Development of a training stand for steganographic protection of files containing financial information using regular expressions and the parallel library of the .NET platform
Development of a training stand for steganographic protection of files containing financial information using regular expressions and the parallel library of the .NET platform
Abstract
The article examines the development of a training stand in the form of a software module for protecting financial data based on associative steganography, regular expressions, and parallel computing in the .NET environment. The suggested method combines cryptographic and steganographic approaches, ensuring a high degree of confidentiality when processing documents. Key aspects of the research: associative steganography — a method of data concealment that is resistant to detection, using matrix encoding and random masks; regular expressions — a flexible tool for searching and filtering confidential data (card numbers, dates, amounts); parallel processing — the use of the Task Parallel Library to speed up the processing of large files. Experimental results have shown that parallel implementation reduces processing time by 2 times compared to the sequential approach. The module generates a structured JSON file with encrypted data, which simplifies integration with other systems. The developed stand will potentially enable students to create solutions for use in the banking sector, corporate systems and government structures to protect financial information from leaks.
1. Введение
В современном мире постоянно возрастает объем информации в интернете и возникает потребность в цифровизации данных с помощью различных инструментов и платформ, которые, безусловно, имеют ряд преимуществ и перспектив, но в то же время появляется ряд недостатков. Появляется множество угроз информационной безопасности. Защита данных в наше время играет важную роль, так как нарушение конфиденциальности и раскрытие существенно значимых сведений может повлечь за собой огромные риски и проблемы, как для одного человека, так и для миллионов людей, огромных организаций или страны.
Создание программных продуктов, обеспечивающих надёжную защиту важной информации, является актуальной задачей. Один из способов обеспечения безопасности данных — это использование ассоциативной защиты файлов. Этот метод используется для обработки данных, чтобы предотвратить возможные нарушения конфиденциальности, связанные с ассоциативными связями между информацией и субъектами. Ассоциативная стеганография является сложной для обнаружения и расшифровки в отличие от других методов шифрования, которые полагаются на сложные алгоритмы и ключи.
Целью работы является разработка учебного стенда в форме программного модуля для защиты файлов с финансовыми данными с использованием регулярных выражений и параллельной библиотеки платформы .NET. Для достижения поставленной цели решены следующие задачи: проанализированы существующие методы защиты, разработан проект программного модуля ассоциативной защиты файлов с финансовыми данными, реализован проект программного модуля защиты файлов с финансовыми данными с использованием регулярных выражений и параллельной библиотеки платформы .NET, проведено тестирование разработанного программного модуля.
Новизна разработки заключается в объединении современных методов информационной безопасности, регулярных выражений и параллельной библиотеки платформы .NET, чтобы обеспечить эффективную защиту финансовых данных по критериям быстродействия и криптостойкости.
2. Существующие алгоритмы защиты данных
Криптография использует математические методы для шифрования данных, чтобы предотвратить их прочтение третьими лицами без знания специального ключа. Существует два типа таких алгоритмов: симметричные и асимметричные.
В симметричном используется один ключ для шифрования и дешифрования. Это означает, что отправитель и получатель должны иметь общий ключ для безопасной передачи данных. Принцип работы симметричного шифрования довольно прост. Сначала данные преобразуются в нечитаемый формат с помощью алгоритма шифрования и общего ключа. Затем зашифрованные данные отправляются получателю. Получатель использует тот же самый ключ для дешифрования данных обратно в исходный формат. Основное преимущество симметричного шифрования заключается в его простоте и высокой скорости обработки данных. Однако есть и недостатки. Главный из них – необходимость обмена общим ключом. Примеры алгоритмов такого типа — ГОСТ 28147-89, ГОСТ 34.12-2018, AES
.В асимметричных алгоритмах
используются уже два ключа — открытый для шифрования и закрытый для дешифрования. Основное преимущество асимметричного шифрования заключается в том, что нет необходимости обмениваться общим ключом перед началом процесса шифрования. Это делает данный метод более безопасным, поскольку исключается риск перехвата общего ключа злоумышленниками. Недостатком асимметричного шифрования является его относительно низкая скорость обработки данных по сравнению с симметричным шифрованием.Проанализировав и изучив информацию об известных на сегодняшний день приложениях, которые используются в целях защиты какой-либо информации, можно сказать, что все они применяют различные алгоритмы и типы алгоритмов, но преимущественное большинство — симметричный алгоритм AES.
Безусловно, преимущественно то, что алгоритмы ГОСТ 28147-89, ГОСТ 34.12-2018, AES практически не обладают избыточностью, но не следует забывать об их помехоустойчивости. В данных алгоритмах позволяется искажение менее 1% данных в 128-битном блоке. Исходя из исследований можно сказать, что безусловной стегостойкостью они так же не обладают. Кроме криптографических алгоритмов существуют методы сокрытия самого факта передачи сообщения. Такие методы называются стеганографическими.
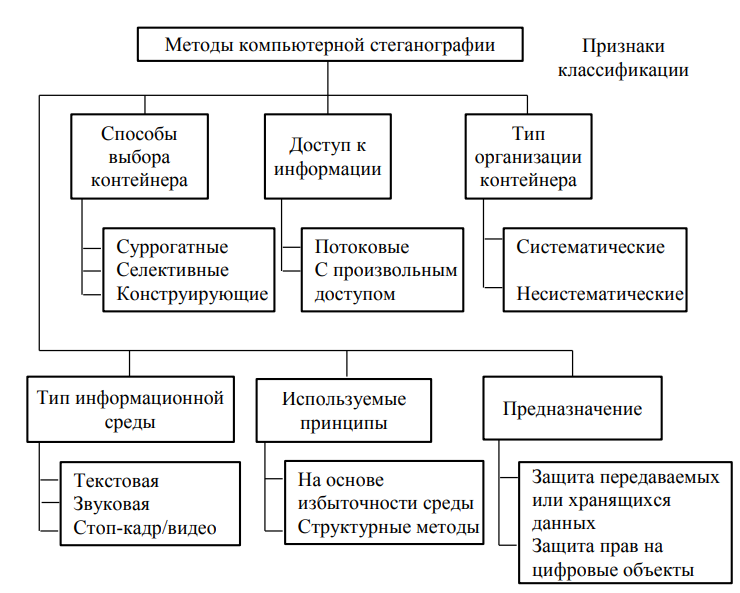
Рисунок 1 - Классификация компьютерной стеганографии
3. Ассоциативная стеганография
Ассоциативная стеганография представляет собой сочетание стеганографии и криптографии, которое изначально было разработано для защиты данных при анализе сцен. Ранние исследования в основном были направлены на управление защищёнными картографическими базами данных. В этом контексте каждый k-битный код (объекта или координат), полученный в результате матричной бинаризации десятичных чисел, преобразуется в k-секционный стегоконтейнер.
