Разработка гибридной рекомендательной системы для авиапассажиров
Разработка гибридной рекомендательной системы для авиапассажиров
Аннотация
Рассматриваются актуальные вопросы разработки и применения рекомендательных систем в сфере пассажирских авиаперевозок.
В качестве научной новизны проведенного исследования предлагается оригинальный гибридный подход, сочетающий коллаборативную фильтрацию, графовые модели и методы машинного обучения. Предложенный подход отличается от известных решений тем, что позволяет повысить точность прогнозов и релевантность предложений.
В качестве практической значимости проведенного исследования на основе предложенного оригинального подхода проведена реализация гибридной рекомендательной системы для авиапассажиров. Выполнено тестирование разработанной рекомендательной системы, которое показало корректность работы и эффективность ее применения. Программное обеспечение разработанной рекомендательной системы зарегистрировано в Роспатенте путем получения Свидетельства о государственной регистрации программы для ЭВМ
.Также описаны этапы разработки предложенной рекомендательной системы, описана разработка и реализация программного интерфейса (API) для интеграции рекомендательной системы с разработанным мобильным приложением для покупки и бронирования авиабилетов в составе автоматизированной системы обслуживания авиапассажиров
.Рассматриваются перспективы дальнейшего развития системы, включая оценку качества, использование методов глубокого обучения и расширение функциональности рекомендаций.
1. Введение
В современном мире рекомендательные системы на базе искусственного интеллекта играют все более значимую роль, предоставляя персонализированный контент и помогая пользователям ориентироваться в обилии доступных опций . В сфере авиаперелетов рекомендательные системы позволяют путешественникам находить наиболее подходящие варианты, облегчая выбор среди множества направлений . Для создания эффективных рекомендаций используются различные подходы и алгоритмы, такие как ассоциативные правила, метрики сходства (Lp-нормы, коэффициенты Оттаи, Пирсона и другие), фильтрации по контексту и др. , .
При этом эффективность систем повышается при одновременном использовании различных методов. Например, ассоциативные правила определяют общие шаблоны в данных, а метрики сходства персонализируют рекомендации. Это подтверждается практическими результатами, полученными крупными авиакомпаниями и сервисами по бронированию авиабилетов, такими как «S7 Airlines», «Booking.com», «Авиасейлс» , . Применение таких систем привело к значительному росту конверсии из просмотров в бронирования, а также упрощению планирования путешествий и разработке маршрутов.
В условиях быстрого развития информационных технологий и роста объемов данных перспективы рекомендательных систем в сфере авиаперелетов расширяются. В данной статье будет рассмотрена разработка оригинальной рекомендательной системы в сфере авиаперелетов на основе гибридного подхода, которая будет анализировать различные факторы: предпочтения пассажира, историю его путешествий, текущие сезонные тренды и многое другое. Такая система делает процесс выбора авианаправления более персонализированным и удовлетворяющим потребностям каждого пользователя.
2. Этапы разработки рекомендательной системы
Разработка эффективной рекомендательной системы включает в себя множество этапов. Рассмотрим общую схему взаимодействий между различными этапами системы, включая сбор данных, их обработку, обучение моделей и предоставление рекомендаций пользователям.
В отличие от существующих решений, в данной работе предлагается принципиально новый гибридный подход, основанный на оригинальной комбинации методов коллаборативной и контентной фильтрации, графовых моделей и машинного обучения. Основные этапы разработки системы представлены на рисунке 1.

Рисунок 1 - Этапы разработки рекомендательной системы
1. История просмотров городов: данные о том, какие города пользователи просматривали до этого в разработанном мобильном приложении для покупки и бронирования авиабилетов .
2. Покупки билетов: информация о купленных билетах, включая города отправления и назначения, даты.
3. Предварительные бронирования: данные о городах, на которые пользователи предварительно бронировали билеты.
4. Интересы пользователей: анкеты и профили пользователей, содержащие их предпочтения и интересы (например, пляжный отдых, исторические места и т.д.).
5. Сезонность: коэффициенты популярности городов в зависимости от текущего сезона.
6. Популярность: общие коэффициенты популярности городов.
Сбор данных осуществляется путем выполнения SQL-запросов к базе данных аэропорта.
На этапе машинного обучения были использованы различные модели для прогнозирования предпочтений пользователей.
