AI-based information system for translating non-verbal language into a linguistic model
AI-based information system for translating non-verbal language into a linguistic model
Abstract
This article is dedicated to the development of an information system based on artificial intelligence to translate non-verbal language, in particular Russian sign language, into a linguistic model. The main objective of the research is to create a system capable of automatically recognising gestures and converting them into text messages. For this purpose, algorithms of machine learning, computer vision and modern models of artificial intelligence were used. During the development process, the system was created and tested in Python language using MMAction2 and ONNX Runtime tools, which allowed to achieve high accuracy of gesture recognition and ensure real-time operation of the system. The development is aimed at solving the problem of limited access of the hearing impaired to information and means of communication, which makes this work relevant for the social integration of this population.
1. Введение
Современное общество характеризуется разнообразием людей с различными физиологическими особенностями, которые, несмотря на различия, активно взаимодействуют в социальных и профессиональных сферах. Одной из таких групп являются слабослышащие люди, которые сталкиваются с рядом трудностей, связанных с недостаточным доступом к информации и социальной изоляцией. Согласно данным Всемирной организации здравоохранения, примерно 650 миллионов человек по всему миру страдают от различных форм потери слуха, что составляет около 5% от общего числа населения планеты . В России, по официальным данным, на 2024 год число людей с нарушениями слуха и зрения превышает 19 миллионов, а по неофициальным подсчетам, количество слабослышащих может составлять более 2 миллионов. С учетом этих тенденций ожидается, что число людей с нарушениями слуха будет неуклонно расти, что подчеркивает необходимость разработки новых подходов к решению связанных с этим проблем.
Слабослышащие люди сталкиваются с рядом социальных и коммуникативных проблем, среди которых можно выделить ограниченный доступ к информации, трудности в понимании речи, а также проблемы в общении со слышащими людьми. Эти сложности зачастую становятся препятствием для их полноценной интеграции в общество. В частности, слабослышащие испытывают затруднения в получении образовательных, медицинских и иных услуг из-за нехватки перевода на жестовый язык или субтитров в реальном времени. В условиях современных технологий некоторые из этих проблем могут быть решены с помощью автоматизированных систем перевода и распознавания жестового языка, что позволит существенно улучшить качество жизни данной категории населения.
Жестовые языки, включая русский жестовый язык (РЖЯ), являются основным средством общения для миллионов людей с нарушениями слуха. Эти языки основываются на жестах, мимике, позах тела и других невербальных компонентах. Однако, несмотря на важность жестового языка как средства коммуникации, его освоение и использование ограничены, поскольку большинство людей не владеют данным языком. Также существует дефицит профессиональных переводчиков жестового языка, что усугубляет проблему. Это подчеркивает необходимость разработки автоматизированных решений, которые помогут преодолеть языковой барьер между слышащими и слабослышащими людьми.
Актуальность темы заключается в необходимости создания технологий для автоматического перевода жестового языка в текст или другие языки в реальном времени. Современные достижения в области искусственного интеллекта (ИИ), машинного обучения и компьютерного зрения открывают новые возможности для решения этой задачи. Автоматический перевод жестового языка является перспективной технологией, которая может значительно улучшить доступность образования, здравоохранения, публичных услуг и других сфер для людей с нарушениями слуха. С развитием технологий в этой области можно ожидать улучшение качества жизни слабослышащих людей и их интеграции в общество.
Целью данной работы является разработка системы на основе искусственного интеллекта для перевода жестового языка в лингвистическую модель. Для достижения этой цели будут рассмотрены существующие методы и технологии распознавания жестового языка, а также разработана информационная система на основе Python с применением алгоритмов машинного обучения и компьютерного зрения, способная эффективно распознавать и переводить жесты РЖЯ в текст.
В рамках исследования поставлены следующие задачи: провести обзор существующих решений к распознаванию и переводу жестового языка, а также рассмотреть особенности РЖЯ; изучить современный инструментарий для распознавания жестов и перевода невербальных языков; оценить эффективность существующих решений и их применимость в контексте перевода жестового языка; разработать информационную систему на языке Python, использующую методы ИИ для распознавания и перевода жестов РЖЯ; оценить эффективность и применимость разработанной системы на основе экспериментальных данных.
Практическая ценность работы заключается в создании программного продукта, который будет способствовать улучшению доступности и качества жизни слабослышащих людей, позволяя им более эффективно взаимодействовать с обществом.
2. Существующие решения
Рассмотрим существующие решения, способные в режиме реального времени переводить жесты русского жестового языка, и приведем показания метрик для дальнейшего сравнения с разрабатываемой системой.
Команда Vision RnD сделала, не побоюсь этого слова, величайший шаг в развитии распознавания и перевода русского жестового языка – собрала крупнейший набор данных для обучения моделей искусственного интеллекта, направленных на распознавание отдельных жестов
.В общей сложности удалось собрать более 200 тысяч видеозаписей с жестами РЖЯ, разделенных на 3 тысячи уникальных классов. К сожалению, в открытом доступе есть лишь малая часть этих данных, но и этого достаточно для обучения моделей искусственного интеллекта, способного распознавать одну тысячу жестов. Именно этот датасет будет использован в качестве обучающей и тестовой выборки в проектируемой нами системе. Процесс сбора и обработки информации будет рассмотрен в следующей главе.