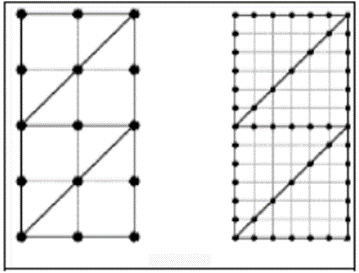
Рисунок 2 - Расположение битов по внешнему контуру и «зигзагу»
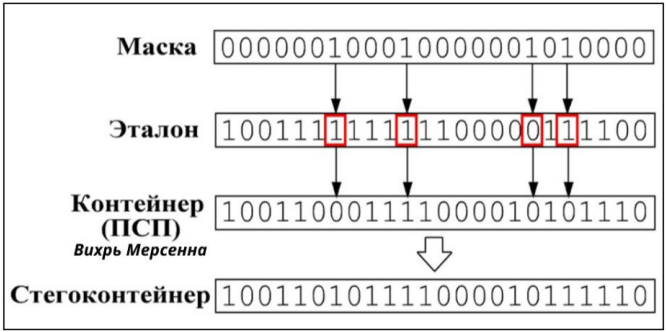
Рисунок 3 - Формирование стегоконтейнера
4. Регулярные выражения
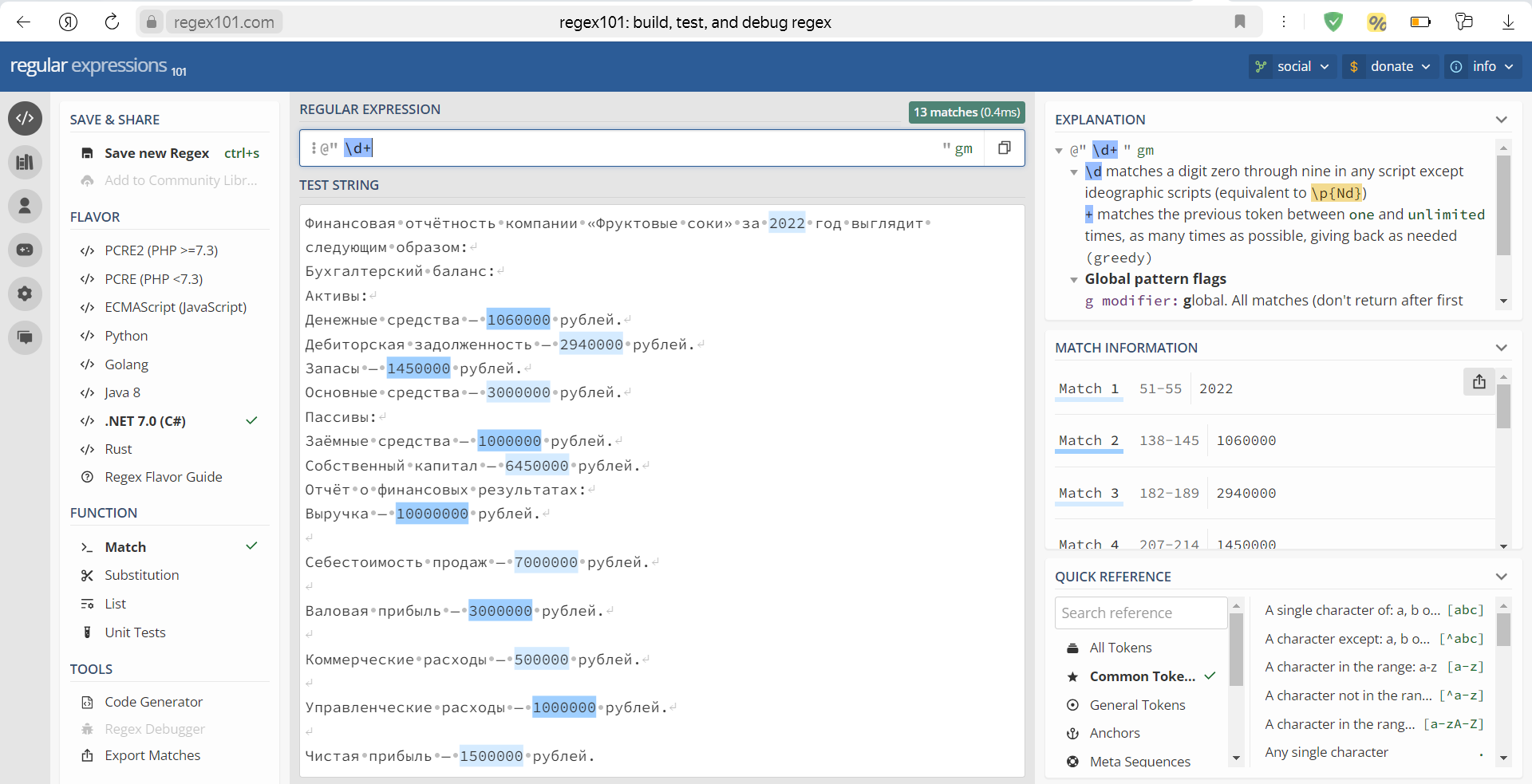
Рисунок 4 - Онлайн-сервис «regex101.com»
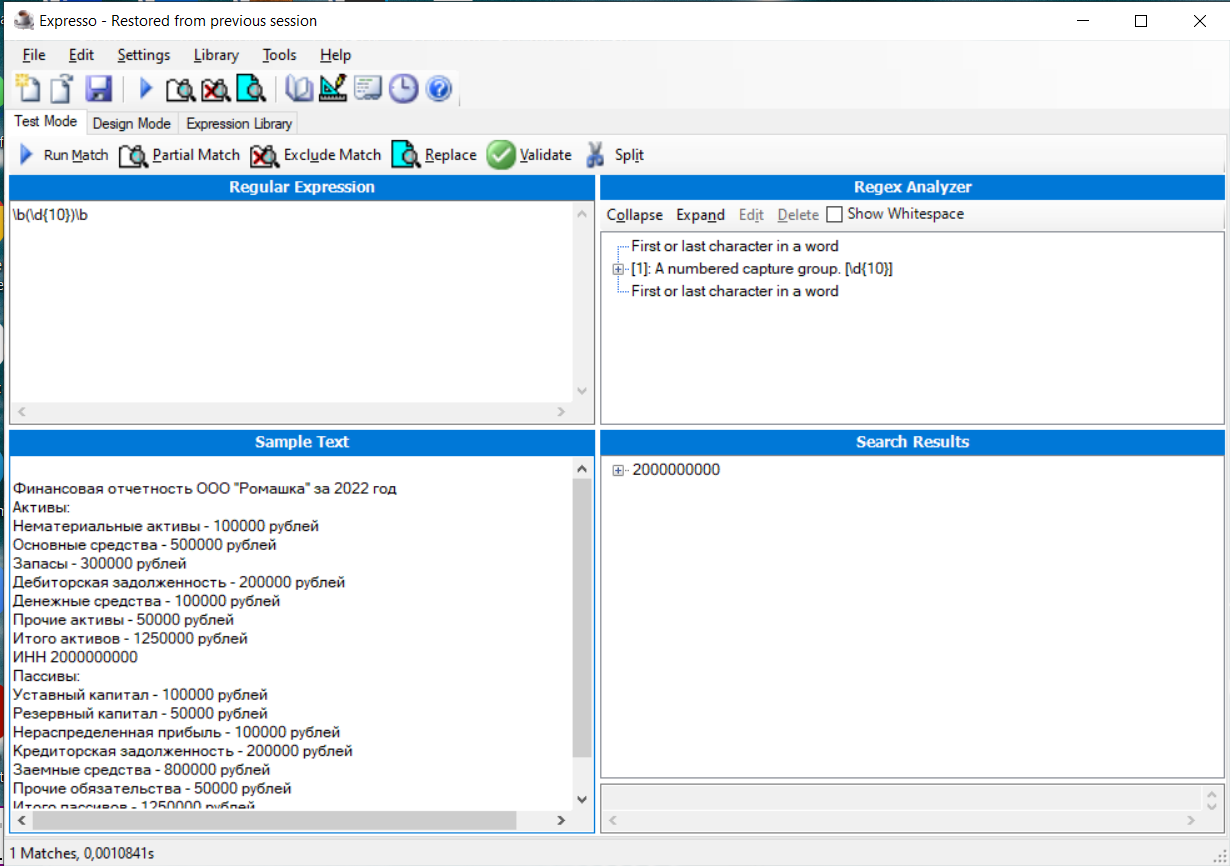
Рисунок 5 - Десктопное приложение «Expresso»
5. Выбор используемых технологий
Технологии, которые были выбраны для разработки модуля, были тщательно отобраны после глубокого анализа требований и условий проекта. Обоснование выбранных технологий для разработки связано с современными тенденциями.
В качестве языка программирования был выбран C# для написания кода, потому что он обладает рядом преимуществ и особенностей:
1. C# является объектно-ориентированным языком, что позволяет создавать структурированный и легко читаемый код.
2. C# хорошо интегрируется с платформой .NET, предоставляющей богатый набор библиотек и фреймворков, что значительно ускоряет разработку и повышает её качество, позволяя использовать готовые решения для многих задач — экономит время и усилия на разработке собственных функций.
3. C# имеет удобную среду разработки, такую как Visual Studio. Она является одной из самых мощных и гибких IDE на рынке.
4. C# поддерживает кроссплатформенность.
В разработке программного модуля использована библиотека параллелизма задач (Task Parallel Library — TPL)
, а именно класс Parallel. Следует отметить, что верхний уровень функциональности инфраструктуры Parallel Framework состоит из двух API-интерфейсов структурированного параллелизма данных: класс Parallel и PLINQ . Поэтому целесообразно обосновать выбор класса Parallel, а не PLINQ.