DEVELOPMENT OF A HYBRID RECOMMENDATION SYSTEM FOR AN ONLINE STORE
DEVELOPMENT OF A HYBRID RECOMMENDATION SYSTEM FOR AN ONLINE STORE

Abstract
In the highly competitive world of e-commerce, online retailers face the challenge of providing personalised search results across tens of thousands of products. Traditional approaches, such as sorting by popularity, fail to take individual preferences into account and often result in the promotion of only cheap accessories, rather than driving sales of high-end technology. A key limitation of collaborative filtering is the cold-start problem, which hinders the promotion of new products with no interaction history.
This work proposes a hybrid recommendation system that combines collaborative filtering with product content features. A full development cycle was carried out: from the generation of a synthetic dataset comprising 2 million events to the deployment of a REST API service. A comparative analysis showed that the LightFM hybrid model with the WARP loss function significantly outperforms the classic ALS algorithm. In offline experiments, the Precision@10 metric increased 5.5-fold (from 0.029 to 0.161), and Recall@10 increased 21-fold (from 0.021 to 0.443). A/B testing simulations confirmed the business impact: conversion to purchase increased by 15.6% (from 3.2% to 3.7%). The results demonstrate the effectiveness of the proposed approach for solving the cold start problem and improving the relevance of recommendations.
1. Введение
Современный рынок электронной коммерции, и в особенности сегмент интернет-магазинов электроники, характеризуется экспоненциальным ростом номенклатуры товаров. Пользователи сталкиваются с информационной перегрузкой, когда выбор подходящего смартфона, ноутбука или комплектующей среди десятков тысяч позиций становится сложной задачей. Стандартные навигационные инструменты, такие как фильтры по брендам или сортировка по цене, не способны решить задачу персонализации, так как демонстрируют всем пользователям одинаковую выборку. Это приводит к доминированию в выдаче дешевых аксессуаров, снижению средней маржинальности сделок и неспособности эффективно продвигать флагманские устройства , .
Для преодоления этих ограничений активно применяются рекомендательные системы. Классические подходы, такие как коллаборативная фильтрация (Collaborative Filtering, CF), анализируют исторические взаимодействия пользователей и товаров, выявляя скрытые паттерны потребления , . Алгоритмы матричной факторизации, например, Alternating Least Squares (ALS), доказали свою эффективность в обработке неявных сигналов (просмотры, клики), однако обладают фундаментальным недостатком — неспособностью обрабатывать новые объекты (проблема холодного старта). В сфере электроники, где выход новых моделей видеокарт или процессоров происходит регулярно, отсутствие возможности рекомендовать новинки без истории продаж критически сказывается на обороте магазина , .
Альтернативой выступают контентные модели, анализирующие метаданные (описания, характеристики), но они страдают от избыточной специализации и не улавливают динамику совместного покупательского поведения. Решением, объединяющим преимущества обоих миров, являются гибридные рекомендательные системы , . Библиотека LightFM представляет одну из наиболее удачных реализаций такого подхода, позволяя интегрировать в единую матричную факторизацию как сигналы взаимодействий, так и векторы признаков пользователей и товаров . Отечественные исследования также подтверждают перспективность гибридных подходов, однако отмечают, что в последние годы нейросетевые модели (например, SASRec) начинают составлять им серьезную конкуренцию . Проблема быстрого обновления каталога и связанного с ней холодного старта особенно актуальна для медиа и электронной коммерции, где жизненный цикл товара невелик .
В данной работе предлагается применение гибридной модели на основе LightFM, использующей категориальные и ценовые признаки товаров, и ALS для построения рекомендательной системы для интернет-магазина электроники. Для оценки потенциального бизнес-эффекта используются методы симуляции A/B-тестирования.
