ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИИ DATA MINING ДЛЯ ВЫЯВЛЕНИЯ ГРУПП ОБЪЕКТОВ ОДНОРОДНЫХ ПО ТИПУ ФУНКЦИОНАЛЬНОЙ СВЯЗИ

Носовец Е.К.
Аспирант, Национальный технический университет Украины «КПИ»
ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИИ DATA MINING ДЛЯ ВЫЯВЛЕНИЯ ГРУПП ОБЪЕКТОВ ОДНОРОДНЫХ ПО ТИПУ ФУНКЦИОНАЛЬНОЙ СВЯЗИ
Аннотация В статье рассмотрены возможности основных методов Data Mining на предмет их использования для выявления однородных по типу функциональной связи кластеров. Применение данных методов при анализе медико-биологических данных позволяет создавать целостное представление о различных системах организма человека путем математического моделирования на основе надежных физиологических характеристик, отражающих взаимосвязи различных показателей.
Ключевые слова: кластеризация, моделирование, функциональная связь.
Nosovets E.K.
Postgraduate student, National Technical University of Ukraine "KPI"
USING METHODS OF DATA MINING TO DETERMINE GROUP HOMOGENEOUS BY TYPE OF FUNCTIONAL CONNECTION
Abstract The possibilities of Data Mining main methods for their use to identify cluster with homogeneous functional connection was analyzed. The use of these methods in the analysis of biomedical data allows to create a holistic view of the various systems of the human body by mathematical modeling based on reliable physiological characteristics that reflect the relationship of various indicators.
Keywords: clustering, modeling, functional relationship.
Математическое моделирование процессов в организме человека должны базироваться на надежных физиологических характеристиках, отражающих взаимосвязи показателей в различных системах. Именно поэтому актуальным остается поиск критериев нормального функционирования целостных систем, которые должны отображать гармонию иерархической взаимодействия ее составляющих. Кроме того, наличие достоверной эмпирической информации о поведении систем в условиях различных воздействий может дать углубленное понимание сущности процессов на каждом иерархическом уровне регуляции и выяснить, чем вызваны наблюдаемые колебания интегральных показателей, то есть их иерархические взаимодействия.
На сегодняшний день, подход, когда основой классификации является тип функциональной связи между показателями, почти не используется в исследованиях сложных объектов биологической и медицинской природы вследствие его низкой развитости. Чаще исследователи пытаются создать группы наблюдений, показатели которых имеют единый вид функциональной связи между собой, или наличие такой связи постулируется априори, или совсем не принимается во внимание.
Ожидаемую способность к разделению количественных данных по типу функциональной связи между ними среди средств Data Mining имеют прежде всего методы кластерного анализа. Так как присоединение друг к другу ближайших объектов вызывает постепенное перемещение центров кластеров в признаковом пространстве, то есть отображает изменение связи между показателями. Они являются наиболее интересными для применения, если классами являются функциональные зависимости между показателями и нужно воспроизвести эти зависимости из массивов наблюдений.
Поэтому мы сочли целесообразным исследовать возможности методов кластеризации на пригодность для выявления эмпирических закономерностей в виде различных функциональных зависимостей между показателями сложных систем, и применить полученные результаты для изучения системы кровообращения человека.
Материалы и методы. Исходным клиническим материалом для исследования физиологических закономерностей были результаты обследования 105 больных (приобретенные пороки сердца и ишемическая болезнь сердца) и 15 относительно здоровых людей. Возраст больных составлял от 17 до 76 (49 +16) лет.
Массивы данных содержали последовательные наблюдения, которые были накоплены в ходе планового лечебного процесса, т.е. были получены не с постановкой каких-либо конкретных исследовательских задач.
Данные были использованы для изучения регуляции кровообращения, путем исследования взаимосвязи между диастолическим (АДд) и систолическим (АДс) артериальным давлением.
Для проведения кластерного анализа методами иерархический и к-средних был использован пакет статистической обработки информации IBM SPSS Statistics 21.0, пакет MatLab R2009b применялся для реализации остальных представленных в работе методов.
