Big Data Method for Content Analysis (on the example of the regional mass media of the socio-political newspaper "Vechernaya Ufa")
Big Data Method for Content Analysis (on the example of the regional mass media of the socio-political newspaper "Vechernaya Ufa")
Abstract
The aim of this article is to compare traditional content analysis and its analogue based on big data analysis in order to identify the specifics of the latter, its capabilities and limitations. For illustrative purposes, the work presents the result of machine analysis of the news column of the regional newspaper "Vechernaya Ufa" on the impact of the Special Military Operation in Ukraine on the news agenda of the publication. In the main part of the article the conducted research is analysed from the point of view of its methodological characteristics, its advantages (speed, work with the general population) and disadvantages (rough work with language, inability to take into account the context) are disclosed. The conclusion is made about the heuristic value of big data analysis, but also about its insufficiency for a full-fledged research.
1. Введение
Современные научные исследования редко обходятся без применения новых цифровых инструментов и методов – развитие технологий и техники диктует ученым новые подходы к проведению исследований. Одним из таких инструментов являются анализ больших данных и основывающиеся на нем конкретные научные методы. Например, метод контент-анализа известен уже давно, но появление специальных программ и средств расширило его возможности и сделало более доступным. Так, например, значительную популярность набирает анализ социальных сетей (, , и др.) и электронных СМИ и прочих источников информации (, , и др.).
Контент-анализ в первую очередь является количественным методом – его характеризуют как формализованный, систематизированный и строгий , что облегчает его трансфер в машинную среду, также оперирующую формализованными единицами, однако для применения этого метода важно выявить, как именно перевод от исследователя к машине влияет на него, какие дает возможности и какие появляются ограничения.
В данной статье для наглядности проводится контент-анализ новостной колонки регионального СМИ машинным способом с целью выявить, насколько в нем отразилась тема Специальной военной операции на Украине, и последующий разбор особенностей и отличий по сравнению с традиционным методом проведения подобного исследования.
2. Методы и процедура исследования
Используя возможности программы RStudio, с помощью пакета rvest с сайта газеты «Вечерняя Уфа» , были собраны сообщения из раздела «Новости» за десять месяцев (октябрь 2021 – июль 2022) – пять месяцев до СВО и пять месяцев после, чтобы можно было сравнить, как изменилась лексика публикаций.

Рисунок 1 - Проверка политики сайта подтвердила, что данные с него собирать разрешено
Возвращаясь к теме статьи: всего было спарсено (собрано) 210 новостей. Для последующего анализа была проведена предобработка возможностями пакета tm. Предобработка включала в себя стемминг (обрезку окончаний), замену заглавных букв на прописные, удаление чисел, знаков препинания, лишних пробелов и стоп-слов. К стандартному списку стоп-слов для русского языка (союзы, предлоги и т.п.) были добавлены имена авторов статей. Кроме того, из перечня слов, входивших в заголовки, были удалены слова повторяющегося объявления о поиске редакцией корреспондента. Все эти операции являются рутинными при работе с текстовыми массивами и не представляют собой чего-то исключительного. По сути, они позволяют отсечь языковой «шум», унифицировать и взять в работу только значимые лексемы, на основании которых можно говорить о содержании текстов и объеме содержащихся в них тем.
По итогам предобработки фрейм заголовков насчитывал 509 слов, фрейм непосредственно текстов – 4156 слов. На рисунке 2 представлены первые 15 строк фреймов заголовков (рис. 2а) и текстов статей (рис. 2б). Разумеется, для больших данных это очень несущественный объем – в этой области оперируют на порядки превосходящими числами – сотнями тысяч и миллионами. Чем больший объем данных обрабатывается, тем более детальный и точный результат можно получить. Однако для целей этой работы нет необходимости расширять выборку, поскольку нас интересует методологическая часть, а не непосредственно результаты анализа.
