Многозадачное регрессионное обучение для цифрового фенотипирования растений на основе байесовского взвешивания неопределённостей и биологических априорных знаний
Многозадачное регрессионное обучение для цифрового фенотипирования растений на основе байесовского взвешивания неопределённостей и биологических априорных знаний

Аннотация
Работа посвящена решению задачи одновременного количественного анализа комплекса морфологических признаков сельскохозяйственных культур на основе изображений с использованием методов глубокого обучения. Основной проблемой многозадачного регрессионного обучения в биологических приложениях является гетероскедастичность данных и конфликт градиентов задач разной природы, что затрудняет ручную настройку весовых коэффициентов функции потерь.
В статье исследуется применение и адаптация механизмов байесовской аппроксимации гомоскедастической неопределенности для автоматического взвешивания задач в рамках единой нейросетевой архитектуры. В качестве целевого функционала использована модифицированная функция отрицательного логарифма правдоподобия (Gaussian Negative Log-Likelihood), в которой параметры неопределённости σ (sigma) для каждой задачи являются обучаемыми. Экспериментальная проверка адаптируемого подхода проведена на выборке изображений растений риса (93 культивара, 9700 объектов) с использованием архитектуры EfficientNet-B0.
Результаты численных экспериментов подтвердили эффективность реализованной архитектуры и её превосходство над моделью с фиксированными весовыми коэффициентами функции потерь. Полученные значения общего коэффициента детерминации (R2 > 0.65) подтверждают высокую обобщающую способность модели. Установлено, что динамическая адаптация параметров σ позволяет эффективно балансировать вклад задач с различным уровнем информационной неопределённости. Это особенно важно для таких параметров, как высота растения (CulmH) и количество зёрен (GN), где наблюдается высокая статистическая вариативность и возможны проекционные искажения при двумерной визуализации трёхмерных структур. Разработанная модель может быть интегрирована в автоматизированные системы цифрового мониторинга агроэкосистем.
1. Введение
В условиях современных вызовов глобальной продовольственной безопасности и необходимости устойчивого развития сельского хозяйства, ускорение селекционных программ и оптимизация агротехнологий приобретают первостепенное значение. Одним из факторов в достижении этих целей является эффективное и масштабное фенотипирование — количественная оценка морфологических, физиологических и продуктивных признаков растений
. Традиционные методы, основанные на ручных измерениях, являются трудоёмкими, медленными и субъективными, что существенно ограничивает исследования в области селекции. Переход к цифровому фенотипированию с использованием методов компьютерного зрения и глубокого обучения расширяет возможности высокопроизводительного анализа растений, позволяя повысить точность измерений. Раннее прогнозирование потенциала сортов имеет значение для идентификации перспективных генотипов задолго до стадии полного созревания .В частности, для культуры риса (Oryza sativa L.) одновременная и точная оценка комплекса интегральных признаков, таких как площадь вегетативной массы, потенциальное число зёрен, сортовой эталон высоты стебля и др., важна в программах селекции, направленных на повышение урожайности
. Однако получение точных количественных данных из 2D-изображений 3D-структур растений сопряжено с рядом сложностей. К ним относятся вариативность внешних условий съемки (даже в лабораторных условиях), проекционные искажения, окклюзии, а также различная степень «визуальной определённости» самих признаков в зависимости от стадии развития растения. Эти факторы обуславливают актуальность разработки математических моделей, способных эффективно решать задачу предиктивной регрессии набора разнородных признаков.Традиционные методы машинного обучения, а также базовые подходы к многозадачному обучению (Multi-Task Learning, MTL), часто сталкиваются с проблемами конфликта градиентов и гетероскедастичности целевых признаков
, . В случае биологических данных, дисперсия ошибок для разных параметров может отличаться на порядки (например, площадь листа в квадратных метрах и количество зёрен в штуках). Простое суммирование ошибок приводит к доминированию задач с большим масштабом ошибки или высокой вариативностью, что снижает общую точность модели. Ручная настройка весовых коэффициентов для каждой задачи в MTL требует экспертных знаний и является трудоёмкой, не гарантируя при этом оптимального баланса.Таким образом, целью настоящего исследования является разработка и тестирование нейросетевой модели, способной эффективно решать задачу многозадачной регрессии для прогнозирования сортового потенциала морфологических признаков риса по изображениям.
