THE STUDY OF THE PEROVSKITE SOLAR CELL PARAMETER INFLUENCE ON THEIR EFFICIENCY BY USING MACHINE LEARNING
THE STUDY OF THE PEROVSKITE SOLAR CELL PARAMETER INFLUENCE ON THEIR EFFICIENCY BY USING MACHINE LEARNING
Abstract
This paper presents an approach to optimize perovskite solar cells (PSC) by using machine learning algorithms. The aim of the study is to find the best PSC parameters that provide high power conversion efficiency (PCE). To train the algorithms, the dataset with PSC feature information (the perovskite layer thickness, the electron transport layer type, the target variables, etc.) was created. Various machine learning algorithms were applied, the XGBoosting, CatBoost and Random Forest showed the low error in both learning stages (regression where the target variable is PCE, multi-target regression where the four variables are PCE, Voc, Jsc and FF as well). The most important variables for PCE are Voc, Jsc and FF, the less important ones – Pero th, ETL, Cs, MA, FA, I and HTL.
1. Введение
Машинное обучение становится все более популярным инструментом для исследований в области материаловедения. При помощи методов машинного обучения можно оптимизировать поиск исходных структур соединений, что способствует созданию новых материалов с определёнными свойствами, их улучшению, ускорению процесса разработки новых инновационных решений, сокращению затрат ресурсов и времени на исследование
, , , , . Перовскиты – класс материалов с широким спектром потенциальных применений, включая солнечные батареи, светодиоды, детекторы и др. , , , , . В данной работе рассматривается применение алгоритмов машинного обучения для решения задачи поиска наилучших параметров для получения соединения с высокой эффективностью преобразования энергии (PCE).2. Методы и принципы исследования
Набор данных для обучения алгоритмов машинного обучения для решения задачи поиска наилучших параметров для получения соединения с высокой эффективностью (PCE) был получен при помощи моделирования PSC различной архитектуры (зарядовые слои, перовскиты, толщины перовскитного слоя) в программном пакете SCAPS
.Перед непосредственной настройкой алгоритмов и их обучением требуется предварительная обработка набора данных, поскольку полученный набор имеет пропуски в данных. На рисунке 1 представлен фрагмент датасета после обработки.
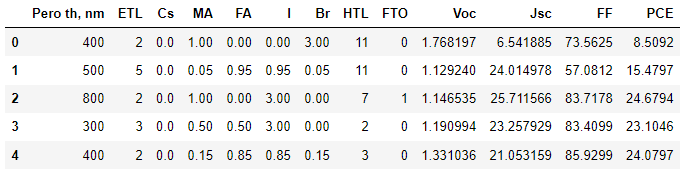
Рисунок 1 - Фрагмент датасета
Примечание: Примечание: Pero th, nm – толщина перовскитного слоя, нм; ETL – тип электронно-транспортного слоя; Cs – количество Cs в А-положении; MA – количество MA в А-положении, FA – количество FA в А-положении, I – количество йода в Х-положении, Br – количество брома в Х-положении, HTL – тип дырочно-транспортного слоя, FTO – присутствие слоя FTO, Voc – напряжение холостого хода, Jsc – ток короткого замыкания, FF – фактор заполнения, PCE – эффективность преобразования энергии
Таблица 1 - Кодировка типов зарядово-транспортных слоёв
Тип ETL | Номер в датасете | Тип HTL | Номер в датасете |
PCBM | 1 | C60 | 1 |
TiO2 | 2 | Cu2O | 2 |
ZnO | 3 | CuI | 3 |
CdS | 4 | Spiro-OMeTAD | 4 |
WO3 | 5 | CuSCN | 5 |
WS2 | 6 | NiO | 6 |
IGZO | 7 | P3HT | 7 |
SnO2 | 8 | CuSbS2 | 8 |
– | – | PEDOT:PSS | 9 |
– | – | CuO | 10 |
– | – | MoO3 | 11 |
Обучение было разбито на два этапа:
1. Решение задачи регрессии (несколько признаков и одна целевая переменная).
2. Решение задачи многоцелевой регрессии (несколько признаков и несколько целевых переменных).
