DESCRIPTION OF AN APPROACH TO THE FORMATION OF THE KNOWLEDGE BASE FOR THE CLASSIFICATION OF OBJECTS

ОБ ОДНОМ ПОДХОДЕ К ФОРМИРОВАНИЮ БАЗЫ ЗНАНИЙ ДЛЯ КЛАССИФИКАЦИИ ОБЪЕКТОВ
Научная статья
Сергиенко М. А.1, *, Данилова И.В.2
1 ORCID: 0000-0003-1322-9624;
2 ORCID: 0000-0001-5524-8351;
Воронежский государственный университет, Воронеж, Россия
* Корреспондирующий автор (sergienko-m-a[at]yandex.ru)
АннотацияРассматривается проблема классификации объектов, описывающих поведение сложной системы, в предположении, что каждый из них характеризуется с помощью типового набора признаков. На основе этой информации разработан подход, базирующийся на методике нечеткого моделирования, который позволяет сформировать базу знаний в форме продукционных правил для нечеткой системы классификации объектов. Подобные системы обладают повышенными объяснительными способностями. За счет изменения мощности (гранулярности) лингвистических шкал для описательных признаков объектов можно регулировать точность выдаваемого системой ответа.
Ключевые слова: классификация объектов, нечеткая база знаний, экспертная система.
DESCRIPTION OF AN APPROACH TO THE FORMATION OF THE KNOWLEDGE BASE FOR THE CLASSIFICATION OF OBJECTS
Research article
Sergienko M.A.1, *, Danilova I.V.2
1 ORCID: 0000-0003-1322-9624;
2 ORCID: 0000-0001-5524-8351;
Voronezh State University, Voronezh, Russia
* Correspondent author (sergienko-m-a[at]yandex.ru)
AbstractThe article considers the problem of classifying objects that describe the behavior of a complex system under the assumption that each of the objects is characterized with the help of a typical set of features. Following this information, an approach is developed based on the indistinct modeling technique, which allows creating a knowledge base in the form of production rules for an indistinct system for classifying objects. Such systems enhance explanatory abilities. The change of the power (granularity) of linguistic scales for descriptive features of objects allows adjusting the accuracy of the response generated by the system.
Keywords: classification of objects, indistinct knowledge base, expert system.
ВведениеПостоянно растущие объемы накапливаемой и обрабатываемой информации, оцениваемые в петабайтах (Big Data), не позволяют человеку самостоятельно их проанализировать. Автоматизация этого процесса реализуется, в частности, с помощью Data Mining [1], одной из функциональных особенностей которого является задача классификации – отнесение объектов к одному из заранее известных классов.
Динамика роста объема данных настолько велика, что существующие классификаторы и алгоритмы их реализации не успевают так быстро изменяться, что приводит к нежелательным ошибкам. Создание классификаторов, способных предоставлять объяснения по результатам своей работы, способствовало бы выявлению подобных проблем на ранних стадиях. Архитектура таких структур данных базируется на базах знаний, представимых с помощью продукционных правил, которые формируются при непосредственном участии эксперта предметной области.
Данная работа посвящена описанию подхода к созданию классификатора в виде базы нечетких продукционных правил. Подобная база знаний (Knowledge Base, KB) повышает объяснительные способности механизма нечеткого логического вывода, что делает функционирование классификатора более прозрачным.
Формализация постановки задачи
Задача классификации объектов может быть сформулирована как задача аппроксимации неизвестной функции с помощью функции ![]()
где ![]() – классификатор вида
– классификатор вида ![]() – множество классифицируемых объектов;
– множество классифицируемых объектов; ![]() – множество классов.
– множество классов.
Каждый объект ![]() характеризуется значениями типового набора признаков
характеризуется значениями типового набора признаков ![]() :
:
![]()
где ![]() – значение j-го признака для i-го объекта.
– значение j-го признака для i-го объекта.
Зачастую объем априорной информации, характеризующий работу сложной системы, недостаточен для классификации объектов. Для построения эффективного классификатора необходимо иметь обучающую выборку ![]() , а для его проверки на качество – тестовую выборку
, а для его проверки на качество – тестовую выборку ![]() . В подобных выборках информация о принадлежности объекта
. В подобных выборках информация о принадлежности объекта ![]() к классу
к классу ![]() известна и задается в виде кортежа
известна и задается в виде кортежа ![]() , а их размерность определяется количеством содержащихся в них объектов :
, а их размерность определяется количеством содержащихся в них объектов :
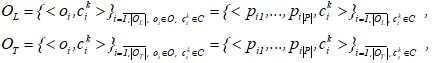 (2)
(2)
где ![]() – значение j-го признака для i-го объекта, а
– значение j-го признака для i-го объекта, а ![]() – k-ый класс для -го объекта.
