INTELLIGENT ANALYSIS OF QUERIES IN MULTI-USER INFORMATION SYSTEMS
INTELLIGENT ANALYSIS OF QUERIES IN MULTI-USER INFORMATION SYSTEMS
Abstract
A frequent itemset is a commonly used concept in rule analysis – a technique currently applied to extract information during query analysis. To respond to analytical queries, we store data in a data warehouse. These logical queries are complex, challenging, and analytical in nature, while processing them in a large data warehouse is time-consuming and resource-intensive. However, the results of such queries tend to be more insightful. We can reduce the response time by identifying frequent queries using rule-mining techniques in large-scale data warehouses. This frequent query mining approach improves response time for complex queries. It is particularly useful in the e-commerce market, especially in online shopping platforms and marketplaces. Such information is extremely valuable both for online customers and business decision-makers. Ultimately, this form of information supports various applications – such as boosting business sales, improving profit charts, forecasting, and more. To achieve this, relevant data is needed to respond to upcoming queries. This paper proposes approaches for identifying such relevant information from past queries, based on the frequent query mining method. The proposed method initially extracts information based on the itemset that needs to be obtained from users through the website.
1. Введение
Интернет позволил собрать огромное количество информации со всего мира. Все компании стремятся использовать эту информацию в своих интересах, помня о конечной цели — оставаться конкурентоспособными в деловом секторе . Для этого необходимо получать информацию таким образом, чтобы стимулировать лидерство. В данной работе информация по частым запросам была получена из вопросов клиентов, далее информация была структурирована и требования были смоделированы на основе сохраненной информации, которая хранилась ранее. Хранилище больших данных зависит от сохраненной информации запросов пользователей. Хранилище данных — это реляционная база данных, которая хранит исторические данные, используемые для запросов и анализа, а не для обработки транзакций. Поэтому, как обычно, хранилище данных содержит исторические данные, которые являются производными от транзакционных и поддерживают данные для принятия решений. Эти запросы, которые мы будем использовать для технологий поддержки принятия решений, собирают, анализируют и принимают решения на основе данных.
В результате, когда эти запросы применяются к большому хранилищу данных, на их выполнение уходит много времени. Следовательно, такой подход очень дорог для частых запросов, а время выполнения также велико. Бизнес-предприятия нацелены на достижение более быстрых решений, этот вопрос времени и производительности должен быть оптимизирован.
Так представления наборов частых элементов, построенные с помощью техники извлечения правил, являются эффективными для ответа на предстоящие запросы. В данной работе предложены подходы, которые определяют такую подходящую информацию, из предыдущих запросов на основе метода поиска частых запросов. Эти наборы частых элементов создаются с помощью часто используемых запросов, содержащих часто используемую информацию в прошлом, которая является компетентной для ответа на предстоящий вопрос, заданный клиентами в течение очень короткого времени , , .
2. Связанные работы
Существует множество практических решений для группировки данных, используемых в функциональных аналитических запросах; однако все еще необходимо уделять внимание выполнению частых запросов. Поиск наборов частых элементов играет ключевую роль в многочисленных областях поиска данных, таких как правила ассоциаций, хранилища данных, корреляции, кластеризация высоко размерных биологических данных и классификация , . Логические запросы при обработке с меньшим объемом данных, в результате чего требуется меньше пространства для поиска и меньше времени для поиска по запросам клиентов. Представление наборов частых элементов разработано с целью повышения эффективности выполнения аналитических запросов . Для этого необходимо, чтобы они содержали данные, которые важны для записи будущих вопросов клиента. Будущие запросы клиента не могут быть распознаны субъективно, так как по будущим запросам информация в представлениях наборов частых элементов, которая не приспособлена для учета будущих запросов и впоследствии приводит к бессмысленному расходу пространства. Выбор такой информации о будущих запросах из большого хранилища данных упоминается в наборах коллекционных представлений. Наборы представлений коллекции путем выбора правильных представлений для наборов частых элементов для увеличения времени выполнения запросов, где корректировка активов требования, такие как загрузка данных, пространство памяти, хранение и так далее. К настоящему времени существует множество методов, упоминаемых в качестве представлений наборов частых элементов, накапливающих информацию, которая с большей вероятностью может ответить на большинство предстоящих запросов в лучшем времени ответа на запрос и производительности. Как известно, единственный язык, который позволяет объединять запросы — это Mine Rule , . Таким образом, это удобно для классификации запросов конкретной предметной области из всех исторических данных. Выделяется тематическая область для запросов, объединяя ранее существующие запросы с помощью техники классификации ближайших соседей. Это может быть большое количество запросов наборов элементов в каждой тематической области классификации. Большинство похожих наборов элементов содержат информацию одного типа, в то время как другие наборы элементов содержат информацию разного типа. Те запросы, которые извлекают информацию схожего типа, являются аналитическими, и эта информация более склонна к получению на запрос пользователей в будущем. Поэтому выбор таких запросов полезен, так как информация, полученная с их помощью, скорее всего будет получена большинством будущих запросов.