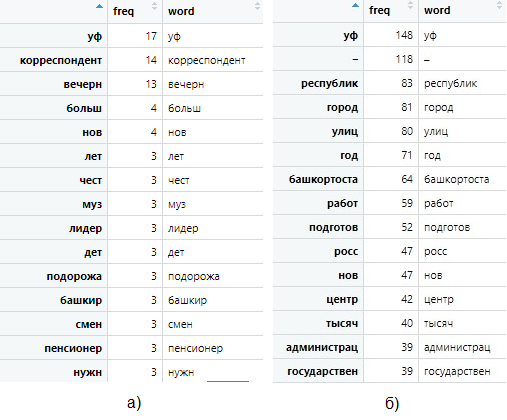
Рисунок 2 - Первые 15 слов каждого фрейма – заголовки (а) и тексты статей (б)
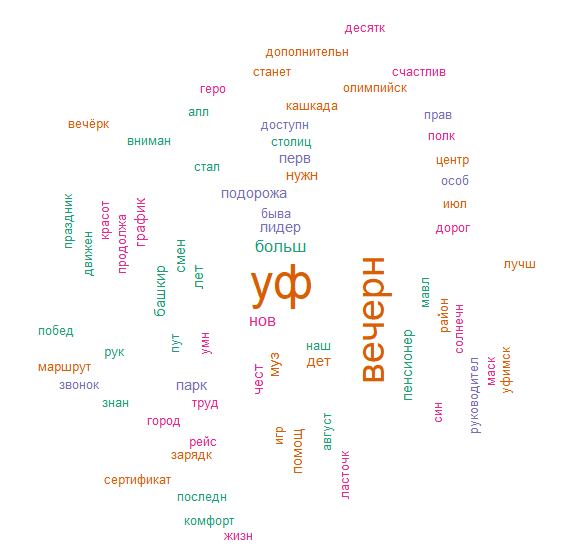
Рисунок 3 - Облако слов, упоминаемых в заголовках за весь выбранный период
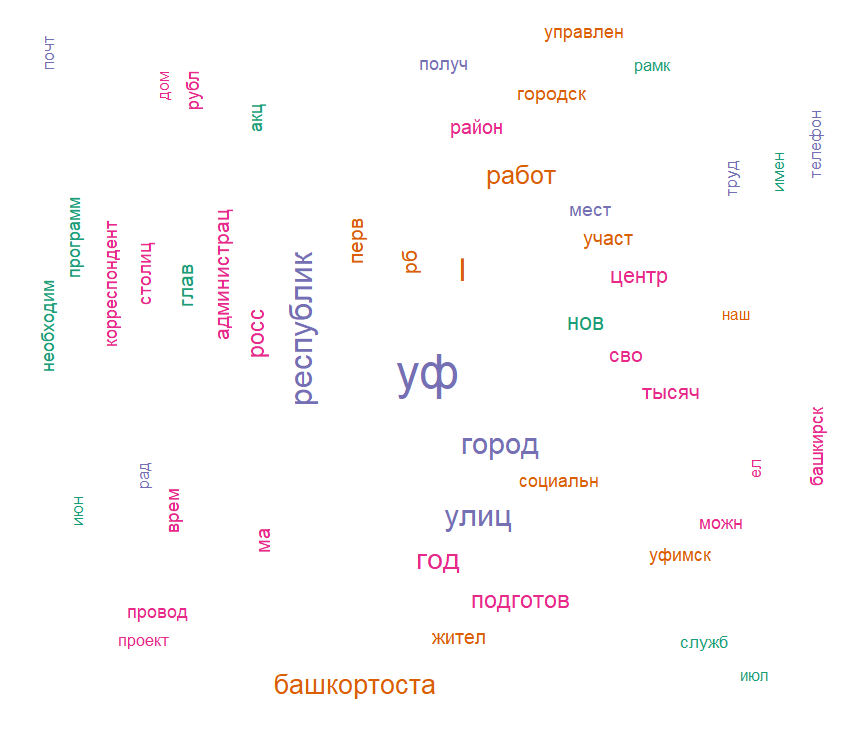
Рисунок 4 - Облако слов, используемых в текстах статей
Облако слов из текстов статей (рис. 4) дает больше информации. Например, очевидно, что стемминг проводится очень грубо: такие слова, как «республика» и «республиканский», «Уфа» и «уфимский» восприняты системой как разные, хотя для контент-анализа разница несущественна. Кроме того, в списки попали неинформативные обрезки слов – «ел», «можн», «наш».
Любопытно, что имя Главы Республики Радий вошло в облако в форме «рад», в то время как фамилия Хабиров не попала. Если посмотреть в самом фрейме, то «рад» встречается 19 раз, а «хабир» – только 9. Полагаем, это может быть связано с тем, что обработанная форма образована не только от имени Главы, но и от краткого прилагательного «рад», предлога «ради» или даже от упоминания украинского парламента.