Последней разработкой команды из SberDevices является семейство моделей SignFlow, содержащее две модели – SignFlow-R для распознавания РЖЯ и SignFlow-A для распознавания американского жестового языка
.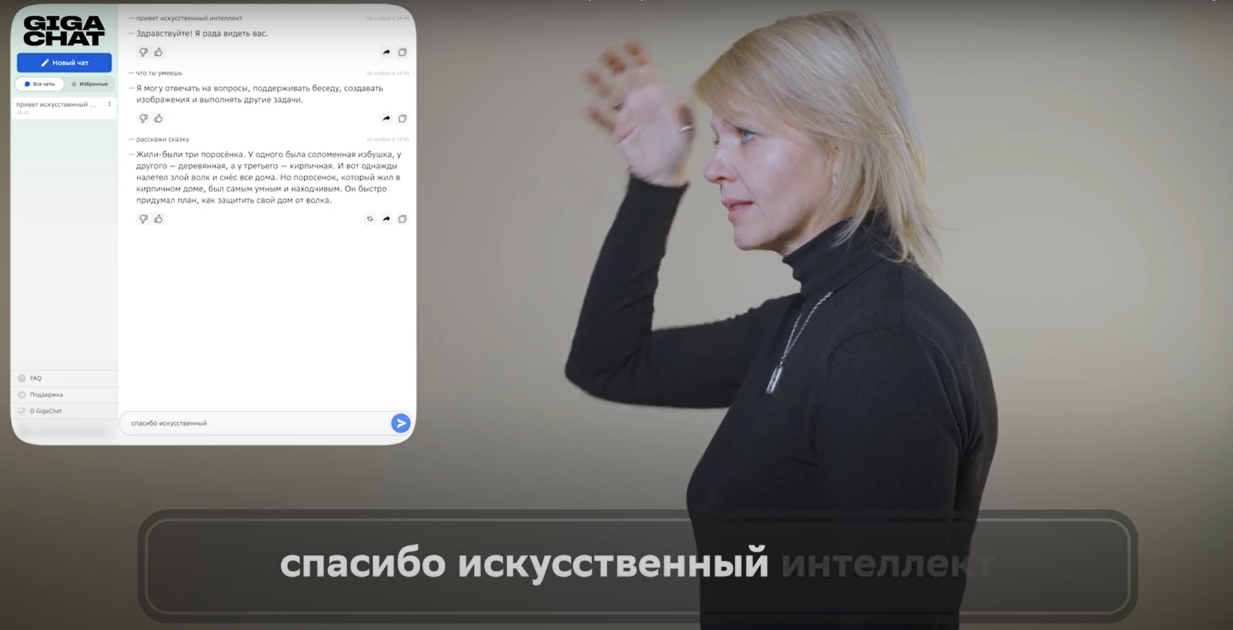
Рисунок 1 - Распознавание жестов РЖЯ с помощью GigaChat
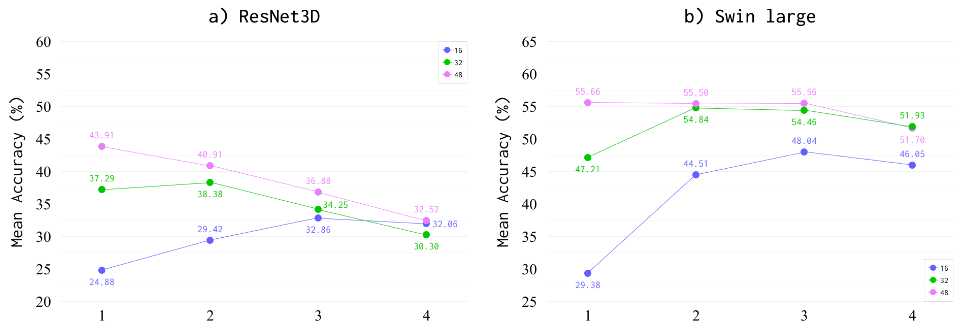
Рисунок 2 - Метрики для «ResNet3D» (a) и «Swin-large» (b)
Команда разработки из SberAI также представила свой вариант обученной модели искусственного интеллекта
.Отличительная особенность данного решения – использование более «легкой» ML-модели – «S3D», которая не требует столь больших вычислительных мощностей, что требуют «ResNet3D» и «Swin-large». По этой причине инференс модели в режиме реального времени не требует графического ускорителя – достаточно производительности центрального процессора (CPU).
По заявлению разработчиков, четырёхъядерного процессора достаточно для того, чтобы совершать 2-2,5 прогноза в секунду (рисунок 3). Этого более чем достаточно для задачи распознавания жестов в режиме реального времени.

Рисунок 3 - Распознавание жестов РЖЯ с помощью решения команды разработчиков из SberAI
Таблица 1 - Типы распознавания жестовых языков
Наименование модели | Кол-во входных кадров | Точность предсказания, % |
S3D | 32 | 44,22 |
S3D | 48 | 52,28 |
S3D | 64 | 55,86 |
3. Проектирование системы
Выбор модели искусственного интеллекта играет критическую роль в успешной разработке систем с использованием машинного обучения. Правильный выбор модели может существенно повлиять на результаты проекта по машинному обучению, включая точность прогнозов, скорость обучения, устойчивость к переобучению и масштабируемость системы.
Используемый нами инструментарий MMAction2
предлагает большой выбор моделей, предназначенных для распознавания действий. Для сравнения были выбраны модели, которые хорошо работают с разрешением 224 на 224 точки (именно в это разрешение будет преобразовываться входной поток данных), а также показывают хорошие результаты с обработкой 16 и 32 кадров по 2 и 3 каналам данных. Их сравнение приведено в таблице 2.Таблица 2 - Сравнение моделей искусственного интеллекта для распознавания действий
Наименование модели | Стратегия сэмплирования кадров | Разрешение | Скелет | top1/acc | top5/acc | FLOPS |
MViTv2 | 16x4x1 | 224x224 | MViTv2-S | 81,1 | 94,7 | 64G |
MViTv2 | 32x3x1 | 224x224 | MViTv2-B | 82,6 | 95,8 | 225G |
C2D | 16x4x1 | 224x224 | ResNet50 | 74,97 | 91,91 | 39G |
I3D | 32x2x1 | 224x224 | ResNet50 | 73,47 | 91,27 | 43.5G |
VideoSwin | 32x2x1 | 224x224 | Swin-T | 78,90 | 93,77 | 88G |
VideoSwin | 32x2x1 | 224x224 | Swin-S | 80,54 | 94,46 | 166G |
VideoSwin | 32x2x1 | 224x224 | Swin-B | 80,57 | 94,49 | 282G |
Исходя из представленных данных, для наших целей лучше всего подойдет модель искусственного интеллекта «MViTv2» с архитектурой «small», поскольку она находится на втором месте по точности предсказания класса и не сильно отстает от первого места, и при этом требует в разы меньше вычислительных мощностей, по сравнению с моделью «MViTv2» с архитектурой «base»
.Высокое качество обучающей и тестовой выборки критически важно для успешного обучения и получения высоких метрик модели искусственного интеллекта. По этой причине было принято решение не пытаться собрать свою выборку, а использовать уже готовую.
