The practical significance of interval estimates: the shift from ‘point forecasts’ to ‘range forecasts’ on the example of NDVI analysis in Khabarovsk Krai
The practical significance of interval estimates: the shift from ‘point forecasts’ to ‘range forecasts’ on the example of NDVI analysis in Khabarovsk Krai

Abstract
The article examines the issue of uncertainty in forecasts within the context of agricultural monitoring and remote sensing. Traditional point estimates, despite their widespread use, do not account for measurement errors or the inherent variability of natural processes, which can lead to erroneous management decisions. The necessity of moving from a ‘point forecast’ paradigm to a ‘range forecast’ one using interval analysis methods is substantiated. A comparative analysis of five interval regression methods is carried out on the example of data from the VEGA-Science satellite service for Khabarovsk Krai: the centroid method, the minimax method, the centroid and radius method, and linear and parameterised models. Computational experiments on synthetic and real data demonstrate that more complex methods are effective under controlled uncertainty, whereas on real data with instrumental errors, the minimax method yields the best results. Particular attention is paid to forecasting time series of the NDVI vegetation index based on long-term observations. It has been demonstrated that the use of historical intervals (5–10 years) allows for the construction of forecast ranges that, with a high probability, encompass the actual values, even when using relatively simple approximation functions. The obtained results confirm that the interval approach is not just a mathematical refinement, but an essential tool for improving the reliability of forecasts and risk assessments in agriculture and environmental monitoring.
1. Введение
Традиционные методы прогнозирования в науках о Земле, включая агрометеорологию и экологический мониторинг, долгое время оперировали точечными оценками. Исследователь, получив значение вегетационного индекса NDVI, равное 0,77, или прогноз урожайности 45 ц/га, склонен воспринимать эти числа как истинные. Однако любое измерение содержит погрешность, а любой прогноз — неопределенность. Точечная оценка, будучи «наилучшим предположением» модели, не дает представления о том, насколько этому предположению можно доверять.
В данной работе рассматривается переход от парадигмы точечного прогнозирования к интервальному, когда результат представляется не одним числом, а диапазоном значений — «коридором прогноза». Этот подход, опирающийся на методы интервального анализа, позволяет учитывать как инструментальные погрешности измерений, так и естественную вариабельность геофизических процессов.
Интервальный прогноз представляет собой диапазон значений, который покрывает истинное значение прогнозируемой переменной. В отличие от точечного прогноза, который собирает всю информацию в одно число, интервальный прогноз явным образом количественно оценивает неопределенность .
Точечный прогноз обладает существенным недостатком — он скрывает неопределенность модели. Например, прогноз температуры 25°C не дает информации о том, может ли реальная температура колебаться в диапазоне 20–30°C. В системах высокой ответственности (управление сельскохозяйственным производством, прогнозирование урожайности, оценка рисков засухи) отсутствие оценки надежности прогноза может приводить к критическим ошибкам. Исследования показывают, что волатильность исходных данных увеличивает смещение в точечных прогнозах, но не влияет на смещение в интервальных прогнозах . Более того, усреднение двух точечных прогнозов снижает шум до уровня, характерного для интервального прогнозирования.
Применительно к задачам дистанционного зондирования и агромониторинга интервальный подход приобретает особую значимость. Измерения температуры, осадков и вегетационных индексов всегда сопровождаются погрешностями. В соответствии с нормативными документами и научными исследованиями:
– температура воздуха измеряется с точностью ±0,5 °С ;
– количество осадков — с относительной погрешностью 3–7% ;
– значение NDVI — с погрешностью порядка ±0,005 .
Если эти погрешности игнорировать и оперировать только точечными значениями, итоговая модель может создавать ложное впечатление точности там, где ее нет. Интервальный анализ предлагает иной подход: вместо попыток угадать будущее значение показателя определяется допустимое множество возможных значений.
2. Методы и принципы исследования
Интервалом называют множество вещественных чисел, расположенных между двумя числами — границами интервала:
где
Важнейшими характеристиками интервала, помимо его границ, также являются его середина (центр), ширина и радиус :
Целью регрессионного анализа является описание зависимости исследуемого показателя от одного или нескольких факторов в виде функции . В случае интервального анализа каждое значение как исследуемого показателя, так и факторов является интервальным. Рассмотрим основные методы нахождения коэффициентов регрессии для интервальных данных .
В методе центров для вычисления вектора коэффициентов используются центры интервалов зависимой и независимых переменных:
где
Полученные значения используются для оценки нижней и верхней границ:
Метод достаточно прост в применении. Сначала интервальные значения заменяются точечными, путем вычисления середины интервалов, а после используется стандартный способ нахождения коэффициентов для множественной линейной регрессии. Однако у данного метода есть большой недостаток — зачастую нижняя граница может оказаться больше верхней, что недопустимо.