Также в облаке вызывает интерес форма «сво». Не вызывает особого сомнения утверждение, что это стемминг различных форм местоимения «свой», однако вполне допустимо предположить, что какая-то часть могла быть образована аббревиатурой СВО – специальная военная операция, проводимая в настоящее время Российской Федерацией на территориях ДНР, ЛНР и Украины. О том, что эта часть, если она действительно есть, не особо значительна, свидетельствует контекст – остальные слова в облаке не отсылают однозначно к военной тематике. Отчасти к таковым могут быть отнесены «защита» (но – опять же «защита детей», «защита прав потребителей» и т.п.), «участник» (устойчивое в настоящее время выражение «участник СВО» не перекрывает «участников» любых других мероприятий, тем более что в облаке также фигурирует слово «конкурс») и «служба» (но и здесь нет однозначной отсылки к военной службе – это может быть государственная или муниципальная служба, служба спасения, служба занятости и т.п.).
Если посмотреть только новости за период после начала СВО, то картина остается практически идентичной (см. рис. 5).
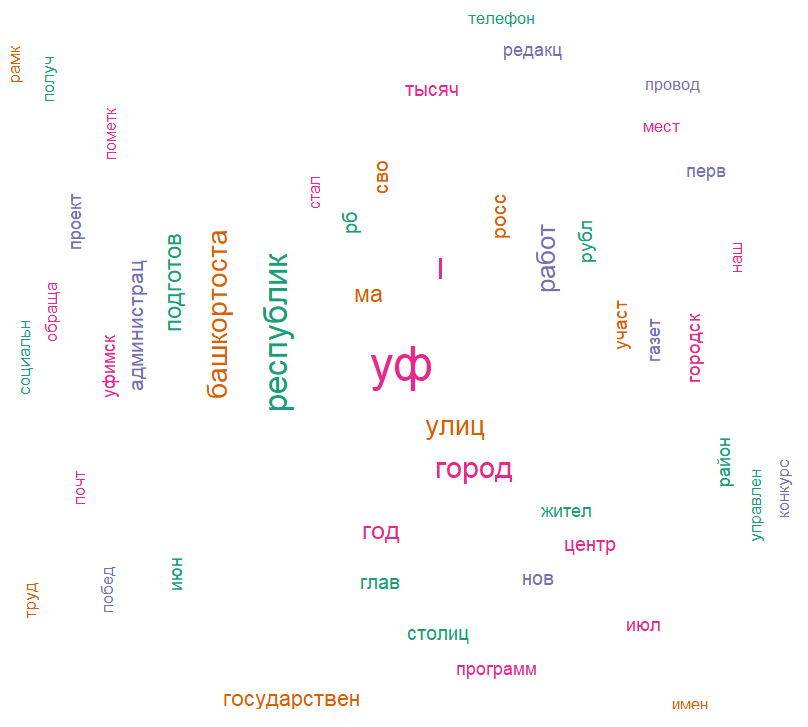
Рисунок 5 - Облако слов, используемых в текстах статей после начала СВО
3. Основные результаты
Представляется очевидным, что машинный анализ обладает гораздо более высокой степенью детализации исследования, однако следует отметить, что она достигается в ущерб целостному видению ситуации. Частотный подсчет отдельных единиц не позволяет восстановить контекст, который воспринимает исследователь при обращении к традиционному контент-анализу. То есть результатом машинного анализа можно считать мозаику тем, для дальнейшей разработки которых нужно более углубленное исследование. Для некоторых исследований этого может быть достаточно – например, если нужно проанализировать, какой объем занимает тема в совокупности текстов, ее соотношение с другими темами и т.п. Но если целью исследования является что-то более сложное, например, оценка отношения автора к теме, языковой портрет, определение влияющих факторов и т.д., без дополнительных процедур, причем в меньшей степени цифровизированных, не обойтись. Есть и промежуточные задачи, решаемые машинным способом, но углубляющиеся в анализ – сравнение текстов по интересующим темам (их близость или отдаленность друг от друга), поиск связей между темами или текстами и т.д. Однако для их решения, опять же, необходимо более серьезное погружение в исследование, не ограничивающееся написанием кода для машины, а требующее понимания проблемной области и постановки задачи.
Необходимо отметить также, что машинный анализ базируется на принципиально ином подходе к анализу текста, чем традиционный контент-анализ. Оставляя в стороне формирование выборки – при использовании последнего сначала определяется тема, формируются ключевые теоретические понятия, выявляются субкатегории и единицы счета и только затем происходит подсчет единиц, который позволяет анализировать тексты по заданной теме. В случае машинного анализа алгоритм практически противоположен: сначала происходит подсчет, а после выделяются темы и категории. С учетом этого можно ли утверждать, что машинный анализ все еще остается контент-анализом, или это какой-то новый метод, требующий дифференциации от традиционного контент-анализа?
