СРАВНИТЕЛЬНЫЙ АНАЛИЗ СИСТЕМ РАСПОЗНАВАНИЯ РЕЧИ С ОТКРЫТЫМ КОДОМ

Беленко М.В.1, Балакшин П.В.2
1студент, Университет ИТМО, 2кандидат технических наук, ассистент, Университет ИТМО
СРАВНИТЕЛЬНЫЙ АНАЛИЗ СИСТЕМ РАСПОЗНАВАНИЯ РЕЧИ С ОТКРЫТЫМ КОДОМ
Аннотация
В статье проведен сравнительный анализ наиболее распространенных систем автоматического распознавания речи с открытым исходным кодом. При сравнении использовалось множество критериев, включая структуры систем, языки программирования при реализации, наличие подробной документации, поддерживаемые языки распознавания, ограничения накладываемые лицензией. Также были проведены эксперименты на нескольких речевых корпусах для определения скорости и точности распознавания. В результате для каждой из рассмотренных систем были выработаны рекомендации по применению с дополнительным указанием сферы деятельности.
Ключевые слова: распознавание речи, метрика, Word Recognition Rate (WRR), Word Error Rate (WER), Speed Factor (SF), открытый код
Belenko M.V.1, Balakshin P.V.2
1student, ITMO University, 2PhD in Engineering, assistant, ITMO University
COMPARATIVE ANALYSIS OF SPEECH RECOGNITION SYSTEMS WITH OPEN CODE
Abstract
The paper provides the comparison of the most common automatic speech recognition systems with open source code. Many criteria were used at comparison, including system structures, programming languages of implementation, detailed documentation, supported recognition languages, and restrictions imposed by the license. Also, there were conducted the experiments on the several speech bases for determination of speed and accuracy of the recognition. As a result, the recommendations were given for application with additional indication of the scope of activity for each of the systems examined.
Keywords: speech recognition, metric, Word Recognition Rate (WRR), Word Error Rate (WER), Speed Factor (SF), open source code
Системы распознавания речи (англ. Automatic Speech Recognition Systems) в основном используются для моделирования привычного для человека общения с машиной, например, для голосового управления программами. В настоящее время распознавание речевых сигналов применяется в широком спектре систем – от приложений на смартфонах до систем “Умный дом” [16]. Дополнительным подтверждением актуальности данной области является множество научно-исследовательских центров и центров разработки по всему миру. Однако подавляющее большинство работающих систем являются проприетарными продуктами, т.е. пользователь или потенциальный разработчик не имеет доступа к их исходному коду. Это негативно сказывается на возможности интеграции систем распознавания речи в проекты с открытым кодом. Также не существует какого либо централизованного источника данных, описывающего положительные и отрицательные стороны систем распознавания речи с открытым кодом. В результате возникает проблема выбора оптимальной системы распознавания речи для решения поставленной задачи.
Целью исследования является выработка рекомендаций по применению систем распознавания речи с открытым исходным кодом для уменьшения затрат при выборе системы для коммерческой или научно-исследовательской деятельности.
В рамках работы были рассмотрены шесть систем с открытым исходным кодом: CMU Sphinx, HTK, iAtros, Julius, Kaldi и RWTH ASR. Выбор основан на частоте упоминания в современных научно-исследовательских журналах, существующими разработками последних лет и популярности у индивидуальных разработчиков программного обеспечения [2], [3], [6-8], [10], [11], [13], [14]. Выбранные системы сравнивались по таким показателям, как точность и скорость распознавания, удобство использования и внутренняя структура.
По точности системы сравнивались по наиболее распространенным метрикам [17]: Word Recognition Rate (WRR), Word Error Rate (WER), которые вычисляются по следующим формулам:
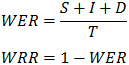
где S – число операций замены слов, I – число операций вставки слов, D – число операций удаления слов из распознанной фразы для получения исходной фразы, а Т – число слов в исходной фразе и измеряется в процентах. По скорости распознавания сравнение было проведено с использованием Real Time Factor – показателя отношения времени распознавания к длительности распознаваемого сигнала, также известного как Speed Factor (SF). Данный показатель можно рассчитать используя формулу:
![]()
где Трасп – время распознавания сигнала, Т – его длительность и измеряется в долях от реального времени.
