Применение векторных представлений BERT и ELMo в задаче лексической типологии
Применение векторных представлений BERT и ELMo в задаче лексической типологии

Аннотация
Работа посвящена использованию векторных представлений ELMo и BERT в задаче определения лексической типологии языков. Также сравнивается способ кластеризация с заданным количеством кластеров K-means и способ кластеризации с автоматическим количеством кластером DBSCAN. Описана задача лексической типологии. Сделан обзор существующих подходов к решению задачи, описаны достоинства и недостатки. Проведены эксперименты для семантической зоны «тянуть-толкать». Выявлено, что на результат влияют как тип векторных представлений, так и способ кластеризации. Способ кластеризации влияет больше, чем векторные представления. Влияние распространяется на точность, полноту и F-меру. BERT показывает результаты лучше, чем ELMo, а K-means лучше, чем DBSCAN. Произведены оценки подходов, найдены оптимальные параметры и сделаны выводы.
1. Введение
Задача определения лексической типологии языков является актуальной и недостаточно автоматизированной. Данная статья описывает использование векторных представлений ELMo и BERT для помощи лингвистам. Для оценки выбрано семантическое поле «тянуть — толкать». Оно уже исследовано в работе , поэтому с ней будет произведено сравнение автоматизированного подхода.
Лексическая типология изучает способы языкового выражения конкретных явлений и сопоставляет соответствующие лексические средства в разных языках. Так, в русском языке один и тот же термин используется для обозначения пальцев руки и ноги, тогда как в английском языке эти понятия различаются лексемами «finger» и «toe». Наряду с межъязыковым сравнением, возможно исследование семантических полей внутри одного языка и анализ средств их выражения. Например, в семантической зоне «чинить — портить» можно выделить такие варианты употребления, как «делать вновь пригодным», «настраивать инструмент», «изменять деятельность», «ухудшать». Подобные типы употреблений представляют собой фреймы .
На основе выделенных фреймов может быть построена таблица, в которой строки соответствуют фреймам, столбцы — языкам, а в ячейках указываются лексические единицы, с помощью которых данные фреймы реализуются в разных языках. Статья направлена на автоматизированное формирование подобных фреймов.
2. Обзор литературы
2.1. Ручные методы
Выделяют четыре основных подхода к исследованию. Первый опирается на использование фреймов и известен как метод Московской лексико-типологической школы. В рамках этого подхода каждая ситуация, входящая в определенное семантическое поле, описывается с помощью фрейма — набора характеристик, выраженных словами. Так, например, фрейм «нажимать предмет вперёд» относится к семантическому полю «тянуть — толкать». В языке фрейм реализуется через конкретные лексемы, при этом количество возможных фреймов может быть значительным. Их отбор осуществляется исследователем на основе словарей, переводных источников и собственных интуитивных представлений. Также возможно использование синхронных переводов текстов.
На следующем этапе составляется таблица: в строках приводятся описания фреймов, в столбцах — лексемы, а в ячейках отмечается, соотносится ли конкретная лексема с данным фреймом. Существует и другой вариант таблицы, где строки соответствуют фреймам, столбцы — языкам, а в ячейках указываются лексемы, с помощью которых в каждом языке выражается данный фрейм. Основным недостатком этого подхода является ручной характер выделения фреймов. Кроме того, при работе со словарями исследователю приходится определять пределы поиска, поскольку в процессе перевода возникают новые фреймы, часто лишь косвенно связанные с изучаемым семантическим полем из-за многозначности слов. В связи с этим также требуется привлечение носителей соответствующих языков.
Второй подход опирается на физическое восприятие человека . Исследователь формирует набор универсальных стимулов, например, объекты с определенным вкусом, запахом, цветом, формой и предъявляет их носителям языка. Задача информанта заключается в максимально точном словесном описании предложенного объекта. Сравнивая ответы носителей разных языков, можно установить, какими лексическими средствами выражаются одни и те же стимулы в разных языках. К недостаткам данного метода относятся невозможность воспроизвести всё разнообразие лексических единиц в виде физических стимулов, а также высокая трудоёмкость и значительные временные затраты. Кроме того, данный подход требует обязательного участия носителей языка.
