The CVAE-WGAN hybrid generative model based on TimeVAE for the analysis of multidimensional time series of socio-economic indicators
The CVAE-WGAN hybrid generative model based on TimeVAE for the analysis of multidimensional time series of socio-economic indicators

Abstract
The article examines the Conditional Variational Autoencoder-Wasserstein Generative Adversarial Network (CVAE-WGAN) generative model, which is designed to analyse and forecast time series of socio-economic indicators. This architecture combines three key components: a Conditional Variational Autoencoder (CVAE), which ensures the creation of a compact latent space; a Wasserstein Generative Adversarial Network (WGAN), which enhances the realism of the generated sequences; and the TimeVAE missing data mechanism, which enables the effective reconstruction of missing data. This model is designed to operate under conditions of incomplete and heterogeneous statistical data, which are characteristic of regional economic analysis. The paper presents a description of the model architecture, a training scheme, the validation methods used, and possible quality metrics. The advantages of the model’s architecture compared to traditional time series forecasting methods are highlighted.
1. Введение
Анализ многомерных временных рядов социально-экономических показателей является одной из фундаментальных задач современной региональной науки и применение в практике государственного управления. Федеральные министерства и ведомства, региональные органы власти, инвестиционные компании и научно-исследовательские организации постоянно нуждаются в инструментах, позволяющих выявлять скрытые закономерности, оценивать текущее состояние и формировать обоснованные прогнозы развития сложных социально-экономических систем.
Сложность данной задачи состоит из нескольких факторов.
Во-первых, социально-экономические показатели характеризуются высокой степенью взаимосвязи, например, (инвестиции в основной капитал) изменение одного показателя влечет за собой изменение множества других (валовой региональный продукт, занятость, доходы населения и т.д.).
Во-вторых, временные ряды часто содержат пропуски, вызванные изменением методологии сбора данных, техническими ошибками или отсутствием наблюдений в сложный период.
В-третьих, динамика показателей носит нелинейный характер и подвержена воздействию экзогенных шоков.
Традиционные методы анализа временных рядов — это модели ARIMA, экспоненциальное сглаживание, векторные авторегрессии «векторной авторегрессии (сокращённо VAR — Vector Autoregressive Model), во-первых, демонстрируется как обобщение AR-моделей в случае применения многомерных временных рядов», а также «VAR-модель представляет собой частный случай системы, состоящей из одновременных уравнений»
— данные модели имеют весьма ограниченные возможности при работе с многомерными данными, особенно в условиях неполноты наблюдений. Эти методы, как правило, требуют стационарности рядов, полноты данных и линейности зависимостей, что не всегда соответствует реальной экономической динамике.В последние годы активное развитие получили методы машинного обучения и глубоких нейронных сетей. Рекуррентные архитектуры (RNN, LSTM, GRU) ориентированы на анализ временной последовательности состояний группы объектов и продемонстрировали высокую эффективность при моделировании последовательных данных. Генеративные модели, такие как вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN), открыли новые возможности для синтеза реалистичных временных рядов и работы с неполными данными.
Целью настоящего исследования является разработка и описание гибридной генеративной модели, объединяющей достоинства CVAE-WGAN и TimeVAE
для анализа многомерных временных рядов социально-экономических показателей. В отличие от существующих подходов, предложенная архитектура позволяет одновременно решать задачи импутации пропусков, генерации реалистичных последовательностей и условного прогнозирования с учетом специфики региона.Обзор существующих методов анализа временных рядов. Существуют классические статистические методы, методы машинного обучения и нейросетевые методы.
Классический подход к анализу временных рядов базируется на моделях семейства ARIMA «линейная стохастическая модель авторегрессии проинтегрированного скользящего среднего (AutoRegressive Integrated Moving Average). Параметры моделей типа ARIMA оцениваются на основе коэффициентов автокорреляции исходного процесса
. С увеличением числа параметров в модели для определения их значений необходимо использовать в качестве исходных данных большее число выборочных коэффициентов автокорреляции (с большими «шагами»). Точность их оценки с ростом шага падает, что снижает надежность оценок коэффициентов моделей временных рядов высоких порядков и качество этих моделей» . Эти модели описывают динамику ряда через его собственные предыдущие значения и скользящее среднее ошибок прогноза. Но существующая модификация SARIMA позволяют учитывать сезонные колебания. Однако ARIMA-модели являются унивариантными — они анализируют каждый ряд независимо, что не позволяет учитывать взаимосвязи между показателями.Векторные авторегрессии (VAR) представляют собой многомерное обобщение ARIMA-моделей. В VAR каждый показатель зависит от собственных лагов и лагов других показателей. Эти модели широко применяются в макроэкономическом анализе, однако они требуют стационарности всех рядов, большого объема данных для надежной оценки параметров и линейности зависимостей.
