ПРОЕКТИРОВАНИЕ И РАЗРАБОТКА СИСТЕМЫ С ИСПОЛЬЗОВАНИЕМ ПАРСИНГА ПРЕДЛОЖЕНИЙ ДЛЯ РАБОТЫ С ИНОСТРАННОЙ ЛИТЕРАТУРОЙ

Ващук И. Н.1, Яхницкий С. А.2
1ORCID: 0000-0003-2047-1910, Кандидат педагогических наук, 2ORCID: 0000-0002-4456-134X, студент, Оренбургский государственный университет
ПРОЕКТИРОВАНИЕ И РАЗРАБОТКА СИСТЕМЫ С ИСПОЛЬЗОВАНИЕМ ПАРСИНГА ПРЕДЛОЖЕНИЙ ДЛЯ РАБОТЫ С ИНОСТРАННОЙ ЛИТЕРАТУРОЙ
Аннотация
В статье рассмотрено – проектирование и разработка системы с использованием парсинга предложений для работы с иностранной литературой, что определяется необходимостью оптимизации процесса чтения и перевода англоязычной литературы. В настоящее время существует несколько отдельных систем, которые либо обладают узкой областью применения, либо являются профессиональными средствами с высокой стоимостью. Разрабатываемая система предполагает объединение ключевых особенностей существующих продуктов в единой системе, что позволит, систематизировано и эффективно читать и переводить англоязычную литературу, повышать навык владения английским языком.
Ключевые слова: автоматизация, обработка текстов, синтаксические деревья.Vashchuk I. N.1, Janicki S. A.2
1ORCID: 0000-0003-2047-1910, PhD in Pedagogy, 2ORCID: 0000-0002-4456-134X, Student, Orenburg State University
DESIGN AND DEVELOPMENT OF SYSTEM WITH THE USE OF PARSING SENTENCES TO WORK WITH FOREIGN LITERATURE
Abstract
In the article - the system design and development with parsing sentences to work with foreign literature, as determined by the need to optimize the reading and translation of English literature process. Currently, there are several separate systems that have a narrow field of application, either professional tools are of high value. The developed system involves pooling the key features of existing products in a single system that will allow, systematically and efficiently read and translate English-language literature, to improve English language skills.
Keywords: automation, word processing, syntactic trees.В настоящее время в мире одним из важнейших ресурсов является информация, а крупнейшим её источником является всемирная сеть Интернет. Количество представленных сайтов в сети увеличилось с 10 миллионов в 2000 году до более чем одного миллиарда в 2014 году (по данным компании Netcraft).Их большую часть, а именно 55% (по данным сайта W3Techs.com) составляют сайты на английском языке. Этот факт указывает на необходимость знания английского языка для современного человека.Для людей, занимающихся научной деятельностью и/или программированием эта проблема ещё более актуальна, поскольку большинство научных статей международного уровня и большая часть пособий и документации по программированию издаются на английском языке.
Из всего вышеперечисленного следует, что необходимость оптимизации процесса чтения и перевода англоязычной литературы является актуальной проблемой.Поэтому основным процессом, требующим автоматизации явилась необходимость обработки текстов на естественных языках, грамматика которых не приспособлена для их полной автоматизированной обработки (рис.1).
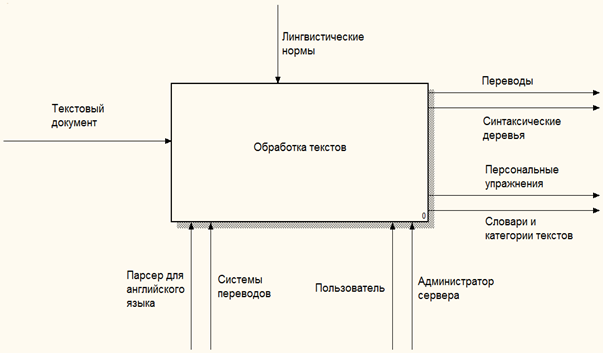
Рис. 1 – Функциональная модель работы программного средства
В настоящее время существует множество программных средств, предназначенных для различных аспектов работы с иностранной литературой. Но такое их разнообразие приводит к большим затратам времени для взаимодействия между ними. На рисунке 2 представлена процедура перевода текста. Хотя множество людей используют не все шаги и не в данной последовательности, схема довольно подробно покрывает данный процесс. На шагах 2, 4-8 используются различные программные средства.
