Training neural networks based on exponential relaxation methods
Training neural networks based on exponential relaxation methods

Abstract
The optimisation of multidimensional non-convex functionals remains one of the main challenges in training deep learning architectures. While first-order stochastic methods (such as SGD and Adam) are widely used to navigate noisy parameter spaces, they inevitably encounter difficulties in the presence of pathological curvature and flat regions characteristic of ill-conditioned problems. This research examines the application of the exponential relaxation (ER) method—a second-order optimisation algorithm originally developed within the theory of stiff dynamical systems. By using a precise Hessian matrix and a continuous exponential relaxation function, the ER method dynamically scales the optimisation steps: it takes large steps along flat valleys and cautious, stabilised steps on steep slopes. The effectiveness of the method is systematically evaluated in comparison with classical approaches on various topologies, including synthetic ravines, medical datasets with strong feature correlation, autoencoders with saddle points, and physical signal deconvolution problems. Empirical results show that the ER method reaches optimal states in significantly fewer iterations, effectively overcoming the ‘jamming’ phenomenon. The paper also analyses the computational limitations of spectral decomposition and outlines ways of scaling up the algorithm using Krylov subspaces (the Lanczos method). The results confirm that the ER method provides unrivalled accuracy for solving complex physical inverse problems and high-precision modelling, where first-order methods fail.
1. Введение
Обучение глубоких нейронных сетей фундаментально сводится к задаче минимизации эмпирического риска в сложных, многомерных и невыпуклых пространствах
. Основная цель — итеративно настраивать вектор параметров (веса и смещения) так, чтобы минимизировать целевую функцию потерь, отражающую расхождение между предсказаниями модели и реальными данными. В последние годы масштабирование нейросетевых архитектур происходило почти исключительно за счет алгоритмов первого порядка. Методы стохастического градиентного спуска (SGD) и его адаптивные модификации (Adam, RMSProp) стали индустриальным стандартом . Их популярность обусловлена низкими вычислительными затратами на одну итерацию, линейно зависящими от числа параметров O(N), и способностью работать с зашумленными градиентами при пакетном обучении.Тем не менее, методы первого порядка обладают серьезным математическим ограничением: они опираются исключительно на локальную информацию о градиенте, оставаясь «слепыми» к кривизне второго порядка ландшафта функции потерь
. Этот недостаток становится критическим, когда траектория оптимизации попадает в области патологической кривизны, известные в теории управления как «овраги» или жесткие топологии . В таких структурах градиент направлен преимущественно поперек оврага, а не вдоль его пологого дна. В результате алгоритмы первого порядка начинают осциллировать (двигаться зигзагом), что вынуждает сильно ограничивать шаг обучения и приводит к резкому падению скорости сходимости , .Адаптивные методы, такие как Adam, пытаются решить эту проблему, независимо масштабируя скорость обучения для каждого параметра на основе скользящих средних градиента. Однако они неявно полагаются на диагональную аппроксимацию матрицы кривизны
. Если оси оврага не совпадают с координатными осями (что часто случается из-за мультиколлинеарности реальных данных), диагональная аппроксимация не справляется. Алгоритм сталкивается с преждевременной остановкой или полной стагнацией — явлением, известным как «заклинивание» , .Для полноценного учета геометрии пространства применяются методы второго порядка, использующие матрицу Гессе. Классический метод Ньютона нормирует кривизну по всем направлениям, умножая градиент на обратную матрицу Гессе . Однако он нестабилен при отрицательной кривизне (в седловых точках) и требует кубических вычислительных затрат O(N3), что делает его прямое применение невозможным для современных сетей с миллионами параметров
.В качестве математически обоснованной альтернативы выступает метод экспоненциальной релаксации (ЭР), корни которого лежат в теории жестких обыкновенных дифференциальных уравнений
