СПОСОБ АВТОМАТИЧЕСКОГО ПОЛУЧЕНИЯ ПРАВИЛ ДЛЯ ТРАНСФЕРНОЙ СИСТЕМЫ МАШИННОГО ПЕРЕВОДА

Ярмолюк А. Э.
Бакалавр, Национальный технический университет Украины «Киевский политехнический институт»
СПОСОБ АВТОМАТИЧЕСКОГО ПОЛУЧЕНИЯ ПРАВИЛ ДЛЯ ТРАНСФЕРНОЙ СИСТЕМЫ МАШИННОГО ПЕРЕВОДА
Аннотация
В данной статье я рассматриваю способ автоматического получения правил для трансферной системы машинного перевода. Обучающий алгоритм получает множество правил и их вероятностей из корпуса переводов. Правило переводит путь в дереве зависимостей исходного предложения в фрагмент дерева зависимостей целевого предложения.
Ключевые слова: машинный перевод, правила трансфера.
Yarmoluk A. E.
Bachelor, National Technical University of Ukraine
ALGORITHM FOR AUTOMATIC RULE ACQUIRING FOR TRANSFER-BASED MACHINE TRANSLATION
Abstract
The article considers an algorithm for automatic rule acquiring for transfer-based machine translation. Training algorithm acquires rules and their possibilities from a parallel corpus. Rule translates a link in source dependency tree into a fragment in target sentence.
Keywords: machine translation, transfer rules.
Недавно появилось много предложений о получении правил трансфера автоматически из параллельного корпуса переводов [1, 2]. Я предлагаю рассмотреть новый подход к решению этой проблемы.
1. Получение правил трансфера
Правило трансфера определяет, как переводится путь в дереве зависимостей исходного языка. Мы получаем трансферные правила автоматически из параллельного корпуса переводов. Трансферные правила также содержат соответствия слово-слово между узлами во исходном и целевом языках (полученные из согласований слов).
Алгоритм получения правил использует понятие интервалов [3, 4]. Если дано согласование слов и узел n в дереве зависимостей исходного языка, интервалы n созданые согласованием слов являются последовательностями слов в целевом предложении. Мы определяем два типа интервалов:
Главный интервал: последовательность слов в согласована с узлом n.
Интервал фразы: последовательность слов от нижней границы главных интервалов всех узлов в поддереве с корнем в n до верхней границы того же множества интервалов.
Так же используется алгоритм согласования слов[5], который гарантирует, что если два интервала накладываются то один должен быть полностью накрыт другим.
Для каждого дерева зависимостей в учебном корпусе, получим все пути, где все узлы согласованы со словами в предложении целевого языка. Допускается чтобы прилагательное в середине пути не было согласовано.
Пускай S i - простой путь от узла h до узла m. Пуска h` и m` - слова целевого языка согласованные с h и m соответственно. Пускай s - интервал фразы родственного для m узла, который находится между h` и m` и является самым близким к m` среди всех таких интервалов фраз. Если m не имеет такого родственного узла, пускай s будет главным интервалом h.
Перевод T i из S i складывается из следующих узлов и ребер:
• Два узла помеченные h` и m` , и ребро от h' до m'.
• Узел, соответствующий каждому слову между s и интервалом фразы узла m и ребро из каждого из этих узлов к m'.
В общем, путь — это или один узел, или простой путь, или последовательность простых путей. Перевод одиночных узлов определяется согласованием слов. Перевод последовательности простых путей можно получить объединяя переводы простых путей.
Также правила обобщаются посредством замены одного из конечных узлов в пути на универсальный символ и часть речи этого слова.
Далее рассчитываем вероятность перевода. Пусть S и - это путь в дереве зависимостей входного языка, а T i - фрагмент дерева целевого языка. Вероятность перевода P (T i | S i) можно вычислить как:
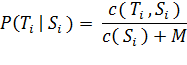
где C (S i) является количеством S i в учебном корпусе, (Т i, S i) это количество раз когда T i является переводом S i, а М является динамическим параметром.