2. Методы и принципы исследования
Исследование основано на контролируемом вычислительном эксперименте с использованием синтетического набора данных. Выбор синтетических данных обусловлен требованиями воспроизводимости эксперимента, строгого контроля над распределением классов и отсутствием правовых ограничений, связанных с конфиденциальностью реальных пользователей. Для обеспечения детерминированности генератора использовался фиксированный seed=42.
Для моделирования рекомендательной системы создан синтетический датасет, имитирующий работу интернет-магазина в течение 180 дней. Объем данных включает 100 000 пользователей, 10 000 товаров и 2 000 000 событий. Товары распределены по 7 категориям электроники. Данные о взаимодействиях содержат три типа событий: просмотр, добавление в корзину и покупка. В соответствии с методикой работы рекомендательной с имплицитной обратной связью , была применена стратегия взвешивания. Просмотру присвоен вес 1, добавлению в корзину — вес 2, покупке — вес 3. Такой подход позволяет модели фокусироваться на более сильных сигналах целевого действия.
Данные для коллаборативной модели ALS были преобразованы в формат разреженной матрицы (Compressed Sparse Row, CSR), которая содержит ID пользователей, номера товаров и накопленные веса событий. Разделение на обучающую и тестовую выборки проводилось по временному принципу (первые 80% событий — обучение, последние 20% — тестирование), что соответствует реалистичному сценарию прогнозирования будущих взаимодействий.
Гибридная модель, в состав которой входит LightFM и ALS, помимо матрицы взаимодействий содержит вектор контентных признаков товаров (item features). Он подготовлен на основе признакового описания товаров и включает: категорию товара (7 уникальных значений, преобразованных one-hot кодированием), бренд (one-hot кодирование) и цену (нормированную в диапазон [0, 1] методом MinMax). Контентные признаки пользователей не использовались.
В качестве базовой линии (baseline) был выбран алгоритм ALS из библиотеки Implicit, реализующий чисто коллаборативную фильтрацию , . Экспериментальной моделью выступил LightFM с функцией потерь Weighted Approximate-Rank Pairwise (WARP), оптимизированной под задачи ранжирования (рекомендация Top-K) , , , . Выбор WARP обоснован тем, что данный функционал потерь напрямую оптимизирует порядок элементов в ранжированном списке, штрафуя модель за неправильное попарное упорядочивание . Обучение моделей проводилось на CPU-инфраструктуре с подбором гиперпараметров (learning rate, количество факторов, коэффициенты регуляризации) по временной кросс-валидации.
3. Архитектура рекомендательной системы
Архитектура рекомендательной системы спроектирована в соответствии с методологией C4, предполагающей последовательную детализацию от общего контекста к внутренним компонентам. Ниже представлены диаграммы уровней C1, C2 и C3.
Уровень C1: контекст системы. Контекстная диаграмма (рис. 1) представляет разработанную «Гибридную рекомендательную систему» (далее РС) как «черный ящик», определяя ее границы и внешние связи. Система функционирует как автономный программный модуль и взаимодействует с тремя внешними сущностями.
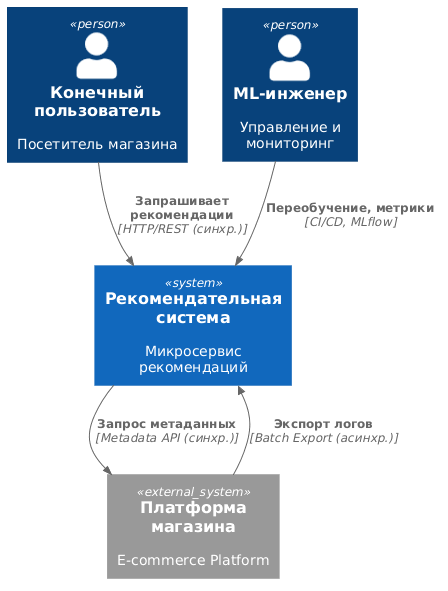
Диаграмма контекста
C1
Вторая внешняя сущность — платформа интернет-магазина (E-commerce Platform), которая является внешней программной системой. Она предоставляет данные по двум независимым каналам. Первый канал (Batch History Export) обеспечивает асинхронную периодическую выгрузку логов пользовательских взаимодействий (просмотры, добавления в корзину, покупки) в формате CSV в общее файловое хранилище. Второй канал (Product Metadata API) представляет собой синхронный интерфейс, через который рекомендательная система по своей инициативе запрашивает метаданные товара (категория, бренд, цена) по его идентификатору. Этот канал критически важен для построения контентных признаков и решения проблемы холодного старта.
