COMPENSATION PLAN FROM THE POINT OF VIEW OF BIG DATA

ОПЛАТА ТРУДА С ТОЧКИ ЗРЕНИЯ КОНЦЕПЦИИ BIG DATA (БОЛЬШИЕ ДАННЫЕ)
Научная статья
Шильников А.С. *
ORCID: 0000-0002-3297-6767,
ООО НПК «Электро-тепловые технологии», Томск, Россия
* Корреспондирующий автор (alex.shilnikov[at]mail.ru)
АннотацияВ статье впервые рассмотрен вопрос Больших данных, применительно к системам оплаты труда на предприятии. Автор дает обзор проблем систем оплаты труда и предлагает их решение посредством новейшей концепции в информационных технологиях – большие данные. Дается обзор самой концепции Большие данные и краткая характеристика современного положения данной концепции в России. Автор полагает, что Большие данные в области систем оплаты труда могут дать новые уникальные знания и теории. Результатом исследования статьи являются выводы о том, что Большим данным в России предстоит еще долгий путь развития. В области же систем оплаты труда Большие данные удастся получить пока только с помощью имитационного моделирования. Но уже сейчас, используя аппарат теории вероятности и математической статистики, можно приобрести ценные знания, такие как установление четкой взаимосвязи выработки, качества, удовлетворенности трудом и заработной платы в зависимости от функционирующей системы оплаты труда на предприятии.
Ключевые слова: Большие данные, Big data, оплата труда, системы оплаты труда, заработная плата.
COMPENSATION PLAN FROM THE POINT OF VIEW OF BIG DATA
Research article
Shilnikov A.S. *
ORCID: 0000-0002-3297-6767,
Postgraduate student, CEO NPK “Electro-Heat technologies”, Tomsk, Russia
* Corresponding author (alex.shilnikov[at]mail.ru)
AbstractThe article observes an actual topic of Big Data, linked to compensation plans on the enterprises. The author gives a review of a compensation plan problems and offers its solution by using the newest information technology concept – Big data. Big data concept is revealed and the situation of its promotion in Russia is described. The author believes that Big data in compensation plan question may give new valuable knowledge an theories. The results of the article research are conclusions: Big data concept is up to make develop for a long time. The only way by now to get a Big data for compensation plan aims is a imitation modeling. Then using methods of probability theory and math statistics we may obtain extraordinary knowledge today. Such as dependence of a compensation plan, quality, production and labor satisfaction.
Keywords: big data, compensation plan, wage, payments.
ВведениеОсновой коммерческих предприятий уже сотни лет являются наемные работники. От качества и объема труда которых зависит успех компаний. Отношения между наемным работником и работодателем главным образом складываются на базе понятной схемы оплаты труда. То есть системы оплаты труда, при которой работник и работодатель чётко оговаривают за какое качество, количество, время труда будет уплачена n-ая сумма денежных средств.
Несмотря на существование современных концепций управления персоналом и социологии, в которых утверждается, что на первое место для человека выходит не оплата труда, а больше такие понятия, как «радость труда», доминантой для большинства наемных работников остается размер заработной платы. Во все времена интересы наемного работника и работодателя были в своего рода конфликте. Наемный работник заинтересован потратить наименьшее количество времени и сил, при этом получить максимально возможную заработную плату. Работодатель же, напротив, получить наибольшее количество продукции наилучшего качества, при этом понеся минимальные издержки (см. рисунок 1). В связи с данным конфликтом интересов, постоянно ведется поиск «справедливой» оплаты труда.
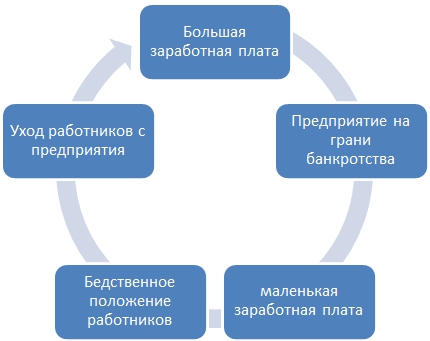
Рис. 1 – цикл размера оплаты труда
«Справедливость» оплаты труда главным образом реализуется в адекватных системах оплаты труда, которых на данный момент существует несколько десятков, если считать все их модификации. Может показаться, что имеющегося инструментария достаточно, чтобы на каждом конкретном предприятии установить приближенную к «справедливой» систему оплаты труда. Однако, практика показала, что это невозможно по нескольким причинам:
- Предприятие – динамически развивающаяся система. Это значит, что, с течением времени параметры этой системы меняются. Например может измениться объем и ассортимент выпускаемой продукции, количество персонала, схема отгрузок товара и так далее. Как следствие, казалось бы, только что найденное решение может перестать работать уже в следующем месяце.