На данный момент в открытом доступе доступен лишь один датасет жестов русского жестового языка, собранный командой Vision RnD из SberDevices. Скачать его можно с репозитория GitHub «Slovo»
.Согласно данным команды SberDevices, им удалось собрать более 200 тысяч видео, которые разделены на 3 тысячи уникальных классов (т.е. 3 тысячи жестов). К сожалению, для скачивания доступны не все данные, а лишь 20400 видеозаписей, из которых 20000 означают какой-либо жест, а 400 – отсутствие жеста. Всего эти видеоданные содержат информацию о 1000 жестов, таким образом на каждый жест приходится 20 видео
.Датасет разбит на 2 выборки – обучающую и тренировочную. В тренировочную выборку входит 15300 видеозаписей, в обучающую – 5100.
Для сбора и разметки жестов русского жестового языка были использованы две компании: Yande.Toloka, которая записывала жесты на видео, и ABC Elementary, которая проводила сбор, валидацию и разметку жестов. Данный подход позволил повысить качество конечных данных, поскольку использование двух компаний создает две непересекающиеся аудитории носителей русского жестового языка.
Таким образом, полный цикл сбора обучающей и тестовой выборки выглядит следующим образом:
1) выявление группы людей, владеющих РЖЯ;
2) получение необработанных видеоданных;
3) проверка качества полученных видеоданных, удаление дубликатов и видео с плохим качеством (низкая частота кадров и/или разрешение видео);
4) выявление участка видео, в котором показывается жест;
5) финальная подготовка данных.
Схематически цикл сбора данных показан на рисунке 4.
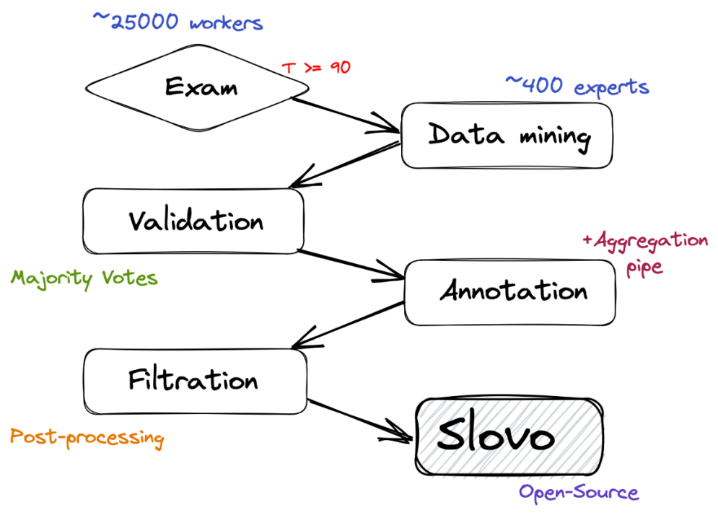
Рисунок 4 - Полный цикл сбора датасета
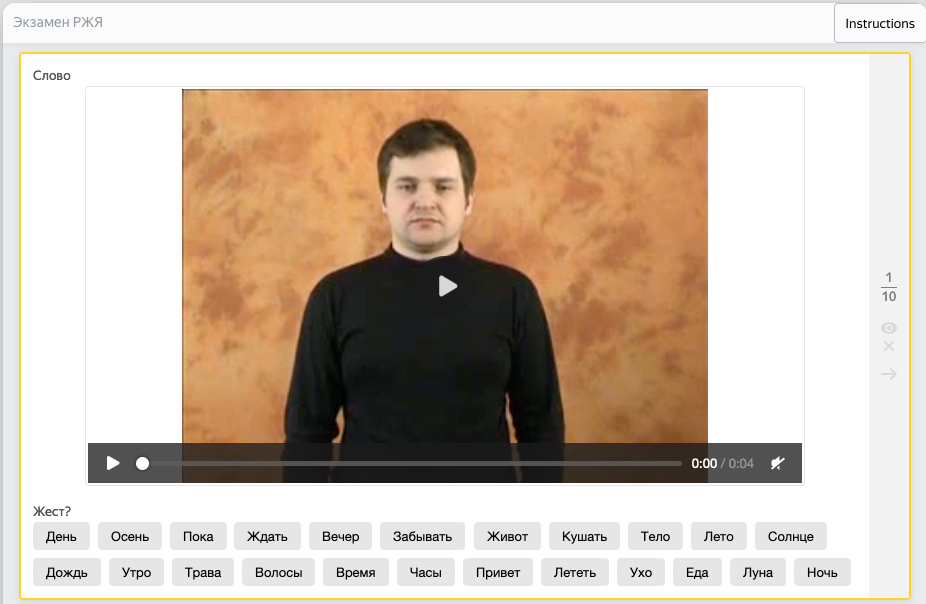
Рисунок 5 - Интерфейс экзаменационной системы
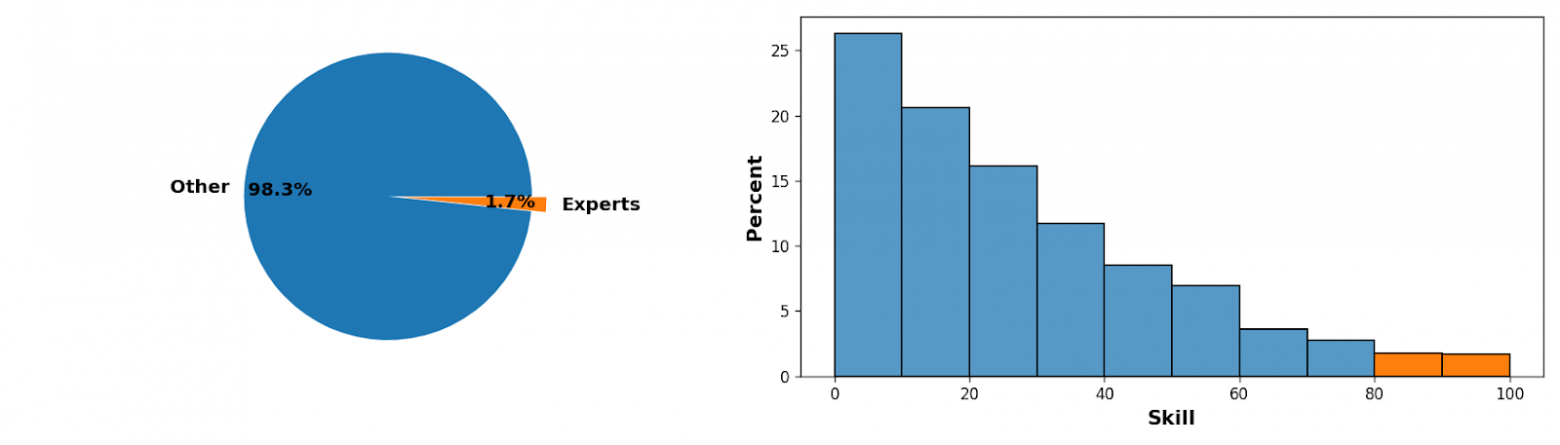
Рисунок 6 - Распределение результатов экзамена
В конечном итоге в данном этапе приняло участие около двухсот человек.