Третья внешняя сущность (ML-инженер или администратор) управляет жизненным циклом модели: асинхронно инициирует переобучение через CI/CD-пайплайн, анализирует метрики качества (Precision@k, Recall@k) в дашборде MLflow и при необходимости корректирует гиперпараметры в конфигурационном файле.
Такое разграничение фиксирует зоны ответственности. Рекомендательная система отвечает только за генерацию ранжированных списков товаров, в то время как бизнес-логика (фильтрация товаров в наличии, итоговое оформление витрины) остается на стороне платформы интернет-магазина.
Уровень C2: контейнеры системы. Внутренняя структура РС, представленная на диаграмме контейнеров (рис. 2), декомпозируется на четыре функциональных блока, каждый из которых развертывается в собственном Docker-контейнере.
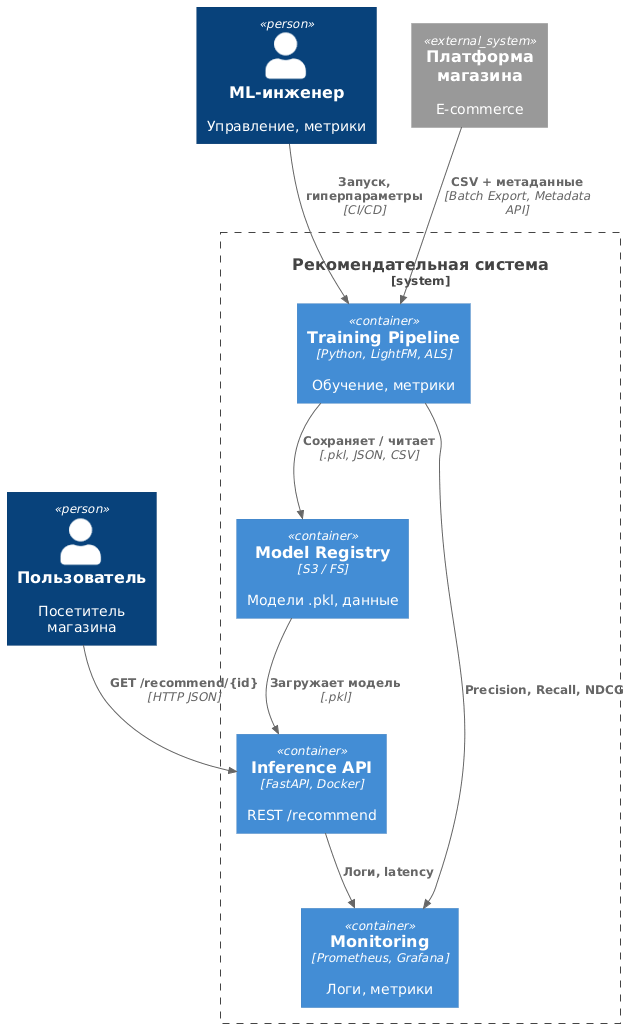
Диаграмма контейнеров
C2
Второй контейнер (Online Inference API — сервис предсказаний) является высокопроизводительным контейнером на базе асинхронного фреймворка FastAPI. При запуске он загружает последнюю стабильную версию модели из Model Registry. Сервис предоставляет REST API (эндпоинт GET /recommend/{user_id}), принимает запросы от фронтенда интернет-магазина и возвращает ранжированный JSON-список идентификаторов товаров. Для обеспечения холодного старта на этапе инференса контейнер обращается к Product Metadata API платформы, получая признаки новых товаров, отсутствовавших на момент обучения модели. Целевое время отклика сервиса составляет менее 50 миллисекунд, что соответствует промышленным стандартам работы в режиме реального времени.