Существующие методы экспоненциального сглаживания (модели Хольта-Уинтерса) эффективны для рядов с трендом и сезонностью, но также являются зависимыми от одной переменной и не учитывают многомерные связи.
Методы машинного обучения — это случайный лес (от англ. Random Forest) и градиентный бустинг (от англ. Gradient Boosting) «…данный подход работает для любых функций потерь и является одним из наиболее мощных и универсальных»
, данные методы успешно применяются для прогнозирования временных рядов. Эти методы позволяют учитывать множество признаков, включая лаговые значения, скользящие средние и внешние факторы. Однако они не моделируют временную структуру явным образом и требуют ручного формирования признакового пространства. Методы опорных векторов (SVR) «который строит гиперплоскость в n-мерном пространстве для разделения двух или более классов» , данные методы демонстрируют хорошие результаты на небольших выборках, но плохо масштабируются на многомерные данные с длинной временной историей.Существуют нейросетевые методы — рекуррентные нейронные (RNN) сети специально разработаны для обработки последовательных данных. Они сохраняют скрытое состояние, передающее информацию о предыдущих элементах последовательности. Однако классические RNN страдают от проблемы затухающих или взрывающихся градиентов, которые могут возникать при обучении нейронных сетей особенно глубоких. Сети с краткосрочной памятью (LSTM) решают проблему затухающих градиентов за счет специальной архитектуры ячеек памяти, содержащих входные, выходные и забывающие вентили
. LSTM стали стандартом де-факто для многих задач анализа временных рядов. Управляемые рекуррентные блоки (GRU) представляют собой упрощенную версию LSTM с двумя вентилями вместо трех. GRU требует меньше вычислительных ресурсов и демонстрирует сопоставимую с LSTM эффективность на многих задачах. Могут применяться и сверточные нейронные сети (CNN) для анализа временных рядов. Одномерные свертки позволяют выделять локальные паттерны различной длительности. Комбинации CNN и RNN часто используют для извлечения пространственно-временных рядов. Механизм самовнимания «позволяющий нейронной сети оценивать важность различных частей входной последовательности по отношению друг к другу» , а также этот механизм позволяет модели учитывать зависимости между любыми элементами последовательности независимо от расстояния между ними.Преимущество генеративной модели – вариационные автоэнкодеры (VAE) сочетают в себе идеи автоэнкодеров и вариационного вывода. Кодировщик преобразует входные данные в параметры латентного распределения, а также восстанавливает исходные данные из латентного представления. Регуляризация KL-дивергенцией приближает латентное распределение к стандартному нормальному, что обеспечивает гладкость латентного пространства и обеспечивает возможность генерации новых данных. Условные вариационные автоэнкодеры (CVAE) расширяют архитектуру VAE возможностью дополнительно учитывать условные переменные, например метку региона, которая позволяет отслеживать источники трафика и выявлять географические особенности поведения пользователей выбранного региона. Или сценарные предпосылки развития региона — это возможность изучить условия, факторы, основные параметры, которые лежат в основе разработки стратегий и составления сценарного прогноза. Что, в свою очередь, позволяет генерировать специфичные данные для заданных условий.
Есть еще один вид генеративной модели — это генеративно-состязательные сети Generative Adversarial Networks (GAN) алгоритм машинного обучения без учителя, которая состоит из двух моделей генератора, создающего синтетические данные и дискриминатора, отличающего реальные данные от сгенерированных. Состязательное обучение в основном приводит к тому, что генератор начинает производить данные, неотличимые от реальных.
Генеративно-состязательная сеть Wasserstein GAN (WGAN) дополняет классическую генеративно-состязательную сеть GAN с использованием расстояния Вассерштейна вместо дивергенции Кульбака-Лейблера или Дженсена-Шеннона, что обеспечивает более устойчивое обучение и устраняет проблему коллапса режимов. Но генеративно-состязательная сеть WGAN требует соблюдения условия Липшица для дискриминатора, это математическое свойство, которое характеризует «неровность» функции и ограничивает скорость изменения ее выходных значений относительно входных данных. Соблюдение данного условия играет важную роль в оптимизации алгоритмов машинного обучения и обычно реализуется клиппированием весов или градиентным штрафом.
TimeVAE еще одна генеративно-состязательная сеть со специализированной архитектурой для работы с временными рядами, в которой кодировщик и декодировщик построены на рекуррентных слоях. Эта модель особенно эффективна для импутации пропусков и восстановления недостающих наблюдений.