- «Справедливость» - очень относительно понятие. И его трактование у каждого наемного работника – своё. Что может быть справедливо для одно, совсем несправедливо для другого.
- Из предыдущей причины следствием идет то, что работодатель, в силу естественных причин, очень мало знает о своих наемных работниках. А именно какие у него жизненные установки, что является для него приоритетом, сколько минимально денег ему требуется, в соответствии с его семейным положением, а сколько комфортно. Также работодатель не может знать до конца способности работника – работает ли он в полную силу или же, как писал Генри Форд «с прохладцей». Соответственно тонкая настройка системы оплаты труда для каждого индивидуально невозможна.
Таким образом, вопрос сколько платить наемным работникам, чтобы это было оптимально для одной и другой стороны, остается открытым. Если внимательно посмотреть на причины, обозначенные выше, то становится понятно, что все они так или иначе связаны с недостатком информации. Логично предположить, что если бы работодатель имел исчерпывающую информацию, причем не только ретроспективную, но и прогнозную с высокой долей вероятности, то проблем с установлением «справедливой» системы оплаты труда не возникало бы. Причем нельзя говорить о сборе данных лишь в рамках одного предприятия, так как для выявления закономерностей во влиянии СОТ на работников, требуется как минимум выборка по всей стране и разных типах предприятий. Рассмотрим какая информация есть на сегодняшний день, и какая информация потребовалась бы для установления «справедливой» системы оплаты труда (см. таблицу 1).
Таблица 1 – информация для определения «справедливой» системы оплаты труда
| Информация в наличии | Требуемая информация |
| Данные Росстата о ВВП в денежном выражении | Помесячные данные о выработке продукции |
| Данные Росстата о среднемесячной заработной плате по видам экономической деятельности | Помесячные данные о качестве продукции |
| Данные Росстата о среднемесячной заработной плате по полу и возрасту | Помесячная оценка и фиксация трудоемкости изготовления продукции |
| - | Помесячные данные об удовлетворенности трудом (в формате соц. опроса, анкетирования) |
| - | Помесячные индивидуальные данные о заработной плате работников на тысячах предприятий |
| - | Помесячная фиксация всех параметров систем оплаты труда на тысячах предприятий |
| - | Анализ изменения выработки, качества, удовлетворенности трудом при изменении параметров систем оплаты труда с одних на другие |
Все данные из правой колонки таблицы 1 должны быть сопоставимы с предприятиями, на которых собирается информация. Как следует из таблицы 1, «имеющаяся информация» не представляет практически никакой ценности для выявления закономерностей влияния СОТ на труд работников. В то же время, «требуемая информация» представляется невозможной для получения, так как потребовалась бы невероятно слаженное и точное взаимодействие тысяч предприятий по всей России.
Некоторые авторы научных работ также отмечают, что в современном мире невозможно добиться конкурентного превосходства, опираясь на стандартную информацию [3, C. 6]. Но, на данный момент эту задачу в ближайшей перспективе можно решить с помощью технологии Big Data (Большие данные), которые позволяют получать сведения, которые мы сами скорее всего специально не стали бы собирать, ввиду их неочевидной ценности. Но, обладая большим массивом данных и применив специфические алгоритмы обработки и анализа, в результате можно получить очень неожиданные теории и гипотезы [3, C. 5].
Концепция Big Data (Большие данные)
Термин «большие данные» появился в работах Джона Маша еще в конце 90-х годов [13]. Но уже на протяжении 20 лет не устоялось общепринятого определения больших данных [3, C. 2-3]. Так консалтинговая компания с мировым именем Garthner предлагает определение, основанное на 3V: «Big data – это масштабные (volume), с высокой скоростью передачи (velocity),многообразные (variety) информационные активы, которые требуют рентабельных инновационных технологий обработки для извлечения полезной информации и принятия обоснованных решений» [3, C. 3]. Другие же, например лидеры ИТ- рынка, такие как Oracle, Intel, Microsoft, предлагают собственные варианты, дополняя 3V признака до 5V [3, C. 2]. Суммируя разные источники, можно сказать, что большие данные обладает следующими признаками [5, C. 164]:
- Volume (объем) – база данных является большим массивом информации, требующий больших затрат для её обработки и хранения;
- Velocity (скорость) – скорость обработки и передвижения данных;
- Variety (разнообразие) – объем структурированных и неструктурированных данных: к первому типу относят классифицируемую информацию; неструктурированная информация занимает примерно 80% от всей поступающей информации и требует переработки (анализа) для будущего использования;
- Veracity (достоверность) – точность и правдоподобность данных;
- Value (ценность) – полезность данных для дальнейшего их применения;
Проведем анализ данных, которые, которые касаются СОТ из таблицы 1, чтобы показать, что в вопросах оплаты труда работников присутствуют признаки больших данных.