Научная новизна:
1. Исследован адаптивный байесовский подход к многозадачному обучению в контексте предиктивного фенотипирования растений, позволяющий динамически взвешивать задачи на основе обучаемой оценки их гомоскедастической неопределённости.
2. Предложен байесовский функционал потерь, включающий штраф за нарушение априорно заданных корреляционных зависимостей между морфологическими признаками. Интеграция биологических знаний о корреляционной структуре растительных характеристик позволяет формировать более физиологически согласованные прогнозы и снижать вероятность некорректных комбинаций признаков
2. Постановка задачи и методы исследования
2.1. Концепция MAP-оценки и вероятностный вывод
Традиционные методы автоматизированного фенотипирования направлены на измерение текущего состояния растения. Однако для селекции важное значение имеет стабильный генетический потенциал сорта
. Пусть X — изображение растения риса на промежуточном этапе развития (например, 8 недель после посадки). Основной задачей является определение отображения F: X → Y, где Y — вектор целевых агрономических признаков (количество зёрен, высота и др.), характеризующих сорт в фазе созревания. Данную задачу можно формализовать как поиск инвариантов генотипа в динамическом потоке фенотипических данных. Поскольку визуальный облик растения подвержен влиянию шумов и временных вариаций роста, итоговые признаки сорта рассматриваются как латентные переменные, которые могут быть реконструированы через многозадачную архитектуру нейронной сети.Для работы с несколькими различными агрономическими задачами, имеющими разные масштабы и уровни шума, используется концепция максимума апостериорной вероятности (MAP). Предполагая, что предсказание модели для каждой задачи i следует нормальному распределению с гомоскедастической неопределённостью, логарифм функции правдоподобия для m задач можно представить в виде (1):
где
Хотя Байесовский подход балансирует веса задач, он рассматривает признаки как статистически независимые. Для обеспечения биологической нормальности вводятся аллометрические ограничения как априорное знание. В физиологии риса морфологические признаки демонстрируют выраженные линейные корреляции в силу законов пропорционального роста, в связи с чем была определена система из биологических инвариантов вида (2):
где
где:
2.2. Набор данных
Исходный набор данных OPIA (Open Plant Image Archive)
содержит изображения растений риса 93 культиваров на разных стадиях развития, сделанные с трёх ракурсов (рисунок 1) и сопровождающиеся множеством из 41 морфометрического параметра.
Изображения экземпляра риса подвида «Japonica» из набора данных
вид спереди, сбоку и сверху
Для формирования устойчивой целевой функции и минимизации шума, связанного с временной динамикой, был проведён двухэтапный процесс отбора признаков.
2.2.1. Этап 1: отбор изображений по стадии вегетации
Из рассмотрения были исключены изображения, соответствующие ранним вегетативным стадиям (<
2.2.2. Этап 2: снижение размерности целевого пространства
Исходное множество из 41 признака было сокращено до 6 (таблица 1).
Таблица 1 - Отобранные целевые признаки
Признак | Описание |
PlantTPA | Финальная проекционная площадь растения, мм2 |
CulmTPA | Финальная проекционная площадь стебля растения, мм2 |
PanicleYPA | Жёлтая проекционная площадь метёлки, мм2 (потенциал продуктивности) |
CulmH | Сортовой эталон высоты стебля, мм |
TFN | Ожидаемое число колосков, шт. |
GN | Потенциальное число зёрен сорта, шт. |
Процесс отбора включал:
- Анализ главных компонент (PCA): определение внутренней размерности данных, показывающее, что 6 компонент объясняют более 85% общей дисперсии (рисунок 2). Определение признаков, вносящих наибольший вклад в главные компоненты.