Иерархические алгоритмы. Методы данной группы [1] основаны на построении минимального покрывающего дерева, объединяющего все объекты в виде дендрограммы. В процессе кластеризации по критерию минимального локального расстояния в мелкие кластеры сначала объединяются ближайшие друг к другу объекты. Далее эти кластеры объединяются во все большие, пока не будет образовано единое покрывающие дерево. После окончания процедуры некоторым способом осуществляется разбиение дерева на кластеры. Наиболее употребляемым является разбиение кластеров по максимальным ребрам (Вроцлавский классификация). В результате образуется некоторая группа кластеров.
Результат применения иерархической кластеризации на тестовой выборке представлен на рис. 1.

Рис. 1 - Результат применения иерархической кластеризации
Кластеры, полученные в результате иерархической кластеризации, имеют эллипсоидную форму. Корреляция АДс и АДд внутри образованных кластеров колебалась в пределах 0,221 до 0,418, что свидетельствует о наличии взаимосвязи между изучаемыми показателями, однако способности данного метода к распознаванию кластеров однородных по типу функциональной связи не достаточны.
Неиерархические алгоритмы. Рассмотрен метод "k - средних" [2]. Метод является вариантом дивизивной стратегии. Некоторым образом в признаковом пространстве выбираются начальные центры кластеризации. Затем к ним по критерию минимальной локальной расстоянии присоединяются ближайшие объекты. Далее процедура повторяется до тех пор, пока координаты центров кластера стабилизируются и объекты не перестанут переходить из одного кластера в другой. Таким образом формируются сферические кластеры, в которых расстояния объектов центра кластера меньше, чем расстояния до центров других кластеров.
Однократное (в один проход) применение метода «k-средних» для взаимно коррелированных показателей приводило к смещению центра кластера вдоль направления тренда и фактически приводило к распознаванию, воспроизведение его фрагментов. Однако, при этом подвижность центров кластеров в пространстве признаков постепенно снижалась вследствие накопления наблюдений и рост массы, а, соответственно, и инерционности кластеров.