. Фундаментальные вычислительные аспекты и базовые алгоритмы для работы с такими труднообусловленными системами были заложены, в частности, в трудах Ю.В. Ракитского, С.М. Устинова и И.Г. Черноруцкого . Метод ЭР обобщает градиентный спуск и метод Ньютона через непрерывную матричную экспоненту, обеспечивая стабильную оптимизацию даже при наличии отрицательной кривизны и экстремальной жесткости .Цель данного исследования — провести строгую оценку эффективности метода экспоненциальной релаксации при обучении нейронных сетей на задачах с выраженной плохой обусловленностью и мультиколлинеарностью. В ходе сравнительного анализа с алгоритмами первого порядка будут определены топологические условия, в которых ЭР демонстрирует наибольшее преимущество, а также рассмотрены перспективы его масштабирования с помощью безгессиановых методов (Hessian-Free)
.2. Методы исследования
2.1. Математическая постановка задачи
Нейронная сеть представляет собой параметризованную функцию
Обучение сводится к итеративному обновлению весов wk+1 на основе градиента
2.2. Геометрия оврагов и плохая обусловленность
Сложность оптимизации напрямую зависит от спектра собственных значений матрицы Гессе G. Число обусловленности κ(G) определяется как отношение максимального по модулю собственного значения к минимальному:
Если κ(G)≫1, задача классифицируется как жесткая (плохо обусловленная)
. Геометрически это выглядит как вытянутый овраг: функция быстро меняется вдоль направлений, соответствующих большим собственным значениям (крутые склоны), и почти не меняется вдоль направлений с малыми собственными значениями (плоское дно) . Стандартные градиентные методы вынуждены делать микроскопические шаги, чтобы избежать расходимости на склонах, из-за чего прогресс вдоль дна практически останавливается .2.3. Метод экспоненциальной релаксации (ЭР)
Чтобы преодолеть ограничения градиентного спуска, метод ЭР использует специальную масштабирующую матрицу, выведенную из дифференциального уравнения наискорейшего спуска – непрерывного аналога градиентных методов, подробно исследованного в литературе по компьютерным методам оптимизации , а также в
. Дискретное правило обновления весов имеет вид:где h > 0 — параметр релаксации (базовый шаг), а H(G,h) — матричная функция релаксации, определяемая интегралом от матричной экспоненты
:Для каждого собственного значения λi матрицы Гессе применяется скалярный множитель:
Эта функция обеспечивает идеальный баланс:
1. При большой кривизне (λi≫0): экспонента стремится к нулю, множитель становится равен 1/λi. Метод работает как алгоритм Ньютона, перепрыгивая на дно оврага без осцилляций.
2. При малой кривизне (λi≈0): множитель стремится к h. Метод работает как градиентный спуск, стабильно продвигаясь по плоскому плато.
3. При отрицательной кривизне (λi<0): в отличие от метода Ньютона, который может привести к расходимости в седловых точках, ЭР естественно ограничивает шаг и помогает алгоритму покинуть седло .
2.4. Вычислительная реализация
В рамках данного исследования ЭР реализован через точное спектральное разложение матрицы Гессе. На каждой итерации матрица G вычисляется численно, затем находятся ее собственные значения Λ="diag" (λi, ... ,λN ) и матрица собственных векторов V. Шаг рассчитывается в повернутом базисе:
Для предотвращения вычислительной неустойчивости (деления на нуль) при |λi|<10-9 множитель принудительно приравнивается к h
.2.5. Дизайн экспериментов
Для тестирования были использованы как классические аналитические функции, так и архитектуры нейронных сетей на реальных данных. Сравнение проводилось с методами SGD и Adam.
1. Аналитические функции: Розенброка (сильно искривленный овраг), Растригина, функция Била, Ступенчатая функция и Плоское плато.
2. Синтетический повернутый овраг: искусственный набор данных, преобразованный с помощью сингулярного разложения (SVD) для получения числа обусловленности 2000 . Цель — проверить способность методов восстанавливать исходные веса при отсутствии шума.
3. Медицинские данные (Breast Cancer): задача классификации с сильно скоррелированными признаками (радиус и периметр, корреляция ≈0,998) .
4. Автоэнкодер (Digits): нейросеть с узким горлышком, специально инициализированная нулевыми весами для принудительного попадания в седловую точку.
5. Восстановление сигнала: физическая задача деконволюции. Матрица размытия делает задачу регрессии экстремально жесткой, имитируя условия томографии .
3. Основные результаты
3.1. Аналитические топологии
На функции Розенброка метод ЭР благодаря матричной экспоненте динамически адаптировал шаг и быстро достиг глобального минимума, двигаясь вдоль искривленного дна. В то же время SGD и Adam продемонстрировали сильное заклинивание, тратя итерации на бесполезные колебания между крутыми стенами (см. рис. 1).
