Architectural substantiation of an end-to-end model for face detection and recognition in low-light conditions while preserving identity
Architectural substantiation of an end-to-end model for face detection and recognition in low-light conditions while preserving identity

Abstract
The work presents an architectural solution for end-to-end face detection and recognition that operates in low-light conditions. Low light levels cause a critical deterioration in the quality of the input data: increased noise, reduced contrast and loss of textural information, which negatively affects the accuracy of object localisation and the stability of the extracted biometric embeddings. To overcome these limitations, we suggest integrating an image enhancement module, a detector and a recogniser into a single computational loop. Unlike traditional cascaded solutions with external pre-processing, this structure ensures coordinated training of all components and targeted optimisation of the feature space relevant for preserving identity information.
The central methodological issue in implementing this approach lies in the incorrect use of unstable embedding from a noisy dark frame as a reference for the identity loss function. The paper analyses two methods for resolving this contradiction. The first involves paired learning using reference images with normal illumination. The second, which does not require bright reference images, is based on a teacher–student distillation mechanism with a momentum teacher, which allows the process of forming biometric representations to be stabilised. Additionally, aspects of keypoint stabilisation, loss gating based on detector confidence, and the balancing of a multi-component objective function are discussed. The proposed architecture provides a methodologically sound foundation for the development of a software suite aimed at achieving high accuracy in person recognition under complex lighting conditions.
1. Введение
Условия недостаточной освещённости ухудшают качество изображения не только визуально, но и на уровне признаков, которыми оперируют современные нейросетевые модели. Рост сенсорного шума, нестабильность экспозиции, локальные тени, снижение контраста и потеря высокочастотных деталей приводят к тому, что ключевые ориентиры лица определяются менее точно, а эмбеддинги, используемые для идентификации, становятся менее устойчивыми , . Поэтому даже сильные модели детекции и распознавания, показавшие высокое качество на кадрах нормальной освещённости, в тёмных сценах демонстрируют выраженную деградацию точности , .
Традиционная каскадная схема, в которой улучшение изображения предшествует детекции и распознаванию, удобна для инженерной реализации, однако разрывает единую оптимизацию между этапами. Модуль улучшения в таком конвейере ориентируется прежде всего на визуальную выразительность изображения и не контролирует сохранение биометрически значимых деталей, тогда как последующие блоки вынуждены работать с входами из иного распределения, чем то, на котором они изначально обучались , . В результате внешнее улучшение может не только не помочь, но и ухудшить распознавание, если сглаживаются тонкие текстуры, искажается локальная геометрия или изменяется микроконтраст в областях глаз, носа и рта.
В настоящей работе рассматривается сквозная постановка задачи, в которой улучшение изображения, детекция и распознавание объединяются в единый вычислительный граф. Базовая идея состоит в использовании общего энкодера признаков, к которому подключаются детекторные и распознавательные головы, а также механизмы сохранения идентичности, устойчивые к шуму, ошибкам раннего выравнивания и фотометрической деградации. Такой подход позволяет трактовать улучшение не как отдельную предобработку, а как часть общей процедуры формирования биометрически полезного представления .
2. Методы и принципы исследования
Исходное изображение рассматривается как входной тензор
где
Далее
Полученное пирамидальное представление используется совместно в детекторе и распознавателе , . Детектор
Где
На следующем шаге выполняются выравнивание лица по ключевым точкам и извлечение фиксированного окна признаков, что позволяет привести входы распознавателя к согласованному геометрическому виду.
В этом выражении
2.1. Архитектурная постановка identity loss
Если эталонный эмбеддинг вычисляется непосредственно по тёмному входу, возникает логически замкнутый контур, в котором нестабильное представление используется как цель для собственной коррекции. В базовом варианте это можно записать следующим образом:
Здесь y обозначает улучшенное изображение. Ключевая проблема состоит в том, что при сильной деградации
Если доступны парные данные, то есть эталонное изображение нормальной освещённости
Такой режим разрывает замкнутый круг, поскольку эталонный эмбеддинг извлекается из качественного изображения и тем самым задаёт более устойчивую цель для оптимизации .
При отсутствии парных данных предлагается использовать teacher student схему. В этой постановке teacher сеть
Здесь
Поскольку teacher ветвь по определению схемы не получает градиент, остановка градиента в данном случае выступает техническим следствием выбранной организации обучения, а не самостоятельным методом стабилизации .