Предлагаемая гибридно-генеративная модель в исследовании формирует архитектуру гибридной модели CVAE-WGAN-TimeVAE, которая объединяет три компонента, каждый из которых отвечает за определенное направление анализа временных рядов
.Структура данной модели состоит из трех компонентов: первый компонент, TimeVAE для импутации пропусков
, данный модуль предназначен для восстановления недостающих значений во входных временных рядах. Второй компонент — CVAE — предназначен для формирования латентного пространства. После заполнения пропусков многомерный временной ряд подается на вход CVAE, кодирует его в компактное латентное пространство. Условная компонента, например, возможный тип сценария развития региона, позволяет учитывать дополнительную информацию. Третий компонент — WGAN — для повышения реалистичности, генератор WGAN обучается производить последовательности, неотличимые от реальных, что достаточно сильно повышает качество синтезируемых данных. Модель WGAN оценивает расстояние Вассерштейна между распределениями реальных и сгенерированных данных (см. рис. 1).
Структура гибридно-генеративной модели CVAE-WGAN-TimeVAE
Скрытое состояние кодировщика после обработки всей последовательности преобразуется в параметры латентного распределения — среднее и логарифм дисперсии. Из этого распределения выбирается латентный вектор, который подается на вход декодировщика. Далее декодировщик, также построенный на рекуррентных слоях, восстанавливает полную последовательность данных. Функция потерь включает два слагаемых: ошибку реконструкции для наблюдаемых значений, обычно это среднеквадратичная ошибка, и KL-дивергенцию между латентным распределением и стандартным нормальным. После обучения вариационных автоэнкодеров TimeVAE используется для заполнения пропусков во всех рядах. Для этого через данную модель пропускаются последовательности с пропусками, и восстановленные значения заменяют пропущенные (см. рис. 2).
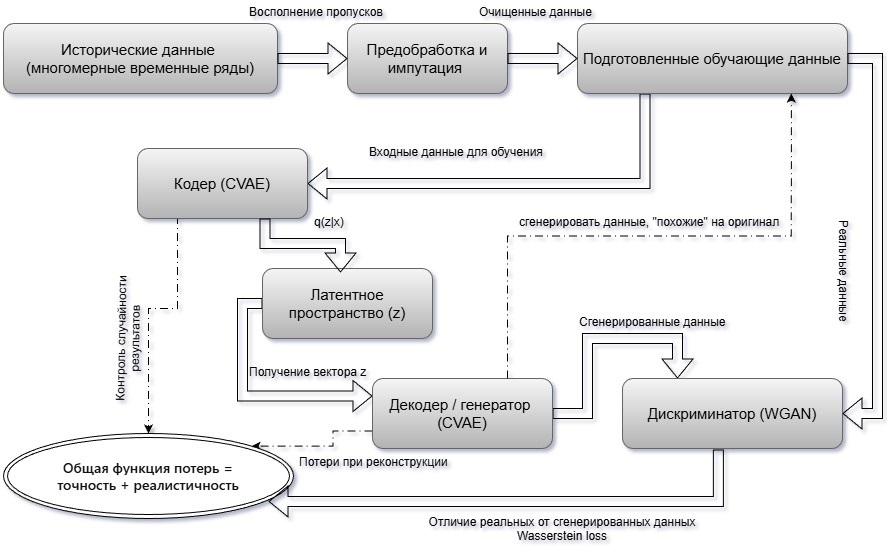
Рисунок 2 - Архитектура гибридной модели CVAE-WGAN-TimeVAE
В рамках анализа социально-экономических показателей условная переменная может включать:
– идентификатор региона (дискретная переменная);
– временной ряд (год, квартал, месяц);
– сценарные предпосылки (оптимистический, базовый, пессимистический сценарий);
– макроэкономические условия (значения внешних факторов).
Кодировщик CVAE принимает данные многомерного временного ряда и условную переменную, формируя параметры распределения латентного пространства. Декодировщик получает латентный вектор и ту же условную переменную, восстанавливая исходный ряд. Данная архитектура модели позволяет после обучения генерировать реалистичные временные ряды для любых комбинаций условных переменных, даже если такие комбинации не встречались в обучающей выборке.
Применение в архитектуре модели WGAN необходимо для повышения качества генерации, вариационные автоэнкодеры имеют тенденцию генерировать «размытые» или сглаженные данные. Это в основном связано с тем, что оптимизация по KL-дивергенции и ошибке реконструкции приводит к усреднению возможных вариантов. Поэтому WGAN решает эту проблему за счет состязательного обучения. В рамках гибридной модели генератор WGAN инициализируется декодировщиком CVAE, далее генератор и критик обучаются совместно.