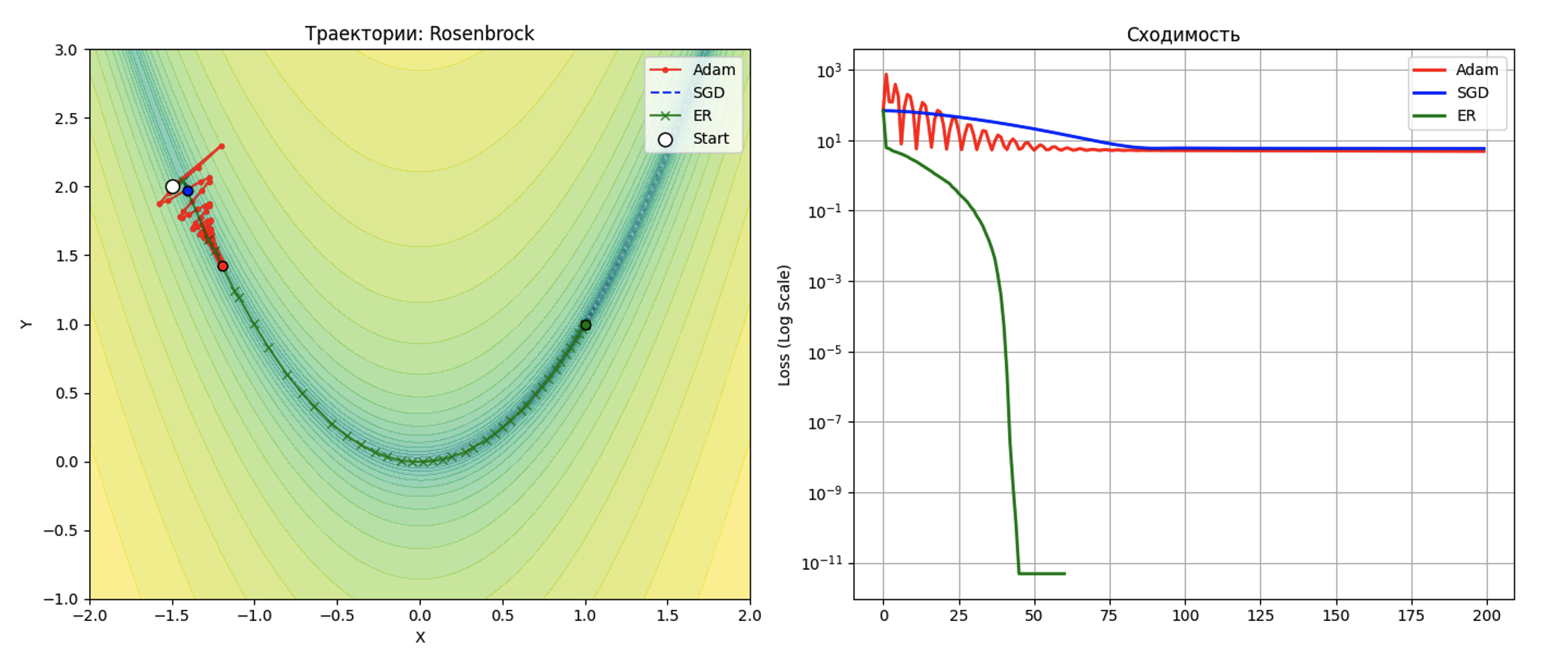
Сходимость методов на функции Розенброка
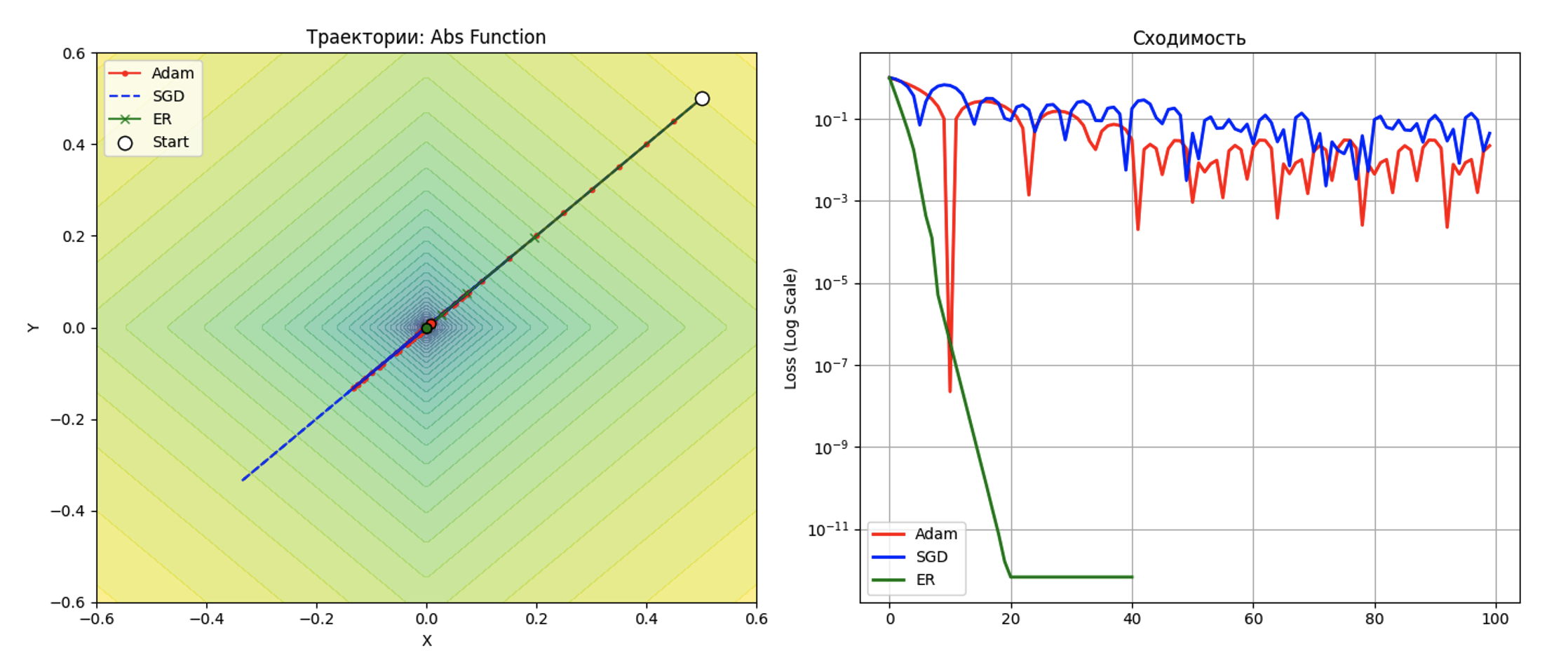
Сходимость методов на ступенчатой функции
3.2. Восстановление параметров (Синтетический овраг)
На задаче с числом обусловленности 2000 тестировалась способность алгоритмов найти точные физические веса (целевые значения W=[2,0, -1,5, 0,5]) (см. табл. 1).
Результаты восстановления параметров в синтетическом овраге
Метод | MSE Loss | Дистанция до оптимума | Итерации | Полученные веса |
SGD | 3,84×10-6 | 5,66×100 | 500 | [-2,089, 2,405, 0,500] |
Adam | 3,84×10-6 | 5,66×100 | 500 | [-2,091, 2,406, 0,500] |
Метод ЭР | 3,40×10-8 | 5,20×10-1 | 100 | [1,624, -1,140, 0,500] |
Хотя функции потерь у SGD и Adam упали до 10-6, алгоритмы остановились далеко от истинных весов (дистанция 5,66). Диагональная аппроксимация Adam не смогла распутать ковариацию признаков. ЭР, используя полную матрицу Гессе, сократил дистанцию до оптимума на порядок всего за 100 итераций.