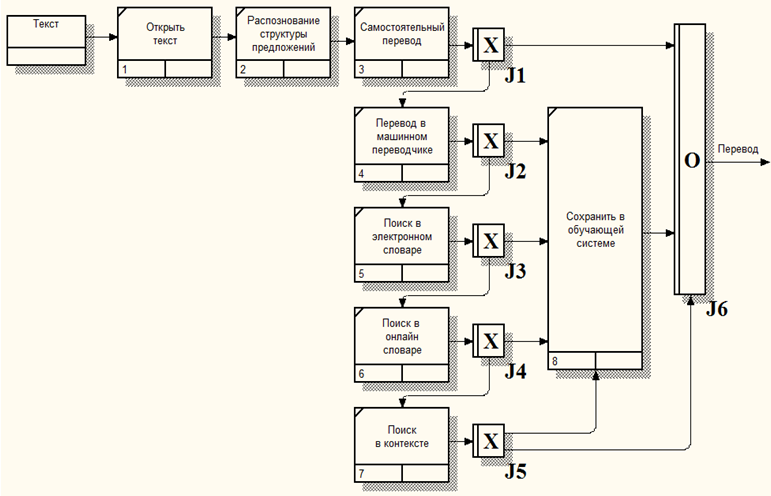
Рис. 2 – Процедура перевода текста
На данный момент существует множество средств, облегчающих работу переводчика. Одной из проблем при переводе является понимание грамматической структуры предложения. Одним из решений является использование парсера, который в удобной графической форме представляет грамматические связи в предложении.
Парсер естественного языка – это программа, которая выражает грамматическую структуру предложений, например, какие слова идут вместе (как «фразы») и какие слова являются предметом или субъектом глагола. Вероятностные парсер используют знания языка, полученные из разобранных вручную предложений, для того чтобы получить наиболее вероятный анализ новых предложений. В таких парсерах всё ещё существует вероятность ошибки, но в общем случае качество анализа довольно высоко. Их разработка была одним из крупнейших прорывов в области обработки естественных языков в 1990-е годы.
Используемый парсер является реализацией вероятностного парсера естественного языка. Исходная версия данного парсера была преимущественно написана Дэном Клейном, с использованием кода и разработанной лингвистической грамматики Кристофера Маннинга.
Лексикализованный вероятностный парсер реализует факторизованную производную модель с отдельными анализаторами «PCFG» фразовой структуры и лексический зависимостей, которые совмещены для получения эффективного точного вывода с использованием А*-алгоритма.
Для графического вывода структуры предложений используется утилита «DependenSee», разработанная Аваисом Атаром.
Цель работы – создание программного средства в качестве основы для информационной системы, повышающей удобство и эффективность работы с иностранной литературой. Данная система будет объединять в себе преимущества следующих средств, используемых в процессе работы с иностранной литературой:
- ридер (электронная книга);
- парсер (структура предложений);
- электронный переводчик (механический);
- электронный словарь (фиксированный);
- онлайн словарь (пополняемый);
- поисковая система (похожие тексты);
- обучающая система (закрепление лексики).
При работе с программой все запросы на перевод пользователем сохраняются для формирования пользовательского словаря и дальнейшего использования в обучающей системе. Принцип формирования запросов на перевод ориентирован на оптимизацию количества запросов к серверу, схема представлена на рисунке 3. Запрос происходит иерархически, и если лексема отсутствует на нижнем уровне, то она запрашивается на более высоком, а затем сохраняется на всех подуровнях. Если же запрошенный перевод найден не был, то корректность запроса проверяется специализированным алгоритмом или вручную администратором сервера.
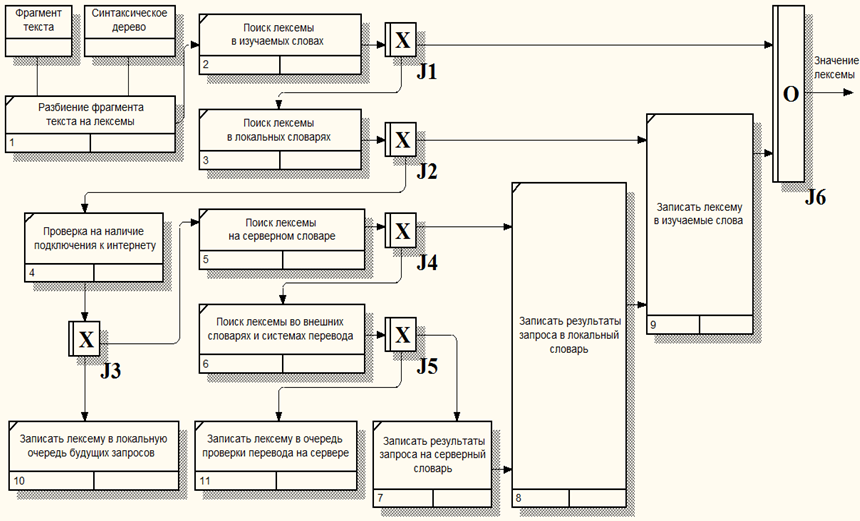
Рис. 3 – Алгоритм формирования запросов при переводе
Уникальной особенностьюразрабатываемого приложения является использование парсера Стэндфордского университета для разбиения предложения на лексемы, распространяемого по свободной лицензии.Это позволит обеспечить перевод для произвольно выделенных фрагментов текста без утери их синтаксической структуры, что в свою очередь повышает качество перевода. Данная методика не автоматизирует процесс перевода, но способствует более глубокому пониманию структуры предложения пользователем. Общая схема модуля перевода теста представлена на рисунке 4.
