OVERVIEW OF METHODS FOR STATIC AND DYNAMIC CLUSTERING OF SECURITY EVENT LOGS

ОБЗОР МЕТОДОВ СТАТИЧЕСКОЙ И ДИНАМИЧЕСКОЙ КЛАСТЕРИЗАЦИИ ЖУРНАЛОВ СОБЫТИЙ БЕЗОПАСНОСТИ
Обзорная статья
Кротова Е.Л.1, Андреев Р.А.2, Андреева П.А.3, *
1 ORCID: 0000-0001-5941-0504;
2 ORCID: 0000-0001-8875-2802;
3 ORCID: 0000-0001-9211-2322;
1, 2, 3 Пермский национальный исследовательский политехнический университет, Пермь, Россия
* Корреспондирующий автор (feofilovap[at]gmail.com)
АннотацияФайлы журналов регистрации событий безопасности дают представление о состоянии информационной системы и позволяют обнаруживать аномалии в поведении пользователей и инциденты информационной безопасности. Однако автоматический анализ данных журналов событий безопасности затруднен, поскольку он содержит огромное количество неструктурированных данных, собранных из различных источников. В данной статье проводится обзор существующих подходов, которые уплотняют или суммируют данные журналов с помощью методов кластеризации, а именно методов статической и динамической кластеризации. Рассматриваются примеры применения статической и динамической кластеризации журналов событий безопасности, а также ограничения и проблемы в использовании данных методов.
Ключевые слова: журналы регистрации событий, поведение пользователя, аномалии, инциденты информационной безопасности, кластеризация.
OVERVIEW OF METHODS FOR STATIC AND DYNAMIC CLUSTERING OF SECURITY EVENT LOGS
Review article
Krotova E.L.1, *, Andreev R.A.2, Andreeva P.A.3
1 ORCID: 0000-0001-5941-0504;
2 ORCID: 0000-0001-8875-2802;
3 ORCID: 0000-0001-9211-2322;
1, 2, 3 Perm National Research Polytechnic University, Perm, Russia
* Corresponding author (feofilovap[at]gmail.com)
AbstractSecurity event log files provide insight into the state of the information system and allow detecting anomalies in user behavior and information security incidents. However, automatic analysis of security event log data is difficult because it contains a huge amount of unstructured data collected from various sources. This article provides an overview of existing approaches that condense or summarize log data using clustering methods, namely static and dynamic clustering methods. The study examines the examples of using static and dynamic clustering of security event logs as well as limitations and problems in the use of these methods.
Keywords: event logs, user behavior, anomalies, information security incidents, clustering.
Файлы журнала содержат информацию почти обо всех событиях, происходящих в системе, в зависимости от уровня журнала. Для этого развернутая инфраструктура ведения журналов автоматически собирает, объединяет и хранит журналы, которые постоянно создаются большинством компонентов и устройств, например, веб-серверами, базами данных или межсетевыми экранами. Текстовые сообщения журнала обычно удобочитаемы и прикрепляются к отметке времени, которая указывает момент времени, когда была создана запись журнала. Доступ к долгосрочным данным журнала имеет множество преимуществ, особенно для крупных организаций и предприятий: журналы позволяют проводить анализ прошлых событий, который дает системным администраторам возможность отследить корни наблюдаемых проблем. Более того, журналы могут помочь восстановить систему до исправного состояния, сбросить неправильные транзакции, восстановить данные, предотвратить потерю информации и воспроизвести сценарии, которые приводят к ошибочным состояниям во время тестирования [1].