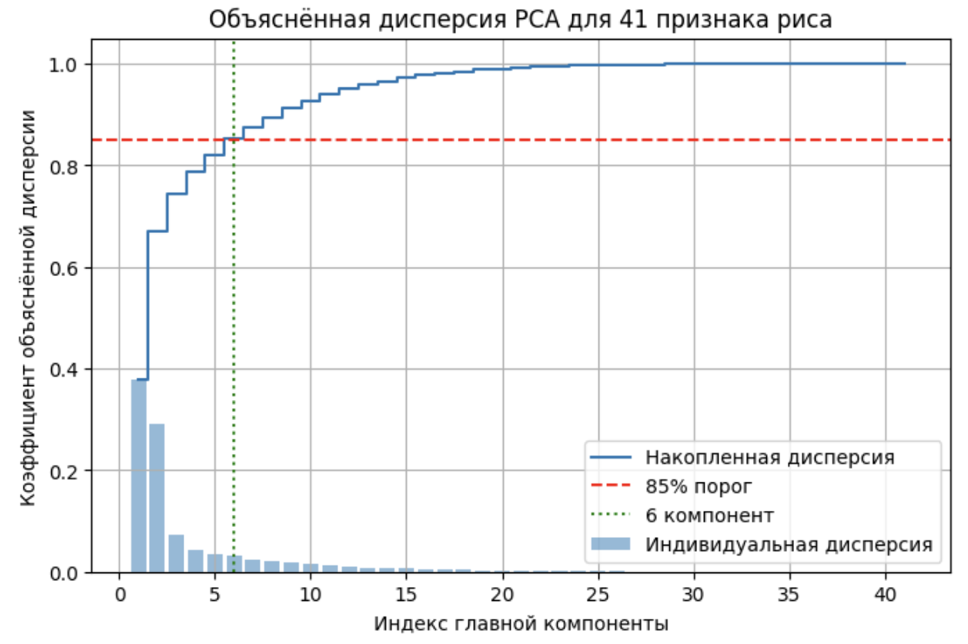
Рисунок 2 - График накопленной доли объяснённой дисперсии
- Анализ биологической репрезентативности: выбор признаков, охватывающих как вегетативные, так и репродуктивные аспекты.
Для каждого сорта
2.3. Структура многозадачной модели
В качестве базового экстрактора признаков (backbone) была использована предобученная свёрточная сеть EfficientNet-B0
, позволяющая эффективно извлекать визуальные дескрипторы из изображений (рисунок 3).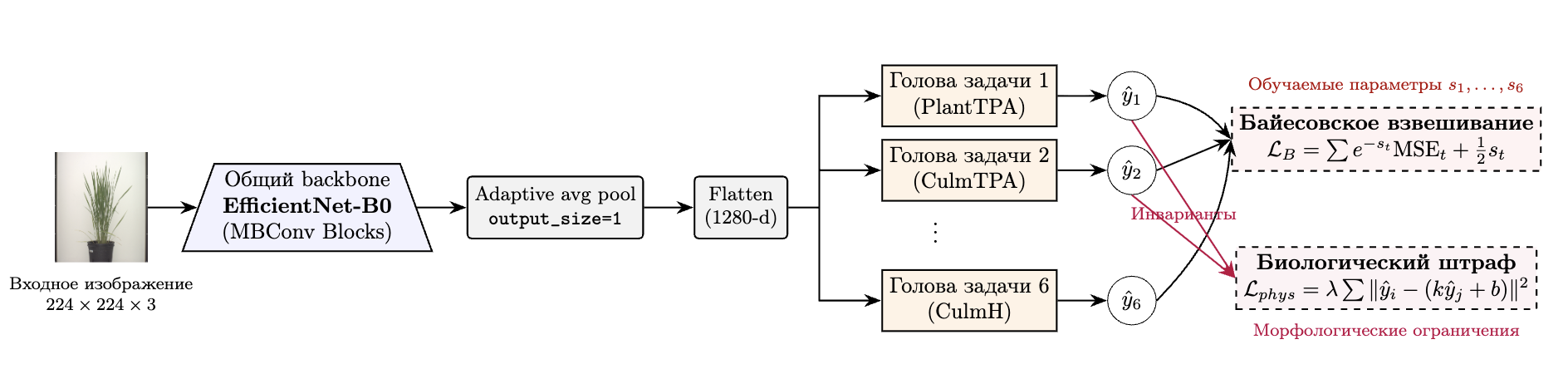
Рисунок 3 - Структурная схема многозадачной модели на основе EfficientNetB0
Обучение модели осуществлялось посредством минимизации полной функции потерь
1. Функция правдоподобия (Likelihood) с динамическим взвешиванием. Помимо классической минимизации среднеквадратичной ошибки (MSE), которая предполагает равный вклад всех задач в итоговый градиент, в данной работе, как уже упоминалось ранее, применяется Байесовский подход. Если в формуле (1) принять
где
2. Априорное распределение биологических инвариантов (bio-loss). Для повышения биологической достоверности прогнозов введён дополнительный регуляризатор (формула (3)), основанный на линейных зависимостях между целевыми признаками (формула (2)). Выбор конкретных пар признаков был обусловлен, во-первых, статистической значимостью — все выбранные пары демонстрируют сильную линейную корреляцию (
Таблица 2 - Характеристики биологических инвариантов
Пара признаков (независимый — зависимый) | Обоснование связи | Коэффициент корреляции |
PanicleYPA — GN Связь «репродуктивная площадь — потенциальная продуктивность» | Физический размер метёлки жёстко лимитирует потенциальное количество зёрен | 0,779 |
PlantTPA — CulmTPA Связь «общая площадь — площадь стебля» | Отражает общую архитектонику куста | 0,857 |