На этом этапе сбора данных экзаменуемые, получившие хорошую оценку по результатам экзамена, записывают видео с тем или иным жестом. Сбор данных также интуитивно понятен и прост – пользователю дается слово и пример жеста, который это слово означает. От пользователя требуется записать жест по аналогии и загрузить полученные данные на площадку по сбору данных.
Валидация – представляет собой проверку и отсеивание некачественных данных. Видеозаписи, полученные от пользователей, показываются отдельной группе людей, которые оценивают качество записи. Критерии оценки:
- камера стоит устойчиво, не трясется и не дрожит;
- жест выполнен верно;
- в процессе выполнения жеста руки не выходят за границы кадра.
Для повышения качества проверки происходил контроль за ответами пользователей, недобросовестных участников блокировали или временно отстраняли от выполнения задания. Помимо этого, видеоролики с низким разрешением (менее 320 точек по наименьшей стороне), низкой частотой развертки (менее 15 кадров в секунду) и слишком малой длительностью (менее секунды) удалялись и не подвергались проверке.
На этапе разметки пользователи определяли место начало и конца показываемого жеста. Для сравнения также давался шаблон правильного выполнения жеста. Записанные видео обрезаются по границам усредненной области, полученной от разных пользователей, и из этих данных формируется финальный датасет.
Заключительным этапом формирования выборки является фильтрация. Данный этап состоит из следующих этапов:
- убираются видео, неподходящие по параметрам (высота, ширина, кол-во кадров в секунду, длина);
- убираются сложные и составные жесты;
- слишком медленные видео ускоряются, а слишком быстрый – замедляются;
- данные разбиваются на обучающую и тестовую выборку.
Процесс сбора данных для обучения модели искусственного интеллекта завершен. Датасет в своем конечном виде представляет собой 2 папки «train» и «test», а также аннотационный файл, содержащий информацию о каждой видеозаписи. Первые строки аннотационного файла «annotations.csv» имеют вид, представленный в таблице 3.
Таблица 3 - Содержание аннотационного файла «annotations.csv»
| attachment_id | text | user_id | height | width | length | train | begin | end |
0 | 44e8d2a0-7e01-450b-90b0-beb7400d2c1e | Ё | 185bd3a81d9d618518d10abebf0d17a8 | 640 | 360 | 156.0 | True | 36 | 112 |
1 | df5b08f0-41d1-4572-889c-8b893e71069b | А | 185bd3a81d9d618518d10abebf0d17a8 | 640 | 360 | 150.0 | True | 36 | 76 |
2 | 17f53df4-c467-4aff-9f48-20687b63d49a | Р | 185bd3a81d9d618518d10abebf0d17a8 | 640 | 360 | 133.0 | True | 40 | 97 |
В таблице 3: attachment_id – название видеофайла; user_id – уникальный идентификатор пользователя, записавшего видео; width – ширина видео; height – высота видео; length – длина видео; text – обозначение жеста на русском жестовом языке; train – флаг обучающей или тестовой выборки; begin – начало жеста на оригинальном видео; end – конец жеста на оригинальном видео.
Поскольку обученную модель искусственного интеллекта будет необходимо выполнять в режиме реального времени, то немаловажным является время, затраченное на обработку входных параметров моделью искусственного интеллекта и получения результата на выходе. Помимо этого, важно, чтобы обученная модель могла выполняться на множестве различных платформ. Для этих целей идеально подходит ONNX Runtime
.ONNX Runtime – это кроссплатформенный движок для выполнения моделей искусственного, которые представлены в формате Open Neural Network Exchange (ONNX). Он предоставляет высокую производительность и оптимизирован для различных аппаратных платформ. ONNX Runtime позволяет эффективно выполнять модели искусственного интеллекта в различных сценариях, включая развертывание на мобильных устройствах, встраивание в приложения и облачные вычисления.
ONNX Runtime предлагает следующие преимущества:
- высокая производительность: он использует оптимизации для ускорения выполнения моделей искусственного интеллекта на различных аппаратных платформах, что обеспечивает быструю и эффективную работу моделей;
- кроссплатформенность: ONNX Runtime поддерживает различные операционные системы и аппаратные платформы, включая Windows, Linux, macOS, а также различные типы устройств, такие как CPU, GPU и специализированные ускорители моделей искусственного интеллекта TPU (Tensor Processing Units);
- гибкость: он предоставляет возможность выполнения моделей искусственного интеллекта, созданных с использованием различных фреймворков, таких как TensorFlow, PyTorch, Keras и др., что делает его удобным инструментом для интеграции различных моделей;
- оптимизации для ресурсов: ONNX Runtime может оптимизировать использование ресурсов, таких как память и процессорное время, что особенно важно для мобильных устройств и встроенных систем;
- простота использования: он предоставляет простой API для выполнения моделей, что делает его доступным для широкого круга разработчиков и специалистов по искусственному интеллекту.
4. Реализация проекта и тестирование разработанной системы
Для развертывания и тестирования системы была использована конфигурация персонального компьютера, приведенного в таблице 4. Данные характеристики не являются обязательными или оптимальными для использования системы распознавания и перевода жестов русского жестового языка, единственным необходимым критерием является наличие видеоадаптера компании NVIDIA, поддерживающего технологию NVIDIA CUDA . В противном случае обработка данных будет осуществляться посредством мощностей центрального процессора (CPU), что может отрицательно сказаться на производительности развернутой системы.