Третий подход базируется на использовании универсальных семантических примитивов, с помощью которых предполагается возможным описать любую ситуацию . В рамках этого метода применяется система из 64 базовых понятий, из комбинаций которых выводятся все остальные значения. Основными недостатками подхода являются неоднозначность интерпретации выводимых значений и общая методологическая сложность.
Четвёртый подход связан с анализом параллельных корпусов текстов. Исследователь выявляет переводные соответствия для различных реализаций определённой семантической зоны. Существенным ограничением данного метода является отсутствие или недостаточная представленность параллельных корпусов для редких и малораспространённых языков.
Наиболее распространённым в лингвистических исследованиях является фреймовый подход. Так, в работе с его помощью анализируется семантическое поле «мешать». В исследовании рассматривается семантическое поле «домашний скот» на материале германских и славянских языков, основным источником данных служит лексический фонд. В работе при изучении семантических зон «попасть, упасть» и «задеть, попасть» в казымском диалекте хантыйского языка используются корпусные данные, словари и материалы, полученные от носителей языка.
Исследование посвящено семантической зоне «острый» в китайском языке и опирается на данные словарей, текстовых корпусов и материалы, полученные от информантов. Автор работы также обращается к семантическому полю «шахматная игра» в русском языке, применяя модель «центр — периферия», где в центре располагаются наиболее узкоспециализированные семантические признаки, а на периферии — менее специализированные.
В работе для анализа семантической зоны «мягкий», «твёрдый», «жёсткий» используется метод анкетирования носителей языка. В главе «Methodology at work: Semantic fields sharp and blunt» книги описывается семантическая зона «острый — тупой». Показано, что ключевыми параметрами оппозиции выступают тип острого объекта и ощущение, на основе которого определяется степень его остроты. В работе семантическая зона слова «город» исследуется на материале литературных источников.
2.2. Автоматизированные методы
Автоматизация типологических исследований на сегодняшний день остаётся недостаточно хорошо развитой. В работе используются заранее подготовленные анкеты, которые затем автоматически переводятся на другие языки с опорой на словари и параллельные корпуса. Исследование посвящено семантическим зонам «острый — гладкий» и «толстый — тонкий». Основным ограничением данного подхода является потребность в предварительной разработке таких анкет.
В работе в качестве материала используются биграммы Национального корпуса русского языка , дополненные различными леммами. Для проведения кластеризации формируются векторные представления: отбираются 10 000 наиболее частотных лексем, после чего для исследуемого слова подсчитывается количество совместных употреблений каждой из этих лексем в окне шириной пять слов. Для анализа применяются алгоритмы иерархической кластеризации, поскольку методы, не требующие заранее заданного числа кластеров, продемонстрировали низкую эффективность. Недостатком данного подхода является отсутствие в векторах семантической информации, а также информации о контексте употребления.
3. Векторные представления
3.1. ELMo
ELMo являются векторными представлениями, обладающих тем свойством, что для одинаковых слов в разных контекстах будут сгенерированы разные векторы . Например, для слова ключ в следующий предложениях будут сгенерированы разные векторы: «на доске нарисован скрипичный ключ», «в реке бил ключ», «ключ находился в замке». При этом в первом предложении вектор будет ближе к векторам слов, связанных с музыкой, во втором к словам, связанным с реками, а в третьем с замками.
Для получения векторов используются две нейронные сети LSTM (Long Short-Term Memory). Одна читает предложение слева направо и предсказывает следующее слово, а вторая справа налево и предсказывает предыдущее слово. Таким образом, получается учитывать контекст сразу с обеих сторон. Затем внутренние состояния двух сетей суммируются и получается контекстуализированное векторное представление. При этом слова в начале и в конце предложения будут иметь разные векторы.
Однако эволюционно векторы ELMo появились первыми, и сегодня существуют представления, которые лучше захватывают дальний контекст и обучаются эффективнее. Одним из таких представлений являются векторы BERT (Bidirectional Encoder Representations from Transformers).
3.2. BERT
Векторы BERT, как и ELMo, являются контекстуализированными векторными представлениями. Однако контекст учитывается слева и справа не последовательно, как в ELMo, а одновременно . BERT состоит из одинаковых Transformer Encoder-блоков из 12 или 24 слоев. Используются только Encoder блоки. Слова разделяются на подслова. Например, слово «невероятный» может быть разделено на токены «не» и «##вероятный». Это дает возможность обрабатывать редкие слова. В каждое предложение вставляется 2 специальных токена: [CLS] — представляет все предложение целиком, [SEP] — разделяет предложения. При обучении используется механизм внимания. Каждый токен представлен комбинацией 3-х векторных представлений: векторное представление самого слова, представление позиции в предложении и представление принадлежности конкретному предложению.