Volume (объем). По данным Росстата в России [12]:
- Около 4,5 миллионов организаций
- Порядка 72 миллионов занятых граждан
- По ОКВЭД 2018 года классифицировано 2680 видов экономической деятельности
Даже если сделать допущение, что каждое предприятие выпускает хотя бы 5 наименований товаров, работ и услуг, то ежедневно в России генерируется 45 000 000 единиц данных о количестве и качестве по каждому наименованию продукции, выпущенной в день. Также ежедневно фиксируется рабочее время и начисленная заработная плата в день 72 000 000 человек. Следовательно, ежедневно генерируется минимум 142 000 000 единиц данных об отработанном времени и начисленной заработной плате каждого из занятых граждан. Некоторая «требующаяся» информация из таблицы 1 не фиксируется вовсе. Таким образом, ежедневно генерируется около 210 млн. единиц данных, что соответствует 76,5 млрд. единиц данных в год. В общем, данные для анализа и работы с СОТ соответствуют критерию «объем» больших данных
Velocity (скорость). Скорость появления данных ежедневна, а если была бы техническая возможность на всех предприятиях, как например в сотовых компаниях, то и ежечасна.
Variety (разнообразие). Данные в СОТ действительно делятся на структурированные и неструктурированные. Например, структурированные данные – количество выпущенной продукции и начисленная заработная плата, а неструктурированные – параметры СОТ, параметры качества, удовлетворенность трудом.
Суммируя выше сказанное, можно с уверенностью утверждать, что данные, относящиеся к СОТ, являются большими данными и соответственно содержат в себе новые знания, характерные для больших данных.
Развитие концепции и технологии Больших данных в России
Современные авторы научных работ, называют Большие Данные (BIG DATA) ключевым направлением развития информационных технологий [5, C.164]. Как упоминалось выше, сам термин появился в 1998 году, но массовый интерес к данному явлению существенно вырос именно в последние несколько лет [3, C. 3]. И связано это, прежде всего, с развитием интернет технологий, а также с развитием технологий в части возможности хранения и обработки данных [3, C. 3]. Вместе с тем, актуализировался вопрос методологии анализа качественных характеристик объектов исследования в социальных и общественных науках. Если в точных науках, всегда превалировали количественные характеристики с дальнейшей их обработкой с помощью математического аппарата, то в нынешних условиях, математический аппарат в концепции Больших данных используется для обработки качественных характеристик объектов [2, C. 38].
Западные компании и государства начали исследовать и разрабатывать подходы к большим данным уже в «нулевые» годы 21 века [9, C. 117], [6 C. 78]. Россия не является исключением: в 2017 году утверждена программа «Цифровая экономика Российской Федерации» до 2024 года [5, C. 165]. В нормативных документах России определено понятие обработки больших объемов данных, под которым понимается совокупность подходов, инструментов и методов автоматической обработки информации из большого количества источников, которую невозможно обработать вручную за ограниченное время [6, C. 78].
Стоит отметить, что некоторые авторы, занимающиеся вопросами больших данных, склоняются к мнению, что в целом технологии обработки Big Data в экономическом анализе пока еще не дошли до России в полной мере. Использование этой концепции в России пока только ограничивается пилотными проектами и апробацией в отдельных отраслях. Те же лидеры в данной области – телекоммуникационные, банковские структуры [8, C. 81]. Например в США уже в 2008 году был запущен масштабный проект, связанный с большими данными [9, C. 117]. В то время, как в России цифровизация экономики принята на государственном уровне почти 10 лет спустя. Исследователи выражают мнение, что главными проблемами развития направления обработки «больших данных» в России являются:
- Нехватка квалифицированных кадров и отсутствие достаточного опыта. В России не сформировалось экспертное сообщество аналитиков в области «больших данных», не появились как квалифицированный и мотивированный заказчик, так и компетентный исполнитель. Отсутствуют специалисты, которые одинаково хорошо владеют как отраслевой спецификой, так и методикой – подходами, инструментами и методами обработки больших данных. [8, C. 81]
- Отсутствие практики накопления «больших данных» и низкое качество этих данных в российских компаниях. Зачастую такие данные хаотично накапливаются российскими компаниями и находятся в состоянии, не пригодном для анализа и получения выгоды (в них присутствует значительный процент искажений и недостаточная глубина). [8, C. 82].