Распараллеливание с помощью данного метода уместно применить при проверке на соответствие искомой информации, которую нужно сокрыть, а также при самом сокрытии. Также данную технологию разумно использовать на больших объемах информации из расчета того, что на малый объем большее количество времени уйдет на создание и координацию нескольких потоков. К тому же при незначительных объемах данных потребность в практической реализации данного подхода является сомнительной. В настоящее время почти всё подверглось цифровизации, поэтому можно утверждать, что значимость обработки и защиты больших документов с содержанием финансовых сведений возрастает с большой скоростью.
Конечный результат после сокрытия — это структурированный JSON-файл , который содержит защищенные и незащищенные данные. JSON идеально подходит для сериализации структурированных данных, что делает его удобным для обмена информацией между различными системами и языками программирования. Это делает его отличным выбором для кроссплатформенной разработки. Десериализация JSON происходит быстрее, чем обработка других форматов данных, таких как SOAP или XML.
6. Проектирование программного модуля
Алгоритм работы программного модуля можно представить в следующем виде:
1. На вход получаем текстовый файл с финансовыми сведениями, которые требуется сокрыть.
2. Происходит разбиение данного текста на блоки с помощью максимального размера блока и некого разделителя для последующего распараллеливания обработки.
3. Каждый блок в отдельном потоке подвергается обработке: выполняется поиск и извлечение фрагментов в блоках, проверка на соответствие, а затем сокрытие определенных данных ассоциативной защитой.