GN — TFN Связь «число зёрен — число колосков» | Биологическая характеристика фертильности и эффективности налива зерна | 0,848 |
CulmTPA — CulmH Связь «площадь стебля — высота стебля» | Отражает механическую устойчивость растения | 0,84 |
PlantTPA — TFN Связь «общая площадь — число колосков» | Баланс между вегетативной мощностью и общим репродуктивным потенциалом сорта | 0,814 |
Аллометрические коэффициенты
3. L2-регуляризация (Weight Decay). Стандартный механизм для предотвращения переобучения
.где
Таким образом, полная функция потерь будет иметь вид:
2.4. Протокол обучения и гиперпараметры
Эксперименты проводились для трёх вариаций многозадачной модели.
1. Стандартная (Base-MTL) с минимизацией функционала (7):
2. Улучшенная (Bayesian-MTL) с динамическим взвешиванием c минимизацией функционала (8):
3. Итоговая (Bio-Bayesian-MTL) с динамическим взвешиванием и учётом биологической морфологии (2), (3) с функционалом потерь (6).
Обучение всех моделей проводилось с использованием оптимизатора Adam и начальной скоростью обучения
Модель Bio-Bayesian-MTL проходила процедуру дообучения, её веса инициализировалась весами предобученной Bayesian-MTL архитектуры. Кроме того, проводилась разморозка глубоких свёрточных блоков (с 6 по 8) базовой сети EfficientNet-B0 с пониженным коэффициентом обучения (
3. Основные результаты
3.1. Анализ точности прогнозирования
Для оценки обобщающей способности моделей исходная совокупность данных была разделена на обучающую, валидационную и тестовую выборки в соотношении 73/10/10 (по 73, 10 и 10 культиваров соответственно). Разделение проводилось на уровне сортов, что исключает попадание изображений одного и того же генотипа в разные выборки и позволяет оценить точность прогнозирования признаков для ранее не изученных селекционных линий.
Результаты сравнительного тестирования трёх конфигураций многозадачных моделей представлены в таблице 3.