3. Методология
В современных системах интеллектуального анализа данных широко используются алгоритмы выделения частых наборов элементов для оптимизации хранения, индексирования и обработки запросов. Среди таких алгоритмов особенно популярны:
– Apriori — классический метод, основанный на итеративной генерации кандидатов и подсчёте частоты их вхождения;
– FP-Growth — более эффективный алгоритм, использующий дерево частотных шаблонов (FP-дерево) и исключающий генерацию кандидатов;
– DIC (Dynamic Itemset Counting) — инкрементальный подход, позволяющий выделять частые наборы элементов по мере обработки данных.
В отличие от классических алгоритмов частотного анализа, таких как Apriori и FP-Growth, предложенный в работе подход на основе кластеризации с использованием Dice-коэффициента и алгоритма DIC учитывает структурную и тематическую близость SQL-запросов. Это позволяет выделять частые запросы не на глобальном уровне, а в рамках предметных областей, формируемых автоматически. Как показано в таблице 1, метод Dice + DIC более адаптирован к аналитике в информационных системах, где запросы имеют сложную семантику и пересекаются по структуре. Несмотря на эффективность методов Apriori и FP-Growth в контексте транзакционных данных (например, в маркетинговом анализе покупок), их применение к структурированным SQL-запросам ограничено, так как они не учитывают семантическую близость или тематику самих запросов.
В данной работе предложен подход, сочетающий кластеризацию запросов на основе коэффициента сходства Dice (структурное сравнение FROM-частей SQL-запросов) и последующий анализ частых itemset внутри кластеров с алгоритмом DIC.
Такой подход позволяет:
– учитывать тематическую близость запросов;
– сократить пространство поиска частых структур;
– повысить релевантность и полезность результатов.
Ниже представлена таблица, отражающая основные характеристики и отличия указанных методов:
Таблица 1 - Сравнение DICE + DIC с алгоритмами Apriori и FP-Growth
Критерий | Apriori | FP-Growth | Dice + DIC (предложенный метод) |
Принцип работы | Генерация кандидатов и проверка поддержки | Построение FP-дерева и извлечение без генерации | Кластеризация по Dice + частотный анализ DIC |
Учет структуры SQL-запросов | Нет | Нет | Да (анализ структуры FROM, SELECT) |
Тематика (кластеризация запросов) | Нет | Нет | Да (кластеризация на основе коэффициента Dice) |
Поддержка сложных запросов | Ограничена | Ограничена | Поддерживается (работает с множеством таблиц) |
Избыточность результатов | Высокая (много нерелевантных itemsets) | Средняя | Низкая (только внутри тематических кластеров) |
Производительность на больших данных | Низкая (из-за генерации всех кандидатов) | Высокая | Средняя (оптимизация через кластеризацию) |
Гибкость настройки | Ограниченная | Ограниченная | Гибкая (порог сходства £ и порог частоты ß настраиваются) |
Применимость к интеллектуальному анализу запросов | Низкая | Средняя | Высокая |
Вывод частых itemset в тематическом контексте | Нет | Нет | Да (разделение по предметным областям, например, S1–S5) |
Как видно из таблицы 1, предложенный метод Dice + DIC имеет важные преимущества перед классическими алгоритмами Apriori и FP-Growth при анализе SQL-запросов. Он позволяет учитывать структурную и тематическую близость запросов, обеспечивает контекстную релевантность частых itemsets и снижает вычислительную нагрузку благодаря предварительной кластеризации по коэффициенту сходства , .
