Development and research of convolutional neural network models in similar image search problems
Development and research of convolutional neural network models in similar image search problems
Abstract
The problem of image location detection using similar image search algorithm is studied. There is a search collection of images consisting of high-resolution satellite images. These images are divided into equal fragments to simplify the search. The input data is a low altitude video sequence. It is necessary, based on the data in the search collection, to determine in which fragment of the satellite image at the current moment of time the shooting takes place. The aim of this work is to evaluate the feasibility of this approach and to modify the architecture of the convolutional model of the VGG16 neural network. This architecture is used for image classification, and can be used in content-based search tasks. The location search is significantly complicated by the strong difference between a pair of compared images: a terrain map of the underlying surface and fragments from a low-altitude survey (projective distortions, different scale). It is possible to evaluate the search accuracy on the basis of GPS-tracking. As a result of the training, an acceptable accuracy of the proposed algorithm was achieved.
1. Введение
В настоящее время задача определения местоположения на основе спутниковых снимков является актуальной задачей, позволяющей осуществлять навигацию без использования глобальных навигационных систем. Решение данной задачи невозможно без алгоритма сопоставления аэрофотоснимка и некоторой карты местности. В данной работе рассматривается решение задачи нахождения места съемки с использованием алгоритмов поиска по содержанию. В качестве исходных данных имеется поисковая коллекция изображений, которая представляет собой спутниковое изображение местности подстилающей поверхности, разбитое на фрагменты. Необходимо определить где в текущий момент времени осуществляется съемка на основе видеоряда съемки на небольшой высоте. Задача усложняется из-за значительных различий в условиях съемки: время суток, сезон, облачность, угол наклона сенсора и масштаб съемки. Существуют подходы, которые на основе особых точек и оптического потока определяют относительное перемещение, однако при больших расстояниях есть вероятность накопления значительной ошибки.
В данной работе рассматривается решение описанной выше задачи с использованием неглубоких свёрточных сетей. Предлагается сжимать пространство признаков изображения до некоторого вектора, фиксированного размера, на основе которого в дальнейшем становится возможно определить расположение места съёмки. Для этого необходимо осуществить обучение нейронной сети на различных парах изображений, подверженных проективным преобразованиям. В ходе работы были исследованы различные архитектуры свёрточных сетей, а также предложено собственное решение, где за основу взята модель VGG (Visual Geometry Group) — архитектура сверточных нейронных сетей, разработанная для задач классификации изображений
. Однако данная модель может быть адаптирована и для поиска похожих изображений. Классическая архитектура данной сети имеет несколько недостатков, которые вытекают из большого размера самой сети: VGG16 долго вычисляет результат работы, а также ей свойственно переобучение при небольшой выборке данных . Указанные недостатки требуют модернизации архитектуры для её использования в рамках данной задачи. Также необходимо оценить целесообразность применения данной архитектуры в задачах поиска местоположения.2. Теоретическая часть
Постановка задачи. Необходимо разработать алгоритм обучения нейронной сети, модернизировать модель VGG16 применительно к задаче поиска изображений.