Таблица 3 - Сравнительный анализ результатов многозадачных моделей
Признак | Base-MTL MAE / MAPE (%) / R2 | Bayesian-MTL MAE / MAPE (%) / R2 | Bio-Bayesian-MTL MAE / MAPE (%) / R2 |
PlantTPA | 68492 / 20,68 / 0,765 | 70928 / 21,1 / 0,766 | 67129 / 20,75 / 0,768 |
CulmTPA | 14547 / 17,96 / 0,661 | 14262 / 17,18 / 0,699 | 13114 / 16,14 / 0,707 |
PanicleYPA | 9342 / 41,49 / 0,665 | 11700 / 47,45 / 0,545 | 9729 / 44,34 / 0,659 |
GN | 338 / 31,23 / 0,384 | 328 / 30,89 / 0,473 | 300 / 28,29 / 0,527 |
TFN | 245 / 19,55 / 0,708 | 249 / 19,67 / 0,689 | 240 / 20,51 / 0,715 |
CulmH | 122 / 12,89 / 0,477 | 121 / 12,54 / 0,548 | 115 / 12,11 / 0,557 |
Общий (MAPE / R2) | 23,97 / 0,61 | 23,91 / 0,62 | 23,69 / 0,655 |
Модель Baseline, обученная с использованием стандартной MSE-функции потерь, показала средний коэффициент детерминации R2 = 0,61. Применение адаптивного Байесовского взвешивания задач (Bayesian-MTL) привело к повышению средней точности до R2 = 0,626. Наилучшие показатели были достигнуты гибридной моделью Bio-Bayesian-MTL со средним R2 = 0,655. Наибольший относительный прирост R2 зафиксирован для признака GN: с 0,384 (Baseline) до 0,527 (Bio-Bayesian-MTL).
3.2. Оценка морфологической консистентности
Для количественной оценки морфологического соответствия предсказаний моделей была введена метрика биологической инконсистентности, измеряющая отклонение предсказанных значений от пяти установленных аллометрических зависимостей (формула 9).
где:
N — количество образцов в тестовой выборке;
M — число используемых пар биологических ограничений (в данной работе M = 5, см. таблицу 2).
Среднее значение
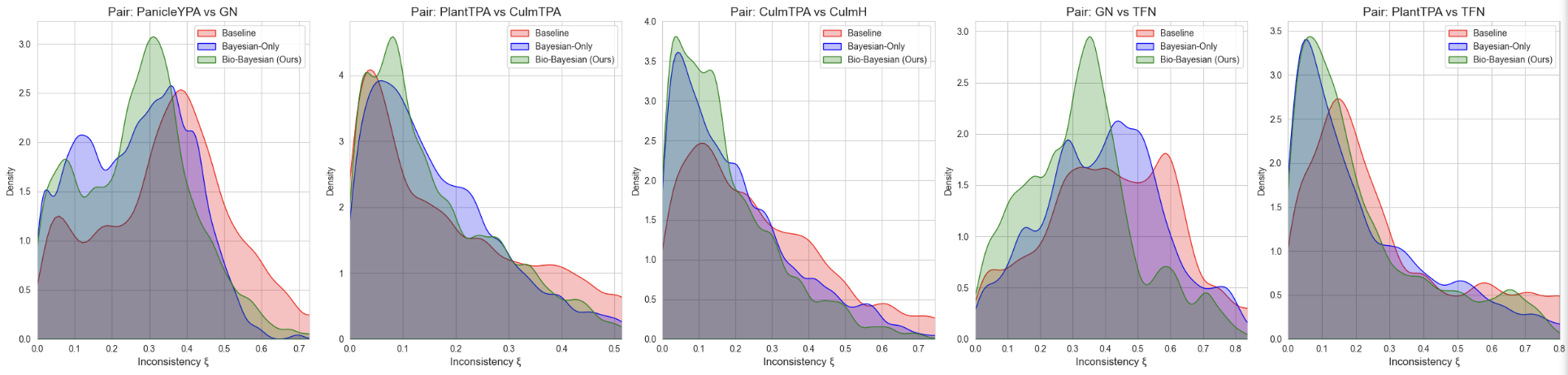
Рисунок 4 - Плотность распределения ошибок биологической консистентности
1. Оптимизация архитектуры: переход от ансамбля из 6 независимых моделей (STL) к единой многозадачной модели (MTL) позволил сократить количество вычислительных операций в 5,8 раз. Это значение было получено через отношение числа операций MFLOPs, затрачиваемых на получение результата: (390 + 0,72) × 6 ≈ 2344 для ансамбля STL к (390 + 0,72) × 6 ≈ 394,3 для MTL. Здесь 390 — число MFLOPs для экстрактора признаков на базе EfficientNetB0, 0,72 — MFLOPs для одной «головы» из 3 полносвязных слоёв (512, 128, 1). Учитывались также накладные расходы на параллельную диспетчеризацию задач в GPU.