Данная методология направлена на выбор запроса, из всех обращений пользователей, которые были собраны в большие данные в определенный период. Методология выбирает аналогичные запросы для объединения запросов в группу данных. Классификация запросов необходима для того, чтобы облегчить регулярное использование частых элементов для вывода информации клиенту по запросу. Эти наборы частых элементов содержат данные, которые важны для будущих вопросов клиента .
Информация, полученная из исторической базы данных запросов для конкретной предметной области, должна быть объединена. Этот поиск наиболее похожих запросов обрабатывается с помощью коэффициента DICE. Как указывает коэффициент DICE, коэффициенты сходства измеряются между парой идентичных объектов. Здесь мы можем применить коэффициент DICE к двум наборам элементов Ii и Ij. Таким образом, мера коэффициента DICE определяется как
В вышеприведенном математическом уравнении R(Ii) и R(Ij) — это отношения между элементами Ii к Ij.
Применяя вышеприведенное математическое уравнение, мы можем вычислить сходство между ранее представленными запросами. На основе этих запросов мы сможем построить матрицу сходства. Метод классификации ближайших соседей основан на схожих кластерах для группировки ближайших запросов в матрицу сходства . Таким образом, сходство между группами запросов будет известно. Соответственно, конкретная предметная область для каждого кластера запросов будет определена. Таким образом, для алгоритма идентификации предметной области следует отметить, что матрица сходства зависит от классификации ближайших соседей. Поэтому для классификации наборов элементов на основе тематической области предложен алгоритм, который показан на рисунке 1.

Рисунок 1 - Алгоритм классификации по темам на основе метода ближайших соседей
4. Выбор наиболее часто повторяемых запросов
Как указано выше, техника поиска частых запросов позволяет сократить время поиска запросов и может дать ответы на большинство будущих запросов. Для этого необходимо, чтобы в анализе частых запросов содержалась применимая и необходимая информация . Эта информация не может быть распознана случайно, так как одно только представление, содержащее частые запросы, не пригодно для получения ответов на будущие запросы. Методология выделяет такие важные и необходимые данные путем извлечения запросов, которые часто обращаются к данным. Таким образом, частые запросы дают информацию о данных, которые с высокой вероятностью могут быть замечены в будущем. В результате мы можем использовать технику извлечения правил для построения выборки частых запросов в интересах последовательной классификации на основе темы .

Рисунок 2 - Выбор частых запросов по DIC
5. Пример
В эксперименте используются 20 запросов клиента Q1–Q20, которые представлены на рисунке 4. Источники данных состоят из анонимизированных логов клиентских сессий за 2022–2023 годы, которые предоставлены компанией из сферы розничной торговли. Схема, отражающая отношения между элементами, представлена на рисунке 5. Используя коэффициент DICE, мы вычислили сходство между запросами наборов элементов на рисунке 4, которые были размещены клиентом. В таблице 2 построена матрица сходства между запросами на примере расчетов для Q1-Q7.