Если доступны метки идентичности, в схему дополнительно включается ArcFace потеря:
Указанный терм усиливает разделимость классов в пространстве эмбеддингов . Если же метки идентичности отсутствуют, ArcFace потеря не используется, а сохранение идентичности обеспечивается исключительно через teacher student механизм и согласование представлений.
2.2. Стабилизация выравнивания и landmarks
На ранних этапах совместного обучения детектор и распознаватель ведут себя нестабильно, поскольку ошибки в landmarks немедленно отражаются на alignment и далее ухудшают эмбеддинги. Поэтому на этапе прогрева целесообразно использовать предобученный детектор
Такое ограничение сдерживает отклонение текущих landmarks от стабильной опорной траектории и позволяет подключать identity потери только после того, как выравнивание становится достаточно надёжным для передачи корректного сигнала в распознаватель , .
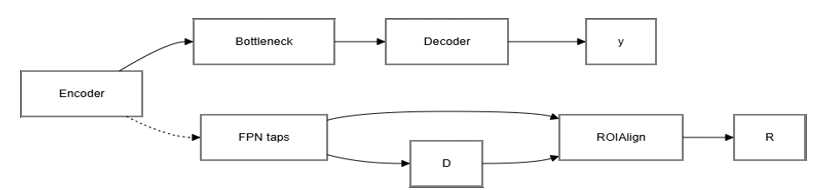
Схема обучения
3. Режимы данных и функция потерь
Под парным режимом понимается наличие пары «тёмное изображение, эталонное изображение» для одной сцены или одного лица. Под непарным режимом понимается отсутствие такого фотометрического эталона. Это различие не совпадает автоматически с наличием identity меток: метки личности могут присутствовать как в парном, так и в непарном сценарии. Такое разделение принципиально важно для корректного выбора супервизии.
Общая функция потерь модели записывается следующим выражением:
где,
В парном режиме модуль улучшения естественно задаётся как сумма пиксельной, структурной и признаковой составляющих, что позволяет одновременно контролировать фотометрическое соответствие и сохранение признаков, значимых для распознавания:
Коэффициенты α и β регулируют вклад структурной и признаковой частей. В непарном режиме вместо прямого эталона используются zero reference регуляризаторы, ориентированные на самосогласованность и корректное поведение улучшателя без явного фотометрического образца:
Аналогично adversarial часть включается только в том случае, если выбран GAN режим:
Таким образом, непарность относится только к отсутствию фотометрического эталона и не отменяет возможность supervision для распознавания , . Это позволяет разделять источник данных для улучшения и источник сигналов для идентификации без логических противоречий.
4. Балансировка многокомпонентной оптимизации
Поскольку отдельные функции потерь могут формировать разнонаправленные градиенты, статический подбор коэффициентов не всегда приводит к устойчивому обучению. Один из практических вариантов заключается в использовании обучаемых весов, связанных с гомоскедастической неопределённостью:
В этом выражении
Здесь
Результаты. Результатом проведённого анализа является непротиворечивая архитектурная схема, в которой улучшение, детекция и распознавание связаны через общий энкодер и согласованные функции потерь. По сравнению с каскадным конвейером предложенная постановка допускает прямое влияние задач детекции и распознавания на формирование общего пространства признаков. Это означает, что модуль улучшения оптимизируется не только по фотометрическим критериям, но и с учётом требований к локализации и устойчивости эмбеддингов
.Существенным результатом является устранение логической проблемы замкнутого круга identity loss. Показано, что использование эмбеддинга тёмного входа в качестве эталона методологически ненадёжно, тогда как парный эталон и teacher student схема формируют более устойчивые и интерпретируемые цели для оптимизации
, . Дополнительно обосновано, что ранняя стабилизация landmarks и staged обучение представляют собой не вспомогательные эвристики, а необходимый элемент архитектурной логики: без них распознаватель получает шумные и геометрически нестабильные входы , .Отдельный результат связан с вычислительной организацией системы. Если головы детекции и распознавания подключены непосредственно к общему энкодеру, декодер улучшения может быть отключён на этапе инференса без потери основной функциональности, при условии, что обучение проводилось в том же режиме и градиенты от задач детекции и распознавания действительно влияли на общий энкодер. Это делает предложенную архитектуру применимой не только для офлайн обработки, но и для сценариев с ограниченным вычислительным бюджетом.