2. Алгоритмическая эффективность: внедрение биологических инвариантов (bio-loss) и механизмов динамического взвешивания задач не несёт накладных расходов на этапе инференса, так как вся сложность биологических правил интегрирована непосредственно в веса сети в процессе обучения.
4. Обсуждение
Результаты экспериментальных исследований подтверждают гипотезу о том, что интеграция биологических априорных знаний в архитектуру многозадачной нейронной сети позволяет преодолеть ограничение стандартных моделей глубокого обучения — биологическую противоречивость предсказаний.
Анализ графиков плотности распределения ошибок демонстрирует качественное различие между моделями. В базовой модели (Base-MTL) распределение остатков характеризуется высокой дисперсией и значительным удалением моды от нулевого значения. Это свидетельствует о том, что без явных структурных ограничений сеть обучается аппроксимировать каждый признак изолированно, игнорируя физиологические взаимосвязи. Применение байесовского взвешивания задач (Bayesian-MTL) позволило снизить ошибку консистентности (с 0,31 до 0,25), что объясняется балансировкой градиентов и устранением доминирования «лёгких» задач над «сложными». Однако наиболее выраженный эффект достигнут в модели Bio-Bayesian-MTL (0,23), где распределение максимально смещено к нулю и имеет (в большинстве случаев) наименьшую дисперсию. Это доказывает, что bio-loss выступает в роли эффективного регуляризатора, удерживающего предсказания в рамках биологически допустимого многообразия.
Особого внимания заслуживает улучшение точности по признаку числа зёрен (GN), где показатель MAPE снизился на 2,94%. Учитывая сложность прямой детекции зёрен на 2D-изображениях, данный прогресс достигнут за счёт переноса знаний от более стабильного признака — жёлтой площади метёлки (PanicleYPA) — через аллометрическое уравнение связи. Наблюдаемый при этом рост ошибки по площади метёлки в Bio-Bayesian-MTL модели можно интерпретировать как необходимый компромисс между «пиксельной» точностью и структурной согласованностью системы.
Таким образом, предложенный метод не только минимизирует математическую ошибку, но и соблюдает внутреннюю логику объекта исследования. Это делает модель устойчивой к ошибкам разметки и шуму, что важно для задач фенотипирования в полевых условиях.
5. Заключение
В данной работе представлена методика цифрового фенотипирования риса на основе многозадачного глубокого обучения, объединяющая байесовскую оценку неопределённости и биологические априорные знания.
Основные выводы исследования:
1. Повышение точности и объяснимости: улучшенная модель Bio-Bayesian-MTL обеспечила рост коэффициента детерминации R2 до 0.66, что превосходит показатели стандартных подходов. Модель показала лучшую робастность при прогнозировании компонентов урожайности (GN, CulmH).
2. Биологическая консистентность: внедрение аллометрического регуляризатора (bio-loss) позволило на 27% снизить уровень системных противоречий в предсказаниях. Визуализация в пространстве признаков подтвердила, что архитектура сети успешно выучила физиологические инварианты развития растения.
3. Эффективность байесовского подхода: динамическое взвешивание задач на основе гомоскедастической неопределённости является важным этапом подготовки модели к восприятию жёстких биологических ограничений.
Научная значимость работы заключается в создании методологического каркаса для разработки «физически информированных» нейронных сетей в биологии. С практической точки зрения, предложенный алгоритм является готовым инструментом для высокопроизводительного скрининга в селекционных программах, обеспечивающим получение объективных и биологически достоверных данных о состоянии растений без необходимости разрушающего контроля.
Разработанный метод является масштабируемым, однако его применение к культурам с иной архитектоникой требует адаптации набора биологических инвариантов. Основным ограничением текущей версии является использование 2D-изображений, что при анализе культур с высокой степенью окклюзии может потребовать перехода к 3D-моделированию. Для адаптации метода к новым растениям необходим предварительный расчёт специфических аллометрических констант, отражающих закономерности роста конкретного биологического вида. Включение таких априорных знаний в функцию потерь позволяет переносить предложенную методику на широкий спектр сельскохозяйственных культур.
Дальнейшее развитие исследования может быть связано с расширением набора аллометрических правил для динамических стадий роста и интеграцией временных рядов в структуру многозадачного обучения.