Таблица 4 - Технические сведения о системе, на которой производилось развертывание и тестирование системы распознавания и перевода жестов РЖЯ
Параметр | Значение |
Процессор | AMD Ryzen 5 5600x (6 core/12 threads) |
Оперативная память | 32 ГБ |
Дисковое пространство | 1024 ГБ NVME SSD |
Видеоадаптер | NVIDIA GeForce RTX 3070 Ti |
Средство видеосвязи (веб-камера) | Papalook PA552 PRO |
Операционная система | Windows 10 Pro 22H2 |
Для реализации системы для перевода невербального языка в лингвистическую модель необходимо установить используемые в исполняемых файлах библиотеки и модули, а также инструменты.
Поскольку система разрабатывается на языке программирования Python
, первоочередно нужно установить Python версии 3.9. В нижней части страницы выбираем и скачиванием установочный файл, соответствующий используемой операционной системе (в нашем случае «Windows x86-64 executable installer»).После установки необходимо проверить установленную версию Python. Для этого вводим в командную строку cmd следующую команду:
py --version
Рисунок 7 - Вызов утилиты «Выполнить» в ОС Windows 10
Рисунок 8 - Окно переменных среды Windows
pip install opencv-python
По аналогии с предыдущим шагом, устанавливаем следующие библиотеки:
- pandas 2.2.2;
- tqdm 4.66.4;
- matplotlib 3.9.0.
Команды для установки вышеперечисленных библиотек приведены в листинге 1.
Листинг 1. Команды для установки библиотек
::загрузка и установка библиотеки pandas 2.2.2
pip install pandas
::загрузка и установка библиотеки tqdm 4.66.4
pip install tqdm
::загрузка и установка библиотеки matplotlib 3.9.0
pip install matplotlib
Следующим шагом будет установка CUDA Toolkit. Для того, чтобы выбрать подходящую версию программного обеспечения CUDA Toolkit необходимо проверить поддержку CUDA установленного графического ускорителя. В нашем случае используется NVIDIA RTX 3070 Ti, который поддерживает как 11, так и 12 версию CUDA Toolkit. В процессе обучения и тестирования модели искусственного интеллекта было замечено несколько критических ошибок при использовании версии 12, которые приводили к остановке обучения и потере всего прогресса. При использовании версии 11 критических ошибок не возникало, по этой причине рекомендуется использовать CUDA Toolkit 11.8.
Рисунок 9 - Выбор платформы установки NVIDIA CUDA
Ранее мы установили CUDA версии 11.8, поэтому устанавливаем PyTorch с поддержкой CUDA версии 11.8, введя следующую команду в командную строку cmd:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
C помощью команд через командную строку устанавливаем следующие библиотеки (листинг 2):
- openmim 0.3.9;
- mmengine 0.10.4;
- mmcv 2.1.0.
Листинг 2. Команды для установки библиотек
::загрузка и установка библиотеки openmim 0.3.9
pip install -U openmim
::загрузка и установка библиотеки mmengine 0.10.4
mim install mmengine
::загрузка и установка библиотеки matplotlib mmcv 2.1.0
mim install mmcv==2.1.0
С установкой библиотек для работы с инструментами мы закончили, переходим к установке непосредственно самих инструментов. Ключевым в разработке системы является MMAction2 – инструмент с открытым исходным кодом для распознавания информации в видеоданных.
Для установки MMAction2 необходимо через командную строку перейти по пути, где в дальнейшем будут храниться файлы инструмента, используя команду «cd».
Для загрузки и установки необходимо ввести следующие команды:
git clone https://github.com/open-mmlab/mmaction2.git
cd mmaction2
pip install -v -e
Помимо MMAction2, используемого для обучения модели, нам понадобится MMDeploy – инструмент для развертывания моделей на различных платформах и устройствах.
Для загрузки и установки необходимо ввести следующие команды:
git clone -b main https://github.com/open-mmlab/mmdeploy.git
pip install mmdeploy
pip install mmdeploy-runtime-gpu
Последним шагом будет установка библиотек, необходимых для запуска демонстрационного приложения, также написанного на языке Python. Для этого необходимо установить следующие библиотеки:
- onnxruntime с поддержкой графических ускорителей;
- loguru;
- omegaconf.
Команды для установки библиотек приведены в листинге 3.
Листинг 3. Команды для установки библиотек
::загрузка и установка библиотеки onnxruntime с поддержкой gpu
pip install onnxruntime-gpu
::загрузка и установка библиотеки loguru
mim install loguru
::загрузка и установка библиотеки omegaconf
mim install omegaconf
Для обучения модели искусственного интеллекта необходимо создать 2 аннотационных файла, в которых будут указаны путь до данных, используемых в обучении и тестировании, а также соответствующие значения на выходе модели. Для этого создадим файл «create_anns.py», код которого рассмотрим далее.
Как уже было сказано ранее, код для разрабатываемой системы на основе искусственного интеллекта для перевода невербального языка в лингвистическую модель написан на языке программирования Python, поэтому код во всех дальнейших листингах приведен на языке программирования Python.
В первую очередь импортируем необходимые библиотеки (листинг 4).
Листинг 4. Код импортирования библиотек
import os
import cv2
import pandas as pd
from tqdm import tqdm
from glob import glob
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['figure.dpi'] = 300
plt.rcParams['savefig.dpi'] = 300
plt.rcParams.update({'font.size': 10})
Затем указываем директории расположения данных для обучения и тестирования, аннотации ко всем данным (листинг 5).
Листинг 5. Директории файлов
DATA_DIR = os.path.join(os.getcwd(), 'dataset')
TRAIN_DIR = os.path.join(DATA_DIR, 'train')
TEST_DIR = os.path.join(DATA_DIR, 'test')
ANNOTATIONS_DIR = os.path.join(DATA_DIR, 'annotations')
Получаем данные для обучения и для тестирования из директорий, записываем их в массив, а также сортируем (листинг 6).
Листинг 6. Заполнение массивов данных
ann = pd.read_csv(os.path.join(DATA_DIR, 'annotations.csv'), sep='\t')
ann.head()
train_files = sorted(glob(os.path.join(TRAIN_DIR, '*')))
test_files = sorted(glob(os.path.join(TEST_DIR, '*')))
Для проверки созданных массивов просмотрим первые файлы и визуализируем в виде покадровой развертки с шагом в 4 кадра (листинг 7). Так мы можем удостовериться, что для обучения модели будут использоваться правильные данные.