1. Коллаборативная фильтрация: метод сингулярного разложения матрицы (SVD) для определения схожести между пользователями и городами.
2. Модель случайного леса: используется для прогнозирования вероятности выбора конкретного направления на основе профиля пользователя и его истории.
3. Линейная регрессия: объединяет результаты коллаборативной фильтрации и графовых моделей для создания финальной гибридной модели.
Графовые модели позволяют представить города и перелеты в виде ориентированного взвешенного графа.
1. Вершины представляют города, а дуги — вероятности перелетов между ними на основе предпочтений пользователя.
2. Алгоритм PageRank определяет ранжирование городов на основе вероятности посещения каждого города.
Гибридная модель объединяет результаты всех вышеуказанных моделей, выполняя следующие этапы.
1. Ранжирование городов осуществляется на основе коллаборативной фильтрации и модели случайного леса.
2. Смешивание результатов выполняется с помощью линейной регрессии, которая комбинирует результаты коллаборативной фильтрации, графовых моделей и модели случайного леса.
Взаимодействие рекомендательной системы с разработанным мобильным приложением для покупки и бронирования авиабилетов осуществляется через API. Оно обеспечивает:
- получение рекомендаций для конкретного пользователя, основанные на его профиле и активности;
- предоставление обновленной информации о пользователе и его предпочтениях.
Результаты коллаборативной фильтрации, графовых моделей и случайного леса комбинируются с помощью модели линейной регрессии для получения гибридной модели и определения финального рейтинга городов.
API рекомендаций выполняет следующие действия:
- предоставляет доступ к рекомендациям через HTTP-запросы для мобильного приложения;
- обновляет информацию о пользователях и сохраняет результаты рекомендаций в базу данных.
Разработанное мобильное приложение для покупки и бронирования авиабилетов взаимодействует с API рекомендаций следующим образом.
1. Запрос авторизации. Приложение отправляет запрос на авторизацию и получает JWT-токен для дальнейшей работы.
2. Получение рекомендаций. Приложение отправляет запрос с JWT-токеном для получения рекомендаций для конкретного пользователя.
3. API возвращает список городов, отсортированных по убыванию релевантности.
4. Приложение отображает полученные рекомендации в пользовательском интерфейсе.
5. Обновление данных пользователя. При изменении предпочтений или активности пользователя приложение отправляет обновленные данные на сервер.
3. Алгоритмы и модели рекомендаций
Рассмотрим подробнее алгоритмы и модели, заложенные в основу оригинальной рекомендательной системы для авиаперелетов. Система использует комбинацию нескольких методов, включая коллаборативную фильтрацию, графовые модели, машинное обучение. Это обеспечивает более точную и персонализированную выдачу рекомендаций для пользователей.
Коллаборативная фильтрация (Collaborative filtering) — это метод рекомендации, при котором анализируется только реакция пользователей на объекты: оценки, которые выставляют пользователи объектам , , . Оценки могут быть как явными (пользователь явно указывает, на сколько «звездочек» он оценивает объект), так и неявными (например, количество просмотров одного ролика). Чем больше оценок собирается, тем точнее получаются рекомендации. В нашем случае используются неявные оценки.
Получается, что пользователи помогают друг другу в фильтрации объектов. Поэтому такой метод называется также совместной фильтрацией.
В нашем случае используется метод сингулярного разложения матрицы (SVD), который позволяет выявить скрытые факторы предпочтений пользователей.
Создание рекомендательной системы производилось на языке программирования Python. Сначала формируется матрица взаимодействий «пассажир-город», где строки представляют пассажиров, а столбцы — города. Значения в ячейках отражают коэффициент взаимодействия пассажира с определенным городом (неявные оценки) на основе его активности (покупка билета добавляет 5 единиц, бронирование — 3, просмотр — 1).
Для построения модели коллаборативной фильтрации используется сингулярное разложение (SVD). Сначала выполняется разложение матрицы на три компонента: U, sigma и Vt. Затем вычисляются факторы пассажиров и городов. Ниже приведен листинг кода, в котором производятся данные шаги.
1from scipy.sparse.linalg import svds
2import numpy as np
3
4# Вычисление сингулярного разложения для коллаборативной фильтрации
5U, sigma, Vt = svds(passenger_city_matrix.to_numpy(), k=10)
6sigma = np.diаg(sigma)
7passenger_factors = U @ sigma
8city_factors = Vt.TС помощью полученных факторов можно прогнозировать предпочтения каждого пассажира к городам, например, с помощью функции, представленной в листинге ниже.