– k-ый класс для -го объекта.
Таким образом, задача классификации сводится к тому, чтобы на основе обучающей выборки ![]() построить аппроксимацию функции
построить аппроксимацию функции ![]() в виде классификатора
в виде классификатора ![]() , который будет корректно идентифицировать объекты, не участвующих в процессе его создания, а с помощью тестовой выборки
, который будет корректно идентифицировать объекты, не участвующих в процессе его создания, а с помощью тестовой выборки ![]() проверить его на качество.
проверить его на качество.
Обзор подходов к решению задачи классификации
Для решения задачи автоматической классификации объектов в настоящее время широко используются:
- статистические методы;
- методы машинного обучения (Machine Learning, ML) «с учителем»;
- методы нечеткого моделирования.
Статистические методы заключаются в восстановлении зависимости между системной и случайной составляющих на основе методов теории вероятностей [2], [3].
Методы машинного обучения «с учителем» предполагают наличие обучающей и тестовых выборок (для каждого объекта уже определен класс) для восстановления зависимости между входными и выходными переменными. Среди них можно выделить [4], [5]:
- метод Байеса(Naive Bayes, NB), относящийся к классу вероятностных методов;
- методk ближайшихсоседей (k Nearest Neighbors, KNN), относящийся к классу метрических методов;
- метод опорных векторов (Support Vector Machine, SVM), относящийся к классу линейных методов;
- метод деревьев решений (Decision Trees, DT), относящийся к классу логических методов;
- регрессионные методы;
- методы на основе искусственных нейронных сетей (сети прямого распространения, рекуррентные сети и др.).
Методы на основе искусственных нейронных сетей и SVM-метод считаются одними из лучших для решения подобных задач.
Методы нечеткого моделирования [6], [7], [9] базируются на теории нечетких множеств и нечеткой логики, что соответствует логике человеческого мышления, оперирующего нечеткими значениями истинности и нечеткими правилами логического вывода. В основе этих методов лежит Fuzzy Approximation Theorem, согласно которой с помощью условных высказываний если-то с последующей их формализацией на основе лингвистических переменных, можно сколь угодно точно описать произвольную взаимосвязь между входными и выходными переменными.
Отличительной особенностью последнего класса методов по сравнению с другими является то, что в качестве решения задачи классификации предоставляется классификатор, который способен пояснить свой ответ. Это достигается за счет высоких объяснительных способностей механизма нечеткого логического вывода. Данное преимущество и обусловило выбор подхода к решению поставленной задачи.
Основные результаты
Для создания классификатора объектов ![]() предлагается использовать следующий алгоритм:
предлагается использовать следующий алгоритм:
- для каждого признака
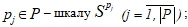
- для каждого класса –
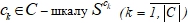
Шаг 3. На основе обучающей выборки ![]() и лингвистических шкал
и лингвистических шкал ![]() сформировать базу нечетких продукционных правил
сформировать базу нечетких продукционных правил 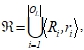 , где
, где ![]() – i-правило, соответствующее i-ой кортеже
– i-правило, соответствующее i-ой кортеже ![]() из
из ![]() , а
, а ![]() – рейтинг i-го правила
– рейтинг i-го правила ![]() .
.
Данные шаги детально рассматриваются в следующих четырех разделах.
Подготовка обучающей и тестовой выборки С привлечением эксперта определяется принадлежность каждого объекта ![]() . Данное соответствие представляется в виде набора кортежей:
. Данное соответствие представляется в виде набора кортежей:
![]()
Множество ![]() разбивается на два подмножества
разбивается на два подмножества ![]() :
:
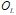 – обучающая выборка, которая используется для формирования базы знаний в форме продукционных правил;
– обучающая выборка, которая используется для формирования базы знаний в форме продукционных правил;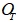 – тестовая выборка, которая используется для оценки прогнозных свойств полученной базы знаний на новых данных, т.е. данных, не участвующих в ее формировании.