Листинг 7. Визуализация данных
train_sample = train_files[0]
test_sample = test_files[0]
def visualize_frames(video_path: str, title: str, num_frames=5):
fig, axes_list = plt.subplots(nrows=1, ncols=5, figsize=(10, 3))
vidcap = cv2.VideoCapture(video_path)
STEP = 4
for i in range(num_frames):
vidcap.set(cv2.CAP_PROP_POS_FRAMES, (i * STEP) - 1)
success, frame = vidcap.read()
if success:
axes_list[i].imshow(frame[:, :, ::-1])
axes_list[i].axis('off')
plt.suptitle(title,
x=0.05, y=1.0,
horizontalalignment='left',
fontweight='semibold',
fontsize='large')
plt.show()
visualize_frames(train_sample, 'Training sample')
visualize_frames(test_sample, 'Test sample')
Заключительным этапом будет обработка полученных на предыдущих этапах массивов данных для обучения и тестирования модели искусственного интеллекта и дальнейшее формирование аннотационных файлов для обучения и для тестирования (листинг 8).
Листинг 8. Обработка массивов и формирование аннотационных файлов
NUM_CLASSES = len(ann['text'].unique())
classes = {label: label_id for label, label_id in zip(ann['text'].unique(), range(NUM_CLASSES))}
ann_train = []
ann_test = []
print(type(ann))
for file in tqdm(train_files + test_files):
video_id = file.split('\\')[-1][:-4]
label = ann[ann['attachment_id'] == video_id]['text'].to_string(index=False)
class_id = classes[label]
line = file + ' ' + str(class_id) + '\n'
if ann[ann['attachment_id'] == video_id]['train'].bool():
ann_train.append(line)
else:
ann_test.append(line)
with open('ann_train.txt', 'w') as train_file, open('ann_test.txt', 'w') as test_file:
train_file.writelines(ann_train)
test_file.writelines(ann_test)
После выполнения Python-скрипта «create_anns.py» в текущей директории мы получим файлы «ann_train.txt» и «ann_test.txt», в которых записаны пути до видеоданных, и числовое значение показанного жеста.
На этом подготовка к обучению модели искусственного интеллекта заканчивается, далее приступаем непосредственно к обучению модели.
Обучение и тестирование модели искусственного интеллекта осуществляется с помощью рассмотренного ранее инструмента MMAction2. Для того чтобы приступить к обучению, необходимо создать конфигурационный файл на языке программирования Python. Для этого создадим файл «model_config.py», код которого рассмотрим далее.
В качестве модели искусственного интеллекта была выбрана модель «Improved Multiscale Vision Transformers for Classification and Detection» (MViTv2) с вариантом архитектуры «small». Для повышения значения метрик обученной модели было принято решение использовать предобученную модель (скелет) на обучающей выборке Kinetics400 с репозитория инструментария MMAction2. Для этого запишем в конфигурационный файл параметры, представленные в листинге 9.
Листинг 9. Конфигурация модели искусственного интеллекта
# Model settings
model = dict(
type='Recognizer3D',
backbone=dict(
type='MViT',
arch='small',
drop_path_rate=0.2,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://download.openmmlab.com/mmaction/v1.0/recognition/mvit/converted/mvit-small-p244_16x4x1_kinetics400-rgb_20221021-9ebaaeed.pth',
prefix='backbone.')),
data_preprocessor=dict(
type='ActionDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
format_shape='NCTHW'),
cls_head=dict(
type='MViTHead',
in_channels=768,
num_classes=1001,
label_smooth_eps=0.1,
average_clips='prob'))
Для того, чтобы контролировать процесс обучения модели, будем использовать журнал событий, куда будут записываться промежуточные результаты обучения модели, такие как потери, время итерации, скорость обучения, полученные метрики и другие. Для этого добавим в конфигурационный файл код, представленный в листинге 10.
В данном случае мы будем записывать следующую информацию во время обучения модели:
- номер эпохи обучения («Epoch»);
- номер итерации («Iter»);
- скорость обучения («lr»);
- среднее время вывода последней итерации («time»);
- среднее время загрузки данных последней итерации («data_time»);
- расчетное время прибытия для завершения обучения («eta»);
- усредненный результат потерь по модели за последнюю итерацию («loss»).
Помимо этого, мы будем сохранять информацию о каждых трех завершенных эпохах и будем сохранять контрольные точки, с которых можно будет продолжить обучение в случае возникновения критической ошибки.
Листинг 10. Конфигурация журнала событий
# Logging settings
default_scope = 'mmaction'
default_hooks = dict(
runtime_info=dict(type='RuntimeInfoHook'),
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=100, ignore_last=False),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(
type='CheckpointHook', interval=3, save_best='auto', max_keep_ckpts=5),
sampler_seed=dict(type='DistSamplerSeedHook'),
sync_buffers=dict(type='SyncBuffersHook'))
env_cfg = dict(
cudnn_benchmark=False,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
log_processor = dict(type='LogProcessor', window_size=20, by_epoch=True)
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='ActionVisualizer', vis_backends=[dict(type='LocalVisBackend')])
log_level = 'INFO'
load_from = None
resume = True
Следующим шагом будет конфигурирование входных данных для обучения модели искусственного интеллекта. Для этого укажем пути до аннотационных файлов, а также директории файлов для обучения и тестирования модели (листинг 11).
Листинг 11. Конфигурация путей
# Specify dataset paths
dataset_type = 'VideoDataset'
data_root = './dataset/train/'
data_root_val = './dataset/test/'
ann_file_train = './ann_train.txt'
ann_file_val = './ann_test.txt'
ann_file_test = './ann_test.txt'
Поскольку для обучения модели входные видеоданные преобразуются в так называемые «Sample Frames» (выборка отдельных кадров видеоизображения), необходимо сконфигурировать обработку и преобразование видеопотока в отдельные кадры, преобразованные в разрешение 224 на 224 точки.
В нашем случае мы имеем следующую конфигурацию:
- окно сэмплирования входных данных – 32;
- интервал между соседними кадрами выборки – 2;
- количество выбранных кадров между интервалами – 1;
- разрешение кадра (ширина и высота) – 224 на 224.