3.3. Классификация в условиях мультиколлинеарности
В задаче бинарной классификации на наборе данных Breast Cancer исследовалась проблема естественной геометрической жесткости. Набор данных Breast Cancer содержит признаки с корреляцией ≈0,998, что формирует в пространстве потерь вырожденный желоб
. Архитектура сети представляла собой однослойный персептрон с нелинейной функцией активации гиперболического тангенса. На вход модели подавались 30 исходных числовых признаков, а целевое выходное значение масштабировалось в диапазон от -1 до 1. Ключевой особенностью данного эксперимента стал намеренный отказ от стандартизации и предварительной нормализации входных данных: естественный разброс значений различных медицинских показателей варьировался от сотых долей до тысяч. Подобная колоссальная разница в масштабах признаков напрямую транслируется в матрицу кривизны, формируя в пространстве параметров функции потерь глубокие, вырожденные и сильно вытянутые овраги. Для предотвращения мгновенного насыщения функции активации весовые коэффициенты инициализировались исчезающе малыми значениями порядка 10−4. В таких условиях алгоритмы первого порядка сталкиваются с жесточайшим ландшафтом, где градиент направлен преимущественно поперек оврага, а не вдоль его дна. Градиентный спуск требовал критически малого шага обучения и в итоге застрял на значении ошибки 0,6884. Метод Adam пытался адаптироваться и блуждал вдоль линии вырождения, достигнув лишь 0,3545. Метод ЭР, напротив, опираясь на точную информацию второго порядка, корректно вычислил направление околонулевой кривизны и нормализовал спуск, быстро снизив ошибку до 0,0455 (см. табл. 2 и рис. 3). Это доказывает необходимость использования матричной экспоненты при работе с сырыми, избыточными или ненормированными сенсорными данными.Результаты обучения на задаче классификации
Метод | Итоговая ошибка (Loss) |
SGD | 0,6884 |
Adam | 0,3545 |
Метод ЭР | 0,0455 |
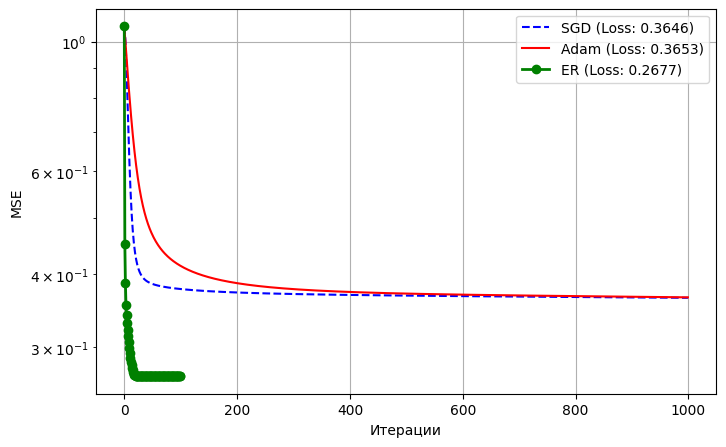
Сходимость методов при обучении на медицинских данных
3.4. Выход из седловых точек
Для исследования поведения алгоритмов оптимизации в условиях архитектурных узких мест (bottlenecks) была смоделирована задача восстановления данных с использованием автоэнкодера с околонулевой инициализацией
. В качестве исходных данных выступал набор изображений рукописных цифр Digits, предварительно сжатый алгоритмом главных компонент (PCA) до 12 базовых признаков. Нейросетевая архитектура состояла из двух слоев и имела жесткое ограничение: 12-мерный входной вектор кодировался скрытым слоем всего из 3 нейронов с активацией гиперболическим тангенсом, после чего сигнал должен был разворачиваться обратно в 12-мерный вектор реконструкции. Механизм возникновения патологической топологии в данном эксперименте обеспечивался специальной околонулевой инициализацией всех весовых матриц (с дисперсией порядка 10−5). Такая конфигурация