1# Функция для прогнозирования предпочтений пассажира к городам с использованием SVD
2def predict_city_preferences_svd(passenger_id):
3 passenger_idx = passenger_city_matrix.index.get_loc(passenger_id)
4 passenger_vector = passenger_factors[passenger_idx, :]
5 scores = passenger_vector @ city_factors.T
6 return pd.Series(scores, index=passenger_city_matrix.columns)
7
8# Предсказания на основе SVD
9svd_predictions = predict_city_preferences_svd (id_passenger).sort_values(ascending=False)Иллюстрацию работы алгоритма коллаборативной фильтрации можно увидеть на рисунке 2, который визуализирует процесс создания и разложения матрицы «пассажир-город» с помощью SVD.
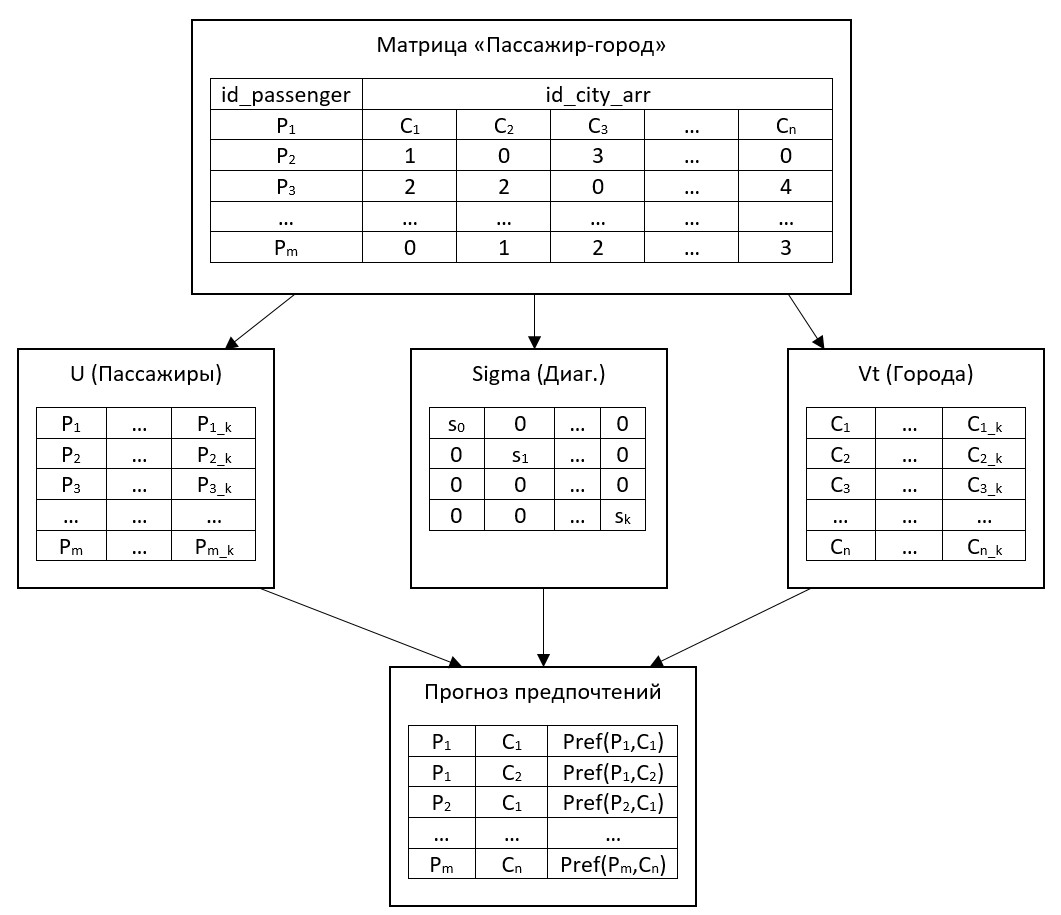
Рисунок 2 - Иллюстрация алгоритма коллаборативной фильтрации
В контексте рекомендательных систем, графовые модели используются для представления и анализа разнообразных данных, таких как социальные сети, пользовательские предпочтения, товарные каталоги и их взаимосвязи. Эти модели способствуют более глубокому пониманию структуры предпочтений и поведения пользователей, позволяя обнаруживать скрытые паттерны и предсказывать потенциальный интерес к определенным товарам или услугам.