- Невозможность получить ожидаемый положительный результат от больших данных, так как многие компании используют унаследованные реляционные системы управления базами данных, а в них не хватает масштабируемости и функциональности. Ведь основной объем данных – это неструктурированная информация. Ее хранение и обработка на основе реляционных баз данных малоэффективна [1, C. 56].
Тем не менее, уже сегодня экспертное сообщество, задумывается о применении больших данных в вопросах оплаты труда. Примерами могут служить публикации в периодических изданиях по темам: «Управление персоналом на основе анализа больших данных: риски и возможности», «Влияние современных технологий на рынок труда», «BIG DATA: новый подход формирования бизнес-знаний» [11], [10], [3].
Применение Больших данных в вопросах систем оплаты труда
В вопросах систем оплаты в рамках концепции Больших данных нужно решить 2 главных вопроса:
- Как «добывать» данные. В теории Больших данных этот раздел называется «data mining» и является, по сути, вопросом номер один [3, C. 5]. Если, например, у сотовых компаний нет проблем с получением больших данных, так как вся информация идёт по телекоммуникационным каналам, то в вопросах оплаты труда таких каналов нет.
- Как обрабатывать и использовать Большие данные. Опять же, применение Больших данных в некоторых сферах весьма очевидна, в то время как полезные знания в системах оплаты труда несколько расплывчаты.
Первый вопрос – вопрос «добычи» больших данных. Как было отмечено выше, в России вопрос Больших данных стал активно развиваться лишь несколько лет назад, и очевидно, что он будет прорабатываться в первую очередь в стратегически важных сферах: медицина, разведка, правоохранительная деятельность и так далее. Кроме того факта, что Большие данные, применимые к вопросу систем оплаты труда не являются приоритетными, существует также большая сложность в непосредственном сборе таких данных. В идеальной ситуации, на миллионах предприятий должна функционировать отлаженная система сбора и обработки управленческой информации. Причем, в подавляющем большинстве случаев такие данные генерируются автоматически без какого-либо участия человека, что и является отличительной особенностью сбора Больших данных [3, C. 5]. В связи с этими обстоятельствами, на данный момент, получать Большие данные такого рода представляется возможным лишь с помощью имитационного моделирования, которое является весьма ценным инструментом для работы с Большими данными [4, C. 229].
Так же стоит сделать ряд пояснений по концепции Больших данных. Точность данных требует тщательной проверки. Но точность нужна для небольших объемов информации и в некоторых случаях, безусловно, необходима. В то время как в мире больших данных абсолютная точность невозможна, а порой и нежелательна. Если оперировать данными, большая часть которых постоянно меняется, строгая точность уходит на второй план [4, C. 227]. В Ситуации данных систем оплаты труда это благоприятный факт. Особенно, если принимать во внимание то, что данные обрабатываются в очень большом объеме, можно снизить требования к их точности. Когда возможность измерения ограничена, подсчитываются только самые важные показатели, и стремление получить точное число вполне целесообразно. До недавнего времени все цифровые инструменты были основаны на точности: считалось, что СУБД должны извлекать записи, идеально соответствующие запросам [4, C. 227].
Второй вопрос – обработка и применение Больших данных, полученных с помощью имитационного моделирования. Качественных показателей в вопросе систем оплаты труда не так много (см. таблицу 1), поэтому обработка данных может проходить с использованием методов ТВиМС (Теории вероятности и математической статистики), особенно ценен регрессионный анализ - набор статистических методов для выявления закономерности между изменением зависимой переменной и одной или несколькими независимыми [4, C. 229]. В итоге, мы считаем, что самый ценный продукт анализа Больших данных в сфере систем оплаты труда – это прогнозная аналитика, или предиктивный анализ данных. Это метод анализа данных, концентрирующийся на прогнозировании будущего поведения объектов и субъектов с целью принятия оптимальных решений [7, C. 15]. Главные знания в вопросах систем оплаты труда, которые можно получить с помощью Больших данных:
- Установление четких взаимосвязей выработки, качества, удовлетворенности трудом и заработной платы в зависимости от функционирующей системы оплаты труда на предприятии.