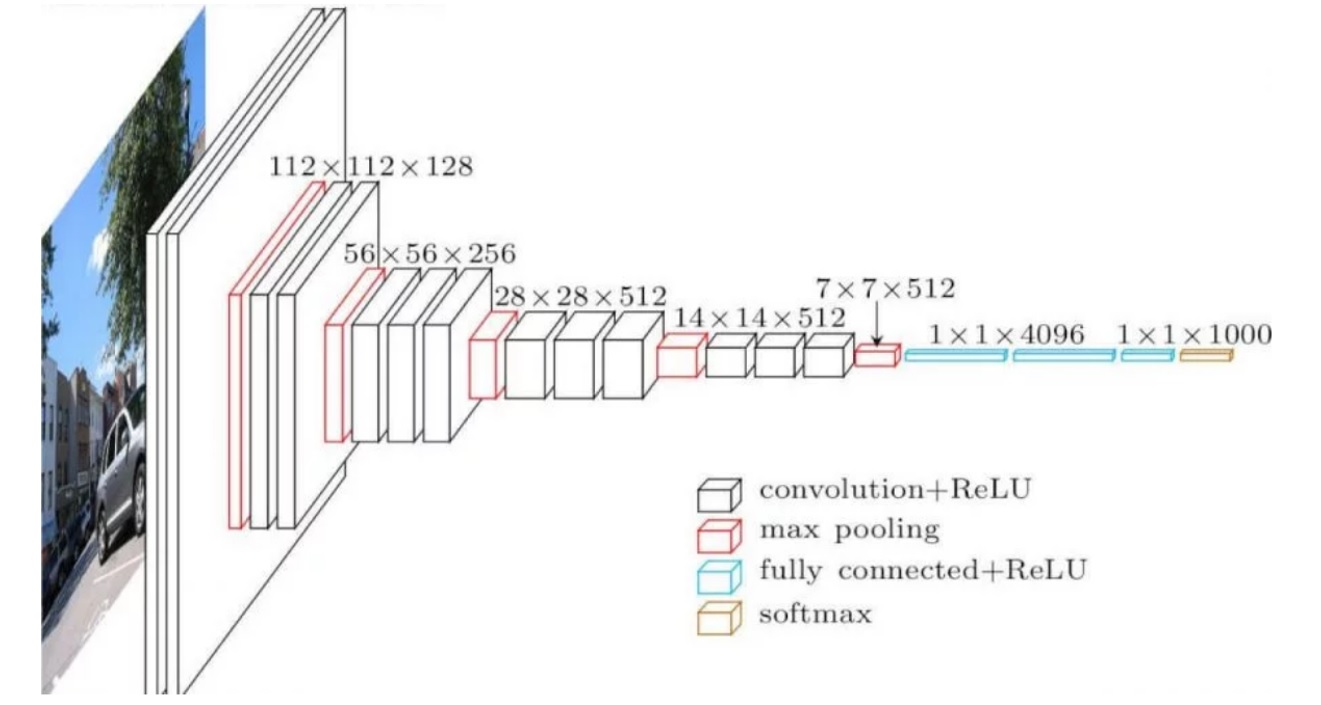
Рисунок 1 - Модель сверточной нейронной сети VGG16
- Глубина сети: 16 слоев, которые обучаются (включая 13 сверточных слоев и 3 полносвязных слоя). Число «16» в названии указывает на количество обучаемых слоев.
- Свёрточные слои: применяются свёрточные слои с небольшими фильтрами размером 3x3, что позволяет сети захватывать более сложные паттерны и детали в изображениях. Слои организованы в блоки, где после нескольких сверточных слоев следует слой подвыборки (max pooling).
- Max Pooling: слои подвыборки (обычно 2x2) используются для уменьшения пространственного разрешения и снижения вычислительной сложности, а также для извлечения наиболее значимых признаков.
- Активация: в качестве функции активации используется ReLU (Rectified Linear Unit), что помогает ускорить обучение и улучшить производительность сети.
- Полносвязные слои: в конце сети находятся три полносвязных слоя, где последний слой использует функцию активации softmax для классификации.
- Параметры: VGG16 имеет около 138 миллионов параметров, что делает ее вычислительно сложной, но при этом она демонстрирует высокую точность в различных задачах.
Для обучения такой сети требуется ее расширения до сиамской архитектуры, где на вход подаются два изображения, а на выходе формируется единственное значение — величина подобности изображений. На рисунке 2 представлена модель вычисления сходства с использованием сиамских сетей.