Основная проблема анализа журналов заключается в том, что инциденты обнаруживаются только задним числом. Кроме того, анализ журналов – это трудоемкая и ресурсоемкая задача, требующая знания предметной области о системе. По этим причинам современные подходы к обеспечению информационной безопасности переходят от чисто судебной экспертизы к проактивному анализу. Таким образом, обнаружение неисправностей в реальном времени становится возможным благодаря постоянному мониторингу системных журналов в режиме онлайн, то есть сразу после их создания. Это позволяет своевременно реагировать на инциденты информационной безопасности [2] и снижает вызванные ими расходы. Вдобавок ко всему, индикаторы предстоящего ошибочного поведения системы часто можно наблюдать заранее. Достаточно раннее обнаружение таких индикаторов и принятие соответствующих мер может помочь предотвратить определенные неисправности.
К сожалению, эта задача вряд ли возможна для человека, поскольку данные журнала генерируются в огромных объемах [3] и с большой скоростью. При рассмотрении крупных корпоративных систем нередко количество ежедневно создаваемых строк журнала исчисляется миллионами, например, общедоступные журналы распределенной файловой системы Hadoop (HDFS) [4] содержат более 4 миллионов строк журнала в день, а небольшие организации имеют дело с пиковыми значениями 22000 событий в секунду. Очевидно, что это делает невозможным ручной анализ, и поэтому разумно использовать алгоритмы машинного обучения [5], которые автоматически обрабатывают линии и распознают интересные шаблоны, которые затем представляются системным операторам в сжатой форме.
Одним из методов анализа больших объемов данных журнала является кластеризация. Существует несколько алгоритмов кластеризации, специально разработанных для текстовых данных журнала [6]. Поскольку большинство алгоритмов в основном разрабатывались для определенных сценариев конкретного приложения, их подходы часто различаются по своим общим целям и предположениям относительно входных данных. В данной статье приведен обзор статической и динамической кластеризации журналов.
Данные журнала обладают определенными характеристиками, которые необходимо учитывать при разработке алгоритма кластеризации. Во-первых, файл журнала обычно состоит из набора однострочных или многострочных строк, перечисленных в заданном хронологическом порядке. Этот хронологический порядок обычно подкрепляется отметкой времени, прикрепляемой к сообщениям журнала. Сообщения могут быть сильно структурированными (например, список значений, разделенных запятыми), частично структурированными (например, пары атрибут-значение), неструктурированными (например, свободный текст произвольной длины) или их комбинацией. Кроме того, сообщения журнала иногда включают идентификаторы процессов, которые относятся к задаче, которая их сгенерировала. В этом случае просто извлечь трассировки журнала, то есть последовательности связанных строк журнала, и выполнить интеллектуальный анализ процессов. Другие артефакты, иногда включаемые в сообщения журнала – это номера строк, индикатор уровня или серьезности сообщения и статический идентификатор, указывающий на оператора, создающего сообщение [7].
Эти свойства позволяют группировать системные журналы двумя разными способами. Во-первых, кластеризация отдельных строк журнала по схожести их сообщений дает обзор всех событий, которые происходят в системе. Во-вторых, кластеризация последовательностей сообщений журнала дает представление о базовой логике программы и раскрывает в противном случае скрытые зависимости событий и компонентов.
Кластеризация отдельных строк журнала рассматривается как статическая процедура, потому что порядок и зависимости между строками обычно не учитываются. После такой статической кластеризации результирующий набор кластеров в идеале должен напоминать набор всех операторов печати, генерирующих журнал, где каждая строка журнала принадлежит кластеру, представляющему оператор, которым она была сгенерирована. Более подробное изучение операторов показывает, что они обычно содержат статические строки, которые идентичны во всех сообщениях, создаваемых этим оператором, и переменные части, которые динамически заменяются во время выполнения. Таким образом, части переменных часто являются числовыми значениями, идентификаторами (например, именами или IP-адресами) или категориальными атрибутами. Стоит обратить внимание, что создание журналов с использованием в основном фиксированных операторов отвечает за искаженное распределение слов в файлах журналов.