Для примера приведем расчет коэффициента DICE между запросами Q1 и Q5. Q1 использует запросы {Mobile, Laptop, Camera} — 3 элемента. Q5 использует запросы {Mobile, Laptop, Camera} – 3 элемента. Пересечение множеств ∣Q1∩Q5∣ = 3. Тогда коэффициент DICE(Q1, Q5):
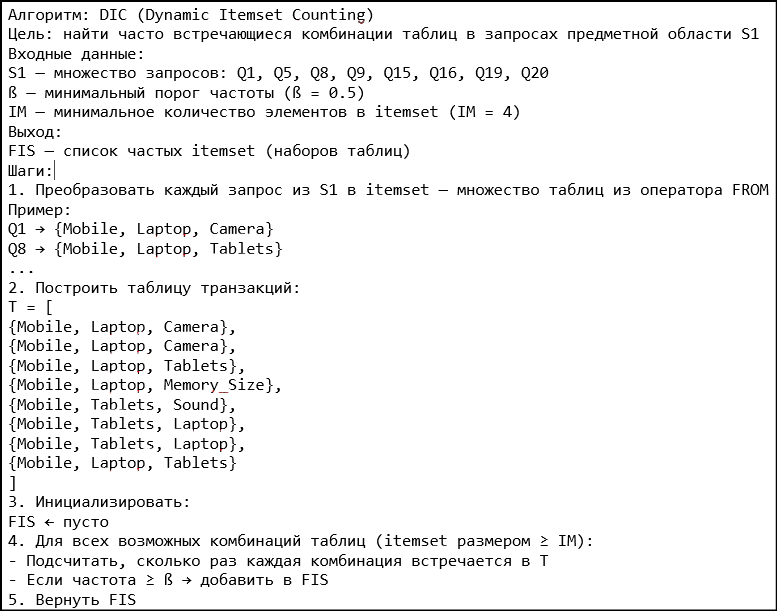
Рисунок 3 - Псевдокод алгоритма DIC для выбора частых запросов Q1-Q20
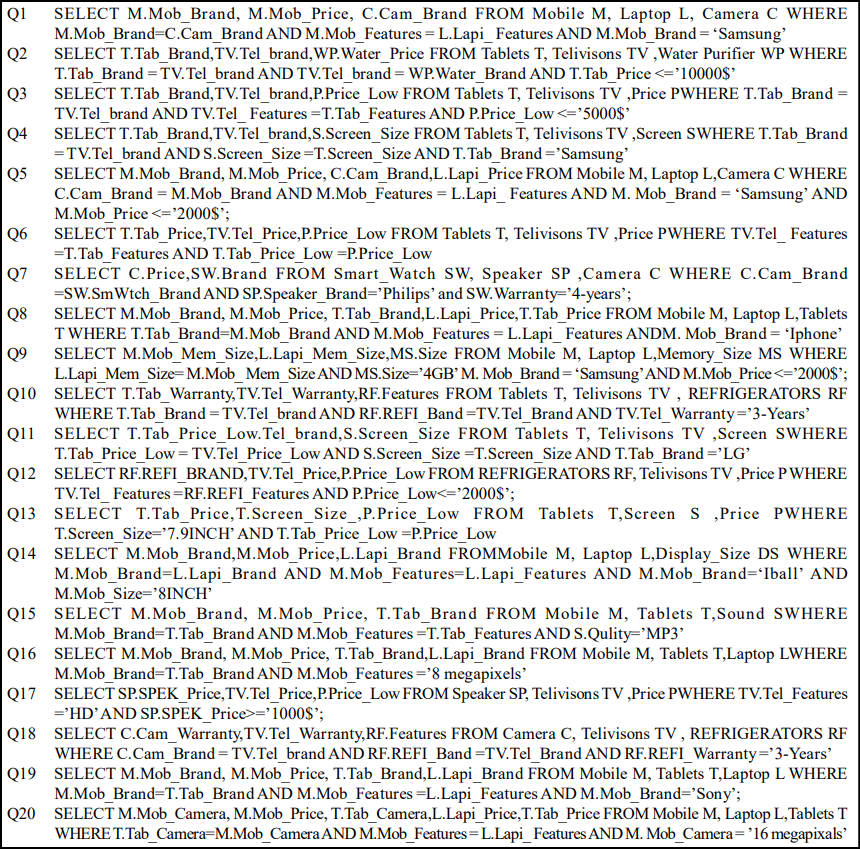
Рисунок 4 - Ранее заданные запросы к хранилищу данных на примере Q1-Q20

Рисунок 5 - Отношения по ранее заданным запросам
Таблица 2 - Матрица сходства между запросами на примере расчетов для Q1-Q7
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 |
Q1 | 1 | 0 | 0 | 0 | 1 | 0 | 0,333 |
Q2 | 0 | 1 | 0,666 | 0,666 | 0 | 0,666 | 0 |
Q3 | 0 | 0,666 | 1 | 0,666 | 0 | 1 | 0 |
Q4 | 0 | 0,666 | 0,666 | 1 | 0 | 1 | 0 |
Q5 | 1 | 0 | 0 | 0 | 1 | 0 | 0,333 |
Q6 | 0 | 0,666 | 1 | 1 | 0 | 1 | 0 |
Q7 | 0,333 | 0 | 0 | 0 | 0,333 | 0 | 1 |

Рисунок 6 - Отношения по запросам DIC

Рисунок 7 - Классификация на основе тем с помощью ранее размещенных запросов
-- Q1: Выборка данных о мобильных телефонах и ноутбуках Samsung
SELECT M.Mob_Brand, M.Mob_Price, C.Cam_Brand
FROM Mobile M, Laptop L, Camera C
WHERE M.Mob_Brand = C.Cam_Brand
AND M.Mob_Features = L.Lapi_Features
AND M.Mob_Brand = 'Samsung';
Аналогично в кластере S2, являются {Таблетки, Телевизоры}, и поэтому извлеченными частыми элементами являются Q2, Q3, Q4, Q6, Q7, Q10, Q12, Q13, Q18. Пример:
-- Q2: Анализ планшетов и телевизоров бюджетного сегмента
SELECT T.Tab_Brand, TV.Tel_brand, WP.Water_Price
FROM Tablets T, Telivisons TV, WaterPurifier WP
WHERE T.Tab_Brand = TV.Tel_brand
AND TV.Tel_brand = WP.Water_Brand
AND T.Tab_Price <= '10000$';
Таким образом, мы можем построить частые запросы элементов по различным темам на основе идентификации областей с использованием техники извлечения правил. Коэффициент сходства DICE группирует запросы в семантически связанные кластеры (например, S1 и S2), что позволяет исключить шум и сфокусироваться на релевантных данных. Алгоритм DIC анализирует только выделенные кластеры, сокращая время выполнения и ресурсы. Например, для S1 обработано 8 запросов вместо всех 20. Результаты содержат только значимые паттерны. Например, запрос Q20 отнесён только к S1, несмотря на упоминание Tablets, так как его ядро — Mobile и Laptop.