Принцип работы сиамский сетей заключается в использовании двух идентичных сетей для пары изображений, на выходном слое формируется вектор признаков
, . На рисунке 2 приведена пара изображений, на которых расположен один и тот же объект. С помощью предложенной нейронной сети формируется вектор признаков изображений, таким образом, чтобы изображения, содержащие один и тот же объект, имели близкие по модулю значения. Расстояния между векторами может быть вычислено с использованием косинусного сходства, Евклидовова расстояния, СКО и др.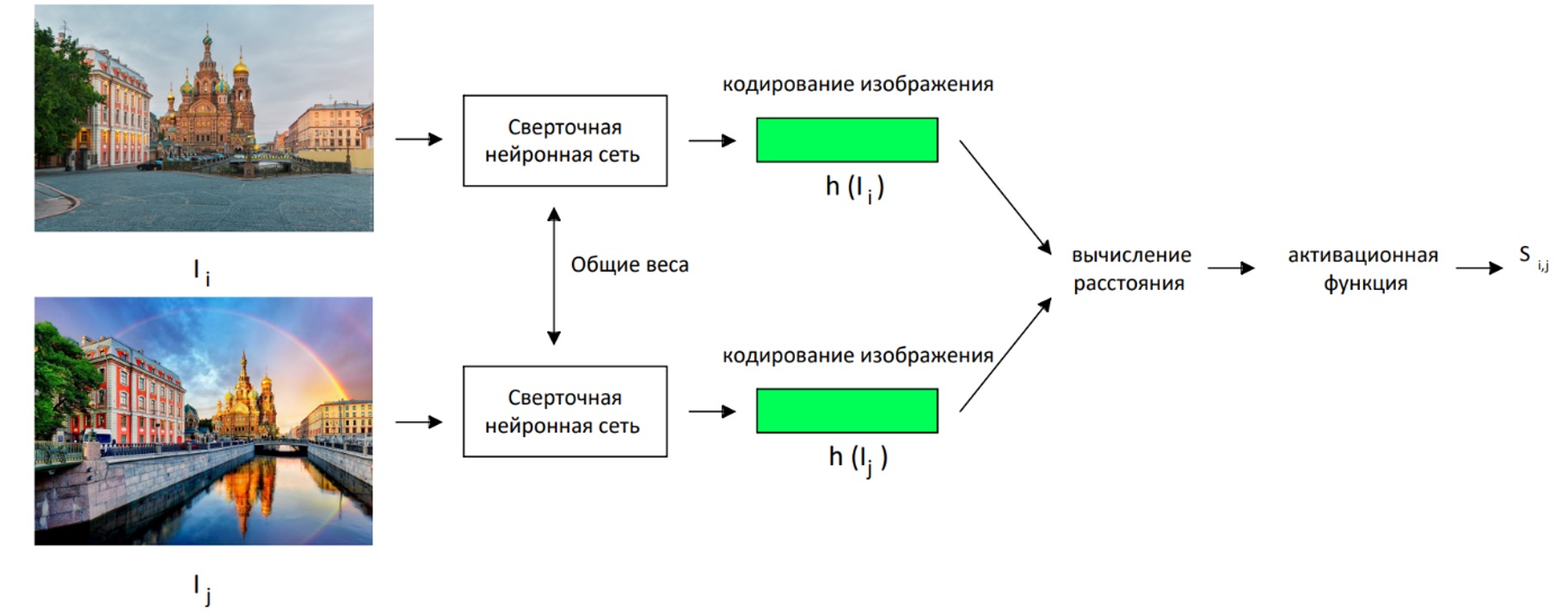
Рисунок 2 - Модель вычисления сходства с использованием сиамских сетей
Косинусное сходство между двумя векторами A и B можно вычислить по следующей формуле:
где
Значение косинусного сходства варьируется от -1 до 1:
1. Значение 1 означает, что векторы идентичны (максимальная схожесть).
2. Значение 0 означает, что векторы ортогональны (нет схожести).
3. Значение -1 указывает на противоположные направления (в контексте поиска похожих изображений это обычно не имеет смысла, так как векторы признаков обычно не имеют отрицательных значений).
В поиске похожих изображений косинусное сходство используется для сравнения векторных представлений изображений, полученных, например, с помощью сверточных нейронных сетей
. Когда пользователь загружает изображение для поиска, его векторное представление сравнивается с векторными представлениями изображений в базе данных, и результаты сортируются по степени схожести. Это позволяет находить визуально похожие изображения на основе их признаков.Евклидово расстояние — это мера, используемая для определения «дистанции» между двумя точками в пространстве. В контексте визуального поиска и обработки изображений, евклидово расстояние может применяться при сравнении векторных представлений изображений
, .Когда изображения преобразуются в векторные представления (например, с помощью сверточных нейронных сетей), Евклидово расстояние может использоваться для измерения различий между этими векторами. Чем меньше Евклидово расстояние между векторами двух изображений, тем более похожими они считаются.
где
3. Экспериментальные исследования
Выбор свёрточной архитектуры, а также количество характеристик в векторе сильно зависят от формата входных данных и обучающей выборке. Поэтому для данной задачи были исследованы как существующие модели ImageNet, так и разработанные в ходе данного исследования, на основе VGG16
, .Выбор метрики оценки расстояния между векторами признаков обуславливается тем, что косинусное сходство фокусируется на направлении векторов, что позволяет лучше оценивать, насколько два документа схожи по содержанию, независимо от их абсолютной величины. Выбор косинусного сходства в задачах поиска по содержанию обусловлен его способностью более точно отражать семантическое сходство между векторами.
