DEVELOPMENT OF MODULE IMPLEMENTING METHODS AND ALGORITHMS FOR PROCESSING VARIOUS TYPES OF DATA FLOW
DEVELOPMENT OF MODULE IMPLEMENTING METHODS AND ALGORITHMS FOR PROCESSING VARIOUS TYPES OF DATA FLOW
Abstract
The amount of data generated by machines and human interactions is now growing rapidly, and technologies are evolving trying to solve this problem. Although big data is widely discussed on a theoretical level, there are a number of difficulties in its processing.
The aim of this work is to develop a module that will classify a data flow and then process it, taking into account certain parameters, such as: file types according to type extension, date, file name and size, using certain methods and algorithms as proof.
Obviously, this module will allow easier and faster processing as well eliminate certain difficulties associated with the structure of big data.
1. Введение
На сегодняшний день, одним из активно развивающихся направлений в области информационных технологий является технология Больших данных (Big Data). В последние годы Большие данные являются общепризнанным признаком экономического и технологического развития. Исследования консалтинговой компании «Gartner» прогнозируют, что технология Больших данных окажет существенное влияние на информационные технологии в производстве, здравоохранении, торговле, государственном управлении и в других отраслях, которые используют большой поток информации.
Big Data -это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений [4].
Термин «Большие данные» обычно относится к наборам данных, которые превышают возможности обычно используемых программных средств по сбору, хранению, управлению и обработке данных в допустимые сроки. В целом, Большие данные можно объяснить в терминах трёх «V»: Volume (объем данных), Velocity (скорость данных) и Variety (диапазон типов и источников данных), которые требуют новой высокопроизводительной обработки [3]. Реализация систем Больших Данных опирается на такие революционные технологии, как облачные вычисления, Интернет вещей и аналитика данных. Поскольку все больше систем используют Большие Данные в различных секторах, таких как здравоохранение, правительство, сельское хозяйство, оборона и образование, в областях их применения были достигнуты прорывы за счёт инноваций и роста. Эти системы представляют собой крупные, долгосрочные инвестиции, требующие значительных финансовых обязательств и масштабного развёртывания программного обеспечения и систем. Для их обработки было разработано несколько технологий, которые классифицируются по концепциям обработки данных. Из собранной информации необходимо извлечь и проанализировать большое количество контента, чтобы удовлетворить потребности в знаниях различных бизнес-организаций, политических партий и научно-исследовательских отделов. Процесс начинается с извлечения информации, которая может поступать из различных источников, таких как базы данных, веб-сайты, документы или системы управления контентом. Вслед за хроникой их нужно фильтровать и оптимизировать. Только релевантная информация должна регистрироваться методами, исключающими ненужные данные. Для поддержки этой работы используются специальные инструменты, например, ETL. Метод ETL обычно объединяет данные из нескольких систем, а затем загружает их в хранилище данных [1]. Современный объем данных, которыми управляют наши системы, превысил возможности обработки традиционных систем [2], и это также относится к добыче данных. Появление новых технологий и услуг (таких как облачные вычисления), а также снижение цен на компьютерное оборудование приводит к постоянному увеличению объема информации в интернете. Это явление, безусловно, представляет собой «большой» вызов для сообщества специалистов по анализу данных.
Однако существуют некоторые проблемы, такие как масштабируемость, интеграция, отказоустойчивость, своевременность, согласованность, неоднородность и неполнота, балансировка нагрузки, проблемы конфиденциальности и точность [5], [6], которые возникают из-за природы потоков больших данных, с которыми необходимо иметь дело.
2. Методы и принципы исследования
Гетерогенная структура, различная размерность и разнообразие представления данных также относятся к этому вопросу. Просто вспомните старые приложения, выполняющие запись данных: различные программные реализации приведут к различным схемам и протоколам [18]. Для больших компаний статистика и анализ данных лежат в основе ведения бизнеса на крупных рынках, но аналитика стала намного более востребованной с развитием телекоммуникаций и намного более эффективной благодаря наличию мощных вычислительных машин. Один из экспертов Big Data Фрэнк Акито, считает, что сильнейшим фактором расширения спектра применения Big Data является Интернет [7].