Для обучения случайно скрываются 15% токенов. Они заменяются на специальный токен [MASK]. BERT должен предсказать это скрытое слово на основе контекста. Например, «Он сидел на [MASK] реки». Вместо слова [MASK] BERT должен научиться предсказывать слово «берегу».
Также его можно дополнительно обучать на задаче предсказания, являются ли 2 предложения последовательными. Например,
1. «Он пошел на рыбалку».
2. «Он поймал много рыбы».
3. «В огороде растет много вкусных овощей».
BERT должен научиться определять, что 2-е предложение с большей вероятностью стоит после 1-го, чем 3-е. Затем BERT дообучается на специфичной для задачи области.
Для лексической типологии могут быть полезны оба представления, поэтому будет произведена оценка их работы и сравнение для данной задачи.
4. Алгоритм работы
4.1. Векторные представления
Исследование проводится на материале текстов Национального корпуса русского языка. Все слова переводятся в начальную форму, после чего из текста удаляются стоп-слова и специальные символы. Затем в корпусе отбираются все предложения, содержащие слова «тянуть» и «толкать». В файл сохраняется предложение, содержащее найденное слово, все дополнительно обнаруженные слова, номер предложения, а также его исходный вариант.
Затем для каждого слова в каждом предложении вычисляются векторные представления с помощью моделей BERT и ELMo. Они обучены на русской Википедии и новостных корпусах. Лексика схожа с лексикой из корпуса постсоветских текстов Национального корпуса русского языка, поэтому модель должна хорошо работать на данном корпусе. Предложения также сохраняются в структуре. Для сохранения результатов используется библиотека Pickle.
Среди найденных предложений много слов в одинаковой семантической зоне, поэтому необходима фильтрация.
4.2. Фильтрация
Предложения, векторы которых сильно отличаются, считаются новыми фреймами исследуемого поля. Для удаления похожих предложений используется алгоритм K-means и алгоритм кластеризации с автоматическим количеством кластеров DBSCAN .
Для выбора количества кластеров в методе в K-means используется метод локтя. Выбирается диапазон значений количества кластеров, например, от 1 до 20. Для каждого количества кластеров запускается работа алгоритма. Затем идет подсчет суммы квадратов внутрикластерных расстояний (Within Cluster Sum of Squares — WCSS) по формуле 1.
Ci — i-й кластер
μi — центроид кластера
||x- μi||2 — квадрат евклидова расстояния
Строится график, на оси X которого обозначается количество кластеров, а на оси Y сумма квадратов внутрикластерных расстояний. График всегда убывает. Он показывает, как уменьшается ошибка кластеризации при увеличении количества кластеров. На нем необходимо найти излом, после которого убывание становится не так значительно по сравнению с предыдущими значениями. Т.е. необходимо найти количество кластеров, после которого улучшения замедляются более медленно, чем до этого. Это количество и будет выбранным k в алгоритме K-means.
Для алгоритма DBSCAN основными параметрами являются:
1) eps — максимальное расстояние между двумя точками, чтобы считать их соседями;
2) min_samples — минимальное количество точек, чтобы сформировать кластер.
min_samples для двумерных данных обычно берется в диапазоне 3-5 и увеличивается для зашумленных данных.
4.3. Псевдокод
Псевдокод представлен в листинге.