Все системы были обучены с применением речевого корпуса WSJ1 (Wall Street Journal 1), содержащего около 160 часов тренировочных данных и 10 часов тестовых данных, представляющих собой отрывки из газеты Wall Street Journal. Данный речевой корпус включает в себя записи дикторов обоих полов на английском языке.
После проведения эксперимента и обработки результатов была получена следующая таблица (табл. 1).
Таблица 1 - Результаты сравнения по точности и скорости
| Система | WER, % | WRR, % | SF |
| HTK | 19,8 | 80,2 | 1.4 |
| CMU Sphinx (pocketsphinx/sphinx4) | 21.4/22.7 | 78.6/77.3 | 0.5/1 |
| Kaldi | 6.5 | 93.5 | 0.6 |
| Julius | 23.1 | 76.9 | 1.3 |
| iAtros | 16.1 | 83.9 | 2.1 |
| RWTH ASR | 15.5 | 84.5 | 3.8 |
Точность и корректность исследования подтверждается тем, что полученные результаты схожи с результатами, полученными при тестировании данных систем на других речевых корпусах, таких как Verbmobil 1, Quaero, EPPS [2], [4], [9].
В качестве критериев сравнения структур были выбраны язык реализации системы, алгоритмы, используемые при распознавании, форматы входных и выходных данных и непосредственно внутренняя структура программной реализации системы.
Процесс распознавания речи в общем виде можно представить в виде следующих этапов [15]:
- Извлечение акустических признаков из входного сигнала.
- Акустическое моделирование.
- Языковое моделирование.
- Декодирование.
Подходы, алгоритмы и структуры данных, используемые рассматриваемыми системами распознавания речи на каждом из перечисленных этапов представлены в таблицах (табл. 2, 3).
Таблица 2 - Результаты сравнения алгоритмов
| Система | Извлечение признаков | Акустическое моделирование | Языковое модели-рование | Распознавание |
| HTK | MFCC | HMM | N-gramm | Алгоритм Витерби |
| CMU Sphinx (pocketsphinx/ sphinx4) | MFCC, PLP | HMM | N-gramm, FST | Алгоритм Витерби, алгоритм bushderby |
| Kaldi | MFCC, PLP | HMM,GMM, SGMM, DNN | FST, есть конвертер N-gramm->FST | Двухпро-ходной алгоритм прямого-обратного хода |
| Julius | MFCC, PLP | HMM | N-gramm, Rule-based | Алгоритм Витерби |
| iAtros | MFCC | HMM, GMM | N-gramm, FST | Алгоритм Витерби |
| RWTH ASR | MFCC, PLP, voicedness | HMM, GMM | N-gramm, WFST | Алгоритм Витерби |
Таблица 3 - Языки реализации систем и их структура
| Система | Язык | Структура |
| HTK | С | Модульная, в виде утилит |
| CMU Sphinx (pocketsphinx/sphinx4) | C/Java | Модульная |
| Kaldi | C++ | Модульная |
| Julius | C | Модульная |
| iAtros | C | Модульная |
| RWTH ASR | C++ | Модульная |
С точки зрения удобства использования рассматривались такие показатели как подробность документации, поддержка различных программных и аппаратных сред выполнения, лицензионные ограничения, поддержка множества естественных языков распознавания, характеристики интерфейса. Результаты представлены в следующих таблицах (табл. 4, 5, 6, 7, 8).