Генератор получает на вход латентный вектор, который отбирается из стандартного нормального распределения, и условную переменную, генерируя временной ряд. Критик оценивает сгенерированный ряд и вычисляет расстояние Вассерштейна до распределения реальных данных. Функция потерь WGAN имеет следующий вид. Для критика — максимизация разности между оценками реальных и сгенерированных данных, а для генератора — минимизация оценки критика на сгенерированных данных, то есть стремление «обмануть» критика. Выделены основные этапы обучения модели (см. табл. 1).
Таблица 1 - Процедура обучения модели CVAE-WGAN на основе TimeVAE
Этап 1: Предобработка данных | 1. Приведение всех показателей к единой временной периодичности. 2. Логарифмирование показателей, демонстрирующих экспоненциальный рост. 3. Стандартизация для обеспечения сопоставимости масштабов разных показателей. 4. Создание маски пропусков — бинарного тензора, указывающего, какие значения наблюдения, а какие отсутствуют. |
Этап 2: Обучение TimeVAE | 1. Обучается на данных с пропусками. 2. Часть наблюдаемых значений искусственно скрывается и используется как валидационная выборка 3. Обучение проводится с использованием оптимизатора Adam с адаптивной скоростью обучения. 4. Обучение прекращается, когда ошибка на валидационной выборке перестает снижаться в течение определенного числа эпох. |
Этап 3: Обучение CVAE | 1. Обучается на полных данных. 2. Условная переменная формируется на основе атрибутов каждого временного ряда. 3. Оптимизация проводится по двум компонентам функции потерь: ошибке реконструкции (MAE или MSE для восстановленных значений) и KL-дивергенции. 4. Гиперпараметры модели подбираются с использованием байесовской оптимизации. |
Этап 4: Совместное обучение WGAN | 1. Обучение критика (обычно 5 итераций на одну итерацию генератора) для максимизации расстояния Вассерштейна. 2. Обучение генератора для минимизации оценки критика. Градиентный штраф WGAN-GP применяется для соблюдения условия Липшица, что позволяет избежать клиппирования весов, которое может приводить к неоптимальным решениям. |
Для оценки качества модели используются следующие метрики:
1) средняя абсолютная ошибка MAE;
2) среднеквадратичная ошибка RMSE, которая осуществляет выявление особенно критичных ошибок;
3) средняя абсолютная процентная ошибка MAPE, которая измеряет среднюю абсолютную процентную ошибку между прогнозируемыми и реальными значениями (MAPE удобна для интерпретации в относительных единицах);
4) расстояние Вассерштейна между распределениями реальных и сгенерированных данных, которое оценивает реалистичность генерации;
5) визуальный анализ, позволяющий проводить наглядное сравнение графиков реальных и сгенерированных рядов.
На основе предоставленных данных и обученной на них генеративной модели появляется возможность ее применения для анализа социально-экономических показателей и формирования долгосрочного прогноза развития региона в условиях дефицита данных.
Для возможной иллюстрации работы модели CVAE-WGAN-TimeVAE был подобран набор социально-экономических показателей регионов. Входной многомерный временной ряд (датасет) для каждого региона включает следующие показатели:
– валовый региональный продукт (ВРП);
– инвестиции в основной капитал;
– среднегодовая численность занятых;
– среднемесячная номинальная заработная плата;
– индекс промышленного производства;
– оборот розничной торговли;
– объем платных услуг населению;
– уровень безработицы
– сальдированный финансовый результат организации и др.
Период наблюдений заключен в рамках с 2010 по 2024 годы с годовой или квартальной периодичностью. Доля пропусков в исходных данных варьируется от 5% до 40% в зависимости от показателя и выбранного для анализа региона с дефицитом данных.
Последовательность решения задачи по импутации данных состоит из нескольких последовательных шагов. На начальном этапе TimeVAE восстанавливает пропущенные значения, после этого осуществляет проверку качества импутации и в заключении демонстрирует, что для показателей с низкой волатильностью, например, таких как: численность населения или уровень безработицы, ошибка восстановления не превышает 3–5%, однако для высоко волатильных показателей, таких как: инвестиции, финансовые результаты — ошибка восстановления может достигать 10–15%, что объясняется большей неопределенностью. Основным важным преимуществом TimeVAE перед традиционными методами (линейная интерполяция, заполнение средним или предыдущим значением) является учет многомерных связей. Например, при восстановлении пропущенного значения показателя ВРП модель учитывает динамику инвестиций и занятости, что позволяет реалистично оценить полученную информацию.