1Вход: корпус НКРЯ
2Выход: фреймы
3
4sents ← corpus[тянуть|толкать]
5embeddingsBERT ← BERT(sents)
6embeddingsELMo ← ELMo(sents)
7centroidsBERTKMeans ← KMeans(embeddingsBERT)
8centroidsELMoKMeans ← KMeans(embeddingsELMo)
9centroidsBERTDBSCAN ← DBSCAN(embeddingsBERT)
10centroidsELMoDBSCAN ← DBSCAN(embeddingsELMo)
11
12func FindNearest(centroids, embeddings:
13 frames ← []
14 FOR centroid in centroids:
15 MaxSim ← 0
16 MaxSimFrame ← 0
17 For emd in embeddings:
18 simCetroidSent ← cos(centroid, emd)
19 frame ← corpus[number(emd)]
20 IF simCetroidSent > MaxSim and NOT(frame in frames):
21 MaxSim ← CetroidSent
22 MaxSimFrame ← frame
23 frames += MaxSimFrame
24
25RETURN frames
26
27framesBERTKMeans ← FindNearest(centroidsBERTKMeans, embeddingsBERT)
28framesELMoLMeans ← FindNearest(centroidsELMoKMeans, embeddingsELMo)
29framesBERTDBSCAN ← FindNearest(centroidsBERTDBSCAN, embeddingsBERT)
30framesELMoDBSCAN ← FindNearest(centroidsELMoDBSCAN, embeddingsELMo)
31
32RETURN (framesBERTKMeans, framesELMoLMeans, framesBERTDBSCAN, framesELMoDBSCAN)5. Эксперименты
5.1. BERT с K-means
Сначала была исследована зона «толкать». Полученные векторы BERT были кластеризованны методом K-means. В этом методе необходимо выбрать количество кластеров. Для этого был использован метод локтя.
Построим график суммы квадратов внутрикластерных расстояний для большого значения k, например, 360. График представлен на Рисунке 1.
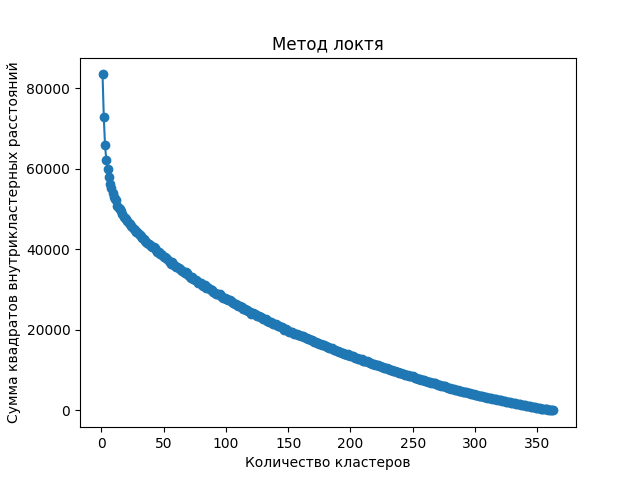
Метод локтя для K-means с векторами BERT зоны «толкать»
количество кластеров - 360
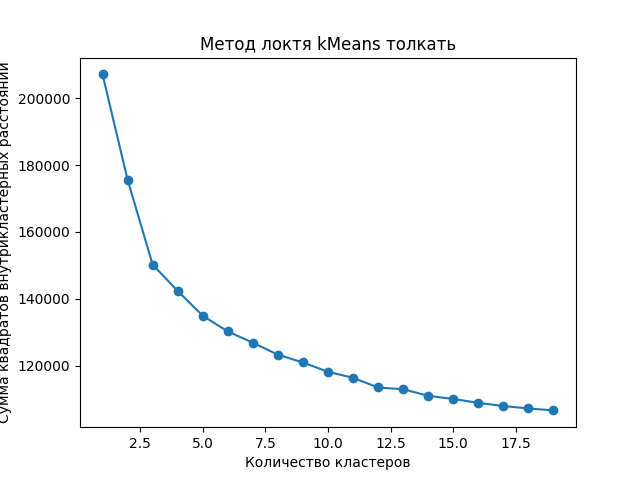
Метод локтя для K-means с векторами BERT зоны «толкать»
количество кластеров - 20
Аналогично для зоны «тянуть» был построен график значений k на Рисунке 3.