Таблица 4 - Наличие документации
| Система | Документация |
| HTK | HTK Book – исчерпывающая информация |
| CMU Sphinx (pocketsphinx/sphinx4) | Подробная онлайн документация |
| Kaldi | Подробная онлайн документация |
| Julius | Julius Book – аналогично HTK Book |
| iAtros | Отсутствие документации |
| RWTH ASR | Неподробная документация |
Таблица 5 - Поддержка различных операционных систем
| Система | Поддерживаемые ОС |
| HTK | Linux, Solaris, HPUX, IRIX, Mac OS, FreeBSD, Windows |
| CMU Sphinx (pocketsphinx/sphinx4) | Linux, Mac OS, Windows, Android |
| Kaldi | Linux, Windows, FreeBSD |
| Julius | Linux, Windows, FreeBSD, Mac OS |
| iAtros | Linux |
| RWTH ASR | Linux, Mac OS |
Таблица 6 - Интерфейсы систем
| Система | Интерфейс |
| HTK | Консольный, API |
| CMU Sphinx (pocketsphinx/sphinx4) | Консольный, API |
| Kaldi | Консольный |
| Julius | Консольный, API |
| iAtros | Консольный |
| RWTH ASR | Консольный |
Таблица 7 - Поддерживаемые языки распознавания
| Система | Языки |
| HTK | Английский |
| CMU Sphinx (pocketsphinx/sphinx4) | Множество языков, в том числе экзотические |
| Kaldi | Английский |
| Julius | Японский, Английский |
| iAtros | Английский, Испанский |
| RWTH ASR | Английский |
Таблица 8 - Лицензии
| Система | Лицензия |
| HTK | HTK |
| CMU Sphinx (pocketsphinx/sphinx4) | BSD |
| Kaldi | Apache |
| Julius | BSD подобная |
| iAtros | GPLv3 |
| RWTH ASR | RWTH ASR |
Проанализировав полученные выше результаты, можно составить характеристику каждой из рассматриваемых систем и выработать рекомендации по их применению.
Kaldi. Данная система показывает лучшую точность распознавания из всех рассматриваемых систем (WER=6.5%) и вторую скорость распознавания (SF=0.6). С точки зрения предоставляемых алгоритмов и структур данных, применяемых для распознавания речи, данная система тоже лидирует, так как предоставляет наибольшее количество современных подходов, применяющихся в сфере распознавания речи, таких как использование нейронных сетей и моделей гауссовых смесей на этапе акустического моделирования и использование конечных автоматов на этапе языкового моделирования. Также она позволяет использовать множество алгоритмов для уменьшения размера акустических признаков сигнала, и, соответственно, увеличивать производительность системы. Kaldi написана на языке программирования С++, что положительно сказывается на скорости работы системы, и имеет модульную структуру, что предоставляет возможность легко производить рефакторинг системы, добавление нового функционала, а также исправлять существующие ошибки. С точки зрения удобства использования Kaldi, также является одной из первых систем. Она предоставляет подробную документацию, но ориентированную на опытных в сфере распознавания речи читателей. Это может негативно сказаться на использовании данной системы новичками в этой области. Она кроссплатформенна, то есть запускается на большинстве современных операционных систем. Kaldi предоставляет только консольный интерфейс, что делает ее интеграцию в сторонние приложения затруднительной. По умолчанию данная система поддерживает только английский язык, распространяется под полностью свободной лицензией Apache, то есть может быть интегрирована в коммерческий продукт без раскрытия его кода. Данная система может с успехом применяться для научно-исследовательской деятельности, так как обеспечивает хорошую точность распознавания, приемлемую скорость распознавания, реализует множество современных методов распознавания речи, имеет множество готовых рецептов, что делает ее простой в использовании и обладает исчерпывающей документацией.