В отличие от предыдущего метода, в методе минимакса коэффициенты для оценки нижней и верхней границ вычисляются по отдельности следующим образом:
Это позволяет более точно описать поведение зависимой переменной, по сравнению с предыдущим методом. Однако метод минимакса обладает тем же недостатком, что и метод центров. Также он неэффективен, если нет четкой зависимости между границами зависимой и независимых переменных.
Метод центров и радиусов является улучшением метода центров. Здесь, помимо центра, берется во внимание радиус интервалов. По формуле (1) вычисляется вектор коэффициентов для центров. Аналогичным образом вычисляется вектор коэффициентов радиусов (соответственно вместо
Затем на основании полученных оценок вычисляются границы:
Данный метод эффективен, если между радиусами зависимой и независимых переменных существует линейная зависимость.
Метод линейной модели учитывает как нижние, так и верхние границы независимых переменных, а также их радиусы для оценки границ зависимой переменной, что значительно повышает его гибкость. Вычисления проводятся в два шага. Сначала находится вектор
где
На втором шаге вычисляются оценки верхней и нижней границ:
Следует уточнить, что отрицательные значения коэффициентов
В отличие от предыдущих методов, где использовались такие конкретные значения, как центр, радиус и границы интервалов, метод параметризованной модели выделяет наилучшие исходные точки из интервалов независимых переменных, на основе которых оцениваются нижняя и верхняя границы зависимой переменной по формулам
Для оценки точности полученных результатов используются известные метрики:
1) среднеквадратическая ошибка (Root Mean Square Error) для левой и правой границ интервалов, вычисляемая по формулам:
2) средняя абсолютная ошибка (Mean Absolute Error) для левой и правой границ интервалов, вычисляемая как
3) средняя величина относительной ошибки (Mean Magnitude of Relative Error), включающая оценку ошибки по верхней и нижней границам,
3. Основные результаты и обсуждение
Пример 1. Модельный (синтетический) набор интервальных данных.
Для проведения вычислительных экспериментов сформированы наборы данных следующей структуры:
– две независимые переменные
– зависимая величина
Все величины являются интервальными. Параметр
В полученные значения вносятся реалистичные шумы (ошибки) для имитации неточности измерений или влияния неучтенных факторов. Тем самым формируются верхние и нижние границы интервала значения интервальной величины. Для
В таблице 1 приведены значения метрик для различных методов регрессионного анализа, полученных при обработке синтетического набора данных.
Таблица 1 - Оценка моделей сгенерированных данных
Метод | | | | | |
Метод центров | 2,345 | 2,408 | 1,7 | 2,408 | 0,0118 |
Метод минимакса | 2,284 | 2,402 | 1,732 | 2,402 | 0,0116 |
Метод центров и радиусов | 2,4 | 2,28 | 1,781 | 2,28 | 0,116 |
Линейная модель | 1,06 | 0,93 | 0,841 | 0,931 | 0,0052 |
Параметризованная модель | 1,04 | 0,92 | 0,838 | 0,916 | 0,0051 |
На сгенерированных данных, где структура неопределенности контролируется, наиболее точные результаты показали линейная модель и параметризованная модель, Линейная модель и параметризованная модель оказались в два раза точнее методов центров и минимакса (RMSE ~1,04 против 2,34). Это демонстрирует, что более сложные методы интервального анализа, учитывающие структуру неопределенности, позволяют существенно повысить точность прогнозов по сравнению с упрощенными подходами, сводящими интервалы к точкам.
Пример 2. Набор данных, полученных по данным спутникового сервиса.
Для исследования использованы данные спутникового сервиса ВЕГА-Science для Хабаровского края за 2023 год . Сервис ВЕГА-Science предоставляет точечные данные о температуре, осадках и NDVI. Индекс NDVI (Normalized Difference Vegetation Index) — это индекс, который служит показателем здоровья растений. С его помощью определяют, сколько активной биомассы в них содержится, поэтому данный показатель активно используется в исследованиях и разработках, связанных с сельским хозяйством, экологией, горным делом и др. Рассчитывается индекс NDVI с помощью значений интенсивности красного и инфракрасного цветов, полученных при анализе мультиспектральных спутниковых снимков.
Данные, полученные от ВЕГА-Science, преобразованы в интервальные с учетом инструментальных погрешностей. Пример такого преобразования показан в таблице 2.
Таблица 2 - Преобразование точечных значений в интервальные
Параметр | Точечное значение | Погрешность | Интервальное представление |
Температура | 2,53 °С | 0,5 °С | [2,03; 3,03] °С |
Осадки | 0,8355 кг/м² | 7% | [0,777; 0,894] кг/м² |
NDVI | 0,293 | 0,005 | [0,288; 0,298] |
Как видно из таблицы, точечные значения представляют собой лишь одну точку внутри интервала возможных значений. Использование только центров интервалов приводит к потере информации о степени неопределенности исходных данных.