Всего получилось 7182 объекта, которые будут анализироваться по 12 признакам ('Pero th', 'ETL', 'Cs', 'MA', 'FA', 'I', 'Br', 'HTL’, ’FTO’, 'Voc', 'Jsc', 'FF') и 1 целевой переменной ('PCE') для первого этапа, а также по 9 признакам ('Pero th', 'ETL', 'Cs', 'MA', 'FA', 'I', 'Br', 'HTL', ‘FTO’) и 4 целевым переменным ('Voc', 'Jsc', 'FF', 'PCE'), значение которых и будут предсказываться на втором этапе.
Перед загрузкой данных в алгоритм была построена тепловая карта взаимокорреляций Пирсона для признаков (см. рис. 2). Корреляция – важнейший фактор, лежащий в основе анализа данных. Он сообщает, как переменные в наборе данных связаны друг с другом.
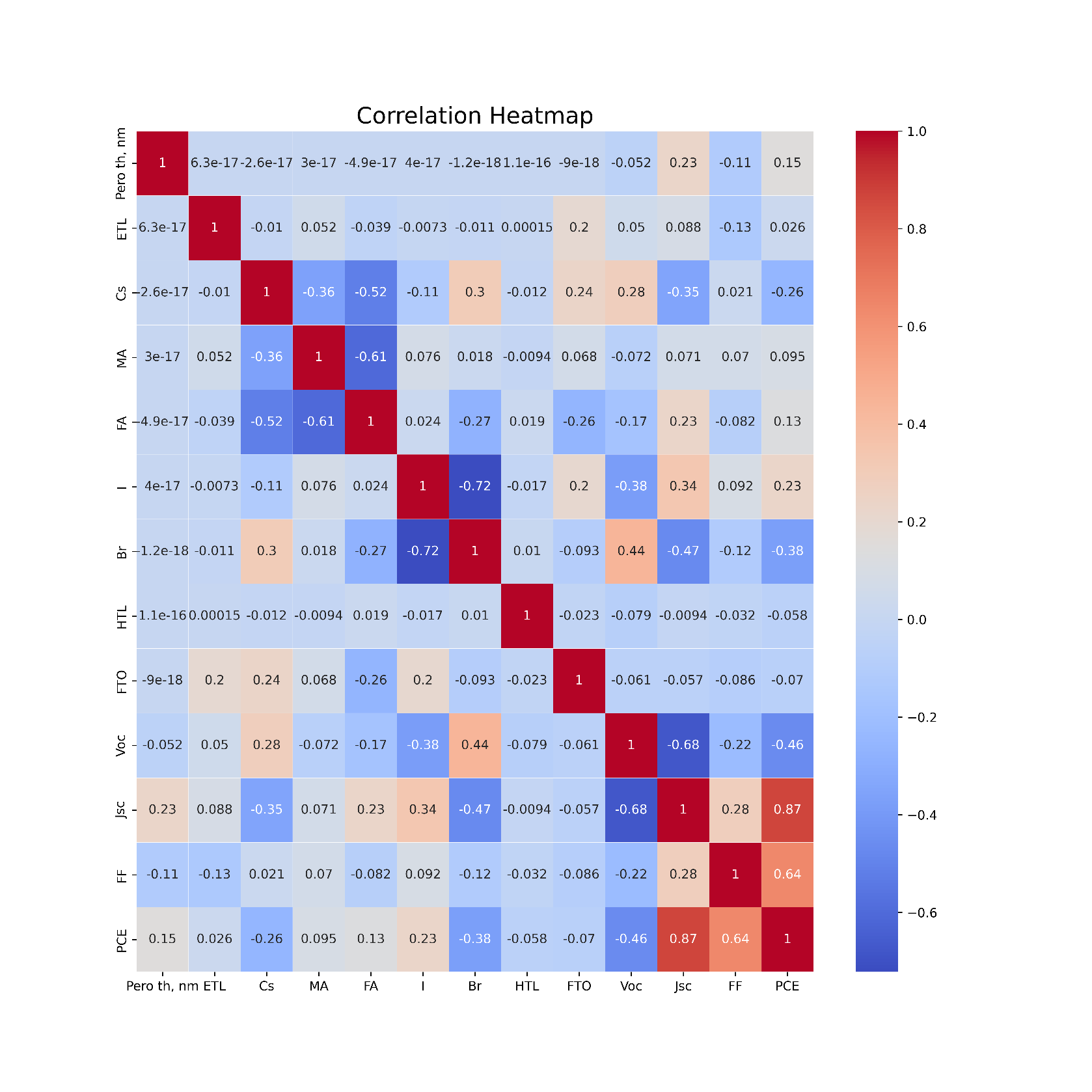
Рисунок 2 - Тепловая карта матрицы корреляции признаков и целевых переменных
Согласно рисунку 3 сильная корреляция (больше 0,6) со значениями целевых переменных наблюдается у следующих признаков: HTL, Cs, MA, FA, I, Br.