В качестве дополнительного параметра зададим горизонтальное отражение изображения, поскольку жесты можно показывать обеими руками. Итоговую конфигурацию обработки входных данных можно увидеть в листинге 12. Аналогичным путем сконфигурирована обработка данных для тестирования модели (листинг 13).
Листинг 12. Конфигурация обработки данных для обучения
train_pipeline = [
dict(type='DecordInit', io_backend='disk'),
dict(
type='SampleFrames',
clip_len=32,
frame_interval=2,
num_clips=1,
out_of_bound_opt='repeat_last'),
dict(type='DecordDecode'),
dict(type='Resize', scale=(224, 224), keep_ratio=False),
dict(type='Flip', flip_ratio=0.5, direction='horizontal'),
dict(type='FormatShape', input_format='NCTHW'),
dict(type='PackActionInputs')
Листинг 13. Конфигурация обработки данных для тестирования
train_pipeline = [
dict(type='DecordInit', io_backend='disk'),
dict(
type='SampleFrames',
clip_len=32,
frame_interval=2,
num_clips=1,
out_of_bound_opt='repeat_last'),
dict(type='DecordDecode'),
dict(type='Resize', scale=(224, 224), keep_ratio=False),
dict(type='Flip', flip_ratio=0.5, direction='horizontal'),
dict(type='FormatShape', input_format='NCTHW'),
dict(type='PackActionInputs')
Последний шаг – конфигурация параметров обучения. Для обучения модели мы задаем количество эпох обучения равное 15, и задаем в качестве вида сходимости градиентный клиппинг (параметр «тип оптимизатора» = «AdamW»). Конфигурация параметров обучения представлена в листинге 14.
Листинг 14. Конфигурация параметров обучения модели
# Training settigns
val_evaluator = dict(type='AccMetric')
test_evaluator = val_evaluator
train_cfg = dict(
type='EpochBasedTrainLoop', max_epochs=1, val_begin=15, val_interval=3)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
base_lr = 0.0016
optim_wrapper = dict(
optimizer=dict(
type='AdamW', lr=0.0016, betas=(0.9, 0.999), weight_decay=0.05),
paramwise_cfg=dict(norm_decay_mult=0.0, bias_decay_mult=0.0))
param_scheduler = [
dict(
type='LinearLR',
start_factor=0.1,
by_epoch=True,
begin=0,
end=15,
convert_to_iter_based=True)
]
auto_scale_lr = dict(enable=False, base_batch_size=64)
dist_params = dict(backend='nccl')
launcher = 'pytorch'
work_dir = 'work_dirs/mvit-slovo'
randomness = dict(seed=None, diff_rank_seed=False, deterministic=False)
После создания конфигурационного файла можно приступать к обучению модели искусственного интеллекта.
Тестирование модели искусственного интеллекта осуществляется с помощью рассмотренного ранее инструмента MMAction2. Для тестирования модели используется тот же самый конфигурационный файл, что и для обучения. После того, как модель искусственного интеллекта была обучена, необходимо
Для этого через командную строку необходимо перейти в директорию, в котором располагаются установленный ранее инструмент MMAction2 и конфигурационный файл для обучения модели. После этого необходимо вызвать Python-скрипт «test.py» из директории «./mmaction2/tools/» и в качестве первого аргумента передать конфигурационный файл «model_config.py», а в качестве второго аргумента передать файл обученной модели с расширением «PTH», расположенный в директории «./work_dirs/mvit-slovo/»:
py ./mmaction2/tools/test.py model_config.py best_acc_top1_epoch3.pth
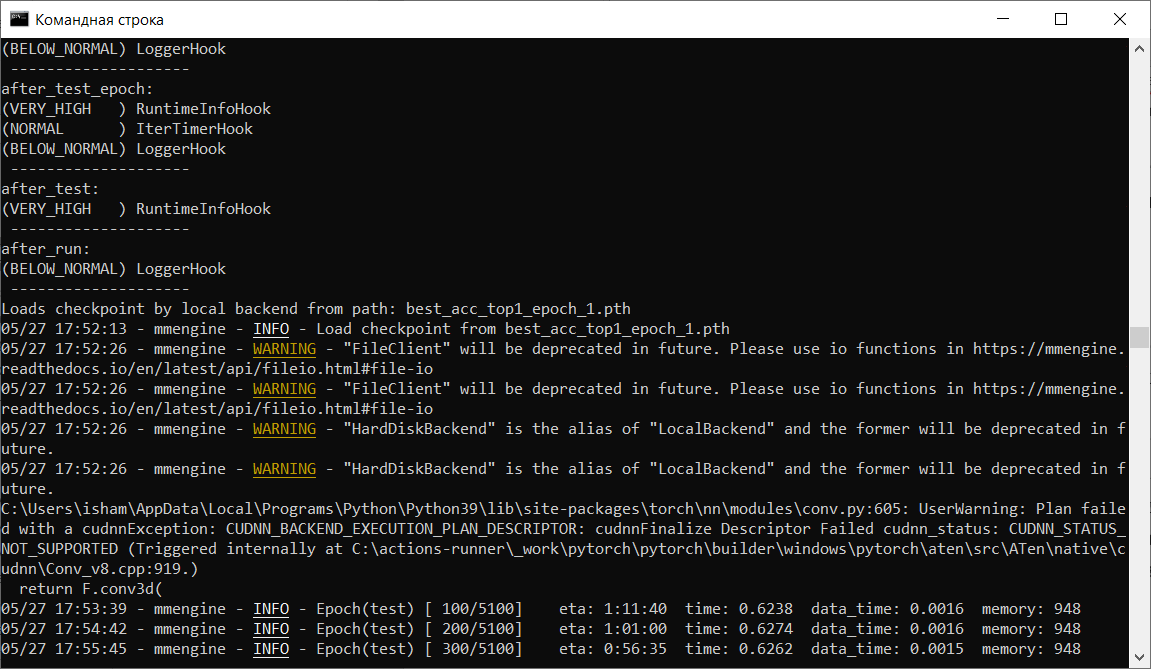
Рисунок 10 - Процесс тестирования модели ИИ
По окончании тестирования мы получаем метрики, которые характеризуют качество получившейся модели. Для дальнейшего сравнения за основу мы возьмем параметр «acc/mean1», что означает точность – долю правильных ответов алгоритма. В нашем случае по результатам тестирования мы получили значение в 0,6016, что соответствует 60,16% правильных ответов.