Результат применения метода "k-средних" (один проход) на тестовой выборке представлен на рис. 2.
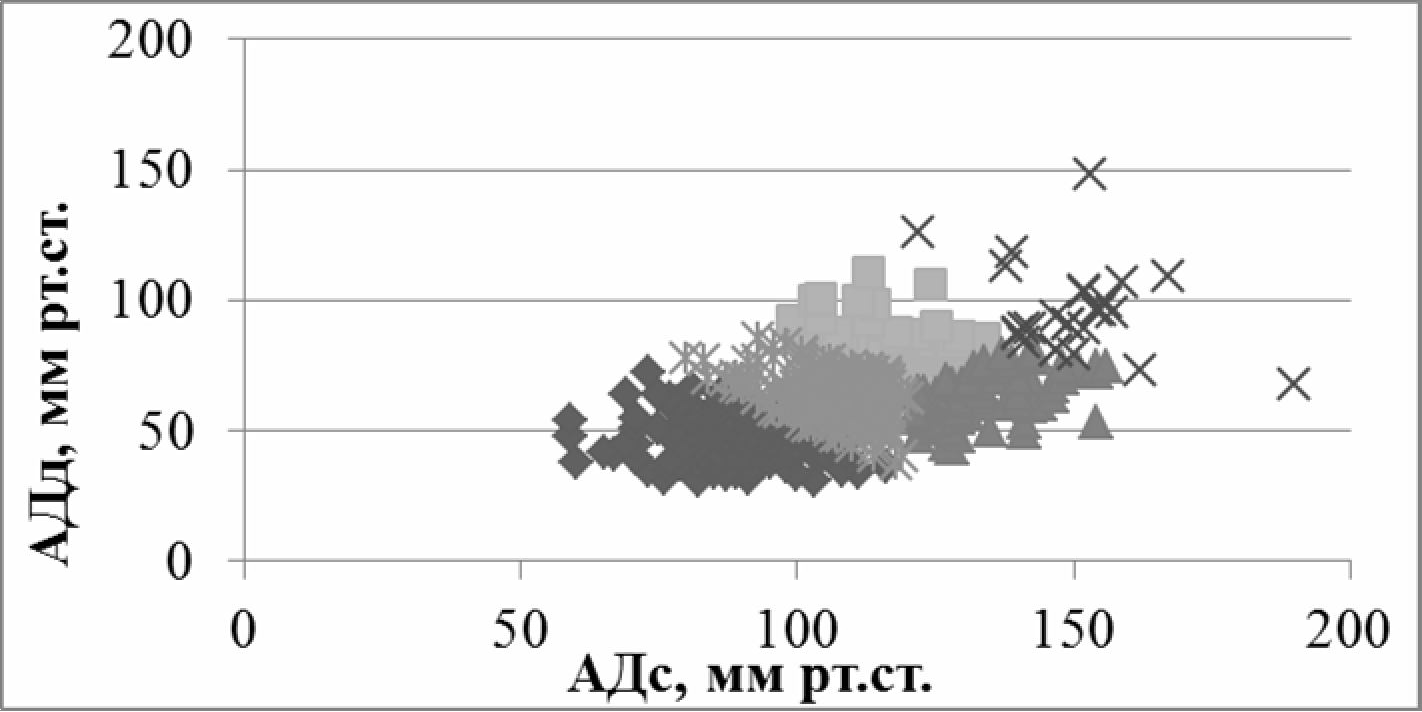
Рис. 2 - Результат применения кластеризации методом "k - средних"
Как видно из рис. 2, образованные кластеры имеют форму близкую к сферической, с корреляцией между признаками в пределах от 0,18 до 0,31. Результаты тестирования показали низкие результаты к распознаванию кластеров однородных по типу функциональной связи.
Алгоритмы нечеткой кластеризации. Алгоритм нечеткой кластеризации называют FCM-алгоритмом (Fuzzy Classifier Means, Fuzzy C-Means) [3]. Целью FCM-алгоритма кластеризации является автоматическая классификация множества объектов, которые задаются векторами признаков в пространстве признаков. Кластеры представляются нечеткими множествами, и, кроме того, границы между кластерами также являются нечеткими.
Результат применения метода Fuzzy C-Means на тестовой выборке был практически идентичен результатам полученным при применении метода однопроходного "k-средних".
Алгоритмы основанные на плотности. Рассмотрен алгоритм DBSCAN [3], плотностный алгоритм для кластеризации пространственных данных с присутствием шума. Идея, положенная в основу алгоритма, заключается в том, что внутри каждого кластера наблюдается типичная плотность точек (объектов), которая заметно выше, чем плотность снаружи кластера, а также плотность в областях с шумом ниже плотности любого из кластеров.
Результат применения метода DBSCAN на тестовой выборке представлен на рис. 3.
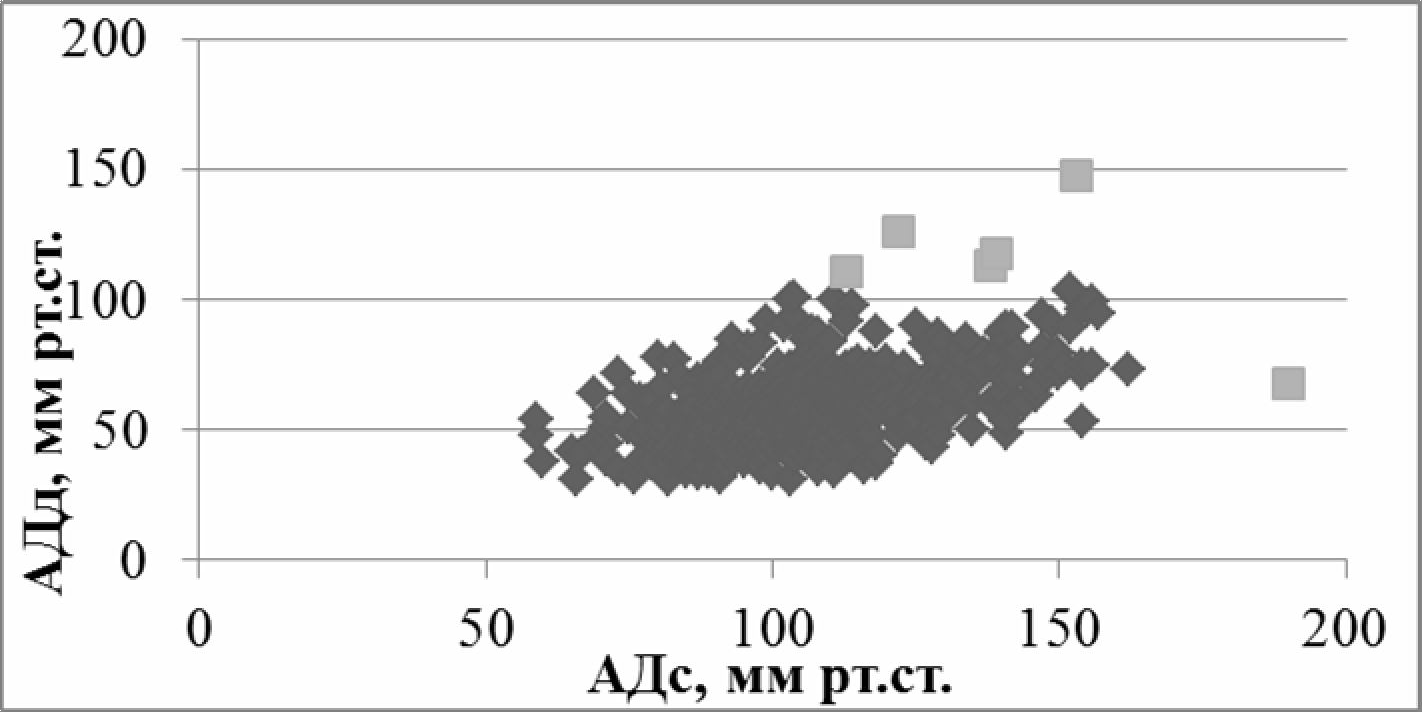
Рис. 3 - Результат применения кластеризации методом DBSCAN
Алгоритм functional separation был разработан в НИССХ им. Амосова. Являясь модификацией метода "k-средних" он, благодаря использованию так называемого «цепочечного» эффекта [4] позволяет воссоздать взаимосвязи показателей сложных систем.
Результат применения метода functional separation на тестовой выборке представлен на рис. 4.

Рис. 4 - Результат применения кластеризации методом functional separation