Проблемы кластеризации с образцами строк журнала представлены в следующем примере строк журнала:
1 : : Пользователь Алиса входит в систему со статусом 1
2 : : Пользователь Боб входит в систему со статусом 1
3 : : Пользователь Алиса выходит из системы со статусом 1
4 : : Пользователь Чарли входит в систему со статусом -1
5 : : Пользователь Боб выходит из системы со статусом 1
В этом примере сообщения журнала описывают вход и выход пользователей. Строки {1, 2, 4} вида («Пользователь» + «Имя» + «Входит в систему со статусом» + «Статус») и строки {3, 5} вида («Пользователь» + «Имя + «Выходит из системы со статусом» + «Статус») относятся к первому и второму кластерам соответственно. Из этой кластеризации могут быть получены шаблоны (также называемые сигнатурами или событиями) «Пользователь * входит в систему со статусом *» и «Пользователь * выходит из системы со статусом *», где подстановочный знак * обозначает любое слово в этой позиции. Таким образом, все пользователи, входящие или выходящие с любым статусом, будут правильно распределены, например, «Пользователь Дейв входит в систему со статусом 0».
Алгоритмам не хватает семантического понимания сообщений журнала, и они могут с таким же успехом сгруппировать строки в соответствии с именем пользователя, то есть создать кластеры {1, 3}, {2, 5} и {4}, или в соответствии со статусом, то есть создание кластеров {1, 2, 3, 5} и {4}. В последнем случае наиболее специфическими шаблонами, соответствующими кластерам, являются «Пользователь * входит в систему / выходит из системы со статусом 1» и «Пользователь Чарли входит в систему со статусом -1». В большинстве сценариев качество этих шаблонов считается плохим, поскольку первый шаблон является слишком обобщенным, а второй шаблон является слишком конкретным. Соответственно, вновь поступающие строки журнала могут образовывать выбросы, то есть не соответствовать какому-либо шаблону кластера.
Данный пример показывает, что всегда существует множество различных кластеров, оценка качества которых в конечном итоге является субъективным решением, которое в значительной степени зависит от приложения. Например, исследователи поведения пользователей могут потребовать, чтобы все строки журнала, созданные конкретным пользователем, попадали в один кластер [8]. В любом случае, соответствующее качество кластера очень важно, поскольку кластеры часто являются основой для дальнейшего анализа, который работает на основе сгруппированных данных и извлеченных шаблонов. Далее динамическая кластеризация рассматривается как приложение, использующее статические распределения кластеров.
Файлы журнала подходят для динамической кластеризации, то есть для распределения последовательностей появления строк журнала по шаблонам [9]. Однако необработанные строки журнала обычно не подходят для такого последовательного распознавания образов из-за того, что каждая строка журнала является уникальным экземпляром, описывающим часть состояния системы в определенный момент времени. Поскольку распознавание образов основано на повторяющемся поведении, сначала необходимо выделить строки журнала по классам, которые относятся к их исходному событию. Эта задача выполняется статической кластеризацией.
Далее рассматривается пример файла журнала, содержащий информацию о трех пользователях, которые входят в систему, выполняют некоторые действия и выходят из системы:
1 : : Пользователь Алиса входит в систему со статусом 1 : : A
2 : : Пользователь Алиса выполняет действие открытие : : B
3 : : Пользователь Алиса выходит из системы со статусом 1 : : C
4 : : Пользователь Боб входит в систему со статусом 1 : : A
5 : : Пользователь Боб выполняет действие запись : : B
6 : : Пользователь Чарли входит в систему со статусом 1 : : A
7 : : Пользователь Боб выходит из системы со статусом 1 : : C
8 : : Пользователь Чарли выполняет действие чтение : : B
9 : : Пользователь Чарли выходит из системы со статусом 1 : : C
Предполагается, что эти шаги всегда выполняются в такой последовательности, то есть невозможно выполнить действие или выйти из системы без предварительного входа в систему.