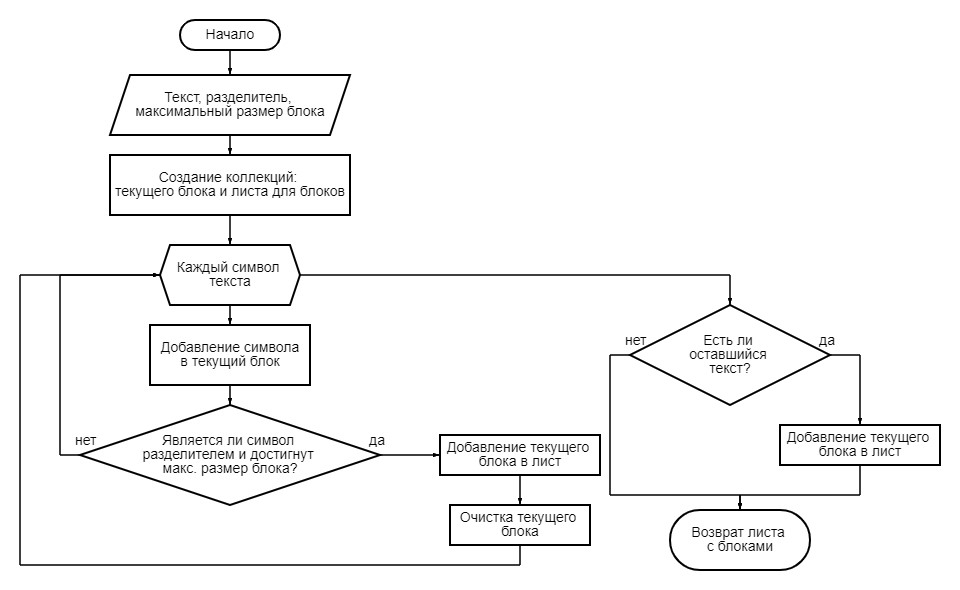
Рисунок 6 - Блок-схема алгоритма деления на блоки
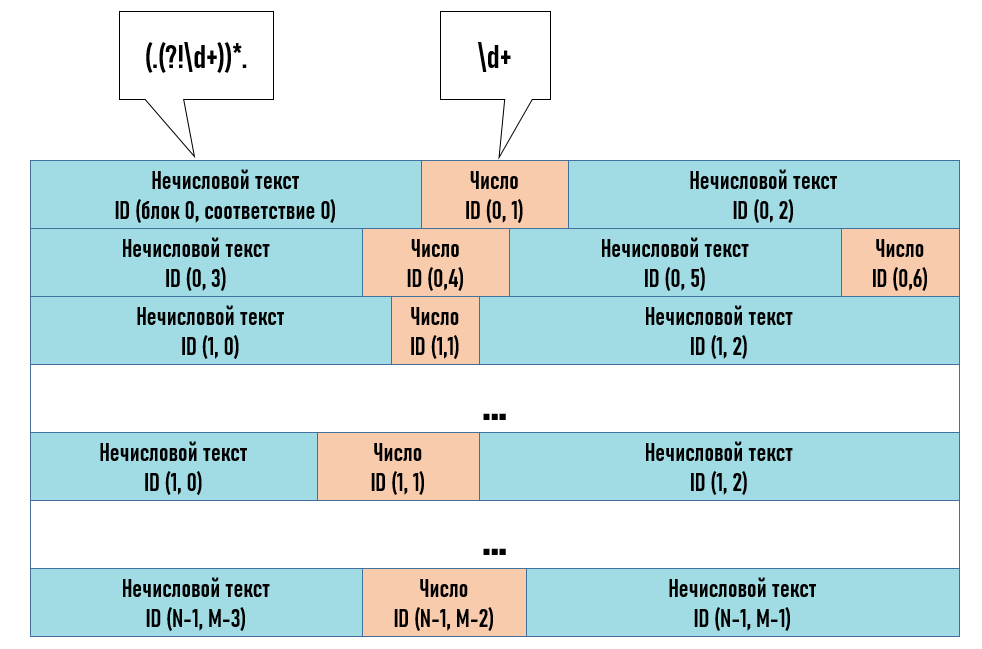
Рисунок 7 - Представление блоков в процессе параллельной обработки

Рисунок 8 - Структурированный набор данных
7. Реализация проекта программного модуля
Для демонстрации реализации разработанного программного модуля следует определить некоторые входные данные. Пусть важными конфиденциальными сведениями в исходном финансовом документе будут любые числа. Для разбиения текста на блоки за разделитель примется «пробел» и максимальным размером будет значение «10».
Следовательно, решение поставленной задачи достигается следующими шагами:
Шаг 1. Импортируются необходимые пространства и создаются объекты для применения ассоциативного механизма защиты (Stegomask, StegoAlg):
1var stegoMask = new Stegomask(n);
2var stegoAlg = new StegoAlg(n);Шаг 2. Читается текстовый файл с данными из заданного в консоли пути «path»:
1Console.WriteLine("Введите название файла");
2string path = Console.ReadLine();
3if (File.Exists(path))
4{
5 using (Stream fs = File.OpenRead(path))
6 using (StreamReader reader = new StreamReader(fs))
7 text = reader.ReadToEnd();
8}
9else Console.WriteLine("Такого файла не существует!");Шаг 3. С помощью заданного разделителя «separators» и максимального размера блока «blockSize» разбивается входной текст на блоки методом SplitText:
1const int blockSize = 10;
2var separators = new[] { ' ' };
3var textBlocks = SplitText(text, separators, blockSize);Определение данного метода со всеми входными параметрами:
1static List<string> SplitText(string text, char[] delimiters, int maxBlockSize)
2{
3 var blocks = new List<string>();
4 var currentBlock = new StringBuilder();
5 foreach (var character in text)
6 {
7 currentBlock.Append(character);
8 if (delimiters.Contains(character) && currentBlock.Length >= maxBlockSize)
9 {
10 blocks.Add(currentBlock.ToString());
11 currentBlock.Clear();
12 }
13 }
14 if (currentBlock.Length > 0)
15 blocks.Add(currentBlock.ToString());
16 return blocks;
17}Шаг 4. Основным выражением baseRegex будет являться любое число (\d+) и с помощью регулярного выражения regex, шаблоном которого является выражение ({baseRegex})|((.(?!{baseRegex}))*.), выполняется поиск и извлечение из блоков числовых фрагментов или фрагментов, соответствующих любой последовательности символов, за которыми не следуют цифры. Запускается параллельная обработка фрагментов текста:
1var fragments = new ConcurrentBag<CipherDataSet>();
2var regex = new Regex($@"({baseRegex})|((.(?!{baseRegex}))*.)", RegexOptions.Singleline);
3Parallel.ForEach(textBlocks, (block, blockState, i_b) =>
4{
5 var matches = regex.Matches(block).OfType<Match>().ToList();
6 Parallel.ForEach(matches, (match, matchState, i_m) =>
7 {
8 if (Regex.IsMatch(match.Value, baseRegex))
9 {
10 fragments.Add(new CipherDataSet
11 {
12 IsPrivateText = true,
13 Id = new IndexData { block = i_b, match = i_m }.EncryptID(stegoAlg),
14 Text = Encrypt(match.Value, stegoAlg),
15 }); ;
16 }
17 else
18 {
19 fragments.Add(new CipherDataSet
20 {
21 IsPrivateText = false,
22 Id = new IndexData { block = i_b, match = i_m }.EncryptID(stegoAlg),
23 Text = match.Value,
24 });
25 }
26 });
27});Шаг 5. В конкурентную коллекцию «fragments» добавляются новые объекты. Проверяется условие соответствия регулярному выражению (baseRegex). В положительном случае проверки флаг приватности «IsPrivateText» становится истинным, сам фрагмент подвергается обработке методом Encrypt:
1public struct CipherDataSet
2{
3 [DataMember]
4 public bool IsPrivateText;
5 [DataMember]
6 public string Id;
7 [DataMember]
8 public string Text;
9}Шаг 6. В методе Encrypt строка text преобразуется в массив байтов с помощью метода Encoding.UTF8.GetBytes(text), создаётся новый поток памяти (ms) и новый поток (c) с использованием предоставленного алгоритма stegoAlg. Записываются данные строки text в стегопоток с помощью метода Write, преобразуется массив байтов encryptedData из стегопотока в массив байтов с помощью метода ToArray(). В итоге метод Encrypt возвращает закодированную строку в виде Base64 с помощью метода Convert.ToBase64String:
1static string Encrypt(string text, StegoAlg stegoAlg)
2{
3 byte[] data = Encoding.UTF8.GetBytes(text);
4 using (var ms = new MemoryStream())
5 {
6 using (Stream c = new StegoStream(ms, stegoAlg))
7 {
8 c.Write(data, 0, data.Length);
9 }
10 var encryptedData = ms.ToArray();
11 return Convert.ToBase64String(encryptedData);
12 }
13}Вне зависимости от результата проверки, идентификаторы блоков «i_b» и соответствий «i_m» подвергаются обработке методом EncryptID, который в свою очередь определен в структуре «IndexData». В данном методе создаётся экземпляр класса DataContractJsonSerializer, который предназначен для сериализации объектов в формате JSON, задаётся тип сериализуемого объекта как typeof(IndexData). Создаётся новый поток памяти (ms) для записи объекта. Вызывается метод WriteObject для сериализации текущего объекта (this) в поток памяти и получается строковое представление данных, записанных в поток памяти, с помощью метода Encoding.UTF8.GetString. В итоге метод EncryptID возвращает зашифрованную версию идентификатора, вызвав метод Encrypt:
1public struct IndexData
2{
3 [DataMember(Order = 1)]
4 public long match;
5 [DataMember(Order = 2)]
6 public long block;
7 public string EncryptID(StegoAlg stegoAlg)
8 {
9 var serializer = new DataContractJsonSerializer(typeof(IndexData));
10 var ms = new MemoryStream();
11 serializer.WriteObject(ms, this);
12 string data = Encoding.UTF8.GetString(ms.ToArray());
13 return Encrypt(data, stegoAlg);
14 }
15}Шаг 7. После проделанной параллельной обработки полученные данные (fragments) с помощью метода сериализации SerializeToJson преобразуются в структурированный JSON-файл. Конечный результат сохраняется в новый текстовый файл по указанному пути (privateTextPath):
1const string privateTextPath = "PrivateText.json";
2SerializeToJson(fragments, privateTextPath);
3static void SerializeToJson(ConcurrentBag<CipherDataSet> fragments, string filePath)
4{
5 try
6 {
7 var serializer = new DataContractJsonSerializer(typeof(ConcurrentBag<CipherDataSet>));
8 using (var fileStream = File.Create(filePath))
9 {
10 serializer.WriteObject(fileStream, fragments);
11 }
12 }
13 catch (Exception ex) { Console.WriteLine(ex.Message); }
14}Шаг 8. Для восстановления текста из JSON-формата используется метод десериализации DeserializeFromJson, который возвращает коллекцию структуры «ChipherDataSet» с помощью интерфейса IEnumerable:
1static IEnumerable<CipherDataSet> DeserializeFromJson(string filePath)
2{
3 var serializer = new DataContractJsonSerializer(typeof(IEnumerable<CipherDataSet>));
4 using (var fileStream = File.OpenRead(filePath))
5 {
6 return (IEnumerable<CipherDataSet>)serializer.ReadObject(fileStream);
7 }
8}Шаг 9. Полученная коллекция «fragments2» сортируется с помощью технологии Parallel LINQ:
1SerializeToJson(fragments, privateTextPath);
2var fragments2 = DeserializeFromJson(privateTextPath);
3var orderedFragments = fragments2
4 .AsParallel()
5 .OrderBy(ds =>
6 {
7 var id = new IndexData();
8
9 id.DecryptID(ds.Id, stegoAlg);
10 return (id.block, id.match);
11 })
12 .Select(ds => ds.IsPrivateText ? Decrypt(ds.Text, stegoAlg) : ds.Text)
13 .ToList();
14StreamWriter sw = new StreamWriter("decr.txt");
15foreach (var fragment in orderedFragments)
16{
17 sw.Write(fragment);
18}
19sw.Close();
20stegoAlg.Dispose();Метод AsParallel() позволяет одновременно выполнять операции над элементами fragments2. Метод OrderBy в данном случае сортирует согласно результату выражения внутри скобок. Результат выражения зависит от создания объекта IndexData, который затем используется для раскрытия методом DecryptId, применяющий ассоциативный механизм защиты, в основе которого задан экземпляр StegoAlg, идентификатора (Id) и возвращения пары значений (block, match). Эти значения и используются для сортировки элементов массива.
Метод Select преобразует каждый элемент. Если свойство IsPrivateText элемента ds истинно, то функция Decrypt, применяющая ассоциативный механизм защиты, в основе которого задан экземпляр StegoAlg, вызывается для дешифрования текста. В противном случае, возвращается сам текст:
1SerializeToJson(fragments, privateTextPath);
2var fragments2 = DeserializeFromJson(privateTextPath);
3var orderedFragments = fragments2
4 .AsParallel()
5 .OrderBy(ds =>
6 {
7 var id = new IndexData();
8 id.DecryptID(ds.Id, stegoAlg);
9 return (id.block, id.match);
10 })
11 .Select(ds => ds.IsPrivateText ? Decrypt(ds.Text, stegoAlg) : ds.Text)
12 .ToList();
13StreamWriter sw = new StreamWriter("decr.txt");
14foreach (var fragment in orderedFragments)
15{
16 sw.Write(fragment);
17}
18sw.Close();
19stegoAlg.Dispose();Тело метода DecryptID:
1public void DecryptID(string encryptedData, StegoAlg stegoAlg)
2{
3 string json = Decrypt(encryptedData, stegoAlg);
4 var serializer = new DataContractJsonSerializer(typeof(IndexData));
5 var data = (IndexData)serializer.ReadObject(new MemoryStream(Encoding.UTF8.GetBytes(json)));
6 this.block = data.block;
7 this.match = data.match;
8}Тело метода Decrypt:
1static string Decrypt(string text, StegoAlg stegoAlg)
2{
3 using (var msInput = new MemoryStream(Convert.FromBase64String(text)))
4 using (var stegoStream = new StegoStream(msInput, stegoAlg))
5 using (var msOutput = new MemoryStream())
6 {
7 stegoStream.CopyTo(msOutput);
8 return Encoding.UTF8.GetString(msOutput.ToArray());
9 }
10}Отсортированная последовательность объектов преобразуется в список методом ToList. После проделанной работы каждый элемент отсортированного списка записывается в новый файл при помощи класса StreamWriter, который реализует запись потока в строку.