Для дальнейшего использования обученной модели искусственного интеллекта необходимо конвертировать ее из расширения «PTH» в расширение «ONNX», поскольку далее используемая нами библиотека ONNX Runtime поддерживает исключительно этот формат.
Для конвертации модели используется инструментарий MMDeploy. Необходимый нам Python-скрипт «deploy.py» расположен в директории «./mmdeploy/tools/». Для его работы необходимо передать в качестве аргументов следующие обязательные параметры:
- deploy_cfg (конфигурационный файл, описывающий во что происходит конвертирование);
- model_cfg (конфигурационный файл, описывающий модель искусственного интеллекта, которая была обучена ранее);
- checkpoint (непосредственно сама обученная модель с расширением «PTH»);
- img (файл, используемый для конвертации модели – представляет собой видеоданные, которые использовались для обучения или для тестирования обученной модели).
Таким образом, для конвертации модели необходимо ввести следующую команду в командную строку cmd:
py ./mmdeploy/tools/deploy.py ./mmdeploy/configs/mmaction/video-recognition/video-recognition_onnxruntime_static.py model_config.py best_acc_top1_epoch3.pth ./dataset/test/0000f6de-ba06-43fc-9cc7-3a93f4350b04.mp4
После окончания процесса конвертации в директории, из которой был вызван скрипт, появится модель искусственного интеллекта с наименованием «end2end.onnx», которая в дальнейшем будет использована в тестовом приложении. Для удобства переименуем ее в «mvit32-2.onnx».
Для оценки качества обученной модели искусственного интеллекта сравним точность прогнозируемых жестов с другими моделями, которые были рассмотрены в первой главе и также способны распознавать и переводить жесты русского жестового языка.
Для удобства сравнения поместим метрики обученных сетей в сводную таблицу и сделаем выводы (таблица 5). Обученная нами модель расположена вверху таблицы.
Таблица 5 - Сравнение точности прогнозируемых жестов
Наименование модели искусственного интеллекта | Точность прогнозируемых жестов (accuracy), % | Используемые вычислительные мощности |
MViTv2-small-32-2 (обученная нами модель) | 60,16 | GPU (NVIDIA CUDA) |
Swin-large-16-3 | 48,04 | GPU (NVIDIA CUDA) |
Swin-large-32-2 | 54,84 | GPU (NVIDIA CUDA) |
Swin-large-48-1 | 55,56 | GPU (NVIDIA CUDA) |
ResNet-i3d-16-3 | 32,86 | GPU (NVIDIA CUDA) |
ResNet-i3d-32-2 | 38,38 | GPU (NVIDIA CUDA) |
ResNet-i3d-48-1 | 43,91 | GPU (NVIDIA CUDA) |
S3D-32 | 44,22 | CPU |
S3D-48 | 52,28 | CPU |
S3D-64 | 55,86 | CPU |
На основании данных, представленных в таблице, можно сделать вывод, что обученная нами модель «MViTv2» с архитектурой «small» показывает наилучшую точность прогнозируемых жестов среди всех представленных моделей.
Но, несмотря на это, она имеет некоторые недостатки. Например, для хорошей производительности в режиме реального времени необходимо использовать графический ускоритель с технологией NVIDIA CUDA
, . В противном случае скорость обработки данных заметно увеличивается, что делает невозможным распознавание и перевод жестов с помощью обученной модели искусственного интеллекта в режиме реального времени.Для демонстрации обученной модели искусственного интеллекта
, , способного распознавать и переводить жесты, было разработано демонстрационное приложение на языке Python.Для запуска приложения необходимо запустить Python-скрипт из директории проекта, а также в качестве аргумента передать конфигурационный файл «config.yaml»:
py demo.py –p config.yaml
Следует отметить, что для работы приложения необходимо указать путь расположения обученной нами модели искусственного интеллекта с расширением «ONNX», а также параметр интервала кадров, который был выбран при обучении модели (в нашем случае равен двум). Поскольку ранее название модели было изменено на «mvit32-2.onnx», и при этом модель расположена в одной директории с исполняемым скриптом, то достаточно указать следующие параметры:
model_path: mvit32-2.onnx
frame_interval: 2
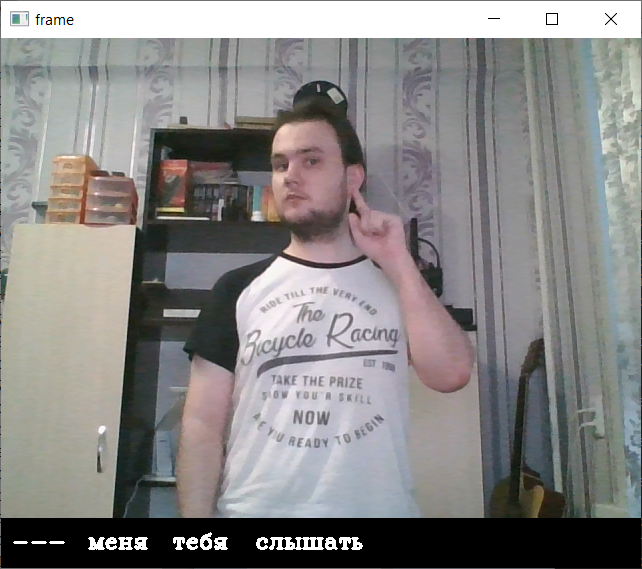
Рисунок 11 - Распознавание жеста «слышать»
5. Заключение
Подводя итоги проделанной работы, можно считать поставленную цель достигнутой: разработана информационная система на языке Python с использованием искусственного интеллекта , , позволяющая распознавать и переводить жесты русского жестового языка.
Результаты данного исследования имеют практическую значимость и вносят вклад в область создания программного обеспечения для распознавания жестовых языков с помощью современных моделей искусственного интеллекта. Разработанная система может распознавать и переводить жесты русского жестового языка в реальном времени, что позволяет улучшить качество коммуникации с людьми, способом коммуникации которых является использование жестового языка.
Помимо этого, результаты проделанной работы могут быть использованы для дальнейшего совершенствования распознавания русского жестового языка, используемого слабослышащими людьми, улучшения качества перевода невербального языка в вербальную модель.