– тестовая выборка, которая используется для оценки прогнозных свойств полученной базы знаний на новых данных, т.е. данных, не участвующих в ее формировании.
Полагаясь на основные принципы методологии по исследованию данных CRISP-DM [10], в рамках данного шага при необходимости можно провести нормализацию значений ![]() для каждого j-го признака
для каждого j-го признака ![]() .
.
Методы нормализации [4] используются для изменения признака, который попадает в указанный диапазон, сохраняя при этом относительные различия между его значениями.
Нормализация значений признаков является необязательной, т.к. в рамках шага 4.2 осуществляется фазификация [7], [8], предполагающая использование функций принадлежности, которые могут принимать свои значения только в рамках промежутка ![]() . С другой стороны, ее выполнение позволит использовать единую лингвистическую шкалу для признаков (шаг 4.2).
. С другой стороны, ее выполнение позволит использовать единую лингвистическую шкалу для признаков (шаг 4.2).
Таким образом, результатами данного шага являются обучающая ![]() и тестовая
и тестовая ![]() выборки, представленные в виде (2).
выборки, представленные в виде (2).
Построение лингвистических шкал для признаков и классов
В общем случае основой использования лингвистического подхода для формализации неточной и нечеткой информации является значительная степень неопределенности. Базовым понятием данного подхода является лингвистическая переменная, позволяющая приближенно описывать сложные понятия процесса функционирования систем, которые не поддаются представлению на общепринятых количественных шкалах.
Лингвистическая переменная задается кортежем следующего вида [8]:
![]()
где β – название переменной; ![]() – терм-множество или множество значений переменной β, причем каждое из них является нечеткой переменной
– терм-множество или множество значений переменной β, причем каждое из них является нечеткой переменной ![]() , заданной на универсальном множестве U; G – синтаксическое правило, порождающее новые названия значений переменной β для формирования расширенного множества термов
, заданной на универсальном множестве U; G – синтаксическое правило, порождающее новые названия значений переменной β для формирования расширенного множества термов ![]() ; M – семантическое правило, которое ставит в соответствие каждой новой нечеткой переменной ее смысл (нечеткое подмножество универсального множества U).
; M – семантическое правило, которое ставит в соответствие каждой новой нечеткой переменной ее смысл (нечеткое подмножество универсального множества U).
Нечеткая переменная задается тройкой ![]() , где α – название переменной; U – универсальное множество (область определения α); A – нечеткое множество на U с функцией принадлежности
, где α – название переменной; U – универсальное множество (область определения α); A – нечеткое множество на U с функцией принадлежности ![]() , описывающее ограничения на значение нечеткой переменной α.
, описывающее ограничения на значение нечеткой переменной α.
Преобразование информации при решении задач осуществляется на основе нечетких переменных с соответствующими функциями принадлежности. Поэтому для каждого терма строится функция принадлежности одним из подходящих методов (возможно, с участием эксперта). Для задания функций принадлежности существуют различные типы форм кривых [6], [7].
Терм-множество лингвистической переменной образует лингвистическую шкалу – инструмент эксперта для формирования качественных оценок. Мощность лингвистической шкалы определяет степень градации неопределенности: она должна быть достаточно малой для избегания ненужной точности, но и достаточно большой, чтобы обеспечить необходимый уровень различения градаций шкалы экспертом.
Для построения лингвистических шкал для признака ![]() необходимо располагать информацией о диапазоне изменения их значений. Верхняя и нижняя границы диапазона могут быть найдены методом экспертного опроса либо путем изучения наборов обучающей выборки с целью определения минимального и максимального значений признака. После чего найденный диапазон надлежит разделить на отрезки по количеству ранее установленных термов.
необходимо располагать информацией о диапазоне изменения их значений. Верхняя и нижняя границы диапазона могут быть найдены методом экспертного опроса либо путем изучения наборов обучающей выборки с целью определения минимального и максимального значений признака. После чего найденный диапазон надлежит разделить на отрезки по количеству ранее установленных термов.
Для решения задачи классификации предлагается использовать лингвистические шкалы с нечетным числом термов, симметричные относительно среднего терма. Размерность шкалы согласовывается с экспертом. Для задания функций принадлежности для термов предлагается использовать следующие типы кривых: треугольная, трапециевидная, гауссова.