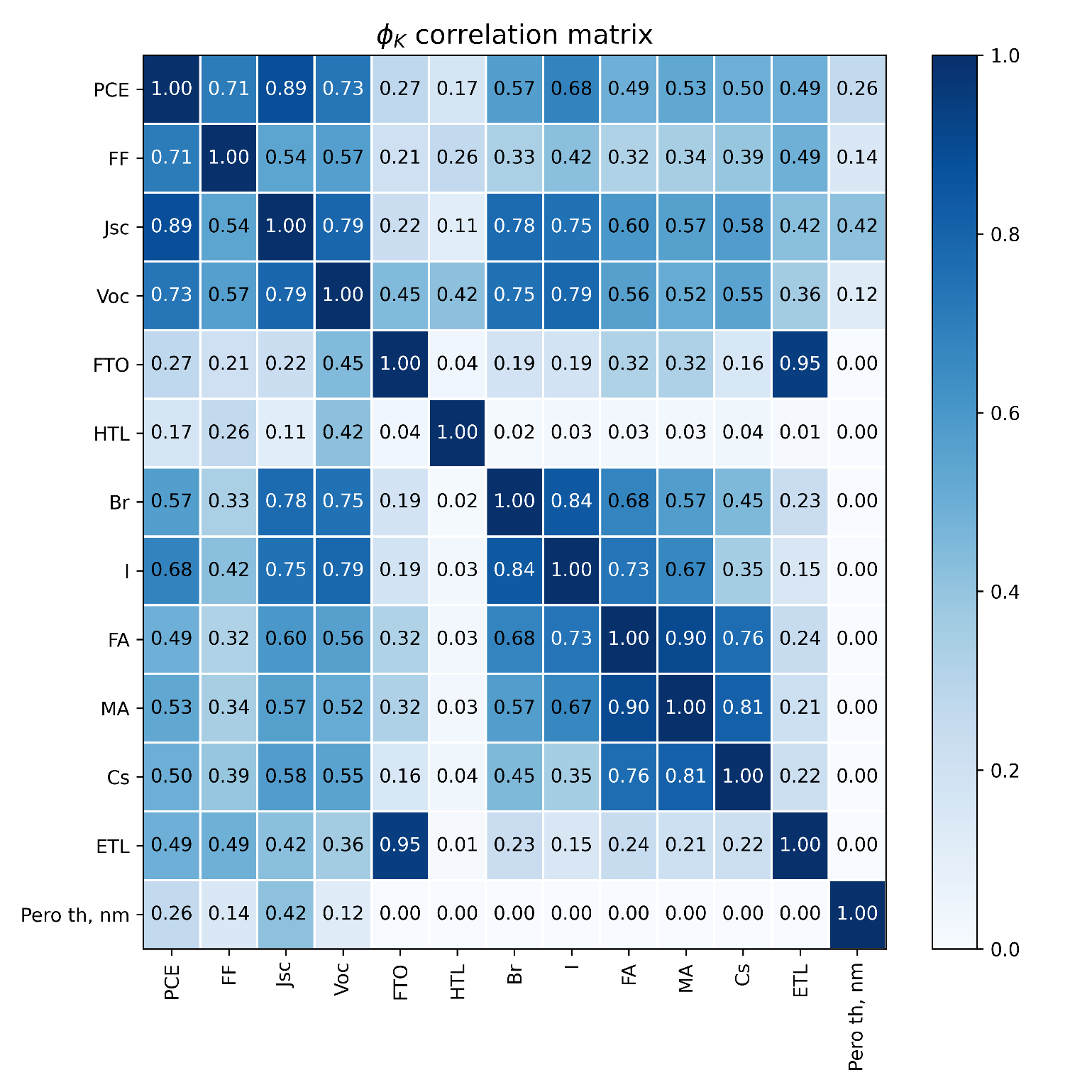
Рисунок 3 - Матрица коэффициентов корреляции φk
Для определения значимости, необходимо учесть значение p-критерия. Значение p менее 0,05 обычно считается статистически значимым, и в этом случае нулевую гипотезу следует отклонить на взятом уровне значимости, то есть связь между двумя наблюдаемыми событиями существует. Значение p больше 0,05 означает, что нулевая гипотеза не отвергается, следовательно, не существует связи между двумя наблюдаемыми событиями.