Таким образом, при восстановлении текста сначала разбивается fragments2 на части, которые обрабатываются параллельно. Затем части сортируются согласно определенному критерию, и, наконец, собирает их обратно в отсортированный список текстовых строк.
8. Тестирование системы

Рисунок 9 - Демонстрационный пример для финансового документа
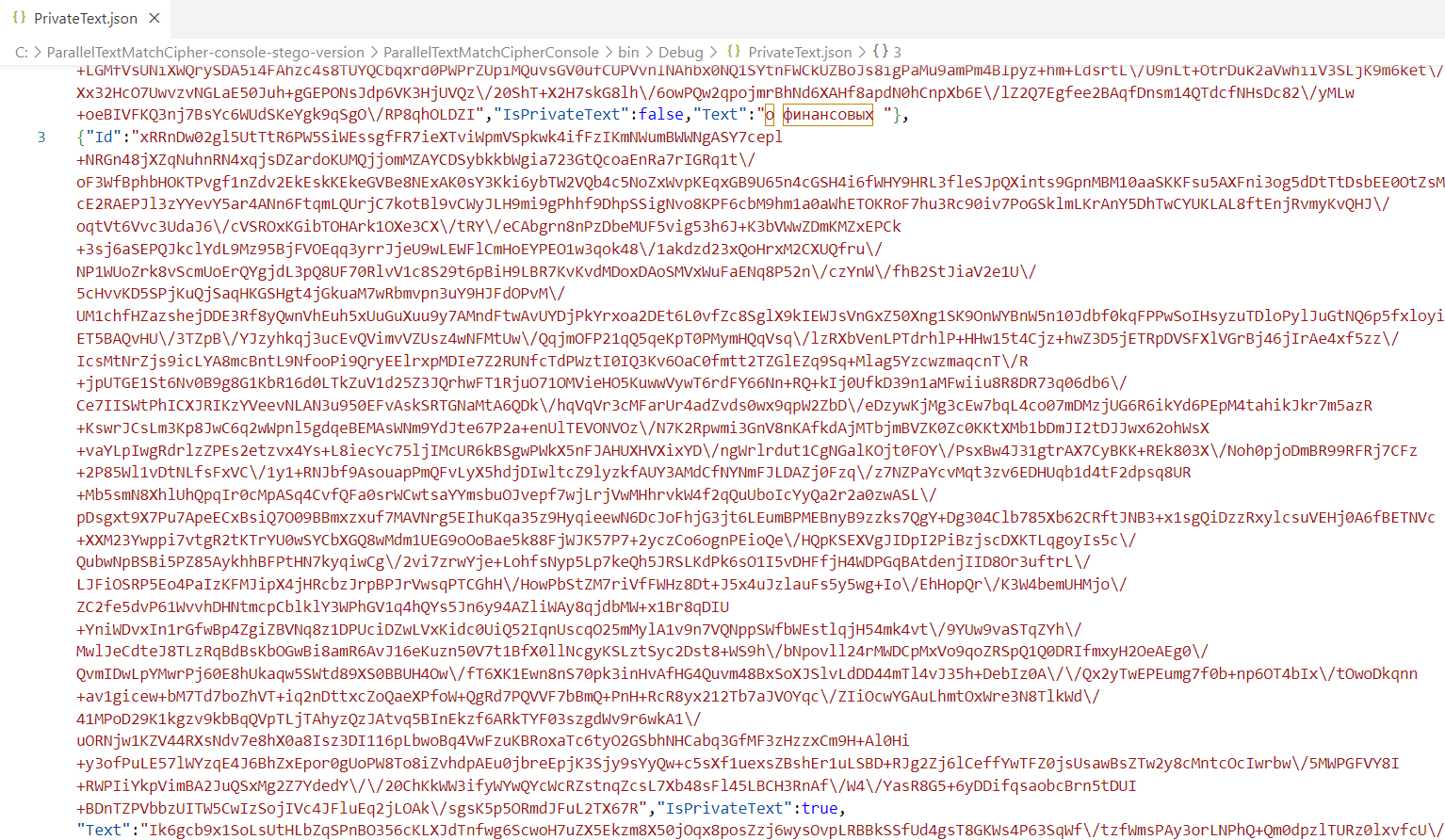
Рисунок 10 - Демонстрационный пример защищенного JSON-файла
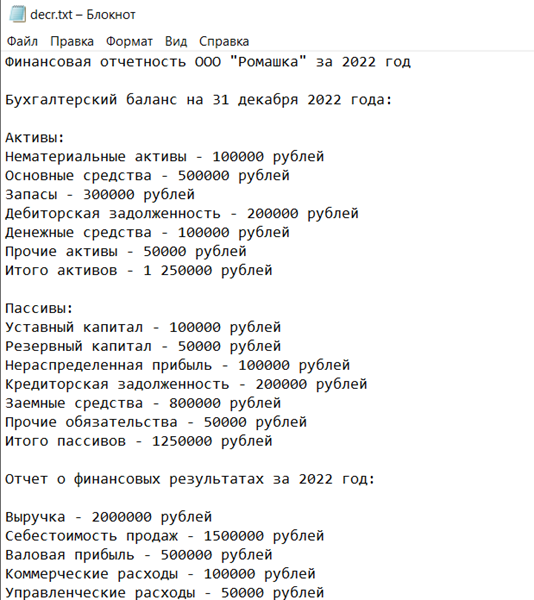
Рисунок 11 - Демонстрационный пример восстановленного файла
- тестирование на разных объемах;
- тестирование модуля с помощью последовательной и параллельной обработки;
- тестирование различных регулярных выражений.
В целях тестирования модуля с исследованием затраченного времени используется класс из пространства имён System.Diagnostics Stopwatch. Он предназначен для точного измерения времени выполнения операций.
Тестирование производилось на различных объемах текстовых файлов, которые имеют финансовые сведения. Были сгенерированы различные файлы, фрагмент одного из них представлен на рисунке 10. Выполнение процедур проводилось на процессоре Intel Core i5-1135G7 с базовой частотой 2,4 ГГц под управлением ОС Windows 10 Pro.
