучения. Данный алгоритм подходит в тех случаях, когда нужно обнаружение точных ограничивающих рамок и обнаружения в разных средах без предварительного дообучения.
YOLOv5 удовлетворяет требованиям обнаружения в потоковом режиме, при этом сохраняет достаточно высокую точность. Однако при получении изображений с другой средой может потерять точность обнаружения как при пороговом значении IoU равном 0.5, так и при больших.
Заключение
В результате исследования был собран набор данных с камер видеонаблюдения и проаннотирован при помощи RoboFlow. Главные представители двух групп алгоритмов обнаружения объектов YOLOv5 и FasterR-CNN были обучены с использованием подготовленного набора данных. Экспериментальным образом были получены метрики моделей. Результаты показали, что обе модели имеют свои преимущества и недостатки, обе модели применимы для различных задач. FasterR-CNN сохраняет высокую точность при различных входных данных, но при этом имеет медленную скорость обработки, что не позволяет ее использовать для обнаружения в потоковом режиме. YOLOv5 немного теряет точность на новых наборах данных, имея AP@.5 и AP@.5:.95 на 1.6% и 6.8% соответственно, чем FasterR-CNN, однако обладает скоростью обработки в несколько раз выше, чем FasterR-CNN, что позволяет использовать ее для обработки в потоковом режиме. Несмотря на то, что YOLOv5 теряет точность на новом наборе данных, показателя AP должно быть достаточно для решения задачи подсчета посетителей в общественных заведениях, погрешность подсчета с такой точностью считается допустимой. Если взять в учет, что среда в конкретном заведении с течением времени не меняется, то можно дообучить модель для получения более точных результатов.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References
- Николенко С.И. Глубокое обучение. Погружение в мир нейронных сетей. / С.И. Николенко, А.А. Кадурин, Е.В. Архангельская – Санкт-Петербург : Питер, 2018. – 480 c.
- Русопрос. Затрачиваемое в очередях время. [Электронный ресурс]. URL: https://rus-opros.com/about/articles/vremia-v-ocherediah/ (дата обращения: 10.04.2022)
- Ren Shaoqing . Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks / Shaoqing Ren, Kaiming He, Ross Girshick et al. // arXiv:1506.01497v1. – 2015. – 10 p.
- Redmon J. You Only Look Once: Unified, Real-Time Object Detection / J. Redmon, S. Divvala, R. Girshick et al. // arXiv:1506.02640v1. – 2015. – 10 p.
- Redmon J. YOLO9000: Better, Faster, Stronger / J. Redmon, A. Farhadi // arXiv:1612.08242v1. – 2016. – 9 p.
- Redmon J. YOLOv3: An Incremental Improvement / J. Redmon, A. Farhadi // arXiv:1804.02767v1. – 2018. – 6 p.
- Bochkovskiy A. YOLOv4: Optimal Speed and Accuracy of Object Detection / A. Bochkovskiy, C.-Y. Wang, H.-Y. Mark Liao // arXiv:2004.10934v1. – 2020. – 17 p.
- Nelson J. YOLOv5 is Here: State-of-the-Art Object Detection at 140 FPS [Electronic source] / J. Nelson, J. Solawetz // RoboflowBlog. – 2020. – URL: https://blog.roboflow.com/yolov5-is-here/ (accessed 20.04.22)
- Jocher G. YOLOv5 Focus Layer [Electronic source] / G. Jocher // GitHub. – 2021. – URL: https://github.com/ultralytics/yolov5/discussions/3181 (accessed 25.04.2022)
- Jocher G. YOLOv5 documentation [Electronic source] / G. Jocher // Ultralytics. – 2020. – URL: https://docs.ultralytics.com/ (accessed 26.04.2022)
- Wu Y. Detectron2 documentation [Electronic source] / Y. Wu, A. Kirillov, F. Massa et al. // Detectron2. – 2019. – URL: https://detectron2.readthedocs.io/en/latest/tutorials/getting_started.html (accessed 01.05.2022)
- Ahmed K. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution [Electronic source] / K. Ahmed // Sensors. – 2021. – 22 p. – URL: https://www.researchgate.net/publication/357093620_ (Date of application: 02.05.2022)
- Wu Y. Detectron2 Model Zoo and Baselines [Electronic source] / Y. Wu // GitHub. – 2021. – URL: https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md (accessed 04.05.2022)
Список литературы на английском языке / References in English
- Nikolenko S.I. Glubokoe obuchenie. Pogruzhenie v mir nejronny'x setej. [Deep learning. Loading into the world of neural networks.] / S.I. Nikolenko, A.A. Kadurin, E.V. Arxangel'skaya – Saint Petersburg : Piter, 2018. – 480 p. [in Russian]
- Zatrachivaemoe v ocheredjah vremja. [Time spent in queues.] [Electronic resource]. URL: https://rus-opros.com/about/articles/vremia-v-ocherediah/. (accessed 10.04.2022) [in Russian]
- Ren Shaoqing . Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks / Shaoqing Ren, Kaiming He, Ross Girshick et al. // arXiv:1506.01497v1. – 2015. – 10 p.
- Redmon J. You Only Look Once: Unified, Real-Time Object Detection / J. Redmon, S. Divvala, R. Girshick et al. // arXiv:1506.02640v1. – 2015. – 10 p.
- Redmon J. YOLO9000: Better, Faster, Stronger / J. Redmon, A. Farhadi // arXiv:1612.08242v1. – 2016. – 9 p.
- Redmon J. YOLOv3: An Incremental Improvement / J. Redmon, A. Farhadi // arXiv:1804.02767v1. – 2018. – 6 p.
- Bochkovskiy A. YOLOv4: Optimal Speed and Accuracy of Object Detection / A. Bochkovskiy, C.-Y. Wang, H.-Y. Mark Liao // arXiv:2004.10934v1. – 2020. – 17 p.
- Nelson J. YOLOv5 is Here: State-of-the-Art Object Detection at 140 FPS [Electronic source] / J. Nelson, J. Solawetz // RoboflowBlog. – 2020. – URL: https://blog.roboflow.com/yolov5-is-here/ (accessed 20.04.22)
- Jocher G. YOLOv5 Focus Layer [Electronic source] / G. Jocher // GitHub. – 2021. – URL: https://github.com/ultralytics/yolov5/discussions/3181 (accessed 25.04.2022)
- Jocher G. YOLOv5 documentation [Electronic source] / G. Jocher // Ultralytics. – 2020. – URL: https://docs.ultralytics.com/ (accessed 26.04.2022)
- Wu Y. Detectron2 documentation [Electronic source] / Y. Wu, A. Kirillov, F. Massa et al. // Detectron2. – 2019. – URL: https://detectron2.readthedocs.io/en/latest/tutorials/getting_started.html (accessed 01.05.2022)
- Ahmed K. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution [Electronic source] / K. Ahmed // Sensors. – 2021. – 22 p. – URL: https://www.researchgate.net/publication/357093620_ (Date of application: 02.05.2022)
- Wu Y. Detectron2 Model Zoo and Baselines [Electronic source] / Y. Wu // GitHub. – 2021. – URL: https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md (accessed 04.05.2022)