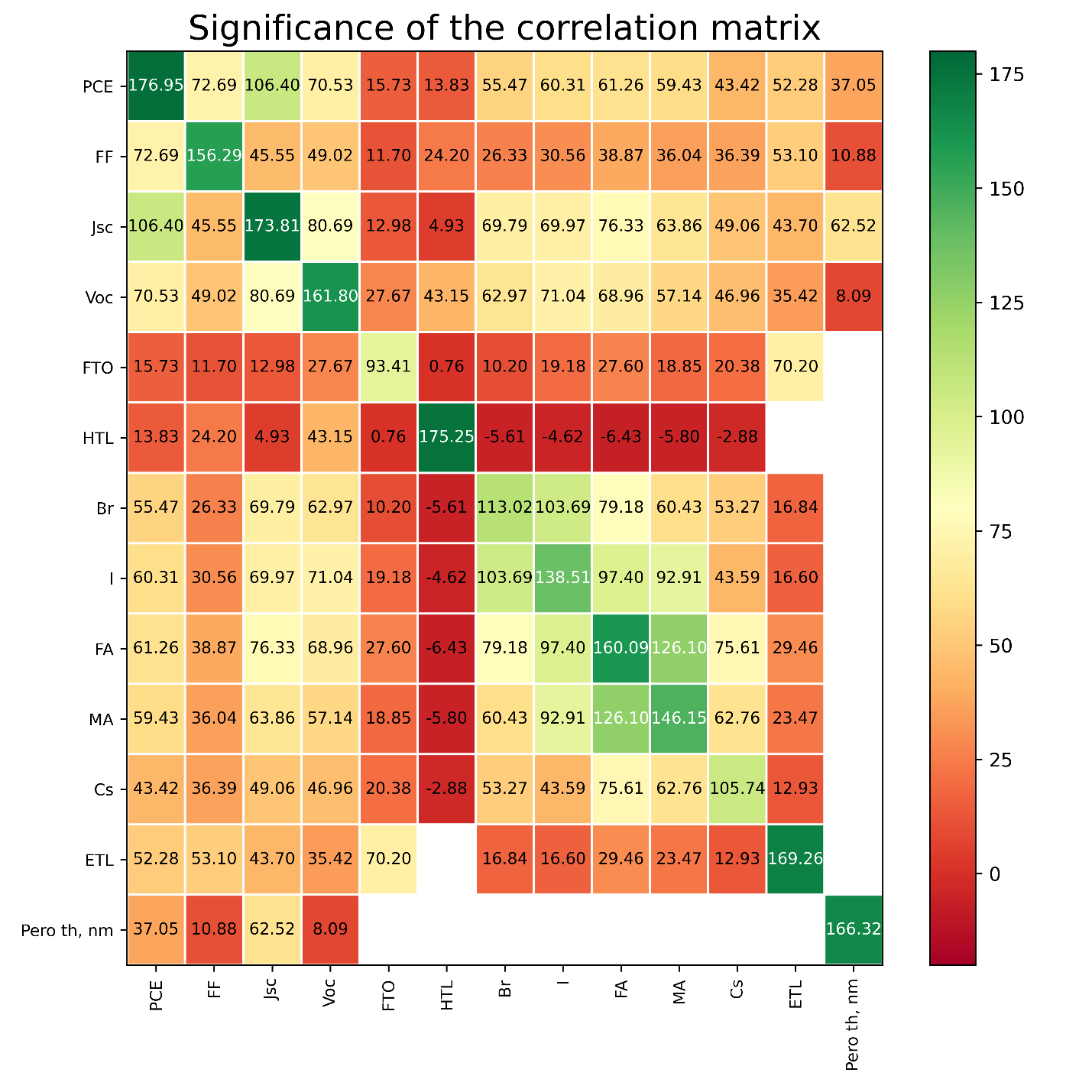
Рисунок 4 - Значимость корреляции
В качестве алгоритмов машинного обучения применялись не только базовые алгоритмы, такие как линейная регрессия (англ. Linear Regression), К-ближайших соседей (англ. K-Nearest Neighbors), метод опорных векторов (англ. Support vector Machine), дерево решений (англ. Decision Tree), но и современные ансамблевые методы, такие как случайный лес (англ. Random Forest) и методы основанные на бустинге (англ. Extreme Gradient Boosting (XGBoosting), Light Gradient Boosting Machine (LightGBM), Gradient Boosting Regressor). Для тонкой настройки алгоритмов, а также для борьбы с переобучением необходимо использовать разбиение набора данных на обучающую и тестовую выборки, кросс-валидацию, различные регуляризации, масштабирование признаков, подбор гиперпараметров при помощи метода GridSearchCV и другие приемы для увеличения обобщающей способности алгоритмов. В результате на основе выбранных алгоритмов можно будет оценить важность выбранных признаков, а также оценить точность алгоритмов по метрикам средняя квадратичная ошибка (англ. mean squared error, MSE) и средняя абсолютная ошибка (англ. mean absolute error, MAE).