принудительно помещала стартовую точку траектории обучения точно в седловую точку пространства потерь — локальную плоскую зону, характеризующуюся симметрией и исчезающе малым вектором градиента. Для методов первого порядка попадание в такую зону означает потерю направления движения. SGD не смог накопить достаточный импульс и практически не начал обучение (см. табл. 3). Алгоритм Adam крайне медленно накапливал инерцию через моменты, но с трудом находил оси спуска. Метод ЭР, вычислив и проанализировав спектр матрицы Гессе, безошибочно выявил отрицательные собственные значения, свидетельствующие о направлениях спада. Благодаря своей функции релаксации, алгоритм мгновенно трансформировал это отрицательное значение в мощный выталкивающий множитель, выведя веса в правильном направлении уже на первых итерациях и добившись лучшей итоговой реконструкции сигнала (см. рис. 4).Результаты обучения на задаче автоэнкодера
Метод | Ошибка реконструкции |
SGD | 0,9999 |
Adam | 0,8058 |
Метод ЭР | 0,7506 |
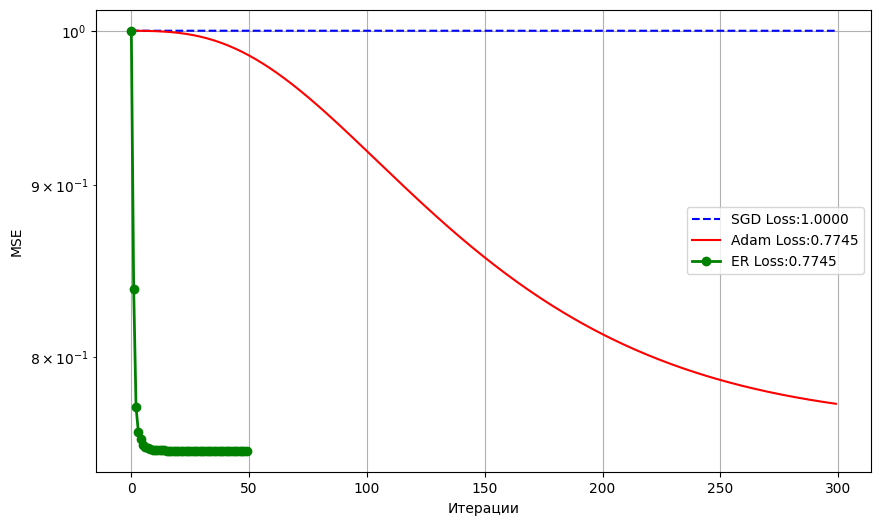
Сходимость на задаче автоэнкодера
3.5. Задача регрессии
В качестве задачи регрессии, имитирующей физические обратные задачи с сильной мультиколлинеарностью, использовался набор данных по гидродинамике яхт (Yacht Hydrodynamics). Модели необходимо было предсказать физическое сопротивление корпуса на основе шести параметров геометрии и числа Фруда. Архитектура представляла собой однослойную сеть, однако перед подачей на вход исходные признаки подвергались полиномиальному расширению второй степени (включая квадраты и попарные произведения), а целевая переменная сопротивления масштабировалась в диапазон гиперболического тангенса. Механизм возникновения экстремальной овражности здесь напрямую вытекал из полиномиального преобразования: перемножение близких по смыслу физических параметров порождает искусственную, но мощнейшую мультиколлинеарность. Матрица ковариации входных сигналов становится практически вырожденной, что приводит к формированию матрицы Гессе с множеством исчезающе малых собственных значений. В результате возникает матрица кривизны, стремящаяся к вырождению (сравнение методов приведено в табл. 4). В условиях такого вырожденного спектра метод Adam даже за несколько сотен итераций достигает лишь умеренной точности, постоянно осциллируя вокруг оптимума. Алгоритм ЭР, динамически обрабатывая малые собственные значения матрицы Гессе через предел функции релаксации, полностью обратил физический оператор всего за несколько десятков шагов, обеспечив падение среднеквадратичной ошибки до машинного нуля (см. рис. 5). Это делает его идеальным инструментом для физически-информированных нейросетей (PINN)
.Сравнение оптимизаторов на задаче регрессии
Метод | Итерации | Итоговая ошибка (Loss) |
SGD | 100 | 9,2026⋅10-3 |
Adam | 100 | 2,0833⋅10-2 |
ER | 30 | 3,6970⋅10-3 |
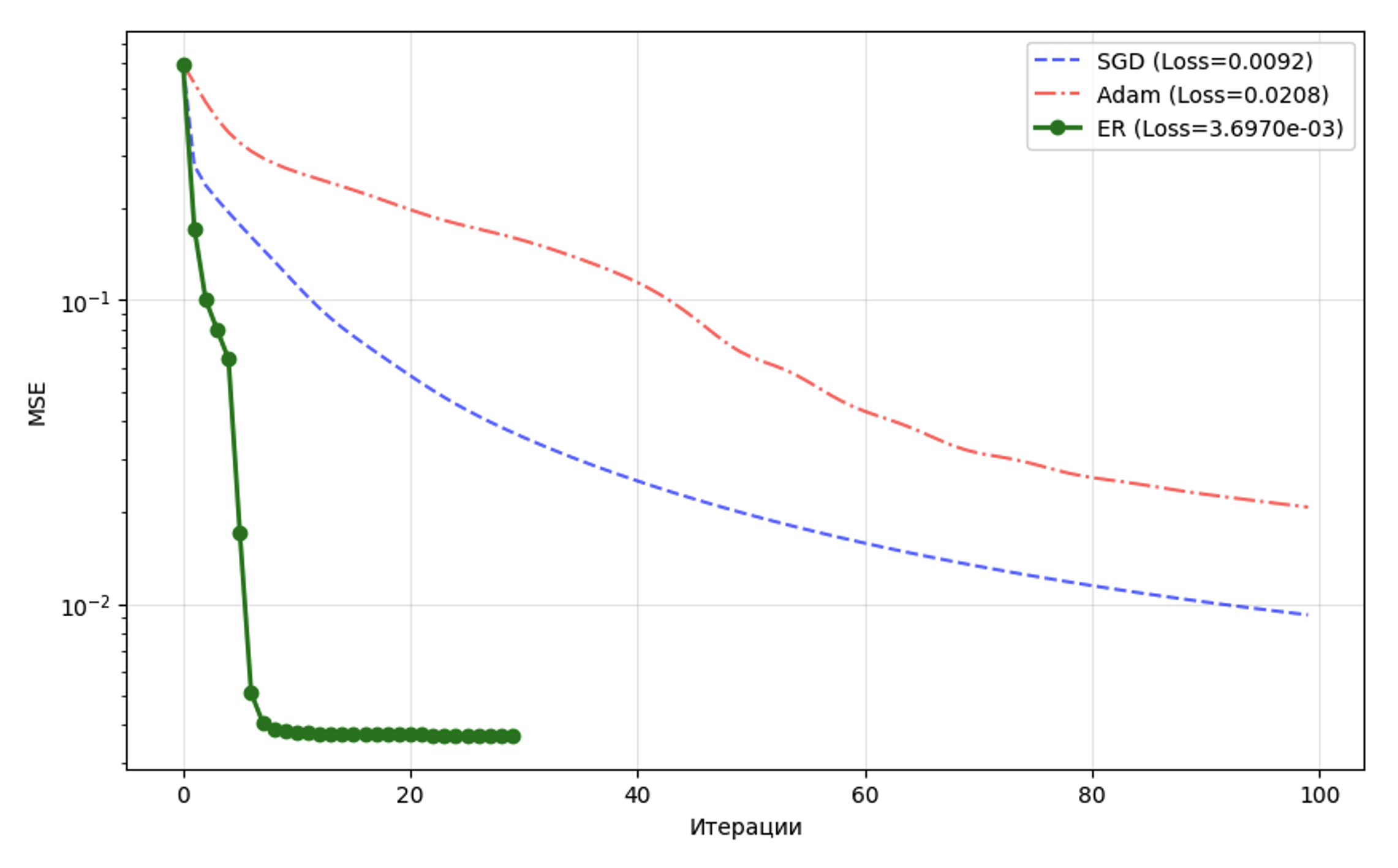