2. Результаты исследований
Я использовал описанный способ для создания СМП Украинский-Английский. Для обучения использовалась часть параллельного англо-украинского корпуса KDE4 [6]. Полученный результат BLEU для данной системы равняется 0.2346. Если сравнивать с подобными системами то данный результат хуже чем в [7] – BLEU=0.201, но лучше чем система основанная на фразах – BLEU=0.3149.
3. Выводы
Описанная система и вообще системы МП на базе трансфера берут дерево разбора исходного языка и переводят его в дерево разбора целевого языка руководствуясь правилами трансфера. Описанная система отличается от предыдущих трансферных систем по двум основным характеристикам: единицей передачи и генеративным модулем.
Единицами перевода в предыдущих трансферных системах обычно служат поддеревья в дереве зависимости исходного языка. Количество поддеревьев является экспоненциальной функцией, число путей в дереве квадратично. Уменьшение количества возможных трансферных единиц приводит к меньшему раздроблению базы.
Обычно, целевое дерево разбора в трансферных системах не содержит информацию о порядке слов. Линеаризация слов в целевом дереве разбора требует отдельного генеративного модуля, который является сводом правил грамматики целевого языка. Описанные правила трансфера наоборот – устанавливают линейный порядок между узлами в правиле. Упорядочивание между узлами по разным правилам определяется парой простых эвристик. Нет отдельного генеративного модуля и не нужна грамматика целевого языка.
Список литературы
Lavoie, Benoit; White, Michael; Korelsky, Tanya. Learning Domain-Specific Transfer Rules: An Experiment with Korean to English Translation // COLING Workshop on Machine Translation in Asia. – Taipei, Taiwan, 2002. – P. 60-66.
Steve Richardson, W. Dolan, A. Menezes, and J.Pinkham. Achieving commercial-quality translation with example-based methods // MT Summit VIII. – Santiago De Compostela, Spain, 2001. – P. 293-298.
Heidi J. Fox. Phrasal cohesion and statistical machine translation. // EMNLP-02. – Philadelphia, PA, 2002. – P. 304-311.
Colin Cherry, Dekang Lin. A Probability Model to Improve Word Alignment // ACL-03. – Sapporo, Japan, 2003. – P. 88-95.
Dekang Lin, Colin Cherry. Word Alignment with Cohesion Constraint. Companion Volume // HLT/NAACL. Companion Volume. – Edmonton, Canada, 2003. – P. 49-51.
Jorg Tiedemann. Collection of Multilingual Parallel Corpora with Tools and Interfaces // Recent Advances in Natural Language Processing. – John Benjamins, Amsterdam, Philadelphia, 2009. – P. 237-248.
Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical Phrase-Based Translation // HLT/NAACL. – Edmonton, Canada, 2003. – P. 127-133.
Список литературы
Lavoie, Benoit; White, Michael; Korelsky, Tanya. Learning Domain-Specific Transfer Rules: An Experiment with Korean to English Translation // COLING Workshop on Machine Translation in Asia. – Taipei, Taiwan, 2002. – P. 60-66.
Steve Richardson, W. Dolan, A. Menezes, and J.Pinkham. Achieving commercial-quality translation with example-based methods // MT Summit VIII. – Santiago De Compostela, Spain, 2001. – P. 293-298.
Heidi J. Fox. Phrasal cohesion and statistical machine translation. // EMNLP-02. – Philadelphia, PA, 2002. – P. 304-311.
Colin Cherry, Dekang Lin. A Probability Model to Improve Word Alignment // ACL-03. – Sapporo, Japan, 2003. – P. 88-95.
Dekang Lin, Colin Cherry. Word Alignment with Cohesion Constraint. Companion Volume // HLT/NAACL. Companion Volume. – Edmonton, Canada, 2003. – P. 49-51.
Jorg Tiedemann. Collection of Multilingual Parallel Corpora with Tools and Interfaces // Recent Advances in Natural Language Processing. – John Benjamins, Amsterdam, Philadelphia, 2009. – P. 237-248.
Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical Phrase-Based Translation // HLT/NAACL. – Edmonton, Canada, 2003. – P. 127-133.