На основе обучающей выборки ![]() строятся лингвистические шкалы для каждого признака
строятся лингвистические шкалы для каждого признака ![]() и классов
и классов ![]() .
.
Для каждого признака ![]() строится симметрическая лингвистическая шкала
строится симметрическая лингвистическая шкала ![]() .
.
Для каждого класса ![]() строится лингвистическая шкала
строится лингвистическая шкала ![]() , состоящая из одного терма (синглтон, singleton):
, состоящая из одного терма (синглтон, singleton):
![]()
где k– номер k-го класса ![]() .
.
Таким образом, результатами данного шага являются следующие лингвистические шкалы: ![]() .
.
Обобщая представленные результаты, получим:
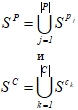 (3)
(3)
Формирование базы нечетких продукционных правил
На основе обучающей выборки ![]() и лингвистических шкал (3) формируется база нечетких продукционных правил с MISO-структурой (multi input – single output, много входов – один выход). Каждому кортежу
и лингвистических шкал (3) формируется база нечетких продукционных правил с MISO-структурой (multi input – single output, много входов – один выход). Каждому кортежу ![]() из
из ![]() ставится в соответствие правило:
ставится в соответствие правило:
![]()
Ассоциация с термами ![]() лингвистических шкал
лингвистических шкал ![]() для признаков
для признаков ![]() nосуществляется на основе их значений
nосуществляется на основе их значений ![]() по следующему правилу: выбирается терм, которому соответствует функция принадлежности, принимающая максимальное значение в точке
по следующему правилу: выбирается терм, которому соответствует функция принадлежности, принимающая максимальное значение в точке ![]() :
:
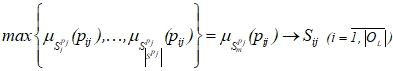 (4)
(4)
Для каждого правила ![]() рассчитывается его рейтинг
рассчитывается его рейтинг ![]() :
:
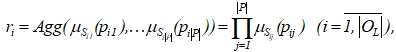
где ![]() – значение функции принадлежности, соответствующей терму
– значение функции принадлежности, соответствующей терму ![]() , полученному на основе (4).
, полученному на основе (4).
Таким образом, результатом данного шага является база нечетких продукционных правил:
![]()
Обобщая полученные результаты текущего и предыдущего шагов, получим представление базы знаний с помощью нечетких продукционных правил и лингвистических шкал для входных/выходных переменных в виде следующего кортежа ![]() .
.
Полученная база знаний и является реализацией классификатора ![]() :
:
![]()
Проверка на качество полученного классификатора
Данный шаг подразумевает:
- проверку на качество полученной базы нечетких продукционных правил
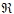 ;
; - проверку точности функционирования классификатора
 на основе тестовой выборки .
на основе тестовой выборки .
Проверка на качество ![]() заключается в выполнении следующих свойств [12]:
заключается в выполнении следующих свойств [12]:
- непротиворечивость;
- полнота:
- в узком смысле;
- в широком смысле (численная и лингвистическая);
- избыточность;
- разделимость.
и опирается на репрезентативность выборки и использование рейтингов правил.
Проверка точности функционирования классификатора на основе тестовой выборки ![]() заключается в том, что для каждого объекта
заключается в том, что для каждого объекта ![]() из кортежа
из кортежа ![]() определяется его принадлежность к классу
определяется его принадлежность к классу ![]() с помощью
с помощью ![]() и сравнивается с ожидаемым классом
и сравнивается с ожидаемым классом ![]() . Основываясь на этом сравнении, можно измерить показатели эффективности (ПЭ) [4], чтобы количественно оценить, насколько прогнозы классификатора
. Основываясь на этом сравнении, можно измерить показатели эффективности (ПЭ) [4], чтобы количественно оценить, насколько прогнозы классификатора ![]() , соответствуют ожидаемым.
, соответствуют ожидаемым.
Простейшим ПЭ является доля ошибок классификации (ДОК), выражаемая в процентах:
Расчет ПЭ опирается в основном на матрицу ошибок (confusion matrix), которая содержит частоты каждого возможного результата прогноза, сделанных моделью (классификатором) для множества тестовых данных. Разнообразие показателей с их алгоритмами вычисления велико и использование интересующих определяется контекстом решаемой задачи.