Обученная гибридная модель производит генерацию синтетических временных рядов с заданными свойствами. Путем изменения условной переменной она гернерирует сценарии для разных регионов или разных макроэкономических условий.
Визуальный анализ показывает, что сгенерированные ряды визуально неотличимы от реальных, так как они демонстрируют схожие тренды, сезонные колебания и волатильность. Количественная оценка с использованием расстояния Вассерштейна подтверждает, что распределение сгенерированных данных близко к распределению реальных значений.
Для прогнозирования на горизонт в несколько лет используется итеративный подход. Модель генерирует следующий временной шаг на основе исторических данных, затем сгенерированное значение добавляется к истории, и процесс повторяется. Применяемый альтернативный подход, то есть прямая генерация всей прогнозной траектории целиком из латентного пространства. Этот метод менее чувствителен к накоплению ошибок, но требует, чтобы модель обучалась генерировать последовательности фиксированной длины. В сравнении с базовыми методами: ARIMA, экспоненциальное сглаживание, LSTM, показывает, что гибридная модель демонстрирует более высокую точность на горизонте до 2-3 лет и сопоставимую точность на более длинных горизонтах.
Предложенная гибридная архитектура отличается рядом достоинств по сравнению с существующими подходами. Во-первых, модель способна эффективно работать с неполными данными благодаря встроенному механизму импутации TimeVAE. Это критически важно для регионалной статистики, где пропуски данных являются скорее правилом, чем исключением. Во-вторых, учет многомерных связей между показателями обеспечивает согласованность прогнозов. Например, модель не сгенерирует сценарий, в котором ВРП растет, а инвестиции снижаются, если такая комбинация не наблюдалась в исторических данных. В-третьих, условная компонента CVAE позволяет адаптировать генерацию к специфике конкретного региона или сценария без переобучения всей модели. В-четвертых, состязательное обучение WGAN повышает реалистичность сгенерированных последовательностей, устраняя проблему «размытости», которая характерна для чистых VAE. В-пятых, модель формирует вероятностные прогнозы, а не только точечные оценки, что важно для анализа рисков и принятия решений в условиях неопределенности.
Несмотря на ценные качества данной модели, она обладает рядом ограничений, которые следует учитывать при практическом применении. Обучение гибридной модели требует значительных вычислительных ресурсов, особенно при большом количестве показателей и длинных временных рядах. Использование Graphics Processing Unit (GPU) ускоряет обучение, но оно не всегда доступно в исследовательских проектах, а также модель чувствительна к гиперпараметрам. Качество работы модели сильно зависит от латентного пространства, количества слоев и скорости обучения. В этом помогает Баесовская оптимизация, но она не полностью решает данную проблему. Еще одно ограничение, которое следует учитывать, заключается в том, что модель требует достаточно большого объема данных для обучения. При малом количестве наблюдений (менее 100–200 временных шагов) качество генерации может быть низким.
Основные направления дальнейшего развития гибридной генеративной модели CVAE-WGAN-TimeVAE включают в себя интеграцию механизмов внимания, как ключевого элемента архитектуры трансформеров, которые позволяют модели анализировать данные параллельно, для учета долгосрочных зависимостей. Следующим направлением является разработка методов интерпретации латентного пространства, а также расширение возможностей модели для работы с пространственными данными, например, с вероятным учетом соседства регионов. Заключительный вектор развития состоит в создании пользовательского интерфейса для интерактивного сценарного моделирования.
2. Заключение
В статье представлена гибридная генеративная модель CVAE-WGAN на основе TimeVAE для анализа многомерных временных рядов социально-экономических показателей. Предложенная архитектура объединяет достоинства трех современных нейросетевых подходов: импутацию пропусков TimeVAE, условную генерацию CVAE и повышение реалистичности через состязательное обучение WGAN.
Описаны структуры модели, процедура обучения, методы валидации и оценки качества. Показано, что модель эффективно решает ри взаимосвязанные задачи — это восстановление пропущенных значений, генерацию синтетических временных рядов и прогнозирование будущих траекторий.
Основные преимущества модели — способность работать с неполными данными, учет многомерных связей, возможность условной генерации и формирование вероятностных прогнозов. Ограничения связаны с вычислительной сложностью, чувствительностью к гиперпараметрам и недостаточной интерпретируемостью.
Предложенная модель может найти применение в региональной экономической аналитике, стратегическом планировании, сценарном моделировании и инвестиционном анализе. Дальнейшие исследования будут направлены на повышение интерпретируемости, интеграцию механизмов внимания и адаптацию модели для работы с пространственно-временными данными.