Данный метод позволил выделить кластеры вытянутой формы, внутри которых четко прослеживается функциональная связь. Коэффициент линейной корреляции между показателями АДс и АДд колебался в пределах от 0,89 до 0,92. Более того, детальное исследование показало, что данные кластеры содержат в себе показатели характерные для нормальной либо патологической (артериальная гипертензия и недостаточность кровообращения разных степеней) регуляции кровообращения.
Выводы. Задача разбиения группы объектов на однородные по типу функциональной связи является актуальной, поскольку позволяет по новому оценить взаимосвязи внутри биологических систем. Исследование существующих методов Data Mining показало, что наиболее высокие результаты показал метод functional separation. Результаты, полученные после применения данного метода могут быть использованы для разработки метода диагностики патологических состояний как внутри системы кровообращения, так и в организме человека в целом.
Список литературы
Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, — 345 с.
Мандель И.Д. Кластерный анализ. - М.: Финансы и статистика. - 176 с.
Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб. пособие / Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. — М.: МИЭМ, 2011. — 272 с.
Knyshov, Ye. Nastenko, V. Maksymenko, O. Kravchuk, and Yu. Shardukova The Interactions between Arterial and Capillary Flow. Cellular Automaton Simulations of Qualitative Peculiarities O. Dossel and . W C. Schlegel (Eds.): WC 2009, IFMBE Proceedings 25/IV, pp. 572–574, 2009.
Список литературы
Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, — 345 с.
Мандель И.Д. Кластерный анализ. - М.: Финансы и статистика. - 176 с.
Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб. пособие / Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. — М.: МИЭМ, 2011. — 272 с.
Knyshov, Ye. Nastenko, V. Maksymenko, O. Kravchuk, and Yu. Shardukova The Interactions between Arterial and Capillary Flow. Cellular Automaton Simulations of Qualitative Peculiarities O. Dossel and . W C. Schlegel (Eds.): WC 2009, IFMBE Proceedings 25/IV, pp. 572–574, 2009.