- Какую систему оплаты труда стоит выбрать на предприятии, при заданных уровнях выработки, качества, удовлетворенности трудом и размера заработной платы.
- Предсказание с высокой долей вероятности последствий изменения параметров систем оплаты труда на предприятии.
Заключение
Система оплаты труда на любом предприятии является чрезвычайно важной составляющей, регулирующей экономические отношения работника и работодателя. К сожалению, сам вопрос «оплаты труда» является весьма тонким и противоречивым. Поставить точку в вопросе «справедливости» оплаты труда в ряд ли удастся, но приблизиться к этому позволят лишь новые высокие технологии, такие как Big Data (Большие данные). На данный момент однозначно можно сделать выводы:
- Технологии сбора, анализа и обработки Больших данных в области труда и, в частности, оплаты труда, систем оплаты труда, позволят получить совершенно новые знания и теории.
- Процесс развития сбора и обработки Больших данных в России только начался.
- Имитационное моделирование сегодня – единственно возможный способ получить и обработать Большие данные в области систем оплаты труда.
- Анализ моделей систем оплаты труда позволит прежде всего установить взаимосвязь выработки, качества, удовлетворенности трудом и заработной платы в зависимости от функционирующей системы оплаты труда на предприятии.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References
- Абдыкаримова А.Т. BIG DATA: проблемы и технологии / Абдыкаримова А.Т. // Международный журнал гуманитарных и естественных наук. 2019.№5-1. С. 55-57.
- Али-Заде А.А. «Большие данные» и методология общественных наук / Али-Заде А.А. // Социальные и гуманитарные науки. Отечественная и зарубежная литература. Серия 8: Науковедение. Реферативный журнал. 2018.№3. С. 37-53.
- Голиков В.А. BIG DATA - новый подход формирования бизнес-знаний / Голиков В.А. // Известия Тульского государственного университета. Экономические и юридические науки. 2018.№2-1. С. 3-7
- Денисова О.Ю. Большие данные - это не только размер данных / Денисова О.Ю., Мухутдинов Э.А. // Вестник Технологического университета. 2015. Т. 18.№4. С. 226-230.
- Закусилова А.Ю. BIG DATA: опасности и перспективы / Закусилова А.Ю. // Международный журнал прикладных наук и технологий Integral. 2019.№4-1. С. 21.
- Каращук О.С. "Большие данные" и перспективы их использования в предпринимательской деятельности / Каращук О.С., Майорова Е.А., Прохоров Ю.Н. // Вестник НГИЭИ. 2018.№10 (89). С. 77-87.
- Медведев Д.А. Большие данные: причины появления и как их можно использовать / Медведев Д.А. / Наука и образование сегодня. 2019.№4 (39). С. 14-16.
- Митрович С. Рынок "Больших данных" и их инструментов: тенденции и перспективы в России / Митрович С. // МИР (Модернизация. Инновации. Развитие). 2018. Т. 9.№1. С. 74-85.
- Нигматова А.В. Опыт гос. управления "большими данными" в США / Нигматова А.В. // Вестник науки и образования. 2018.№17-1 (53). С. 117-119.
- Петров С.К. Влияние современных технологий на рынок труда / Петров С.К. // Проблемы науки. 2018.№5 (29). С. 74-75.
- Попазова О.А. Управление персоналом на основе анализа больших данных: риски и возможности / Попазова О.А., Шихова Н.Н. // Известия Санкт-Петербургского государственного экономического университета. 2019.№3 (117). С. 110-115.
- Россия в цифрах. 2018: Крат.стат.сб./Росстат- M., Р76 2018 - 522 с.
- Федоренко Н.С. Большие данные. подходы к толкованию термина / Федоренко Н.С., Хрусталев В.И. // E-Scio. 2018.№6 (21). С. 61-63.