Разрабатываемое программное средство является только основой для информационной системы работы с иностранной литературой, но планируется внедрение методов кластерного анализа для категоризации и поиска похожих текстов и обучающей системыв качестве модулей, что также является уникальной идеей, применительно к данной информационной системе.
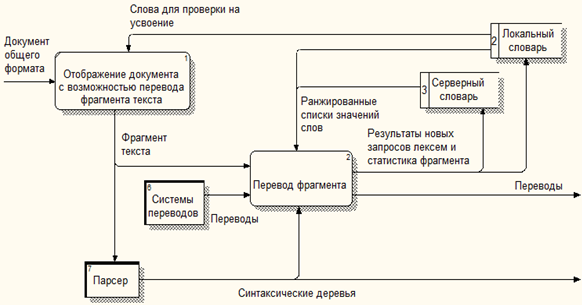
Рис. 4 – Модуль отображения и перевода текста
Для проектирования программ было решено пользоваться методами объектно-ориентированного программирования (ООП), как наиболее удобными для проектирования программных комплексов с возможностью расширения их в будущем, из-за большой гибкости модификации и возможности оперирования со структурами данных как с некоторыми абстрактными объектами.
Основными качествами системы являются:
- простой и понятный интерфейс, ориентированный на непрофессионального пользователя;
- интеграция средств перевода в режим чтения текстов;
- редактирование и хранение результатов перевода;
- кроссплатформенность.
В результате была разработана система, состоящая из клиентского приложения, предназначенного для чтения текстов с возможностью перевода, и серверного приложения, служащего основой для расширения функционала. Клиентское приложение разработано на языках HTML5, CSS3, JavaScript в среде NW.js. Для клиентского приложения был использован Linux-сервер с использованием Node.js.
В соответствии с исходным заданием и проведённым обзором аналогов было решено хранить книги пользователя в персональной библиотеке, которая должна быть доступна с устройств на различных платформах. Все документы должны обладать легко редактируемыми настройками отображения. Программное средство должно активно задействовать интернет, но также иметь возможность работы офлайн. Должны применяться как машинный, так и словарно-лексемный подходы к переводу.
На данный момент разработана модель программного средства и создан прототип клиентского приложения. Приложение проходит апробацию на базе факультета филологии и журналистики Оренбургского государственного университета. Проект награждён дипломом второй степени на конкурсе «Университетская IT-весна 2015». На разработку системы Фондом содействия развития малых форм предприятий в научно-технической сфере выделен грант по программе УМНИК-2015.
Список литературы / References
- Зубов А. В. Информационные технологии в лингвистике: М.: Академия 2004. – С.195-196.
- Соловьева А. В. Профессиональный перевод с помощью компьютера: СПб.: Питер 2008. – С.140-147.
- Шевчук В. Н. Электронные ресурсы переводчика: М.: Либрайт, 2010. – С.100-120.
- Библиотека MSDN. Источник информации для разработчиков, использующих средства, продукты, технологии и службы корпорации Майкрософт. [Электронный ресурс]. – Режим доступа: http://msdn.microsoft.com
- Машинный перевод: исторический обзор и преимущества [Электронный ресурс]: Компания ПРОМТ. — Режим доступа: https://goo.gl/P7cleX
Список литературы на английском языке / References in English
- Zubov A. V. Informacionnye tehnologii v lingvistike [The Information technologies in linguistics] M.: the Academy 2004. – P. 195-196. [in Russian]
- Solov'eva A. V. Professional'nyj perevod s pomoshh'ju komp'jutera [Professional translation by computer] SPb.: Peter 2008. – S. 140-147. [in Russian]
- Shevchuk V. N. Jelektronnye resursy perevodchika [Electronic resources the translator] M.: Librit, 2010. – S. 100-120. [in Russian]
- MSDN. Istochnik informacii dlja razrabotchikov, ispol'zujushhih sredstva, produkty, tehnologii i sluzhby korporacii Majkrosoft. [The MSDN library. Source of information for developers using the tools, products, technologies and services from Microsoft.] [Electronic resource]. – Mode of access: http://msdn.microsoft.com
- Mashinnyj perevod: istoricheskij obzor i preimushhestva [Machine translation: a historical overview and benefits] [Elektron-NYY Resurs]:PROMT.-Mode of access: https://goo.gl/P7cleX