Вычислительный эксперимент
Рассмотренный метод был использован для реализации экспертной системы (ЭС) [13] по оценке квалификации сотрудников Компании. Задача данной ЭС заключается в том, чтобы на основе числовой (бальной) оценки квалификации сотрудника определить для него соответствующее положение в проекте (роль/должность).
Эксперимент проводился на ПЭВМ со следующими основными параметрами: 2-х ядерный 64-разрядный процессор Intel(R) Pentium(R) 3556U 1.70GHz, 4ГБ ОЗУ. В качестве технологии для реализации ЭС использовался язык программирования Python и библиотека skfuzzy [14], содержащая API для работы с основными элементами нечеткой логикой.
Множество классов в данном случае формируется из набора ролей и должностей (табл. 1). Их перечень был составлен согласно руководству PMBOK [15], представляющему собой свод знаний по управлению проектами и включающему описание подходов к организации и концепции управления проектами, формализацию, стандартизацию и структурирование форматов проектной деятельности.
Таблица 1 – Перечень ролей и должностей
| Роли |
| Java Developer |
| Python Developer |
| System Administrator |
| Web Developer |
| Project Manager |
| QA |
| DB Engineer |
| Должности |
| Junior |
| Middle |
| Senior |
| Team Lead |
Менеджером по персоналу (HR-менеджером) был сформулирован перечень квалификационных требований, подготовлены тесты и проведена аттестация персонала Компании. Оценка квалификационных требований персонала осуществлялась по 100-бальной шкале. Результаты были аккумулированы в виде Excel-файла, фрагмент которого представлен на рис. 1.
На основе представленных данных были сформированы обучающая ![]() и тестовая
и тестовая ![]() выборки в виде (2).
выборки в виде (2).
Для всех квалификационных требований использовалась единая лингвистическая шкала, построенная на основе лингвистической переменной «Оценка квалификационного требования» с универсальным множеством ![]() и множеством термов
и множеством термов ![]() . Каждый терм – нечеткое треугольное число (рис. 2).
. Каждый терм – нечеткое треугольное число (рис. 2).
Согласно шагу 4.3 была сформирована нечеткая продукционная база правил ![]() вида (на примере правила для Java Developer junior):
вида (на примере правила для Java Developer junior):
IF Java[good] AND
SQL[great] AND
C#[fair] AND
Python[fair] AND
Linux[fair] AND
MSOffice[good] AND
PHP[fair] AND
Zabbix[fair]
THEN response[Java Developer junior]
Данная база правил ![]() и является реализацией классификатора
и является реализацией классификатора ![]() .
.
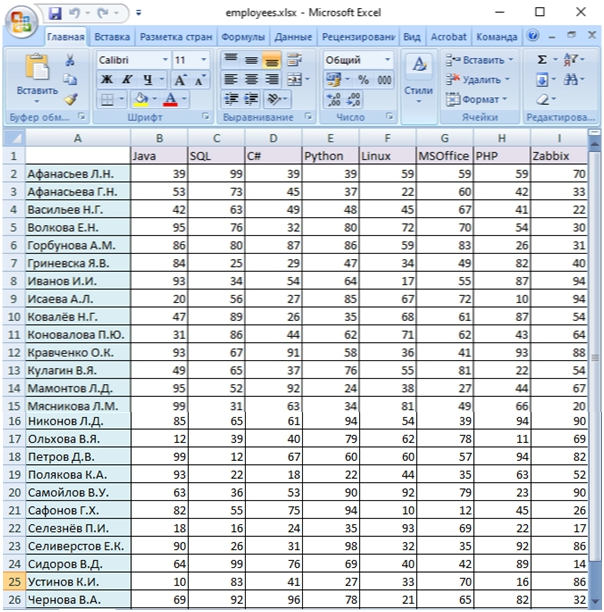
Рис. 1 – Фактическая оценка квалификационных требований персонала Компании
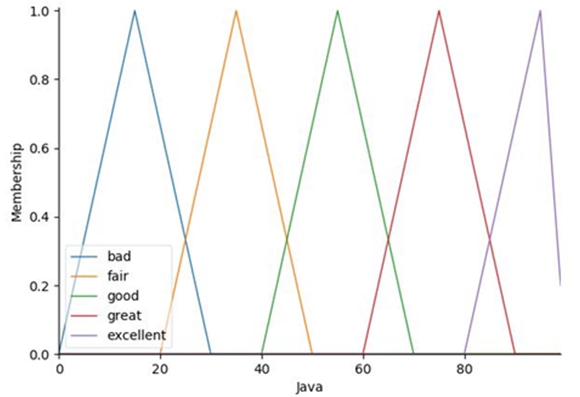
Рис. 2 – Лингвистическая шкала лингвистической переменной «Оценка квалификационного требования» (на примере квалификационного требования Java)
Проверка на качество полученного классификатора ![]() осуществлялась на основе тестовой выборки
осуществлялась на основе тестовой выборки ![]() и с привлечением эксперта.