В ходе обучения сети было выявлено, что существующие модели с большим количеством весов склонны к переобучению, в то время как неглубокие модели демонстрируют более высокие показатели точности при фиксированном количестве эпох (количество полных проходов через обучающий набор данных). В таблице 1 приведены рассматриваемые модели нейронной сети, время обучения в мс, количество весов у указанных моделей, а также ошибка, вычисленная с использованием СКО.
Таблица 1 - Результаты исследования набора данных на существующих моделях ImageNet
Модель | Время, мс | Ошибка (СКО) | Кол-во весов (млн) |
MobileNet v2 | 27 | 0,7557 | 3,5 |
Xception | 192 | 0,5487 | 22,9 |
VGG16 | 867 | 0,2695 | 138,4 |
VGG19 | 892 | 0,2311 | 143,7 |
Предложенное решение | 32 | 0,1729 | 0,358 |
Исходя из данных, полученных в таблице 1 можно сделать вывод, что при существенном уменьшении количества весов (в 10 раз по сравнению с MobileNet v2) ошибка (СКО) ниже.
В предлагаемой модели акцент был сделан на замене функции активации (ELU вместо ReLU), что позволило избавиться от проблемы «умирающих» нейронов, а также снизило количество свёрток на слоях сети.
В качестве последнего слоя свёрточной сети располагался вектор характеристик изображения. На последнем слое свёрточной нейронной сети VGG16 (рисунок 1) получаем 1000 характеристик, которые представляются в виде вектора. На таблице 2 представлена архитектура предлагаемой нейронной сети.
Таблица 2 - Архитектура предлагаемой нейронной сети
Тип слоя | Размерность | Тип активации | Кол-во параметров |
Input | 256, 256, 3 | - | - |
Conv2D | 256, 256, 128 | elu | 1280 |
Conv2D | 256, 256, 128 | elu | 147584 |
MaxPooling2D | 128, 128, 128 | - | - |
Conv2D | 128, 128, 64 | elu | 73792 |
Conv2D | 128, 128, 64 | elu | 36928 |
MaxPooling2D | 64, 64, 64 | - | - |
Conv2D | 64, 64, 32 | elu | 18464 |
Conv2D | 64, 64, 32 | elu | 9248 |
MaxPooling2D | 32, 32, 32 | - | - |
Conv2D | 32, 32, 32 | elu | 9248 |
Conv2D | 32, 32, 32 | elu | 9248 |
MaxPooling2D | 16, 16, 32 | - | - |
Conv2D | 16, 16, 16 | elu | 4624 |
Conv2D | 16, 16, 16 | elu | 2380 |
MaxPooling2D | 8, 8, 16 | - | - |
Conv2D | 8, 8, 64 | elu | 9280 |
MaxPooling2D | 4, 4, 64 | - | - |
Conv2D | 4, 4, 128 | elu | 73856 |
MaxPooling2D | 1, 1, 128 | - | - |
Flatten | 128 | - | - |
Итого параметров: | 395 872 | ||
Данная архитектура относится к разряду классических свёрточных сетей. Размер входного изображения — 256x256 пикселей с 3 каналами (RGB). Модель состоит из нескольких свёрточных слоёв, которые применяют фильтры к входным данным для извлечения признаков. Каждый свёрточный слой использует активацию ELU (Exponential Linear Unit), которая помогает модели быстрее сходиться и избегать проблемы «умирающих нейронов». После нескольких свёрточных слоёв применяется операция MaxPooling, которая уменьшает размерность карт признаков, сохраняя наиболее важные признаки. Это помогает снизить вычислительную сложность и предотвратить переобучение. После последнего слоя MaxPooling2D, данные выравниваются в одномерный вектор, который представляет собой вектор признаков изображения.
Размерность данных постепенно уменьшается от 256x256 до 1x1, что типично для CNN. Это достигается за счёт комбинации свёрточных слоёв и слоёв подвыборки. Количество фильтров (каналов) в свёрточных слоях варьируется от 128 на начальных слоях (поскольку наибольшую ценность в аэрофотосъёмках имеет именно высокочастотная составляющая) до 16 и 64 на более глубоких слоях, что позволяет модели извлекать как общие, так и более специфические признаки. Общее количество обучаемых параметров модели составляет 395 872. Это относительно небольшое количество параметров для CNN, что делает модель менее склонной к переобучению и более подходящей для задач, где доступно ограниченное количество данных.