В нашем случае графовые модели позволяют представить города и перелеты в виде ориентированного графа, где вершины — это города, а дуги — вероятности перелетов между ними. Веса дуг зависят от предпочтений пользователя и его активности.
Для каждого пассажира создается взвешенный ориентированный граф предпочтений. Вершины представляют города, а дуги – вероятности перелетов между ними, основываясь на профиле пользователя и его предыдущей активности. Листинг кода, осуществляющего создание такого графа, представлен ниже.
1import networkx as nx
2
3graphs = {}
4
5for id_passenger in data['id_passenger'].unique():
6 G = nx.DiGraph()
7 G.add_nodes_from(all_cities)
8
9 passenger_data = data[(data['id_passenger'] == id_passenger)].iloc[[0]]
10
11 # Добавление дуг с весами
12 for city_departure in all_cities:
13 for city_arrival in all_cities:
14 if city_departure == city_arrival:
15 continue
16
17 G.add_edge(city_departure, city_arrival, weight=coeff)
18 graphs[id_passenger] = GДля ранжирования городов в графе предпочтений используется алгоритм PageRank. Он определяет вероятность посещения каждого города на основе случайных блужданий. Идея алгоритма заключается в определении важности веб-страницы, исходя из количества и качества ссылок на нее . Если важная страница ссылается на другую страницу, то последняя также считается важной. Аналогично, в нашем случае PageRank используется для ранжирования городов в графе предпочтений пассажиров.
Для ранжирования городов в графах предпочтений применялся алгоритм PageRank, реализованный в библиотеке networkx. Алгоритм вычисляет для каждого города значение PageRank, отражающее его «важность» в графе, что интерпретируется как вероятность посещения города. Параметр alpha=0.85 задает коэффициент демпфирования. Результаты PageRank, представляющие собой словарь «город-значение», сортируются по убыванию значения для получения ранжированного списка городов.
Упрощенно созданный граф можно представить на рисунке 3. На нем изображено в качестве узлов 3 города (C1, C2 и C3), а также дуги, представляющие вероятность перехода из одного города в другой, веса которых высчитываются для каждого пассажира отдельно с использованием модели случайного леса. Также в каждом узле определен PageRank. Как можно заметить, наименее релевантным городом в данном графе является C3.
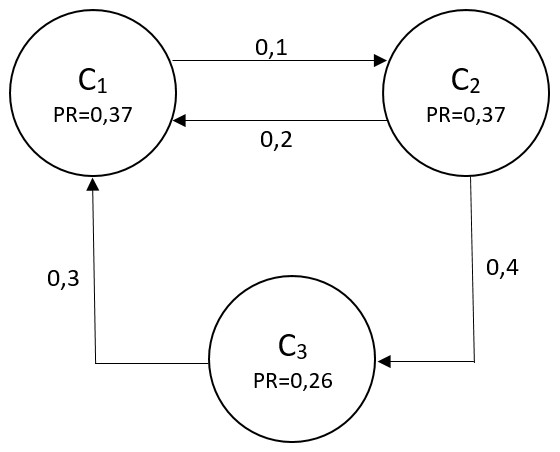
Рисунок 3 - Иллюстрация графовой модели
В контексте рекомендательных систем, случайный лес может использоваться для прогнозирования интересов пользователя, базируясь на его профиле и истории взаимодействий . В нашем случае модель обучается на данных о пассажирах и их предпочтениях относительно различных городов и типов отдыха. Так как города являются категориальными признаками, то для них сначала применяется кодирование по принципу One-hot.
Помимо используемого в работе метода случайного леса в современной научной литературе также рассматриваются альтернативные методы прогнозирования предпочтений пользователей на основе популяционных алгоритмов .
Для прогнозирования коэффициента предпочтения города была использована модель случайного леса, реализованная в библиотеке scikit-learn (класс RandomForestRegressor). Модель была обучена на подготовленных данных признаков и целевой переменной. Для каждого пассажира были сформированы входные данные (input_data), соответствующие его характеристикам и закодированным городам, и выполнен прогноз с помощью обученной модели (RandomForestRegressor.predict(...)).