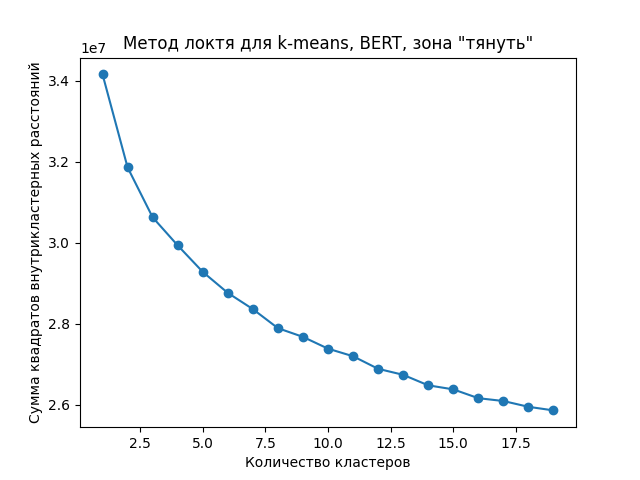
Метод локтя для K-means с векторами BERT зоны «тянуть»
Была произведена оценка. Сначала была подсчитана точность, потом полнота, затем F-мера. Эти метрики применимы к оценке алгоритма, т.к. необходимо понять, сколько найденных фреймов соответствуют фреймам из работы , и сколько фреймов из работы было найдено. Для оценки точности среди найденных фреймов были найдены те, которые семантически совпадают с фреймами из работы . Их количество было разделено на общее количество фреймом, найденных алгоритмом. Для оценки полноты было определено, сколько из найденных в работе фреймов совпадает с фреймами, найденными алгоритмом. Их количество было разделено на общее количество фреймов, найденных в работе . F-мера считалась по формуле (2).
P — точность.
R — полнота.
Результаты в Таблице 1.
Таблица 1 - Оценка метода BERT + K-means
Тянуть | Толкать | Тянуть-толкать | |
Точность | 75 | 100 | 88 |
Полнота | 70 | 73 | 71,4 |
F-мера | 72,4 | 84,4 | 79 |
Подход показал хорошие результаты. Не были найдены только следующие фреймы: «перемещать ногами», «нажимать на кнопку», «сталкивать с высоких объектов», «помещать во внутрь».
5.2. BERT с DBSCAN
Для алгоритма DBSCAN необходимо выбрать значения eps и min_samples. Были найдены следующие оптимальные значения параметров для зоны «тянуть»:
1) eps = 0.27;
2) min_samples = 5.
Оптимальные значения eps лежат в диапазоне от 0.27 до 0.29. Такие значения дают 11 кластеров. Оптимальны именно такие значения, т.к. при выборе значения eps равным 0.26 уменьшается точность, и остается много нерелевантных предложений — 22, а значение 0.3 наоборот оставляет слишком мало предложений — 6, и таким образом уменьшается полнота. Оптимальным значением min_samples будет 5, т.к, если его уменьшить до 4, будет 9 кластеров, и уменьшится полнота, а если повысить до 6, будет 12 кластеров, и уменьшится точность.
Найдены 3 новых фрейма, которых нет в работе (здесь и далее примеры взяты из Национального корпуса русского языка):
1. «Когда Wimm Bill Dann разливал свой сок J7, то это было намного лучше, чем сегодняшние ролики, где показан человек, постоянно тянущийся за стаканом».
2. «Колтунов «раскочегарил» свою «пятерку» и натужно потянулся по остывшему следу».
3. «Глаза Гуревича на секунду затянуло пеленой: он представил себе добрый шмоток сырокопченой свининки».
Для зоны «толкать» такие же параметры, как для зоны «тянуть», дают только один кластер. Поэтому оптимальными для данной зоны являются следующие параметры:
1) eps = 0.2;
2) min_samples = 3.
Диапазон возможных значений min_samples от 1 до 3, а eps от 0.19 до 0.21.
Они дают 9 кластеров. При min_samples = 4 количество найденных кластеров уменьшается до 7.
Оценка работы приведена в Таблице 2.
Таблица 2 - Оценка метода BERT + DBSCAN
Тянуть | Толкать | Тянуть-толкать | |
Точность | 73 | 78 | 75 |
Полнота | 50 | 64 | 57 |
F-мера | 59,4 | 70,3 | 64,77 |
Не были найдены фреймы «перемещать ногами»,»помещать во внутрь», «нажимать на кнопку», «сталкивать с высоких объектов»
5.3. ELMo с K-means
Получение эмедингов BERT значительно быстрее, чем ELMo. Перевод первых 100 000 предложений в BERT занимает 8,2 секунды, а в ELMo 41.68 секунд на Macbook pro с процессором m1, 16-ю гигабайтами оперативной памяти и 1-м тб постоянной памяти.
Аналогично, как для метода BERT + K-means, построим график суммы квадратов внутрикластерных расстояний в зависимости от значений количества кластеров k для зоны «тянуть» на Рисунке 4.