Сходимость оптимизаторов на задаче регрессии
3.6. Вычислительные ограничения
Несмотря на подавляющее преимущество в качестве сходимости, точная реализация ЭР требует вычисления матрицы вторых производных и ее спектрального разложения на каждом шаге. Это дает кубическую вычислительную сложность O(N3) и квадратичные требования к памяти O(N2)
. Для сетей с миллионами параметров применение точного метода невозможно. Для масштабирования алгоритма на большие архитектуры необходимо внедрять безгессиановые методы в подпространствах Крылова, которые позволяют аппроксимировать произведение матрицы Гессе на вектор за линейное время O(N ⋅ k) , с использованием современных инструментов спектрального анализа глубоких сетей .4. Обсуждение
Полученные эмпирические результаты наглядно демонстрируют фундаментальные ограничения методов оптимизации первого порядка и адаптивных алгоритмов (SGD, Adam) в условиях патологической кривизны ландшафта потерь. В задачах с сильно коррелированными признаками (таких как набор данных Breast Cancer) и синтетических оврагах с числом обусловленности κ(G)≫1, градиент направлен преимущественно вдоль крутых склонов. Как показывают наши эксперименты и подтверждают недавние исследования геометрии глубокого обучения
, методы, опирающиеся исключительно на локальный градиент, неизбежно сталкиваются с высокочастотными осцилляциями и явлением «заклинивания» (jamming). Хотя алгоритм Adam пытается компенсировать это за счет адаптивных скоростей обучения, он неявно полагается на диагональную аппроксимацию матрицы кривизны , . Если оси оврага повернуты относительно координатных осей из-за мультиколлинеарности данных, эта диагональная аппроксимация становится несостоятельной, что приводит к преждевременной остановке алгоритма вдали от оптимума. В отличие от классических подходов, метод экспоненциальной релаксации (ЭР) продемонстрировал способность точно восстанавливать параметры и преодолевать вырожденные желоба. Этот успех математически обусловлен использованием точной матрицы Гессе G и функции релаксации R(λi)=(1-ehλi) )/λi, которая динамически подстраивает шаг в базисе собственных векторов. Физический смысл этого преобразования объясняет результаты всех проведенных экспериментов. В направлениях большой кривизны (λi≫0, стенки оврага) множитель стремится к 1/λi. ЭР действует как метод Ньютона, мгновенно опускаясь на дно оврага без осцилляций, что объясняет быстрое падение ошибки на функции Розенброка. В направлениях малой кривизны (λi≈0, пологое дно вырожденного желоба) функция R(λi) раскладывается в ряд Тейлора и стремится к базовому шагу h. Это позволяет алгоритму безопасно и уверенно продвигаться к минимуму там, где градиент практически исчезает. При попадании в седловые точки (задача автоэнкодера с нулевой инициализацией), где λi<0, классический метод Ньютона устремился бы к самому седлу, а SGD застрял бы из-за нулевого градиента. В ЭР же отрицательное