Третий контейнер (Monitoring & Logging — мониторинг) осуществляет централизованный сбор логов запросов и ответов от Online Inference API, а также офлайн-метрик от Batch Training Pipeline. Эти данные используются для валидации качества рекомендаций и последующего A/B-тестирования.
Четвертый контейнер (Model & Data Storage — файловое хранилище) выступает связующим звеном архитектуры, обеспечивая надежное хранение CSV-файлов с событиями, CSR-матриц, сериализованных моделей и метаданных. Платформа интернет-магазина выгружает в него логи взаимодействий по каналу Batch History Export.
Уровень C3: компоненты контейнера Batch Training Pipeline. Для детального понимания внутренней логики обучения представлена диаграмма компонентов контейнера Batch Training Pipeline на рисунке 3.
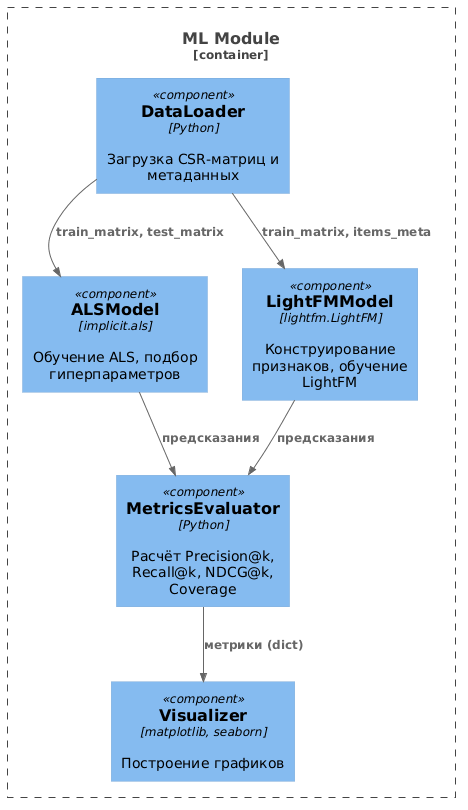
Диаграмма компонентов контейнера Batch Training Pipeline
C3
4. Результаты
Сравнительный анализ качества базовой и гибридной моделей проводился по стандартным метрикам релевантности на отложенной временной выборке. Результаты представлены в таблице 1.
Метрики качества базовой и гибридной моделей на тестовой выборке
Метрика | Базовая модель ALS | Гибридная модель LightFM+ ALS | Коэффициент улучшения |
Precision@10 | 0,029 | 0,161 | x5,5 |
Recall@10 | 0,021 | 0,443 | x21,0 |
NDCG@10 | 0,018 | 0,416 | x23,1 |
Из таблицы видно, что точность (Precision@10) гибридной модели превосходит точность базовой модели в 5,5 раз. Значительный рост полноты (Recall@10) с 0,021 до 0,443 свидетельствует об успешном поиске релевантных товаров гибридной моделью, которые базовая модель полностью игнорирует, в частности, новые или редко покупаемые товары из категорий со специфическими характеристиками. Высокое значение NDCG@10 (0,416) подтверждает, что модель не только находит релевантные товары, но и располагает их на верхних строчках рекомендаций, что критически важно для пользовательского восприятия качества системы.
Оценка бизнес-эффекта осуществлялась с помощью проведения симуляции A/B теста на синтетическом трафике.
Контрольная группа (A): рекомендации генерируются базовой моделью ALS. Зафиксирована конверсия в покупку (CR) = 3,2%, показатель кликабельности (CTR) = 8,7%.