Результаты экспериментов сокрытия файлов различных размеров показали следующие временные показатели, которые представлены в таблице 1. В данных экспериментах целью сокрытия были любые числовые данные. Они были внедрены в произвольные позиции в текст этих файлов. Максимальным размером блока так же было выбрано значение 10, разделителем — пробел.
Таблица 1 - Время сокрытия данных параллельно
Размер документа | Количество цифр в файле | 1 опыт, мсек. | 2 опыт, мсек. | 3 опыт, мсек. | Среднее время обработки, мсек. |
2 КБ | 120 | 30 | 40 | 27 | 32,4 |
7 КБ | 580 | 52 | 55 | 52 | 53 |
13 КБ | 1160 | 82 | 81 | 82 | 82 |
100 КБ | 9228 | 490 | 482 | 497 | 489,7 |
200 КБ | 18456 | 915 | 960 | 928 | 934,4 |
400 КБ | 37068 | 1945 | 1892 | 1870 | 1902,4 |
602 Кб | 55741 | 2831 | 2797 | 2787 | 2805 |
1 МБ | 111805 | 5692 | 5861 | 5739 | 5764 |
2 МБ | 185340 | 9468 | 9307 | 9496 | 9423,7 |
Результаты экспериментов, показавшие время восстановления текста в файл представлены в таблице 2. Исходя из полученных результатов, можно сказать, что на раскрытие данных и восстановление его обратно в текст уходит в 1,5–2 раза больше времени, а в некоторых случаях даже и больше, чем на сокрытие данных.
Таблица 2 - Время восстановления текста
Размер документа | Количество цифр в файле | 1 опыт, мсек. | 2 опыт, мсек. | 3 опыт, мсек. | Среднее время обработки, мсек. |
2 КБ | 120 | 49 | 49 | 51 | 49,7 |
7 КБ | 580 | 113 | 116 | 112 | 113,7 |
13 КБ | 1160 | 187 | 185 | 186 | 186 |
100 КБ | 9228 | 1049 | 1047 | 1052 | 1049,4 |
200 КБ | 18456 | 2043 | 2085 | 2006 | 2044,7 |
400 КБ | 37068 | 4052 | 4129 | 4105 | 4095,4 |
602 КБ | 55741 | 6211 | 6223 | 6292 | 6242 |
1 МБ | 111805 | 13008 | 12654 | 12861 | 12841 |
2 МБ | 185340 | 57994 | 58162 | 57331 | 57829 |
Для более наглядного сравнения и показателя эффективности распараллеливания обработки следовало провести опыты с последовательной обработкой. Фрагменты кода, где происходило распараллеливание блоков по нескольким потокам и поиск соответствий, были адаптированы в последовательную обработку, то есть параллельные методы были заменены последовательными. Тестирование производилось на тех же файлах, что и при параллельном тестировании. Время работы сокрытия данных на разных объемах приведено в таблице 3.
Таблица 3 - Время сокрытия данных последовательно
Размер документа | Количество цифр в файле | 1 опыт, мсек. | 2 опыт, мсек. | 3 опыт, мсек. | Среднее время обработки, мсек. |
2 КБ | 120 | 29 | 25 | 21 | 25 |
7 КБ | 580 | 94 | 94 | 85 | 91 |
13 КБ | 1160 | 156 | 164 | 153 | 157,7 |
100 КБ | 9228 | 1203 | 1158 | 1131 | 1164 |
200 КБ | 18456 | 2261 | 2234 | 2213 | 2236 |
400 КБ | 37068 | 4537 | 4447 | 4551 | 4511,7 |
602 КБ | 55741 | 6968 | 6824 | 6814 | 6868,7 |
1 МБ | 111805 | 13840 | 13694 | 13669 | 13734,3 |
2 МБ | 185340 | 23912 | 23342 | 26190 | 24481,3 |
Для того чтобы оценить эффективность распараллеливания сокрытия данных, целесообразно представить получившиеся временные результаты последовательной и параллельной обработки в одной таблице 4. Проведенные эксперименты показали, что параллельное сокрытие данных происходит быстрее почти в 2 раза по сравнению с последовательным. Однако следует отметить, что при малом размере файла последовательная обработка будет происходить быстрее из-за ряда причин, указанных ранее в главе 2. На малый объем большее количество времени уходит на создание и координацию нескольких потоков, поэтому наблюдается более медленная обработка. Данную ситуацию можно наблюдать при тестировании документа размеров 2 КБ.