Существует множество методов классификации, которые используют различный математический аппарат и различные подходы при реализации [9], [10], [11], [12]. Однако эффективность этих методов зависит от конкретной решаемой задачи. Несмотря на то, что последнее десятилетие коммерческие компании занимаются проблемой повышения качества машинного обучения, на сегодняшний день не существует методов, которые могли бы однозначно эффективно решить задачу классификации. Можно выделить следующие типы методов классификации: вероятностные, метрические, логические, линейные, логическая регрессия. Обобщенно опишем некоторые из них, указывая преимущества и недостатки каждого из них.
Методы и алгоритмы анализа больших данных
Существует множество разнообразных методик анализа массивов данных, в основе которых лежит инструментарий, [8] заимствованный из статистики и информатики. В данном списке отражены наиболее востребованные в различных отраслях подходы. При этом следует понимать, что исследователи продолжают работать над созданием новых методик и совершенствованием существующих. Кроме того, некоторые из перечисленных них методик вовсе не обязательно применимы исключительно к большим данным и могут с успехом использоваться для меньших по объему массивов (например, A/B-тестирование, регрессионный анализ). Безусловно, чем более объемный и диверсифицируемый массив подвергается анализу, тем более точные и релевантные данные удаётся получить на выходе.
Машинное обучение − узкоспециализированная область знаний, входящая в состав основных источников технологий и методов, применяемых в областях больших данных и Интернета вещей, которая изучает и разрабатывает алгоритмы автоматизированного извлечения знаний из сырого набора данных, обучения программных систем на основе полученных данных, генерации прогнозных и/или предписывающих рекомендаций, распознавания образов и т.п.
Алгоритмы машинного обучения: Линейная и логистическая регрессия; SVM; Решающие деревья; Random forest; AdaBoost; Градиентный бустинг; Нейросети; K-means; EM-алгоритм; Авторегрессии; Self-organizing maps.
Основные методы обработки больших данных включают в себя, смешение и интеграцию разнородных данных, таких как
- цифровая обработка сигналов и обработка естественного языка;
- машинное обучение, включая искусственные нейронные сети, сетевой анализ, методы оптимизации и генетические алгоритмы;
- распознавание образов;
- прогнозную аналитику;
- имитационное моделирование;
- пространственный и статистический анализ;
- визуализацию аналитических данных — рисунки, графики, диаграммы, таблицы.
Анализ больших данных может быть охарактеризован по следующим параметрам:
1 - Объем, т.е. количество генерируемых данных. От этого показателя зависит, может ли определённый массив данных считаться большими данными или нет. Данных хранятся SQL-серверах в облачной среде.
2 - Многообразие, т.е. категория, к которой принадлежат большие данные. Знание такой принадлежности позволяет аналитикам наиболее эффективно работать с информацией.
3 - Скорость, т.е. скорость генерирования или обработки данных с целью осуществления поставленных целей.
4 - Изменчивость, т.е. нестабильность данных во времени.
5 - Достоверность, т.е. качество собранных данных, от которого зависит точность анализа.
6 - Сложность, т.е. трудоёмкость процесса корреляции и построения взаимосвязей между данными.
Как мы видели в предыдущих разделах, было предложено множество алгоритмов и методик для решения проблем интеграции Больших Данных, но многие элементы не учитываются в этих предложениях. В отношении некоторых проблем, связанных с Большими Данными, из которых эта статья посвящена решению проблем, связанных с обработкой различных данных.
Постановка задачи
ИТ-индустрия давно создала методологию и инструменты для работы со структурированными данными - это реляционная модель данных и системы управления базами данных. Но современной тенденцией является необходимость работы с широким спектром данных, и это та область, где предыдущие подходы работают плохо или не работают вообще из-за несовместимости методов и алгоритмов.
Именно эта потребность требует нового способа работы с данными, и модель Больших Данных становится все более популярной. Задача разработчиков и учёных в области Больших Данных - найти программное и техническое решение, которое можно легко интегрировать в существующую инфраструктуру центров обработки данных и обеспечить этапы обработки информации.