CMU Sphinx. Эта система распознавания речи показывает посредственную точность распознавания (WER~22%) и лучшую скорость распознавания из всех рассмотренных (SF=0.5). Нужно заметить, что наибольшая скорость распознавания достигается при использовании декодера pocketsphinx, написанного на С, декодер sphinx4 показывает вполне среднюю скорость работы (SF=1). Структурно данная система также использует множество современных подходов к распознаванию речи, включая модифицированный алгоритм Витерби, однако используемых подходов меньше, чем у Kaldi. В частности, на этапе акустического моделирования данная система работает только со скрытыми марковскими моделями. CMU Sphinx включает в себя два декодера – pocketsphinx, реализованный на С, и sphinx4, реализованный на Java. Это позволяет применять данную систему на множестве платформ, в том числе под управлением операционной системы Android, а также облегчает интеграцию в проекты, написанные на Java. Данная система имеет модульную структуру, что положительно сказывается на возможности быстрого внесения изменений и исправления ошибок. С токи зрения удобства использования CMU Sphinx опережает Kaldi, так как кроме консольного интерфейса предоставляет API, что существенно упрощает процесс встраивания системы в стороннее приложение. Также она обладает подробной документацией, ориентированной, в отличие от Kaldi, на начинающего разработчика, что сильно упрощает процесс знакомства с системой. Также сильной стороной данной системы является поддержка множества языков по умолчанию, то есть наличие языковых и акустических моделей этих языков в свободном доступе. Среди поддерживаемых языков кроме стандартного английского встречаются также русский, казахский и ряд других. СMU Sphinx распространяется под лицензией BSD, что разрешает ее встраивание в коммерческие проекты. Данная система может применяться в коммерческих проектах, так как обладает большинством достоинств Kaldi, хотя и обеспечивает несколько худшую точность распознавания, а также предоставляет API, которое можно использовать для построения сторонних приложений на базе данной системы.
HTK. С точки зрения точности и скорости работы данная система показывает средние результаты из рассмотренных систем (WER=19.8%, SF=1.4). HTK предоставляет только классические в сфере распознавания речи алгоритмы и структуры данных. Это связано с тем, что с тем, что выпуск предыдущей версии системы был произведен в 2009 году. В конце декабря 2015 года была выпущена новая версия HTK, однако она не была рассмотрена в данном исследовании. Реализована данная система на языке С, что хорошо отражается на скорости работы, так как C является низкоуровневым языком программирования. По структуре данная система представляет собой набор утилит, вызываемых из командной строки, а также предоставляет API, известное под названием ATK. С точки зрения удобства использования HTK, наравне с Julius, является лидирующей системой из рассмотренных. В качестве документации она предоставляет HTK Book – книгу, описывающую не только аспекты работы HTK, но и общие принципы работы систем распознавания речи. По умолчанию данная система поддерживает только английский язык. Распространяется под лицензией HTK, которая разрешает распространение исходного кода системы. Данную систему можно порекомендовать для использования в образовательной деятельности в сфере распознавания речи. Она реализует большинство классических подходов к решению проблемы распознавания речи, обладает очень подробной документацией, которая также описывает основные принципы распознавания речи в целом, и имеет множество обучающих статей и рецептов.
Julius. Данная система показывает худший показатель точности (WER=23.1) и средний показатель скорости распознавания (SF=1.3). Этапы акустического и языкового моделирования осуществляются с помощью утилит, входящих в состав HTK, однако декодирование происходит с помощью своего декодера. Он, как и большинство рассмотренных систем, использует алгоритм Витерби. Реализована данная система на языке С, структура реализации является модульной. Система предоставляет консольный интерфейс и API для интеграции в сторонние приложения. Документация, как и в HTK, реализована в форме книги Julius book. По умолчанию Julius поддерживает английский и японский языки. Распространяется под BSD подобной лицензией. Систему Julius можно также порекомендовать для образовательной деятельности, так как она обладает всеми плюсами HTK, и также предоставляет возможность распознавать такой экзотический язык как японский.
Iatros. Данная система показывает хороший результат по точности распознавания (WER=16.1%) и посредственный результат по скорости (SF=2.1). Она весьма ограничена в возможностях касательно алгоритмов и структур данных, применяющихся при распознавании речи, однако предоставляет возможность использовать модели гауссовых смесей в качестве состояний скрытой марковской модели на этапе акустического моделирования. Реализована данная система на языке С. Имеет модульную структуру. Кроме функционала распознавания речи содержит в себе также модуль распознавания текста. Это не имеет большого значения для данного исследования, однако является отличительно особенностью данной системы, про которую нельзя не упомянуть. С точки зрения удобства использования iAtros проигрывает всем рассмотренным в ходе исследования системам. Данная система не обладает документацией, не предоставляет API для встраивания в сторонние приложения, из поддерживаемых по умолчанию языков представлены английский и испанский. Является совершенно не кроссплатформенной, так как запускается только под управлением операционных систем семейства Linux. Распространяется под лицензией GPLv3, которая не позволяет встраивать данную систему в коммерческие проекты без раскрытия их исходного кода, что делает ее непригодной для использования в коммерческой деятельности. Система iAtros с успехом может использоваться там, где кроме распознавания речи необходимо еще применение распознавания образов, так как данная система предоставляет такую возможность.