и с привлечением эксперта.
Результаты повторной аттестации в виде Excel-файла были переданы на вход ЭС, она осуществила безошибочно определение «проектной локализации» для каждого сотрудника Компании (рис. 3). Время ответа на запрос – 08.306 сек.
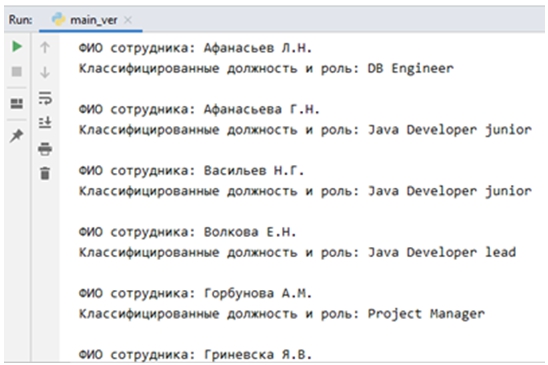
Рис. 3 – Результат работы ЭС
ЭС можно задействовать при принятии решения о приеме новых сотрудников в Компанию, либо о повышении в должности существующего персонала.
Заключение
Предложенный подход в ходе эксперимента продемонстрировал свою работоспособность. Он позволяет создать классификатор, который можно использовать в качестве ядра нечеткой экспертной системы классификации объектов [11], [13]. Подобные системы обладают повышенными объяснительными способностями. За счет изменения мощности (гранулярности) лингвистических шкал для описательных признаков объектов можно регулировать точность выдаваемого системой ответа. Указанные преимущества позволяют таким нечетким экспертным системам находить все более широкое приложение в практических задачах.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References
- Linoff Gordon S. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management / Gordon S. Linoff, Michael J.A. – Wiley Publishing, Inc, 2011. – 821 p.
- Draper N.R. Applied Regression Analysis / N.R. Draper, H. Smith. – John Wiley & Sons, 1998. – 736 p.
- Айвазян С.А. Методы эконометрики / С.А. Айвазян. – М. : Инфра-М, 2010. – 508 с.
- Келлехер Джон Д. Основы машинного обучения для аналитического прогнозирования. Алгоритмы, рабочие примеры и тематические исследования / Джон Д. Келлехер, Брайан Мак-Нейми, Аоифе д'Арси. – М.: Издательский дом «Диалектика-Вильямс», 2019. – 656 с.
- Хайкин С. Нейронные сети. Полный курс / С. Хайкин. – М. : Издательский дом «Вильямс», 2006. – 1104 с.
- Кофман А. Введение в теорию нечетких множеств / А.Кофман. – М.: Радио и связь, 1982. - 432 с.
- ПегатА. Нечеткое моделирование и управление / А.Пегат. – М.: БИНОМ, 2009. – 798 с.
- Леденева Т.М. Обработка нечеткой информации: учебное пособие / Т.М.Леденева. – Воронеж: Воронежский государственный технический университет, 2006. – 233 с.
- Борисов В.В. Нечеткие модели и сети / В.В.Борисов, В.В.Круглов, А.С. Федулов. М.: Горячая линия – Телеком, 2007. – 284 с.
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining / C. Shearer // Journal of Data Warehousing. – 2000. – Vol. 5. – pp. 13-22.
- Леденева Т.М. Об одном подходе к формированию базы знаний для сегментации временных рядов / Т.М. Леденева, М.А. Сергиенко // Вестник ВГУ. Серия Системный анализ и информационные технологии, 2017. – № 3. – С. 156-164.
- Сергиенко М.А. О некоторых свойствах базы нечетких продукционных правил / М.А.Сергиенко // Международный научно-исследовательский журнал. – 2015. – Ч.3. – №1(32) – С. 27-28.