Список литературы на английском языке / References in English
- Abdykarimova A.T. BIG DATA: problemy i tekhnologii [BIG DATA: Problems and Technologies] / Abdykarimova A.T.// Mezhdunarodnyy zhurnal gumanitarnykh i yestestvennykh nauk [International Journal of Humanities and Natural Sciences]. – 2019. – No. 5-1. – P. 55-57. [in Russian]
- Ali-Zade A.A. «Bolshie dannye» i metodologiya obshchestvennykh nauk [Big Data and Social Sciences Methodology] / Ali-Zade A.A. // Sotsial'nyye i gumanitarnyye nauki. Otechestvennaya i zarubezhnaya literatura. Seriya 8: Naukovedeniye. Referativnyy zhurnal [Social and Human Sciences. Domestic and Foreign Literature. Series 8: Study of Science. Abstract Journal]. – 2018. – No. 3. – P. 37-53. [in Russian]
- Golikov V.A. BIG DATA – novyi podkhod formirovaniya biznes-znanii [BIG DATA - New Approach to Building Business Knowledge] / Golikov V.A. // Izvestiya Tul'skogo gosudarstvennogo universiteta. Ekonomicheskiye i yuridicheskiye nauki [Bulletin of Tula State University. Economic and Legal Sciences]. – 2018. – No. 2-1. – P. 3-7 [in Russian]
- Denisova O.Yu. Bolshie dannye - eto ne tolko razmer dannykh [Big Data is More than Just Data Size] / Denisova O.Yu., Mukhutdinov Ye.A. // Vestnik Tekhnologicheskogo universiteta [Bulletin of the Technological University]. – 2015. – Vol. 18. – No. 4. – P. 226-230. [in Russian]
- Zakusilova A.Yu. BIG DATA: opasnosti i perspektivy [BIG DATA: Dangers and Prospects] / Zakusilova A.Yu. // Mezhdunarodnyy zhurnal prikladnykh nauk i tekhnologiy Integral [International Journal of Applied Sciences and Technology “Integral.”] – 2019. – No 4-1. – P. 21. [in Russian]
- Karashchuk O.S. "Bolshie dannye" i perspektivy ikh ispolzovaniya v predprinimatelskoi deyatelnosti [Big Вata and the Prospects for their Use in Business] / Karashchuk O.S., Mayorova E.A., Prokhorov Yu.N. // Vestnik NGIEI [Bulletin of the NSEEI]. – 2018. – No 10 (89). – P. 77-87. [in Russian]
- Medvedev D.A. Bolshie dannye: prichiny poyavleniya i kak ikh mozhno ispolzovat [Big Data: Causes of their Occurrence and How to Use them] / Medvedev D.A. // Nauka i obrazovaniye segodnya [Science and Education Today]. – 2019. – No. 4 (39). – P. 14-16. [in Russian]
- Mitrovich S. Rynok "Bolshikh dannykh" i ikh instrumentov: tendentsii i perspektivy v Rossii [Big Data Market and its Instruments: Trends and Prospects in Russia] / Mitrovich S. // MIR (Modernizatsiya. Innovatsii. Razvitiye) [MIR (Modernization. Innovation. Development).] – 2018. – Vol. 9. – No. 1. – P. 74-85. [in Russian]
- Nigmatova A.V. Opyt gos. upravleniya "bolshimi dannymi" v SShA [Experience of Big Data State Management in the USA] / Nigmatova A.V. // Vestnik nauki i obrazovaniya [Bulletin of Science and Education]. – 2018. – No. 17-1 (53). – P. 117-119. [in Russian]
- Petrov S.K. Vliyanie sovremennykh tekhnologii na rynok truda [Impact of Modern Technology on the Labour Market] / Petrov S.K. // Problemy nauki [Problems of Science]. – 2018. – No. 5 (29). – P. 74-75. [in Russian]
- Popazova O.A. Upravlenie personalom na osnove analiza bolshikh dannykh: riski i vozmozhnosti [HR Management Based on Big Data Analysis: Risks and Opportunities] / Popazova O.A., Shikhova N.N. // Izvestiya Sankt-Peterburgskogo gosudarstvennogo ekonomicheskogo universiteta [News of St. Petersburg State University of Economics]. – 2019. – No. 3 (117). – P. 110-115. [in Russian]
- Rossiya v tsifrakh. 2018: Krat.stat.sb. [Russia in Numbers. 2018: Short Stat. Coll.] / Federal State Statistics Service – M., P76 2018 - 522 p. [in Russian]
- Fedorenko N.S. Bolshie dannye: podkhody k tolkovaniyu termina [Big Data: Approaches to Term Interpretation] / Fedorenko N.S., Khrustalev V.I. // E-Scio. – 2018. – No. 6 (21). – P. 61-63. [in Russian]