RWTH ASR. По точности распознавания RWTH ASR показывает неплохой результат (WER=15.5%), однако по скорости распознавания является худшей системой из рассмотренных (SF=3.8). Данная система так же как и iAtros может использовать модели гауссовых смесей на этапе акустического моделирования. Отличительной чертой является возможность использования характеристики звонкости при извлечении акустических характеристик входного сигнала. Также данная система может использовать взвешенный конечный автомат в качестве языковой модели на этапе языкового моделирования. Данная система реализована на языке С++ и имеет модульную архитектуру. По удобству использования является второй с конца, имеет документацию, описывающую только процесс установки, чего явно недостаточно для начала работы с системой. Предоставляет только консольный интерфейс, по умолчанию поддерживает только английский язык. Система недостаточно кроссплатформенна, так как не может работать под управлением операционной системы Windows, которая сильно распространена в настоящее время. Распространяется под лицензией RWTH ASR, по которой код системы предоставляется только для некоммерческого использования, что делает данную систему непригодной для интеграции в коммерческие проекты. Данная система может применяться для решения задач, где важна точность распознавания, но не важно время. Также стоит заметить, что она совершенно непригодна для какой-либо коммерческой деятельности из-за ограничений, накладываемых лицензией.
Список литературы / References
- CMU Sphinx Wiki [Электронный ресурс]. – URL: http://cmusphinx.sourceforge.net/wiki/ (дата обращения: 09.01.2017)
- Gaida C. Comparing open-source speech recognition toolkits [Электронный ресурс]. / C. Gaida et al. // Technical Report of the Project OASIS. – URL: http://suendermann.com/su/pdf/oasis2014.pdf (дата обращения: 12.02.2017)
- El Moubtahij H. Using features of local densities, statistics and HMM toolkit (HTK) for offline Arabic handwriting text recognition / H. El Moubtahij, A. Halli, K. Satori // Journal of Electrical Systems and Information Technology – 2016. – V. 3. №3. – P. 99-110.
- Jha M. Improved unsupervised speech recognition system using MLLR speaker adaptation and confidence measurement / M. Jha et al. // V Jornadas en Tecnologıas del Habla (VJTH’2008) – 2008. – P. 255-258.
- Kaldi [Электронный ресурс]. – URL: http://kaldi-asr.org/doc (дата обращения: 19.12.2016)
- Luján-Mares M. iATROS: A SPEECH AND HANDWRITING RECOGNITION SYSTEM / M. Luján-Mares, V. Tamarit, V. Alabau et al. // V Journadas en Technologia del Habla – 2008. – P. 75-58.
- El Amrania M.Y. Building CMU Sphinx language model for the Holy Quran using simplified Arabic phonemes / M.Y. El Amrania, M.M. Hafizur Rahmanb, M.R. Wahiddinb, A. Shahb // Egyptian Informatics Journal – 2016. – V. 17. №3. – P. 305–314.
- Ogata K. Analysis of articulatory timing based on a superposition model for VCV sequences / K. Ogata, K. Nakashima // Proceedings of IEEE International Conference on Systems, Man and Cybernetics – 2014. – January ed. – P. 3720-3725.
- Sundermeyer The rwth 2010 quaero asr evaluation system for english, french, and german / M. Sundermeyer et al. // Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP) – 2011. – P. 2212-2215.
- Алимурадов А.К. АДАПТИВНЫЙ МЕТОД ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ГОЛОСОВОГО УПРАВЛЕНИЯ / А.К. Алимурадов, П.П. Чураков // Труды Международной научно-технической конференции «Перспективные информационные технологии» – 2016. – С. 196-200.
- Бакаленко В.С. Интеллектуализация ввода-вывода кода программы с помощью речевых технологий: дис. ... магистра техники и технологии. – ДонНТУ, Донецк, 2016.