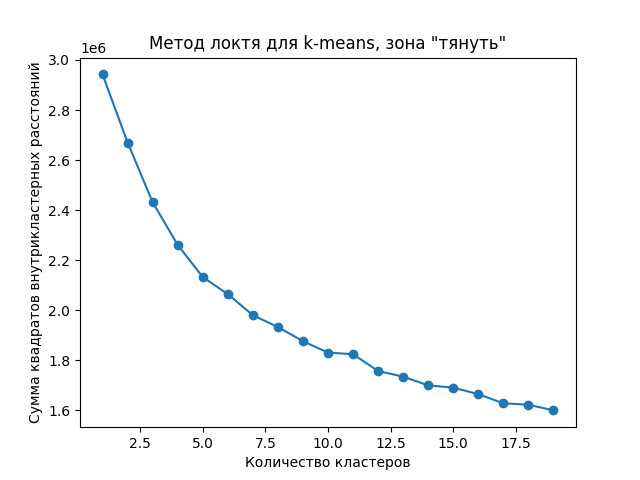
Метод локтя для K-means с векторами ELMo зоны «тянуть»
- «Правду молвил Ухмыл: такой затянулся узелок, что и не распустишь».
- «Лизавета тянула Сашу к дверям».
- «Дима-а -- протянул мужик».
- «Марик замер и вытянул шею, чтоб ему было все видно».
- «Тут и рекламные щиты, и мигающий неон, и виллы в зелени, а в небе летел самолетик, за которым тянулся какой-то шлейф».
- «Больные, шаркая тапочками, потянулись на процедуры».
- «Но почему-то потянуло прогуляться».
- «Ты не могла бы снять с меня эти браслеты -- спросил Сергей, пошевелив руками, по-прежнему стянутыми за спиной наручниками».
- «Ларт подал ему руку и рывком втянул в круг: -- Время».
- «Ну и тени, конечно, тоже мелькали на дне сознания -- желающий мог дотянуться и до них».
Аналогично для зоны «толкать» график на Рисунке 5.
Метод локтя для K-means с векторами ELMo зоны «толкать»
Таблица 3 - Оценка метода ELMo + K-means
Тянуть | Толкать | Тянуть-толкать | |
Точность | 70 | 83 | 77 |
Полнота | 60 | 64 | 62 |
F-мера | 65 | 72 | 68,7 |
5.4. ELMo с DBSCAN
Для векторов ELMo и зоны «тянуть» были выбраны следующие оптимальные параметры:
1) eps = 0.2;
2) min_samples = 5.
Диапазон оптимальных значений eps от 0.2 до 0.22, min_samples от 4 до 7. Они дают 11 фреймов. При min_samples = 3 находится больше фреймов, и уменьшается точность. При значении eps 0.19 находится 16 фреймов, тоже уменьшается точность. При значении 0.23 находится 6 фреймов, уменьшается полнота.
Для зоны «толкать» подходят такие же оптимальные параметры, как и для зоны «тянуть».
Оценка приведена в Таблице 4.
Таблица 4 - Оценка метода ELMo + DBSCAN
Тянуть | Толкать | Тянуть-толкать | |
Точность | 55 | 73 | 64 |
Полнота | 40 | 55 | 48 |
F-мера | 46 | 63 | 55 |
Самые лучшие результаты показал подход BERT с K-means, на втором месте ELMo с K-means, на третьем BERT с DBSCAN, на четвёртом ELMo с DBSCAN. Таким образом, векторы BERT показываются лучше результаты, чем ELMo, а кластеризация K-means лучше, чем DBSCAN, при этом классификатор больше влияет на результат, чем тип векторов.
6. Результаты
В Таблице 5 приведены сравнительные оценки работы алгоритмов. Жирным выделен самый лучший результат.