- ДжарратаноД. Экспертные системы: принципы разработки и программирование / Д.Джарратано, Г.Райли. – 4-е изд. – М.: Издательский дом «Вильямс», 2007. – 1152 с.
- SciKit-Fuzzy – skfuzzy v2 docs [Электронный ресурс] // URL: https://pythonhosted.org/scikit-fuzzy/overview.html (дата обращения 27.02.2020).
- Guide to the Project Management Body of Knowledge PMBOK Guide 6th Edition. – Newtown Square, Pa: Project Management Institute, 2018 – 41 p.
Список литературы на английском языке / References in English
- Linoff Gordon S. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management / Gordon S. Linoff, Michael J.A. Berry. – Wiley Publishing, Inc. 2011. – 821 p.
- Draper N.R. Applied Regression Analysis / N.R. Draper, H. Smith. – John Wiley Sons, 1998. – 736 p.
- Ajvazjan S.A. Metody jekonometriki [Methods of econometrics]/ S.A. Ajvazjan. – M.: Infra-M, 2010. – 508 p. [in Russian]
- Kelleher Dzhon D. Osnovy mashinnogo obuchenija dlja analiticheskogo prognozirovanija. Algorit-my, rabochie primery i tematicheskie issledovanija [The Basics of Machine Learning for Analytical Predic-tion. Algorithms, working examples and case studies] / Dzhon D. Kelleher, Brajan Mak-Nejmi, Aoife d'Arsi. – M.: Izdatel'skij dom «Dialektika-Vil'jams», 2019. – 656 p. [in Russian]
- Hajkin S. Nejronnye seti. Polnyj kurs [Neural Networks. Full course] / S. Hajkin. – M. : Izdatel'skij dom «Vil'jams», 2006. – 1104 p. [in Russian]
- Kofman A. Vvedenie v teoriju nechetkih mnozhestv [Introduction to the theory of indistinct sets] / A.Kofman. – M.: Radio i svjaz', 1982. 432 p. [in Russian]
- Pegat A. Nechetkoe modelirovanie i upravlenie [Fuzzy modeling and management] / A. Pegat. – M.: BINOM, 2009. – 798 p. [in Russian]
- Ledeneva T.M. Obrabotka nechetkoj informacii: uchebnoe posobie [Processing of indistinct infor-mation: manual] / T.M. Ledeneva. – Voronezh: Voronezhskij gosudarstvennyj tehnicheskij universitet, 2006. – 233 p. [in Russian]
- Borisov V.V. Nechetkie modeli i seti [Fuzzy models and networks] / V.V. Borisov, V.V. Kruglov, A.S. Fedulov. M.: Gorjachaja linija – Telekom, 2007. – 284 p. [in Russian]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining / C. Shearer // Journal of Data Warehousing. – 2000. – Vol. 5. – pp. 13-22.
- Ledeneva T.M. Ob odnom podhode k formirovaniju bazy znanij dlja segmentacii vremennyh rjadov [On One Approach to the Formation of a Knowledge Base for Time Series Segmentation] / T.M. Ledeneva, M.A. Sergienko // Vestnik VGU. Serija Sistemnyj analiz i informacionnye tehnologii [VSU Gazette. Series System Analysis and Information Technologies]. 2017. – № 3. – pp. 156-164. [in Russian]
- Sergienko M.A. O nekotoryh svojstvah bazy nechetkih produkcionnyh pravil [On Certain Properties of the Base of Fuzzy Production Rules] / M.A. Sergienko // Mezhdunarodnyj nauchno-issledovatel'skij zhur-nal [International Research Journal]. – 2015. – Ch.3. – № 1 (32) – pp. 27-28. [in Russian]
- Dzharratano D. Jekspertnye sistemy: principy razrabotki i programmirovanie [Expert Systems: Principles of Development and Programming] / D. Dzharratano, G.Rajli. – 4-e izd. – M.: Izdatel'skij dom «Vil'jams», 2007. – 1152 p. [in Russian]
- SciKit-Fuzzy – skfuzzy v0.2 docs [Electronic resource] // URL: https://pythonhosted.org/scikit-fuzzy/overview.html (accessed: 23.02.2020). [in Russian]
- Guide to the Project Management Body of Knowledge PMBOK Guide 6th Edition. – Newtown Square, Pa: Project Management Institute, 2018 – 41 p.