Допустим, что образец файла журнала был проанализирован алгоритмом статической кластеризации для создания трех шаблонов A = «Пользователь * входит в систему со статусом *», B = «Пользователь * выполняет действие *» и C = «Пользователь * выходит из системы со статусом *». Затем каждой строке присваивается одно из событий. В такой настройке результатом алгоритма динамической кластеризации может быть извлеченная последовательность A, B, C, поскольку этот шаблон описывает нормальное поведение пользователя. Однако события в строках 6 и 7 меняются местами, тем самым прерывая шаблон. Причина этой проблемы вызвана чередованием поведения пользователя, то есть пользователь Чарли входит в систему до того, как пользователь Боб выходит из системы (см. рисунок 1).
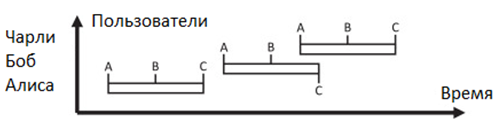
Рис. 1 – Примеры событий журнала, отображаемых на временной шкале
Поскольку в реальных системах многие приложения работают параллельно, в файлах журналов обычно возникают чередующиеся процессы, что усложняет процесс извлечения шаблонов. Некоторые файлы журналов включают идентификаторы процессов, которые позволяют анализировать соответствующие журналы, изолированные от прерывающихся процессов, и таким образом решать эту проблему. Для этой цели может использоваться имя пользователя. В дополнение к чередующимся последовательностям событий реальные системы, очевидно, содержат гораздо более сложные шаблоны, включая произвольно повторяющиеся или изменяющиеся подшаблоны.
Хотя анализ последовательностей является обычным явлением, это не единственный метод динамической кластеризации. В частности, аналогичные группы логических линий могут быть сформированы путем их объединения во временные окна и анализа их частот, совпадений или корреляций. Например, кластеризация может быть направлена на создание групп строк журнала, которые часто встречаются вместе. В этой настройке порядок событий не имеет значения, имеет значение только их появление в течение определенного временного интервала [10].
Дальнейшие исследования будут посвящены более подробному изучению статических и динамических методов кластеризации, а также других методов кластеризации журналов событий безопасности и их сравнению.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References
- Oliner A. Advances and Challenges in Log Analysis: Logs contain a wealth of information for help in managing systems / A. Oliner, A. Ganapathi, W. Xu //ACM Queue, 2011, 9(12). DOI: 10.1145/2076796.2082137.
- Best practices for incident response [Electronic resource] URL: https://www.securitymagazine.com/articles/93235-best-practices-for-incident-response (accessed: 10.03.2021).
- Miranskyy A. Operational-Log Analysis for Big Data Systems: Challenges and Solutions / A. Miranskyy, A. Hamou-Lhadj, E. Cialini et al. //IEEE Software, 2016, 33(2), pp. 52–59. DOI: 10.1109/MS.2016.33.
- HDFS Architecture [Electronic resource] URL: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html (accessed: 15.03.2021).
- A Tour of Machine Learning Algorithms [Electronic resource] URL: https://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/ (accessed: 20.03.2021).
- Rodriguez, M.Z. Clustering algorithms: A comparative approach / M.Z. Rodriguez, C.H. Comin, D. Casanova et al. // PLOS One, 2019.
- Zeng L. Computer operating system logging and security issues: a survey / L. Zeng, Y. Xiao, H. Chen et al. // Security and communication networks, 2016, 9 (17), pp. 4804–4821. DOI: 10.1002/sec.1677.
- Zhang M. Review of User Behavior Analysis Based on Big Data: Method and Application / M. Zhang, Y. Wang, J. Chai // Proceedings of the International Conference on Advances in Mechanical Engineering and Industrial Informatics, 2015.
- Bouchachia A. Dynamic Clustering / A. Bouchachia //Evolving Systems, 2012, 3, pp. 133–134.
- Barbosa Roa N. A novel algorithm for dynamic clustering: properties and performance / N. Barbosa Roa, L. Trave-Massuyès, V.H. Grisales // 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, United States, 2016, pp. 565–570. DOI: 10.1109/ICMLA.2016.0099.