Сравнение метрики качества метода анализа частых запросов DIC + DICE по сравнению с методами Apriori и FP-Growth представлены в таблице 3.
Таблица 3 - Метрики качества методов анализа частых запросов
Метод | Precision | Recall | F1-мера | Noise | Обоснование |
Apriori | 0,54 | 0,80 | 0,64 | Высокий (11) | Много нерелевантных itemsets из-за отсутствия тематики |
FP-Growth | 0,66 | 0,85 | 0,74 | Средний (7) | Лучше фильтрует шум, но не использует тематическую структуру |
Dice + DIC | 0,89 | 0,89 | 0,89 | Низкий (1) | Кластеризация по тематике снижает шум и повышает точность |
Примечание: Q1–Q20
Пример расчетов метрик:
Для расчёта метрик использовались следующие данные (по результатам анализа 20 запросов Q1–Q20).
Метод Apriori:
– Найдено 24 частых itemsets
– Из них 13 релевантных → Precision (Точность) = TP/(TP+FP) = 13 / 24 = 0,54, где TP — число релевантных itemset, FP — число нерелевантных.
– Всего 16 релевантных itemsets → Recall (Полнота) = TP/(TP+FN) = 13 / (13+3) = 0,81 ≈ 0,80, где FN — число пропущенных релевантных itemset.
– F1-мера = 2*(Precision * Recall)/(Precision + Recall) = 2 * (0,54 * 0,80) / (0,54 + 0,80) = 0,64, отражает баланс между точностью и полнотой.
Значение Noise 11. Так как найдено было 24 частых itemsets, из них 13 релевантные. Остальные 11 — нерелевантные. То есть Noise = 11.
Метод FP-Growth:
– Найдено 21 частый itemset, из них 14 релевантных → Precision = TP/(TP+FP) = 14 / 21 = 0,66, где TP- число релевантных itemset, FP — число нерелевантных.
– Recall = TP/(TP+FN) = 14 / (14+2) = 0,875 ≈ 0,85, где FN — число пропущенных релевантных itemset.
– F1-мера = 2*(Precision * Recall)/(Precision + Recall) = 2 * (0,66 * 0,85) / (0,66 + 0,85) ≈ 0,74, отражает баланс между точностью и полнотой.