Гибридная модель объединяет результаты коллаборативной фильтрации, графовых моделей и машинного обучения для формирования финальных рекомендаций, используя модель линейной регрессии из библиотеки scikit-learn (класс LinearRegression). Модель была обучена на наборе данных, где входными признаками (X_train) выступали оценки, полученные методами и алгоритмами PageRank, коллаборативной фильтрации (SVD) и случайного леса, а целевой переменной (y_train) — финальный коэффициент предпочтения. После обучения модель использовалась для прогнозирования итогового коэффициента (predicted_coeff), комбинируя оценки от различных моделей.
После прогнозирования предпочтений результаты сохраняются в базу данных для последующего использования в API рекомендаций.
После того как все данные обработаны, и рекомендации добавлены в базу данных, следующим шагом является создание API для предоставления этих рекомендаций пользователям через мобильное приложение.
Данное приложение представляет собой удобный и простой в использовании инструмент для покупки или бронирования авиабилетов на определенные рейсы. Пользователи могут просматривать подробную информацию о рейсах, включая дату и время вылета и прилета, количество свободных мест, цену, тип самолета и многое другое. Приложение позволяет легко и быстро оформить бронирование или покупку билетов прямо с мобильного устройства, предоставляя также возможность повторного использования данных пассажиров, изменения информации о пассажире или покупателе, выкупа или снятия брони, а также возврата билетов.
Для реализации API используется контроллер в ASP.NET MVC, который обращается к базе данных, где хранятся рекомендации, и возвращает список городов, отсортированных по убыванию коэффициента (листинг представлен ниже).
1// GET: Cities/Recommendations
2[HttpGet]
3public ActionResult Recommendations(int id_passenger, int n = 3)
4{
5 var recommendations = db.Recomendation
6 .Where(r => r.id_passenger == id_passenger)
7 .OrderByDescending(r => r.coeff)
8 .Take(n)
9 .Select(r => r.City.name_city)
10 .ToList();
11
12 if (recommendations.Count == 0)
13 {
14 // Список городов по умолчанию, если рекомендации не найдены
15 recommendations = new List<string> { "Москва", "Пенза", "Санкт-Петербург" };
16 }
17
18 return Json(recommendations, JsonRequestBehavior.AllowGet);
19}Мобильное приложение взаимодействует с API, отправляя запросы на получение рекомендаций для конкретного пользователя.
Пример кода реализации запроса рекомендаций в мобильном приложении представлен ниже.
1public static async Task<List<string>> GetRecommendationsAsync(int id_passenger, int n)
2{
3 // Получение jwt-токена
4 var token = await SecureStorage.GetAsync("jwt_token");
5 Client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", token);
6
7 // Отправка GET-запроса и обработка ответа
8 var response = await Client.GetAsync(url + $"Cities/Recommendations?id_passenger={id_passenger}&n={n}");
9 if (response.IsSuccessStatusCode)
10 {
11 string responseText = await response.Content.ReadAsStringAsync();
12 List<string> recommendations = JsonConvert.DeserializeObject<List<string>>(responseText);
13 return recommendations;
14 }
15 else
16 {
17 return new List<string>();
18 }
19}В контексте аппаратной реализации рекомендательной системы и API, представляющим собой связующее звено между серверной частью и мобильным приложением, стоит отметить возможность использования встраиваемых решений .
Было проведено тестирование разработанной рекомендательной системы. Примеры вывода рекомендованных авианаправлений из мобильного приложения представлены на рисунках 4 и 5. В первом случае пассажир периодически летает в Сочи и Пензу, поэтому ему предлагают данные направления. Но также он бывал несколько раз в Нижнем Новгороде. А так как помимо этого в его профиле указано, что он имеет высокую оценку предпочтения исторических мест, то ему также предлагается посетить Ереван, в котором он ни разу не был.