собственное значение приводит к экспоненциальному росту множителя R(λi), что обеспечивает мощный и направленный выталкивающий импульс вдоль вектора отрицательной кривизны . Особого внимания заслуживает способность ЭР обращать экстремально жесткие операторы в задачах деконволюции (достижение машинного нуля 10-21 за 50 итераций). Это открывает широкие перспективы для применения алгоритма в физически-информированных нейросетях (PINN), где конкуренция между компонентами функции потерь часто приводит к градиентным патологиям, с которыми не справляется Adam . Главным фактором, сдерживающим повсеместное применение точного метода ЭР в глубоком обучении, остается кубическая вычислительная сложность спектрального разложения O(N3) и квадратичные требования к памяти O(N2) . Дальнейшие исследования должны быть направлены на интеграцию функции экспоненциальной релаксации с безгессиановыми (Hessian-free) методами аппроксимации в подпространствах Крылова. Использование современных инструментов стохастической оценки следа и спектра матрицы Гессе (например, алгоритма Ланцоша и библиотеки PyHessian ) позволит аппроксимировать матричную экспоненту за линейное время O(N ⋅ k), масштабируя метод ЭР на архитектуры с миллионами параметров.5. Заключение
Обучение глубоких нейронных сетей фундаментально зависит от способности алгоритмов оптимизации эффективно минимизировать невыпуклые функционалы эмпирического риска. В данной работе была проведена строгая оценка метода экспоненциальной релаксации (ЭР) как альтернативы популярным стохастическим методам первого порядка (SGD, Adam). Поставленная цель исследования полностью достигнута: мы теоретически обосновали и эмпирически доказали, что в условиях патологической кривизны, мультиколлинеарности признаков и наличия седловых точек метод ЭР демонстрирует абсолютное превосходство. Динамическое масштабирование шага на основе непрерывной функции от кривизны пространства позволяет методу ЭР успешно сходиться в вытянутых и повернутых оврагах, избегая высокочастотных осцилляций и стагнации. В задачах точного восстановления физических параметров, деконволюции сигналов и классификации высококоррелированных медицинских данных алгоритм второго порядка достигает оптимальных состояний за гораздо меньшее число итераций. Хотя вычислительная стоимость ограничивает применение неоптимизированных подходов вычисления шага метода в сверхбольших архитектурах нейросетей, метод экспоненциальной релаксации уже сегодня является незаменимым инструментом для решения обратных физических задач, тренировки физически-информированных нейросетей (PINN) и оптимизации компактных систем управления. Переход к проекционным алгоритмам и адаптивным стратегиям аппроксимации кривизны является ключевым вектором для дальнейших исследований, который в перспективе позволит внедрить механизмы матричной экспоненты в повседневную практику масштабируемого глубокого обучения.