Далее представлены результаты обучения алгоритмов, а также важности признаков для первого этапа.
Таблица 2 - Результаты обучения алгоритмов для одноцелевой регрессии
Алгоритм | MSE | MAE |
Support Vector Machine | 1,63 | 0,93 |
Linear Regression | 1,56 | 0,92 |
Ridge | 1,88 | 1,05 |
Lasso | 3,86 | 1,54 |
K-nearest neighbors | 0,75 | 0,54 |
Decision Tree | 0,16 | 0,22 |
Random Forest | 0,05 | 0,14 |
XGBoosting | 0,04 | 0,15 |
LightGBM | 0,05 | 0,16 |
CatBoost | 0,02 | 0,10 |
Gradient Boosting | 0,15 | 0,30 |
Исходя из данных таблицы 2, низкую ошибку показали ансамблевые методы (Random Forest и методы, основанные на бустинге).
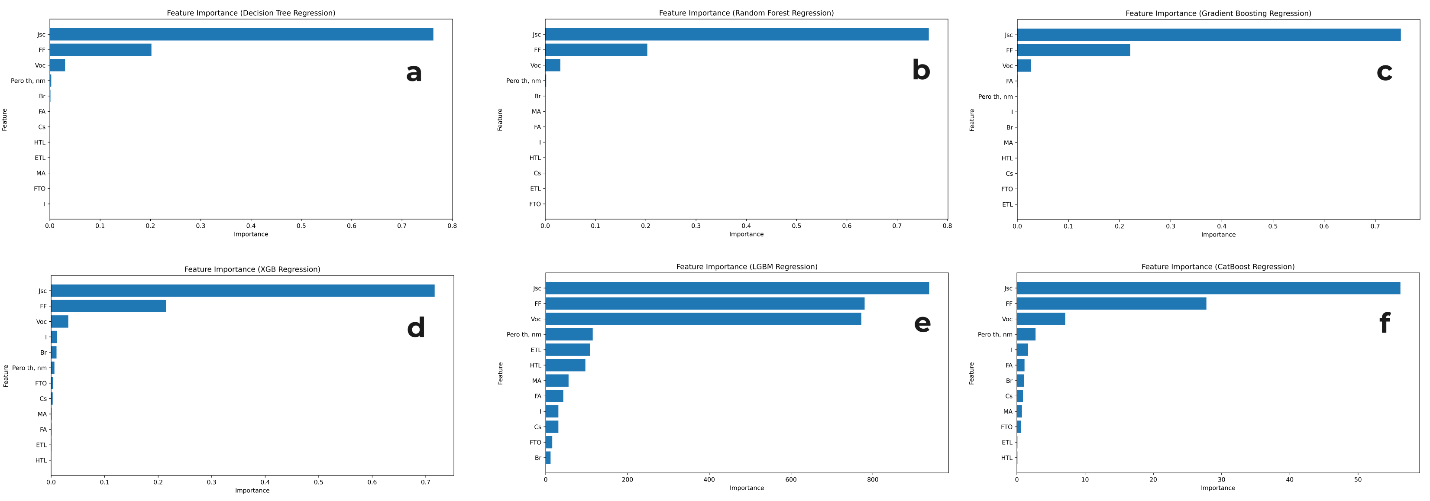
Рисунок 5 - Важность признаков в алгоритмах
Примечание: Примечание: a – decision tree regression, b – random forest regression, c – gradient boosting regression, d – xgboosting regression, e – lightgbm regression, f – catboost regression
Далее представлены результаты обучения алгоритмов для второго этапа.