Применение метода big data для контент-анализа новостных публикаций регионального издания выявило как плюсы, так и минусы такого подхода. К его достоинствам, безусловно, можно отнести скорость сбора и обработки материала: написанный код проводит указанные операции за несколько минут, легко адаптируется под уточненные задачи (общий фрейм и фрейм за определенный период), визуализирует результат.
К выявленным недостаткам можно отнести грубую работу с языком, высокую погрешность образования форм и иные сложности, вызванные в том числе особенностями русского языка. Стоит отметить, что существуют более совершенные инструменты, например, вместо стемминга может быть использована лемматизация – т.е. слова не обрезаются, а приводятся в первоначальную форму (именительный падеж единственного числа для существительных, инфинитив для глаголов и т.д.). Да и проведенные операции могут быть осуществлены с помощью других пакетов и других команд, что может дать отличающийся результат. Если говорить образно, то это как использовать для измерения два теоретически одинаковых прибора, но из-за погрешности настройки они могут дать разный результат. Кроме того, существуют специальные программы, предназначенные непосредственно для контент-анализа (например, MaxQDA, ), чей функционал шире, а настройки гибче и в большей степени способствуют решению поставленных задач.
4. Обсуждение
Если говорить о сравнении традиционного контент-анализа и исследования методом анализа больших данных, то можно выделить следующие отличия:
1. Нет необходимости формировать выборочную совокупность – методика позволяет провести контент-анализ всей генеральной совокупности. Во-первых, это позволяет сократить время на подготовку к исследованию. Во-вторых, помогает избежать ошибок, которые могут быть совершены при формировании выборочной совокупности. В-третьих, дает более точный результат, поскольку анализ на основе выборочной совокупности по умолчанию является неполной индукцией, в то время как генеральная совокупность (по умолчанию) исчерпывает множество исследуемых объектов, а значит, ее анализ представляется полной индукцией;
2. Нет необходимости выделять единицы анализа. При проведении традиционного контент-анализа особо кропотливая и трудоемкая часть работы связана с подбором смысловых единиц, наличие которых и анализируется в исследуемом объекте. Анализ больших данных, по сути, превращает каждое слово, встречающееся в каждом тексте совокупности, в такую единицу и считает частоту его употребления. Схожие алгоритмы есть и для более крупных единиц анализа (например, устойчивые словосочетания, темы и т.п.);
3. При машинном анализе затруднительно выявить и учесть синонимичные слова, метафорические обороты и использование местоимений при подсчете единиц анализа. Также представляет определенную сложность оценка контекста для них. В этих ситуациях необходимо оценивать слова не как отдельные единицы, а как часть целого (словосочетания, предложения, абзаца), а машина именно что разрывает связи между единицами и ведет учет каждой отдельно. Некоторые программные решения , специализирующиеся именно на контент-анализе, позволяют обратиться к контексту в каждом конкретном случае – выдают подборку фрагментов текстов, где встречается выбранная единица анализа, на установленную исследователем «глубину» – количество слов вокруг, предложение, абзац, в котором оно употребляется, что частично снимает указанную трудность, однако не избавляет от нее полностью, поскольку требует уже «немашинного» подхода к анализу и, в каком-то смысле, возвращает к традиционной форме исследования.
Отдельно следует отметить тот факт, что традиционный контент-анализ требует от исследователя четкой постановки цели и задач исследования – и, соответственно, длительную процедуру его подготовки. Он требует постановки проблемы. Машинный же анализ в этом отношении более лоялен к исследователю. Он позволяет взять любой массив информации и посмотреть, что в нем есть интересного и проблемного. Разумеется, исследователь должен понимать, куда смотреть и что искать, и, тем не менее, машинный анализ дает куда больший простор при постановке целей и задач .
5. Заключение
Резюмируя сказанное, машинный анализ представляется удобным инструментом на начальном этапе для первичной оценки текстов. Он позволяет анализировать всю совокупность текстов, а не выборку, выделить основные темы (единицы анализа), оценить общий «объем» интересующих тем в генеральной совокупности. По сути, строит наглядную макрокарту исследуемых текстов, отталкиваясь от которой можно переходить к более глубокому и конкретному исследованию интересующей темы, в том числе к качественному контент-анализу.
Если говорить об анализе больших данных, как о научном методе, то его научным результатом является эмпирическое обобщение (на основе полной или неполной индукции – в зависимости от характеристики генеральной совокупности), что с уверенностью позволяет отнести данный метод к количественным методам эмпирического уровня научного познания .