В целом, данная модель представляет собой компактную и эффективную свёрточную нейронную сеть, которая подходит для задач извлечения признаков аэрокосмических изображений. Она хорошо сбалансирована по количеству параметров и может быть использована в условиях ограниченных вычислительных ресурсов.
Было проведено исследование, результаты которого представлены на рисунке 3, как количество характеристик влияет на вероятность обнаружения пары.
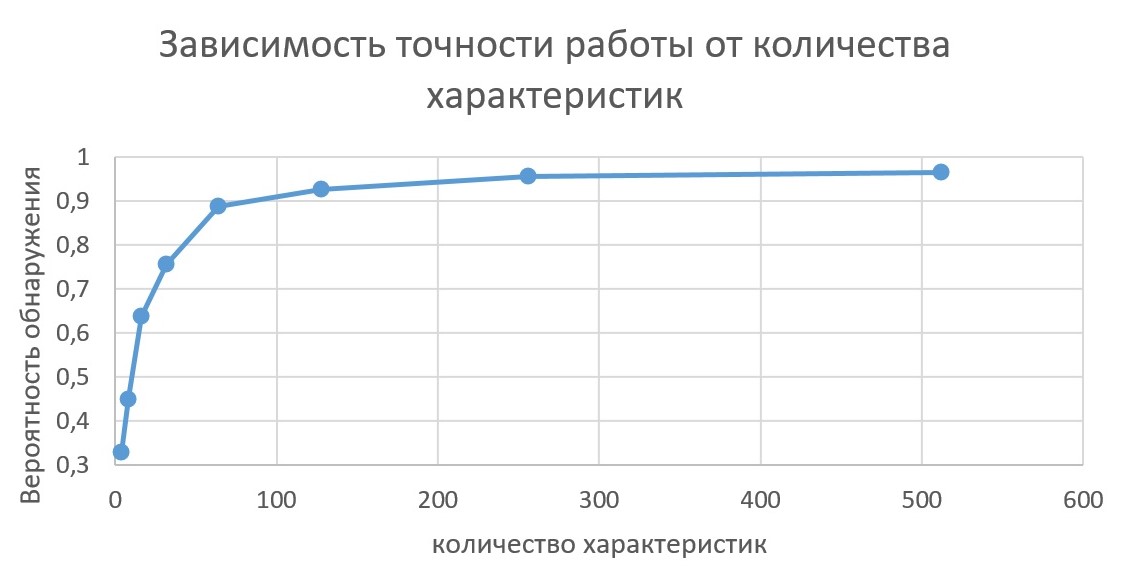
Рисунок 3 - Зависимость вероятности обнаружения пары изображений от количества характеристик
Также ниже представлены результаты экспериментальных исследований пар изображений. Приведены 3 примера пар и значения показателей их схожести.

Рисунок 4 - Пара изображений с величиной сходства - 0,63
Примечание: различный сюжет

Рисунок 5 - Пара изображений с величиной сходства - 0,98
Примечание: идентичный сюжет

Рисунок 6 - Пара изображений с величиной сходства - 0,93
Примечание: идентичный сюжет
4. Заключение
В данной работе было проведено исследование существующих свёрточных моделей нейронных сетей для решения задачи поиска похожих аэрокосмических изображений. Экспериментальная проверка на основе разработанного набора данных показала, что существующие архитектуры не являются оптимальными для данной задачи. Была предложена адаптация архитектуры VGG16 для решения поставленной задачи. Предлагаемая модель нейронной сети позволила более эффективно с точки зрения вероятности обнаружения пар изображений выделить значимые характеристики аэрофотоснимков, в сравнении с существующими моделями, при этом обладая в разы меньшей вычислительной сложностью. Также на предложенной модели было исследовано определение оптимального количества числовых характеристик изображения. При существенном уменьшении количества весов (в 10 раз по сравнению с MobileNet v2) ошибка (СКО) ниже на ≈ 0.6. Были проведены исследования на значениях, от 4 до 512. Было определено, что при увеличении числа характеристик свыше 128 точность практически не изменяется.