3. Основные результаты
Случай алгоритма распознавания образов объектов, встроенных в модули
Для выполнения операции сортировки деталей на конвейере предлагается использовать алгоритм распознавания на основе анализа контуров — границ, изображений объектов. В этих алгоритмах в этапе представления и описания границы объектов используется метод Фурье. Для вычисления фурье-дескрипторов контур границы объекта представляется в виде массива комплексных чисел f(k) =x(k)+iy(k), k=0,1, …, N = −1. Выражение дискретного преобразования Фурье для массива f(k) задается выражением [19].
Комплексные коэффициенты F(u) = Fu, определяемые выражением (1), называются фурье-дескрипторами границы. При формировании вектора признаков используют модули фурье-дескрипторов с положительными и отрицательными индексами u = ±1, ±2,…, ±L/2, причем L ≤ N−1. Для обеспечения инвариантности признаков к сдвигу, повороту и изменению масштаба выполняют нормировку дескрипторов на модуль дескриптора с индексом u =1. Вектор признаков X имеет вид
Значение параметра L определяет размерность признакового пространства K = L− 2.
На этапе распознавания выбран простейший классификатор, основанный на минимизации евклидова расстояния между вектором Xr признаков распознаваемого объекта и векторами Xm ,
. признаков эталонных объектов, образующих алфавит классов [19]. В данном случае число классов равно M. Евклидово расстояние определяется по формуле
.
Решение о принадлежности объекта к некоторому классу
.
Реализация
Решение перечисленных задач может лежать в следующем:
Эта работа состоит из двух основных частей:
- этап подготовки данных: это этап группировки данных в соответствии с их типом или расширением в каталоге с помощью библиотеки shutil. Классификация рассматривается как метод контролируемого обучения в машинном обучении, относящийся также к проблеме прогностического моделирования, когда для данного примера предсказывается метка класса [17]. Математически, он отображает функцию (f) от входных переменных (X) на выходные переменные (Y) в виде цели, метки или категории. Чтобы предсказать класс заданных точек данных, это может быть выполнено на структурированных или неструктурированных данных. Например, обнаружение спама, такого как «спам» и «не спам» в почтовых службах может быть проблемой классификации.
- этап фактического лечения - это этап избирательного выбора лечения в соответствии с нашими потребностями, по принципу и с учетом адекватных методов и алгоритмов.
Шаг 0: создайте набор данных, содержащий несколько типов файлов.
Шаг 1: загрузка набора данных и предварительная обработка данных
Шаг 2: классификация данных по группам в соответствии с расширением
Шаг 3: преобразование и выбор метода обработки данных.
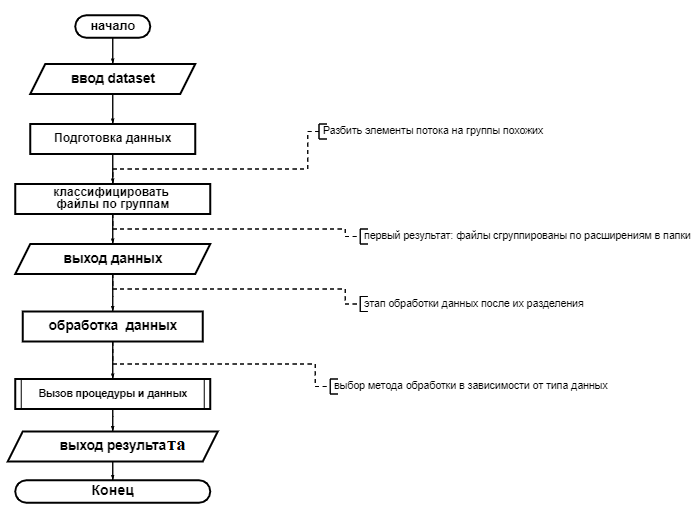
Рисунок 1 - Общая схема предлагаемого алгоритма
Библиотека python:
Tkinter - для создания графического интерфейса;
shutil.move -Эта функция используется для перемещения файла и каталога из одного каталога в другой и удаления его из предыдущего каталога[13]. Эта функция позволит нам классифицировать файлы по расширению в отдельной папке
def filTransprocess():
list_of_files = os.listdir(path)
for file in list_of_files:
name, ext = os.path.splitext(file)
ext = ext[1:]
if ext == '':
continue
if os.path.exists(path+'/'+ext):
shutil.move(path+'/'+file,path+'/'+ext+'/'+file)
else:
os.makedirs(path+'/'+ext)
shutil.move(path+'/'+file,path+'/'+ext+'/'+file)
return name
OS поставляется со стандартными служебными модулями Python [14].