Тестовая группа (B): рекомендации гибридной модели LightFM+ALS. Зафиксированы повышенные значения CR = 3,7% и CTR = 8,9%. Для гибридной модели относительный прирост конверсии в покупку составил +15,6%, а прирост CTR +2,6%. Прирост конверсии является статистически и практически значимым для бизнеса, подтверждая гипотезу о том, что более релевантные рекомендации напрямую влияют на готовность пользователя совершить дорогостоящую покупку.
5. Обсуждение
Результаты экспериментов подтверждают выдвинутую гипотезу. Гибридный подход на основе LightFM демонстрирует значительное преимущество над коллаборативной фильтрацией ALS. Такой прирост метрик связан с архитектурными особенностями гибридной модели. Во-первых, LightFM обучает латентные представления для товаров, используя их контентные признаки — бренд, категорию, цену , , . Модель учитывает не только историю взаимодействий, но и характеристики самого товара. ALS такой возможности лишена: она работает только с матрицей взаимодействий. Когда в каталоге появляется новый товар без единого просмотра или покупки, ALS не знает, кому его предложить, и игнорирует новинку. Гибридный LightFM опирается на эмбеддинги бренда и категории , . Проблема холодного старта для новых товаров полностью снимается. Во-вторых, в отличие от взвешенного MSE, который использует ALS на имплицитной обратной связи, WARP решает задачу оптимизации порядка в ранжированном списке. Ей не требуется угадывать точный вес взаимодействия, она напрямую выстраивает Top-K рекомендации. WARP штрафует модель каждый раз, когда неинтересный товар оказывается выше интересного , . Для пользователя критичен именно порядок выдачи, поэтому такой подход даёт существенный прирост по метрикам Precision и NDCG.
В A/B симуляции зафиксирован умеренный прирост CTR (+2.6%) и значительный прирост конверсии (+15.6%). Это объясняется тем, что гибридный LightFM меняет характер рекомендаций. ALS часто предлагает дешёвые популярные аксессуары, на которые пользователи охотно просматривают, но редко покупают. Гибридный LightFM вместо этого показывает более дорогие и соответствующие интересам товары. Их просматривают реже, но когда просматривают, то чаще покупают. Рекомендации становятся не просто просматриваемые, а продаваемые, что увеличивает средний чек.
Полученные результаты согласуются с выводами отечественных исследователей, отмечающих, что гибридные подходы на основе LightFM сохраняют конкурентоспособность на малых и средних наборах данных по сравнению с более сложными нейросетевыми архитектурами . При этом необходимо обозначить ограничения настоящего исследования. Во-первых, использованный синтетический датасет обеспечивает контролируемый и воспроизводимый эксперимент, однако поведение реальных пользователей может содержать непредсказуемые шумы и смещения. Во-вторых, эксперименты ограничены доменом электроники с семью категориями. Сохранится ли эффективность предложенного подхода при масштабировании на более широкую номенклатуру товаров — это вопрос, требующий проверки.
6. Заключение
В заключении следует отметить, что предложенная гибридная модель LightFM, интегрирующая контентные признаки товаров, кратно превосходит классический ALS в задаче рекомендации электроники. Разработанная рекомендательная система успешно решает проблему холодного старта, обеспечивая рост точности (Precision@10) в 5,5 раз и полноты (Recall@10) в 21 раз, что приводит к прогнозируемому росту конверсии в покупку на 15,6%.
Направления дальнейших исследований включают валидацию предложенного подхода на реальных данных, внедрение контентных признаков пользователей, а также сравнение с современными нейросетевыми архитектурами. Особый интерес представляет сопоставление с моделью SASRec, основанной на архитектуре Transformer и механизмах самовнимания (self-attention) , , , а также с графовыми нейронными сетями, показавшими высокую эффективность в промышленных рекомендательных системах .