Таблица 4 - Сравнение последовательной и параллельной обработки
Размер документа | Количество цифр в файле | Среднее время параллельной обработки, мсек. | Среднее время последовательной обработки, мсек. |
2 КБ | 120 | 32,4 | 25 |
7 КБ | 580 | 53 | 91 |
13 КБ | 1160 | 82 | 157,7 |
100 КБ | 9228 | 489,7 | 1164 |
200 КБ | 18456 | 934,4 | 2236 |
400 КБ | 37068 | 1902,4 | 4511,7 |
602 КБ | 55741 | 2805 | 6868,7 |
1 МБ | 111805 | 5764 | 13734,3 |
2 МБ | 185340 | 9423,7 | 24481,3 |
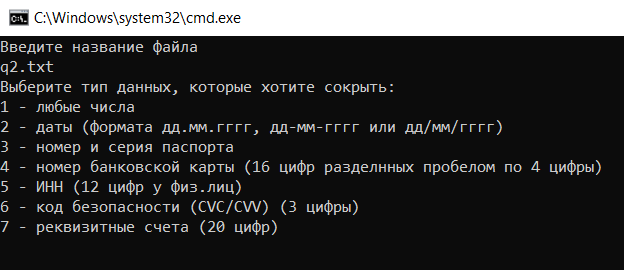
Рисунок 12 - Пример для выбора данных в консоли
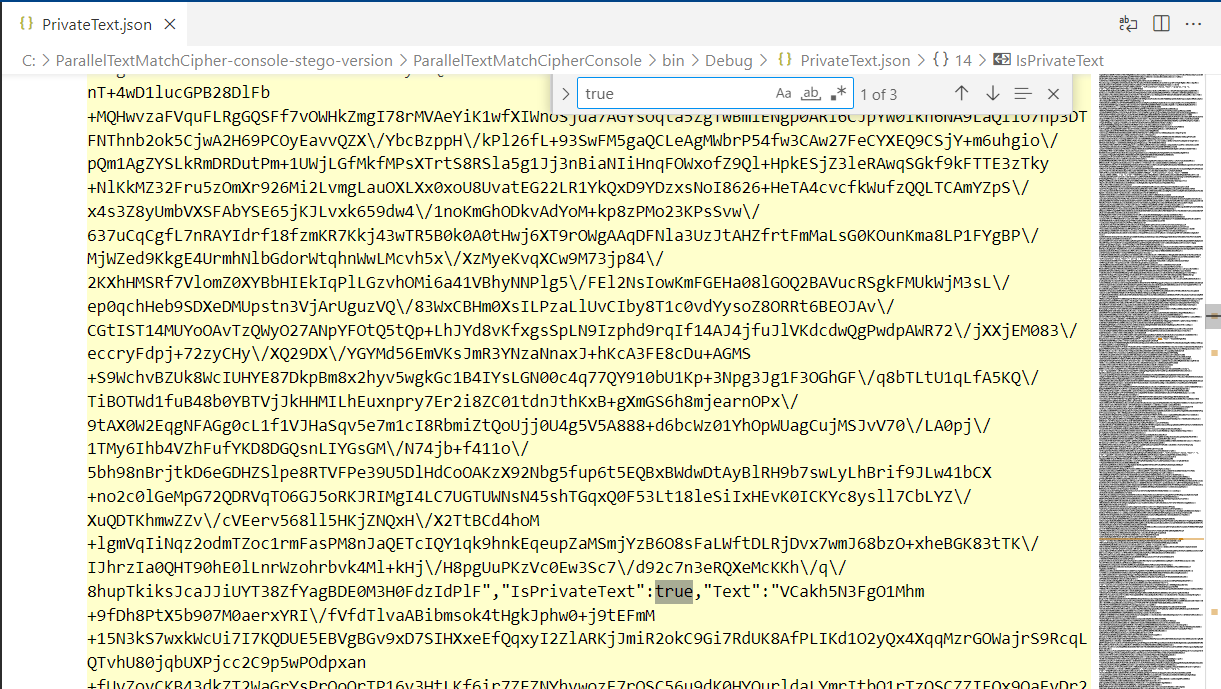
Рисунок 13 - Пример JSON-файла при сокрытии дат
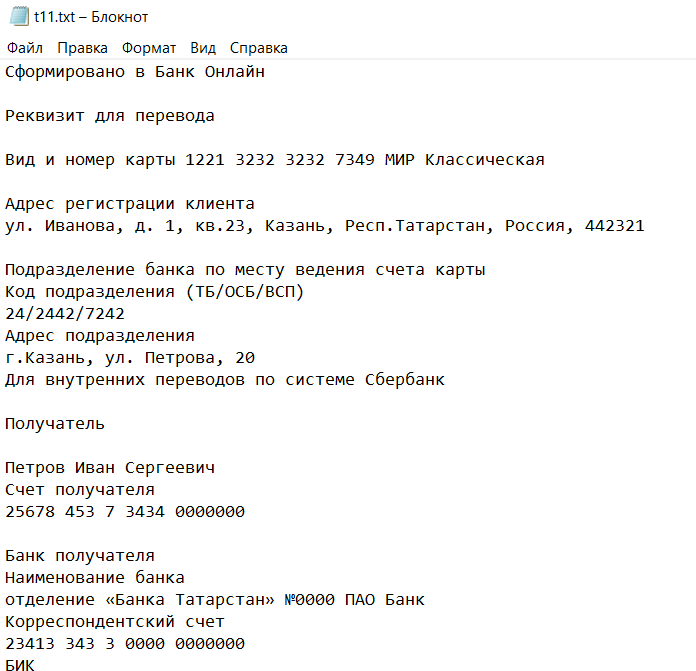
Рисунок 14 - Пример исходного файла при тестировании шаблона
Рисунок 15 - Проверка флага при сокрытии номера банковской карты

Рисунок 16 - Поиск номера карты на предмет проверки правильной работы
Результаты тестирования показали, что разработанный программный модуль ассоциативной защиты файлов с финансовыми данными с использованием регулярных выражений и параллельной библиотеки платформы .NET работает корректно и эффективно.
9. Заключение
Проведенная работа позволила разработать программный модуль ассоциативной защиты файлов с финансовыми данными с использованием регулярных выражений и параллельной библиотеки платформы .NET. Этот модуль не только демонстрирует эффективные методы защиты информации, но и служит ценным учебным инструментом для изучения современных технологий стеганографии, криптографии
и параллельных вычислений.Результаты тестирования показали, что параллельное сокрытие данных происходит быстрее почти в 2 раза по сравнению с последовательным, что подтверждает эффективность применения Task Parallel Library для обработки больших объемов данных. Однако при работе с малыми файлами (например, 2 КБ) последовательная обработка оказывается быстрее из-за накладных расходов на управление потоками. Этот аспект может быть использован в учебном процессе для объяснения принципов оптимизации и выбора подхода в зависимости от объема данных.
Использование регулярных выражений обеспечило гибкость системы, позволяя адаптировать модуль для поиска и сокрытия различных типов конфиденциальных данных, таких как номера банковских карт, даты и суммы. Это делает модуль полезным для обучения студентов работе с текстовыми шаблонами и автоматизированной обработкой информации. Параллельное программирование, реализованное на платформе .NET, наглядно демонстрирует преимущества многопоточной обработки, что особенно актуально в современных условиях роста объемов данных.
В учебных целях модуль может быть использован для:
- изучения основ стеганографии и криптографии;
- освоения работы с регулярными выражениями и параллельными вычислениями;
- практического применения принципов обработки больших данных;
- разработки и тестирования алгоритмов защиты информации.
Перспективы развития модуля включают:
- реализацию пользовательского интерфейса для удобства использования в учебных лабораторных работах;
- расширение набора регулярных выражений для охвата более широкого спектра финансовых и персональных данных;
- интеграцию дополнительных алгоритмов шифрования для сравнения их эффективности;
- разработку методических материалов и примеров для использования в образовательных программах.
Таким образом, разработанный модуль представляет собой не только эффективное решение для защиты данных, но и мощный инструмент для обучения. Его применение в учебном процессе позволит студентам получить практические навыки в области информационной безопасности, параллельного программирования и обработки данных, что соответствует современным требованиям к подготовке IT-специалистов. Дальнейшее развитие модуля может быть направлено на создание специализированных курсов и лабораторных практикумов, способствующих углубленному изучению технологий защиты информации.