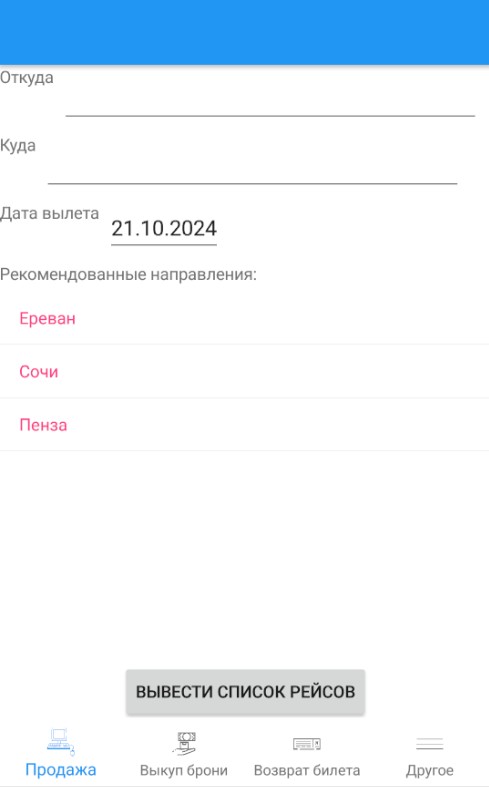
Рисунок 4 - Пример вывода рекомендованных авианаправлений для пассажира 1
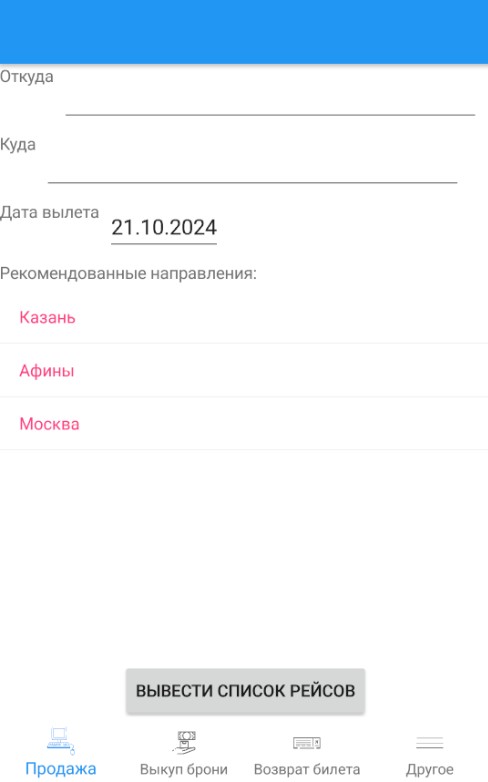
Рисунок 5 - Пример вывода рекомендованных авианаправлений для пассажира 2
4. Заключение
Были рассмотрены актуальные вопросы разработки и использования рекомендательных систем в сфере пассажирских авиаперевозок.
Научной новизной проведенного исследования является предложенный оригинальный гибридный подход, сочетающий в себе применение коллаборативной фильтрации, графовых моделей и методов машинного обучения. Предложенный подход отличается от известных решений тем, что позволяет повысить точность прогнозов и релевантность предложений.
Практическая значимость проведенного исследования заключается в том, что на основе предложенного оригинального подхода была разработана и реализована гибридная рекомендательная система для авиапассажиров, а также выполнено тестирование разработанной рекомендательной системы, которое показало корректность работы и эффективность ее применения. На программное обеспечение разработанной рекомендательной системы получено Свидетельство о государственной регистрации программы для ЭВМ .
Были описаны этапы разработки предложенной рекомендательной системы, описана разработка и реализация программного интерфейса (API) для интеграции предложенной рекомендательной системы с разработанным мобильным приложением для покупки и бронирования авиабилетов в составе комплексной автоматизированной системы обслуживания авиапассажиров.
Хотя текущая реализация рекомендательной системы уже дает хорошие результаты, есть несколько направлений для дальнейшего ее улучшения и развития.
1. Тестирование и оценка качества на реальных данных. Проведение тестирования и оценки качества рекомендательной системы на реальных данных для определения релевантности рекомендаций.
2. Улучшение точности рекомендаций. Использование глубокого обучения: рекуррентных нейронных сетей (RNN) и сверточных нейронных сетей (CNN) для более точного прогнозирования предпочтений.
3. Расширение функциональности и интеграция с другими сервисами. Добавление рекомендаций не только направлений, но и событий в выбранных городах, например, концертов, фестивалей или спортивных мероприятий. Формирование пакетных туров, включающих билеты, проживание, экскурсии и другие услуги.
4. Персонализация интерфейса. Адаптация интерфейса под предпочтения пользователя, отображение наиболее релевантной информации.
5. Интерактивные опросы. Проведение опросов и сбор обратной связи от пользователей для улучшения качества рекомендаций.
6. Оптимизация производительности. Использование технологий параллельной обработки данных для ускорения обучения моделей.