Таблица 5 - Сравнение работы алгоритмов
B-K-Т1 | B-K-Т2 | B-K-ТО | B-D-Т1 | B-D-Т2 | B-D-ТО | E-K-Т1 | E-K-Т2 | E-K-ТО | E-D-Т1 | E-D-Т2 | E-D-ТО | |
P | 75 | 100 | 88 | 73 | 78 | 75 | 70 | 83 | 77 | 55 | 73 | 64 |
R | 70 | 73 | 71,4 | 50 | 64 | 57 | 60 | 64 | 62 | 40 | 55 | 48 |
F | 72,4 | 84,4 | 79 | 59,4 | 70,3 | 65 | 65 | 72 | 68,7 | 46 | 63 | 55 |
Примечание: B-K-Т1 - BERT + K-means для зоны «тянуть»; B-K-Т1 - BERT + K-means для зоны «толкать»; B-K-TO - BERT + K-means для зоны «тянуть-толкать»; B-D-Т1 - BERT + DBSCAN для зоны «тянуть»; B-D-Т2 - BERT + DBSCAN для зоны «толкать»; B-K-TO - BERT + DBSCAN для зоны «тянуть-толкать»; E-K-Т1 - ELMO + K-means для зоны «тянуть»; E-K-Т2 - ELMO + K-means для зоны «толкать»; E-K-TO - ELMO + K-means для зоны «тянуть-толкать»; E-D-Т1 - ELMO + DBSCAN для зоны «тянуть»; E-D-Т2 - ELMO + DBSCAN для зоны «толкать»; E-D-ТO - ELMO + DBSCAN для зоны «тянуть-толкать»
По всем семантическим зонам («тянуть», «толкать», объединенная «тянуть-толкать») и по всем показателям (точность, полнота, F — мера) самые лучшие результаты показал подход с вектором BERT и фильтрацией K-means. При этом из семантических зон лучших показателей удалось достичь для зоны «толкать».
Второе место для зоны «тянуть» занял подход с векторами ELMo и кластеризацией K-means. По точности он меньше на 5%, по полноте на 10%, по F-мере на 7.4%. На 3 месте подход с векторами BERT и кластеризацией DBSCAN, по точности он больше на 3%, но по полноте меньше на 10% и по F-мере меньше на 5.6%. Четвёртое место занял подход ELMo с кластеризацией DBSCAN. По точности он меньше на 18%, по полноте на 10%, по F-мере на 13.4%.
Второе место для зоны «толкать» занял подход с векторами ELMo и кластеризацией K-means. По точности он меньше на 17%, по полноте на 9%, по F-мере на 12.4%. Третье место занял подход с векторами BERT и кластеризацией DBSCAN. По точности он меньше на 5%, по полноте одинаково, по F-мере меньше на 1.7%. Четвертое место занял подход с векторами ELMo и кластеризацией DBSCAN. По точности он меньше на 5%, по полноте на 9%, по F-мере на 6.7%
Второе место для объединенной зоны «тянуть-толкать» также занял подход с векторами ELMo и кластеризацией K-means. По точности он меньше на 11%, по полноте меньше на 9.6%, по F-мере меньше на 1.3%. Третье место занял подход с векторами BERT и кластеризацией K-means. По точности он меньше на 2%, по полноте на 5%, по F-мере на 3.7%. Четвертое место занял также подход с векторами ELMo и кластеризацией DBSCAN. По точности он меньше на 9%, по полноте на 9%, по F-мере на 10%.
7. Выводы
Эксперименты показали влияние как векторов, так и способов фильтрации на результат. Векторы BERT показывают результаты лучше, чем векторы ELMo, а кластеризацией с заданным количеством кластеров K-means лучше, чем кластеризация с автоматическим количеством кластеров DBSCAN. При этом на результат больше влияет именно способ фильтрации, чем тип векторов. Влияние распространяется как на точность, так и на полноту на всех подзонах. Исключение составляет только точность подхода BERT с кластеризацией DBSCAN для зоны «тянуть». Он показал улучшение результатов на 3% относительно подхода ELMo с кластеризацией K-means. Также этот подход является исключением для зоны «толкать» по полноте. Он показал такие же результаты, как алгоритм с векторами ELMo и кластеризацией DBSCAN.
8. Заключение
Для решения задачи лексической типологии применены современные векторные представления и способы кластеризации. Лучшие результаты показал подход c использованием векторов BERT и кластеризацией K-means. Выявлено, что способы фильтрации слов влияют больше, чем векторные представления. Полученные результаты приближены к ручным. Найдены не все фреймы, которые есть в ручном методе, при этом найдены и те, которые не были обнаружены в ручном методе, но они принадлежат зоне «тянуть-толкать». Таким образом, автоматизированные поход не может полностью заменить ручную работу ученых лингвистов, однако может помочь в исследованиях, способствуя увеличению скорости работы и ее полноте.