- Балакшин П.В. Алгоритмические и программные средства распознавания речи на основе скрытых марковских моделей для телефонных служб поддержки клиентов: дис. … канд. техн. наук : 05.13.11 : защищена 10.12.2015 : утв. 08.06.2016 / Балакшин Павел Валерьевич. – СПб.: Университет ИТМО, 2014. – 127 с.
- Балакшин П.В. ФУНКЦИЯ ПЛОТНОСТИ ДЛИТЕЛЬНОСТИ СОСТОЯНИЙ СММ. ПРЕИМУЩЕСТВА И НЕДОСТАТКИ / П.В. Балакшин // Современные проблемы науки и образования. – 2011. – № 1. – С. 36-39. URL: http://www.science-education.ru/ru/article/view?id=4574 (дата обращения: 13.11.2016).
- Беленко М.В. СРАВНИТЕЛЬНЫЙ АНАЛИЗ СИСТЕМ РАСПОЗНАВАНИЯ РЕЧИ С ОТКРЫТЫМ КОДОМ / М.В. Беленко // Сборник трудов V Всероссийского конгресса молодых ученых. Т. 2. – СПб.: Университет ИТМО, 2016. – С. 45-49.
- Гусев М.Н. Система распознавания речи: основные модели и алгоритмы / М.Н. Гусев, В.М. Дегтярев. – СПб.: Знак, 2013. – 128 с.
- Карпов А.А. Многомодальные ассистивные системы для интеллектуального жилого пространства / А.А. Карпов, Л. Акарун, А.Л. Ронжин // Труды СПИИРАН. – 2011. – Т. 19. – №. 0. – С. 48-64.
- Карпов А.А. Методология оценивания работы систем автоматического распознавания речи / А.А. Карпов, И.С. Кипяткова // Известия высших учебных заведений. Приборостроение. – 2012. – Т. 55. – №. 11. – С. 38-43.
- Тампель И.Б. Автоматическое распознавание речи – основные этапы за 50 лет / И.Б. Тампель // Научно-технический вестник информационных технологий, механики и оптики. – 2015. – Т. 15. – № 6. – С. 957–968.
Список литературы на английском / References in English
- CMU Sphinx Wiki [Electronic resource]. – URL: http://cmusphinx.sourceforge.net/wiki/ (accessed: 09.01.2017).
- Gaida C. Comparing open-source speech recognition toolkits [Electronic resource]. / C. Gaida et al. // Technical Report of the Project OASIS. – URL: http://suendermann.com/su/pdf/oasis2014.pdf (accessed: 12.02.2017)
- El Moubtahij, H. Using features of local densities, statistics and HMM toolkit (HTK) for offline Arabic handwriting text recognition / H. El Moubtahij, A. Halli, K. Satori // Journal of Electrical Systems and Information Technology – 2016. – V. 3. №3. – P. 99-110.
- Jha, M. Improved unsupervised speech recognition system using MLLR speaker adaptation and confidence measurement / M. Jha et al. // V Jornadas en Tecnologıas del Habla (VJTH’2008) – 2008. – P. 255-258.
- Kaldi [Electronic resource]. – URL: http://kaldi-asr.org/doc (accessed: 19.12.2016)
- Luján-Mares, M. iATROS: A SPEECH AND HANDWRITING RECOGNITION SYSTEM / M. Luján-Mares, V. Tamarit, V. Alabau et al. // V Journadas en Technologia del Habla – 2008. – P. 75-58.
- El Amrania, M.Y. Building CMU Sphinx language model for the Holy Quran using simplified Arabic phonemes / M.Y. El Amrania, M.M. Hafizur Rahmanb, M.R. Wahiddinb, A. Shahb // Egyptian Informatics Journal – 2016. – V. 17. №3. – P. 305–314.
- Ogata, K. Analysis of articulatory timing based on a superposition model for VCV sequences / K. Ogata, K. Nakashima // Proceedings of IEEE International Conference on Systems, Man and Cybernetics – 2014. – January ed. – P. 3720-3725.
- Sundermeyer, M. The rwth 2010 quaero asr evaluation system for english, french, and german / M. Sundermeyer et al. // Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP) – 2011. – P. 2212-2215.