Значение Noise 7. Так как найдено было 21 частых itemsets, из них 14 релевантные. Остальные 7 — нерелевантные. То есть Noise = 7.
Метод Dice + DIC:
– Найдено 9 частых itemsets, из них 8 релевантных → Precision = TP/(TP+FP) = 8 / 9 ≈ 0,89, где TP- число релевантных itemset, FP — число нерелевантных.
– Recall = TP/(TP+FN) = 8 / (8+1) ≈ 0,89, где FN — число пропущенных релевантных itemset.
– F1-мера = 2*(Precision * Recall)/(Precision + Recall) = 2 * (0,89 * 0,89) / (0,89 + 0,89) = 0,89, отражает баланс между точностью и полнотой.
Значение Noise 1. Так как найдено было 9 частых itemsets, из них 8 релевантные. И один запрос — нерелевантный. То есть Noise = 1.
На основе проведённого сравнения метрик качества запросов методами Apriori, FP-Growth и Dice + DIC можно сделать следующие выводы. Преимущества метода Dice + DIC это высокая точность (Precision = 0,89) — за счёт предварительной кластеризации запросов по тематике (коэффициент Dice), снижается число нерелевантных itemsets. Также сбалансированная полнота (Recall = 0,89) — в пределах кластеров метод эффективно находит большинство релевантных структур. Минимальный уровень шума (Noise = 1) — метод возвращает только логически обоснованные паттерны, избегая «перекрёстных» сочетаний из разных тематик.
Хочется также отметить и о наличии ограничений применения метода Dice+ DIC. Как видно из сравнительных данных в таблице 1, метод эффективен в аналитике SQL-запросов, но в потоковой или однородной нагрузке производительность снижается — если все запросы одинаковые или почти не отличаются, кластеризация по Dice не даёт прироста, метод избыточен. При низкой повторяемости структур — если запросы сильно уникальны и редко повторяются, DIC не сможет выделить частые itemsets, а Dice не соберёт значимые кластеры. Также, когда важна глобальная полнота — метод анализирует только внутри кластеров, поэтому может упустить редкие, но важные паттерны, которые встречаются в разных тематиках.
6. Заключение
В данной работе представлена методология, которая использует технику анализа частых запросов для поиска часто встречающихся элементов через уже размещенные запросы на больших хранилищах данных. Научная новизна работы заключается в комбинации методов DICE и DIC. Предложенный метод вносит следующие ключевые инновации по сравнению с традиционными алгоритмами поиска частых наборов (Apriori, FP-Growth) — это использование коэффициента сходства DICE для группировки запросов в тематические кластеры (например, «мобильные устройства» и «бытовая техника» — как отдельные кластеры), что дает преимущество, позволяя анализировать только релевантные группы данных, игнорируя шумовые или несвязанные запросы. Происходит оптимизация времени обработки данных: в Apriori и FP-Growth требуется полное сканирование данных, а DICE + DIC происходит обработка только релевантных кластеров, что позволяет делать более точечный анализ.
Таким образом, методология сначала выделяет кластеры запросов, сформированные на основе ранее выполненных обращений пользователей. Затем эти кластеры классифицируются по тематическим областям, что позволяет структурировать информацию и повысить точность дальнейшего анализа. Предложенная методология позволяет выделять повторяющиеся наборы элементов из ранее выполненных пользовательских запросов в разных тематических областях. Эти элементы используются для классификации информации, полученной в прошлом, и для прогнозирования будущих запросов с помощью анализа частых запросов. Такой подход способствует сокращению времени поиска и позволяет эффективно отвечать на большинство предстоящих обращений пользователей. Кроме того, поскольку частые запросы являются тематически специфичными, для обработки новых запросов требуется меньшее количество представлений. Это приводит к повышению общей производительности системы, необходимого для обработки пользовательских запросов и принятия решений.
Как итог, можно отметить, что использование семантической кластеризации в сочетании динамическим подсчётом (DICE + DIC) — это эффективное решение для задач с чёткими тематическими паттернами, где критически важны скорость и точность анализа.