Дополнительным результатом является повышение отказоустойчивости за счёт гейтинга по уверенности детектора. Пусть
Соответствующий гейтированный identity loss принимает вид:
Аналогичным образом определяется и гейтированная ArcFace потеря:
Такая форма ослабляет влияние распознавания на ранних и слабодетектируемых примерах, не отключая распознаватель полностью и не разрушая совместную оптимизацию.
Предложенная схема показывает, что ключевые инженерные риски в задачах low light распознавания лиц определяются не столько выбором конкретного backbone, сколько согласованием источников супервизии и моментом включения распознавательных термов. Если identity loss привязан к нестабильному эмбеддингу тёмного входа, система получает ошибочную цель вне зависимости от мощности генератора. Напротив, при использовании согласованных признаков общего энкодера и при подключении identity термов только после стабилизации landmarks архитектура становится существенно более устойчивой как с методологической, так и с вычислительной точки зрения.
Не менее важна и вычислительная организация модели. Shared encoder с прямыми подключениями к головам детекции и распознавания уменьшает избыточную стоимость обработки, а возможность отключения декодера на инференсе делает схему пригодной для практических систем, где критичны время отклика и объём памяти. Дополнительный гейтинг распознавательных потерь по уверенности детектора естественным образом учитывает качество наблюдения и снижает риск разрушительных градиентов на ранних стадиях обучения.
Дополнительное методологическое значение предложенной архитектуры состоит в том, что она позволяет явно развести фотометрическую и биометрическую составляющие задачи, не разрывая их на уровне обучения. В классических каскадах между этими составляющими обычно отсутствует обратная связь: модуль улучшения стремится восстановить визуальную разборчивость кадра, а распознаватель лишь пассивно принимает полученный результат. В рассматриваемой схеме, напротив, улучшение подчиняется требованиям последующих задач и тем самым оптимизируется в контексте конечной цели. Это особенно важно для сцен с неравномерным освещением, локальными пересветами, тенями и сенсорным шумом, где визуально «приятное» восстановление не всегда совпадает с сохранением идентичностно значимых микропризнаков. Следовательно, даже без проведения экспериментальной части уже на уровне архитектурного анализа можно утверждать, что согласование источников супервизии и последовательности включения потерь является критическим условием устойчивой работы системы.
Практическая перспектива дальнейшей верификации такой модели связана с поэтапной экспериментальной проверкой на наборах данных, содержащих как контролируемые, так и естественные низкоосвещённые сцены. На первом этапе необходимо подтвердить устойчивость детекции и корректность landmarks после прогрева и регуляризации, на втором этапе — оценить влияние парного и непарного режимов на сохранение идентичности, а на третьем этапе — сопоставить качество распознавания при включённом и отключённом декодере улучшения на инференсе. Подобная стратегия не меняет предложенную архитектурную логику, но позволяет последовательно проверить те допущения, которые были сформулированы в данной статье на теоретическом уровне. Тем самым предложенная схема выступает не только как концептуальная модель, но и как практически пригодный каркас для построения последующих экспериментальных протоколов.
5. Заключение
Предложенная сквозная архитектура объединяет улучшение изображения, детекцию и распознавание лиц в единый вычислительный контур и устраняет ключевые противоречия, характерные для каскадных схем. Основной вклад работы состоит в том, что улучшение рассматривается не как внешняя предобработка, а как часть процесса формирования биометрически полезного представления. Благодаря этому фотометрическая коррекция связывается с требованиями к точности детекции и к устойчивости эмбеддингов.
Показано, что наиболее критичным риском является использование нестабильного тёмного эмбеддинга как эталона для identity loss. Для устранения этого риска предложены два согласованных режима: первый основан на парном эталонном изображении, второй использует teacher student дистилляцию с momentum teacher. Кроме того, обоснована необходимость ранней стабилизации landmarks, адаптивного взвешивания многокомпонентной функции потерь и гейтинга распознавательных термов по уверенности детектора.
С практической точки зрения наибольший интерес представляет вариант с общим энкодером и прямыми подключениями голов детекции и распознавания, поскольку он позволяет отключать декодер улучшения на этапе инференса и тем самым снижать вычислительную нагрузку. Следовательно, сформулированная архитектурная схема может служить основой для дальнейшей программной реализации, экспериментальной верификации и прикладного внедрения в задачах распознавания лиц при низкой освещённости.