KImage даёт дополнительную функциональность для обработки группы изображений как одного изображения [15].
Matplotlib - это основная библиотека для построения научных графиков в Python. [16]
NumPy В результате в процессе выполнения основных NumPy-операций (срезов, масок, индексирования) есть возможность менять пиксельные значения изображения [16].
Практический этап и результат работы
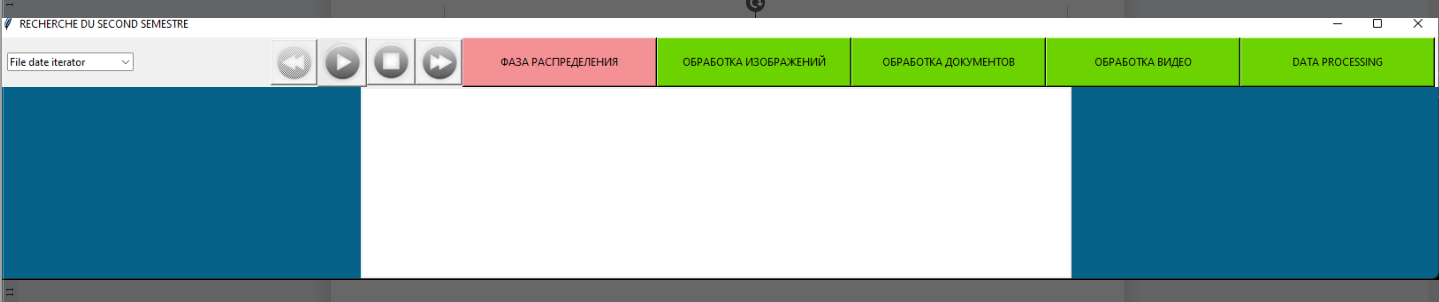
Рисунок 2 - Интерфейс программы
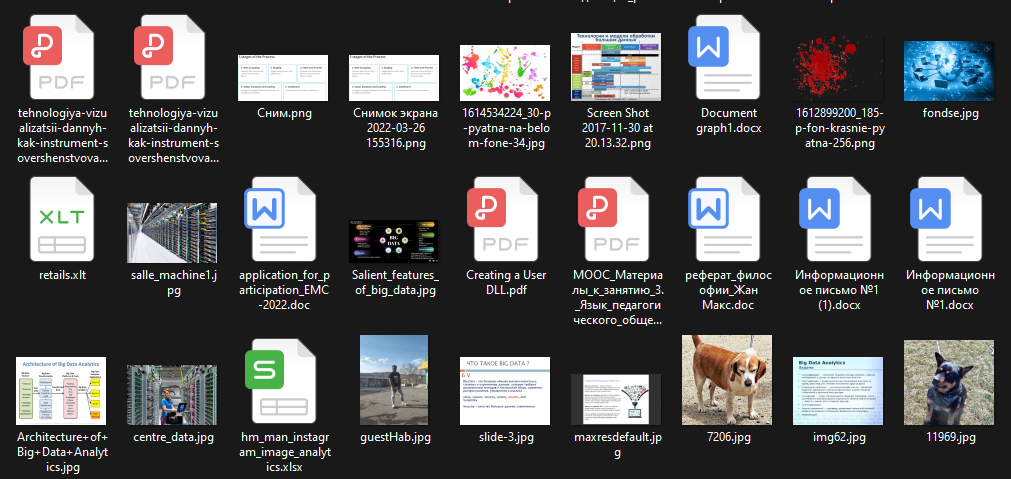
Рисунок 3 - Создать папку и импортировать несколько файлов с разными типами расширений, которая будет рассматриваться как набор данных(dataset)
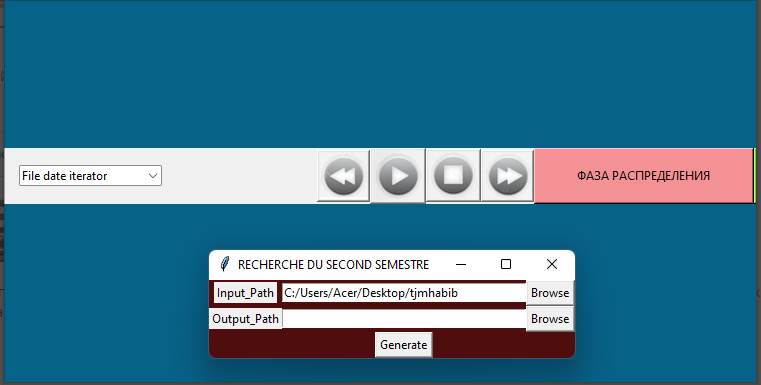
Рисунок 4 - Импорт набора данных в программное обеспечение и группировка файлов по типам расширений

Рисунок 5 - Результат группировки файлов по типу расширения
Рисунок 6 - Выбор обработки изображений
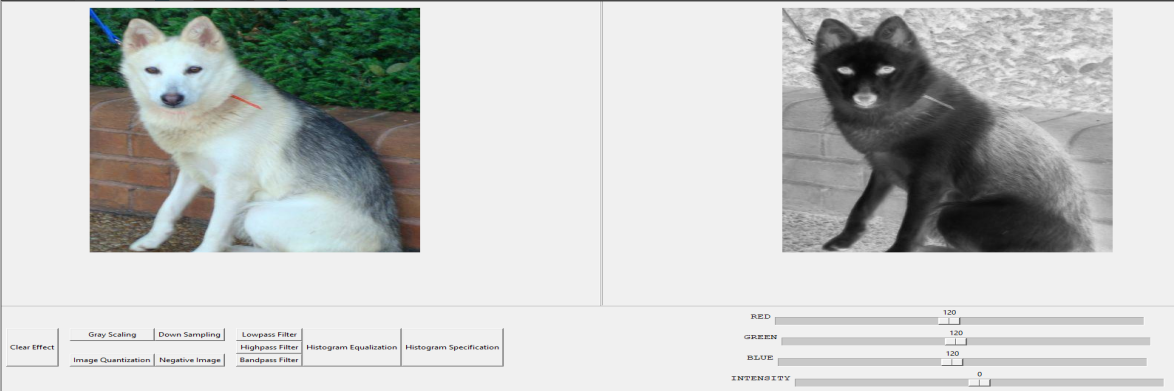
Рисунок 7 - Обработка изображений, фильтрация и негативное изображение
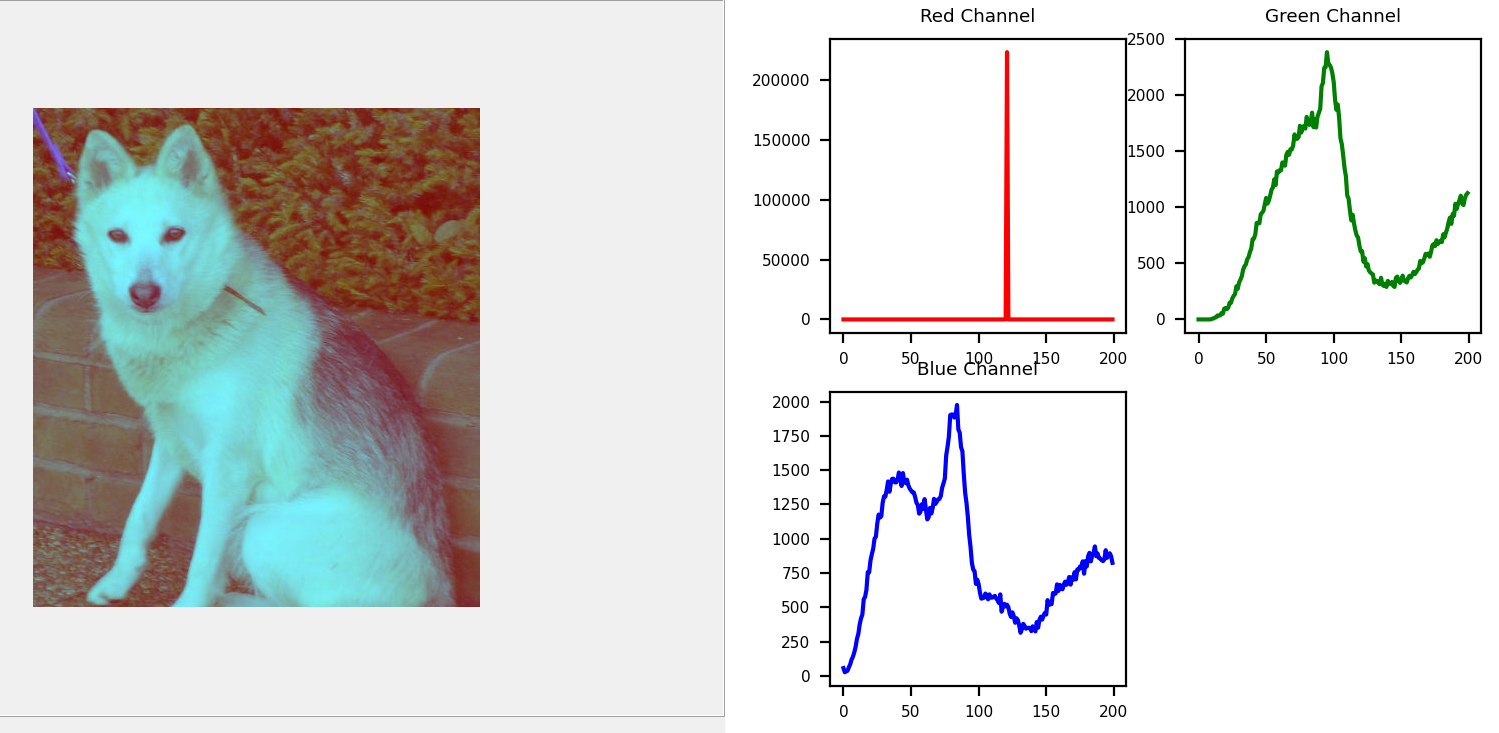
Рисунок 8 - Обработка изображений, фильтрация и гистограмма
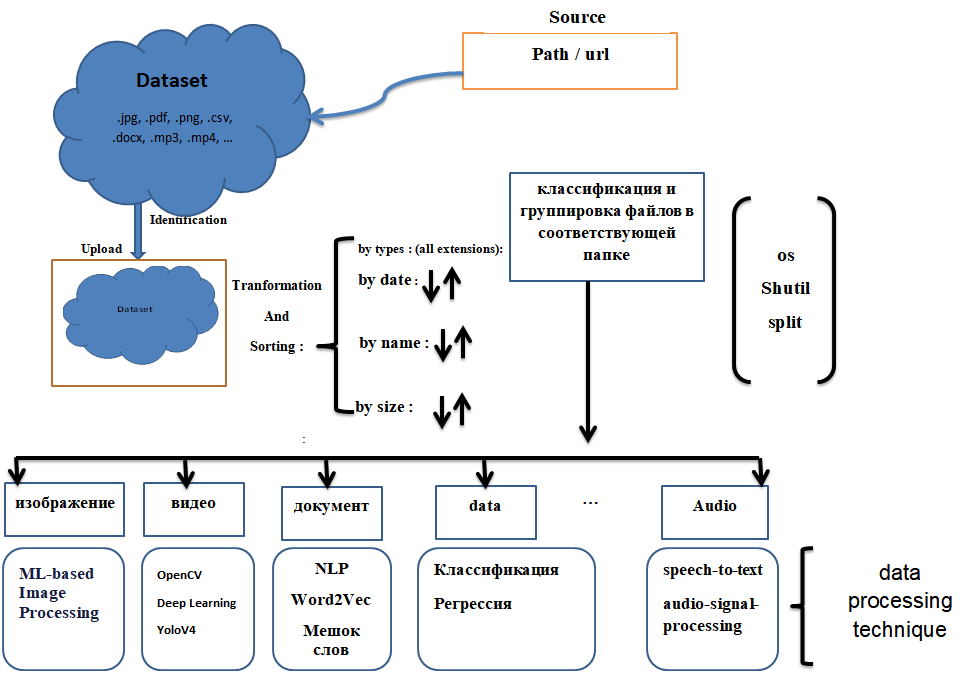
Рисунок 9 - Схема описания работы модуля анализа и обработки файлов