- Alimuradov A.K. ADAPTIVNYJ METOD POVYShENIJa JeFFEKTIVNOSTI GOLOSOVOGO UPRAVLENIJa [ADAPTIVE METHOD OF IMPROVING EFFICIENCY OF VOICE CONTROL] / A.K. Alimuradov, P.P. Churakov // Trudy Mezhdunarodnoj nauchno-tehnicheskoj konferencii «Perspektivnye informacionnye tehnologii» [Proceedings of the International Scientific and Technical Conference «Perspective Information Technologies»]. – 2016. – P. 196-200. [in Russian]
- Bakalenko V.S. Intellektualizatsiya vvoda-vyivoda koda programmyi s pomoschyu rechevyih tehnologiy [Intellectualization of program’s code input/output with the help of speech technologies]: dis. ... of Master in Engineering and Technology. – DonNTU, Donetsk, 2016.
- Balakshin P.V. Algoritmicheskie i programmnyie sredstva raspoznavaniya rechi na osnove skryityih markovskih modeley dlya telefonnyih sluzhb podderzhki klientov [Algorithmic and software speech recognition tools on the basis of hidden Markov models for telephone customer support services]: dis. … PhD in Engineering : 05.13.11: defense of the thesis 10.12.2015 : approved 08.06.2016 / Balakshin Pavel Valer'evich. – SPb.: ITMO University, 2014. – 127 p. [in Russian]
- Balakshin P.V. FUNKCIJa PLOTNOSTI DLITEL'NOSTI SOSTOJaNIJ SMM. PREIMUShhESTVA I NEDOSTATKI [DENSITY FUNCTION OF DURATION IN STATES OF HMM. ADVANTAGES AND LIMITATIONS] / P.V. Balakshin // Sovremennye problemy nauki i obrazovanija [Modern problems of science and education]. – 2011. – № 1. – P. 36-39. URL: http://www.science-education.ru/ru/article/view?id=4574 (accessed: 13.11.2016). [in Russian]
- Belenko M.V. SRAVNITELNYY ANALIZ SISTEM RASPOZNAVANIYA RECHI S OTKRYTYM KODOM [ANALYSIS AND COMPARISON OF THE OPEN SOURCE SPEECH RECOGNITION SYSTEMS] / M.V. Belenko // Sbornik trudov V Vserossiyskogo kongressa molodyih uchenyih [Collection of Proceedings of the V All-Russian Congress of Young Scientists]. V. 2. – SPb.: ITMO University, 2016. P. 45-49. [in Russian]
- Gusev M.N. Sistema raspoznavaniya rechi: osnovnyie modeli i algoritmyi [Speech recognition system: basic models and algorithms] / M.N. Gusev V.M. Degtyarev. – SPb.: Znak, 2013. – 141 p. [in Russian]
- Karpov A.A. Mnogomodalnyie assistivnyie sistemyi dlya intellektualnogo zhilogo prostranstva [Multi-modal assistive systems for intelligent living space] / A.A. Karpov, L. Akarun, A.L. Ronzhin // Trudyi SPIIRAN [Proceedings of SPIIRAS]. – 2011. – V. 19. – №. 0. – P. 48-64. [in Russian]
- Karpov A.A. Metodologiya otsenivaniya rabotyi sistem avtomaticheskogo raspoznavaniya rechi [Methodology for evaluating the operation of automatic speech recognition systems] / A.A. Karpov, I.S. Kipyatkova // Izvestiya vyisshih uchebnyih zavedeniy. Priborostroenie. [Journal of Instrument Engineering] – 2012. – V. 55. – №. 11. – P. 38-43. [in Russian]
- Tampel I.B. Avtomaticheskoe raspoznavanie rechi – osnovnyie etapyi za 50 let [Automatic speech recognition - the main stages of 50 years] / I.B. Tampel // Nauchno-Tehnicheskii Vestnik Informatsionnykh Tekhnologii, Mekhaniki i Optiki [Scientific and Technical Journal of Information Technologies, Mechanics and Optics]. – 2015. – V. 15. – № 6. – P. 957–968. [in Russian]