Таблица 3 - Результаты обучения алгоритмов для многоцелевой регрессии
Алгоритм | MSE | MAE | ||||||
Voc | Jsc | FF | PCE | Voc | Jsc | FF | PCE | |
SVM | 0,05 | 62,07 | 271,67 | 58,65 | 0,15 | 5,61 | 10,83 | 6,52 |
Linear Regression | 0,04 | 39,34 | 205,79 | 48,39 | 0,14 | 4,65 | 11,72 | 5,75 |
Ridge | 0,04 | 39,34 | 205,79 | 48,40 | 0,14 | 4,65 | 11,72 | 5,74 |
Lasso | 0,05 | 43,55 | 212,35 | 50,66 | 0,17 | 5,27 | 12,10 | 6,05 |
KNN | 0,03 | 22,52 | 127,06 | 22,75 | 0,11 | 3,29 | 8,45 | 3,72 |
Decision Tree | 0,02 | 8,02 | 135,05 | 18,12 | 0,09 | 2,24 | 8,53 | 3,37 |
Random Forest | 0,00 | 0,11 | 4,96 | 0,48 | 0,01 | 0,18 | 1,19 | 0,43 |
XGBoosting | 0,00 | 0,05 | 4,96 | 0,21 | 0,01 | 0,12 | 1,45 | 0,32 |
LightGBM | 0,00 | 0,15 | 11,84 | 0,67 | 0,02 | 0,22 | 2,21 | 0,58 |
CatBoost | 0,00 | 0,06 | 6,29 | 0,31 | 0,01 | 0,13 | 1,64 | 0,37 |
Gradient Boosting | 0,00 | 0,98 | 43,85 | 4,37 | 0,05 | 0,68 | 5,20 | 1,59 |
Исходя из данных табл. 3, самые низкие значения ошибки показали следующие алгоритмы: XGBoosting, CatBoost и Random Forest.
3. Заключение
В работе были применены методы машинного обучения для поиска наилучших параметров PSC с высоким PCE. Для обучения алгоритмов был создан набор данных, содержащий информацию о PSC, таких как толщина перовскитного слоя, тип электронно-транспортного слоя и т.д., а также целевые переменные: Voc, Jsc, FF и PCE. Были применены различные алгоритмы машинного обучения, включая линейную регрессию, K-ближайших соседей, метод опорных векторов, дерево решений, случайный лес и методы, основанные на бустинге. Результаты показали, что:
1) низкую ошибку на обоих этапах обучения показали XGBoosting, CatBoost и Random Forest;
2) наибольшую важность для PCE имеют такие параметры, как Voc, Jsc и FF;
3) дополнительными важными параметрами, в меньшей степени влияющими на PCE, являются Pero th, ETL, Cs, MA, FA, I и HTL.
Данная работа демонстрирует потенциал применения машинного обучения для оптимизации PSC и может быть использована для ускорения разработки новых материалов с высокой PCE.