Специфика методов и алгоритмов, разработанных в модуле, позволяет интегрировать и проводить совместный анализ для выполнения конкретных функций обработки:
-OCR: Оптическое распознавание символов работает путем разделения изображения текстового символа на участки и различения пустых и непустых областей. В зависимости от шрифта или сценария, используемого для письма, контрольная сумма полученной матрицы впоследствии маркируется (первоначально человеком) как соответствующая символу на изображении
- распознавание объектов на фотографиях и видео.
- преобразование документов
- преобразование аудио в текст и наоборот
-обработка изображений (фильтрация, обнаружение разрывов, математическая морфология...)
-анализ изображений (связанные компоненты, корректировка примитивов...)
-графический интерфейс (отображение изображений, видео, управление событиями...)
- расчет гистограммы оттенков серого или цветовых гистограмм.
- сглаживание, фильтрация.
- воспроизведение, запись и просмотр видео (из файла или камеры)
- обнаружение прямых, сегментов и окружностей с помощью преобразования Хью
- распознавание лиц методом Виолы и Джонса
- обнаружение движения, история движения
- обнаружение точек интереса
- зрение (калибровка камеры, стереовидение, поиск ассоциаций...)
Учитывая несовместимость методов и алгоритмов при обработке больших данных из-за структур данных, этот комплекс позволяет использовать несколько типов данных.
4. Обсуждение
Для решения проблем интеграции больших данных было предложено множество алгоритмов и методик, но многие элементы не учитываются в этих предложениях. Прежде всего, все предложения предполагают, что данные хорошо сформированы и проведена их предварительная обработка (извлечение, преобразование). Кроме того, единственным типом рассматриваемых неструктурированных данных является текст, но часто встречаются и другие типы, например, посты в социальных сетях могут содержать видео, аудио, изображения, карты и другие типы. Кроме того, при интеграции данных из социальных сетей (блоги, твиты, посты ...), данные обычно очень низкого качества, поскольку они предоставляются обычными пользователями, которые необязательно имеют базовые навыки работы с компьютером и письма. Поэтому очень трудно обрабатывать полезную информацию.
Кроме того, все предложения требуют сначала построить модель в автономном режиме, а затем передать ее в онлайн. В реальном мире это не всегда возможно. Когда речь идет о достоверности и разнообразии данных, мы не всегда можем проанализировать автономные источники данных. Иногда приходится проводить анализ онлайн, что очень сложно, особенно учитывая перечисленные выше проблемы.
5. Заключение
В данной статье рассматриваются технические и интеллектуальные методы работы с данными разнородных типов. Комплекс разработанных методов интеллектуального анализа данных, используемый для анализа разнородных данных в рамках системы поиска и анализа данных, а также для улучшения процедур принятия решений для обработки большого потока данных с помощью методов и алгоритма, реализованных при разработке модуля, может улучшить процедуры принятия решений при обработке больших потоков данных. Эта система облегчит обработку больших наборов данных без необходимости использования нескольких различных программных пакетов для обеспечения однородности данных. Этапы обработки включают идентификацию данных в наборе данных, затем группировку их в классы в соответствии с типом, а затем, собственно, обработку. Для других текущих исследований она будет адаптирована к развёртыванию систем баз данных SQL server и NoSQL, которые предназначены для работы с информацией или данными с различными характеристиками.