В таблице 3 показаны полученные значения метрик для различных методов регрессии. Заметим, что оценки линейной модели отсутствуют. Это связано с тем, что из-за того, что ширина всех интервалов одной из зависимых переменных равна единице, матрица X является вырожденной. В этом случае невозможно вычислить вектор коэффициентов линейной модели. Этот пример наглядно демонстрирует, что переход к интервальному анализу требует не только модификации методов, но и учета специфики данных. В некоторых случаях структура интервальных данных может создавать математические проблемы, не встречающиеся при работе с точечными значениями.
Таблица 3 - Оценка моделей регрессии для реальных данных
Метод | | | | | |
Метод центров | 0,0592 | 0,0616 | 0,0446 | 0,0616 | 0,1048 |
Метод минимакса | 0,0591 | 0,0615 | 0,0451 | 0,0615 | 0,1047 |
Метод центров и радиусов | 0,0595 | 0,0619 | 0,0442 | 0,0619 | 0,1051 |
Линейная модель | - | - | - | - | - |
Параметризованная модель | 0,0707 | 0,0771 | 0,0538 | 0,056 | 0,1342 |
Пример 3. Анализ данных многолетних наблюдений временных рядов NDVI.
В предыдущем примере для получения интервальных значений из точечных использовалась погрешность измерений. Однако интервальное представление данных позволяет учитывать не только погрешности, но и диапазоны значений за определенный временной период, что позволяет обрабатывать данные сразу за несколько лет.
Для демонстрации возможности применения интервалов для анализа многолетних наблюдений использованы данные о значениях NDVI для Хабаровского края c 2014 по 2024 год, полученные с помощью спутникового сервиса ВЕГА-Science.
Проведем регрессионный анализ, используя в качестве исходных интервалов значения NDVI в разные временные периоды. В качестве метода регрессионного анализа выбран метод минимакса, так как данный метод оказался наиболее точным при анализе реальных данных.
Прежде чем приступить к регрессионному анализу многолетних наблюдений, убедимся, что данных за один год было бы недостаточно. Попробуем спрогнозировать значения индекса NDVI на 2024 год, используя точечные данные за предыдущий год. Как видно на рисунке 1, предсказанные значения сильно отличаются от фактических фактическими, следовательно, необходимо расширить временной диапазон.
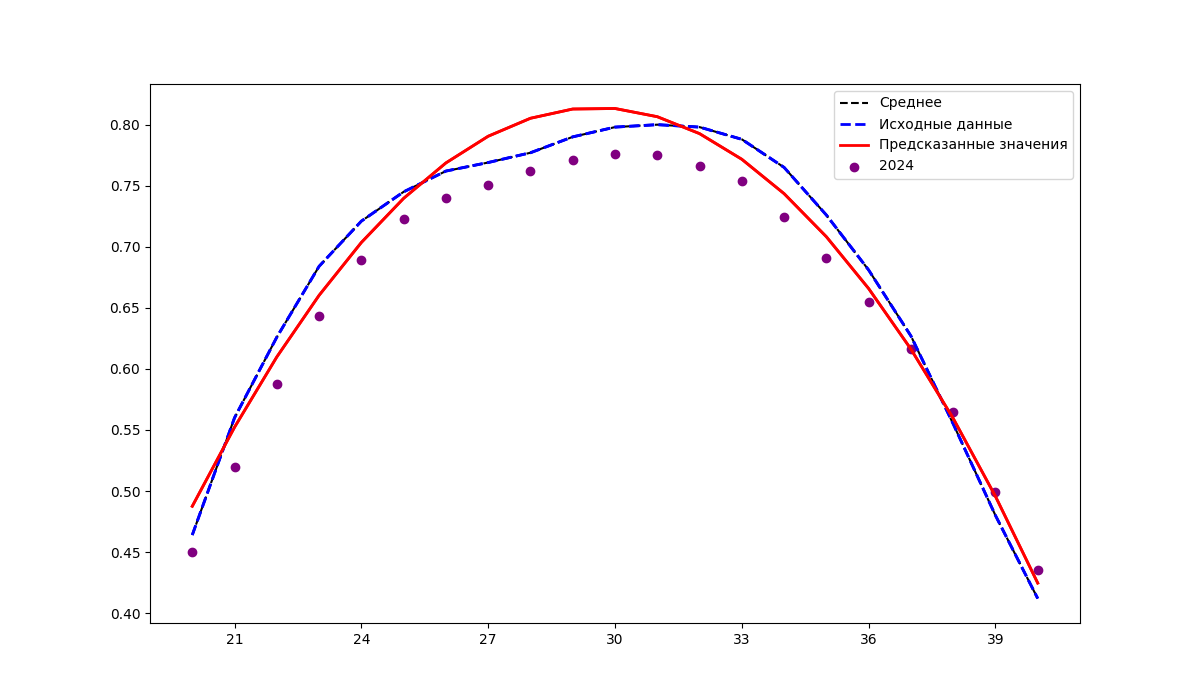
Прогнозирование значений индекса NDVI на 2024 год на основе данных за 2023 год
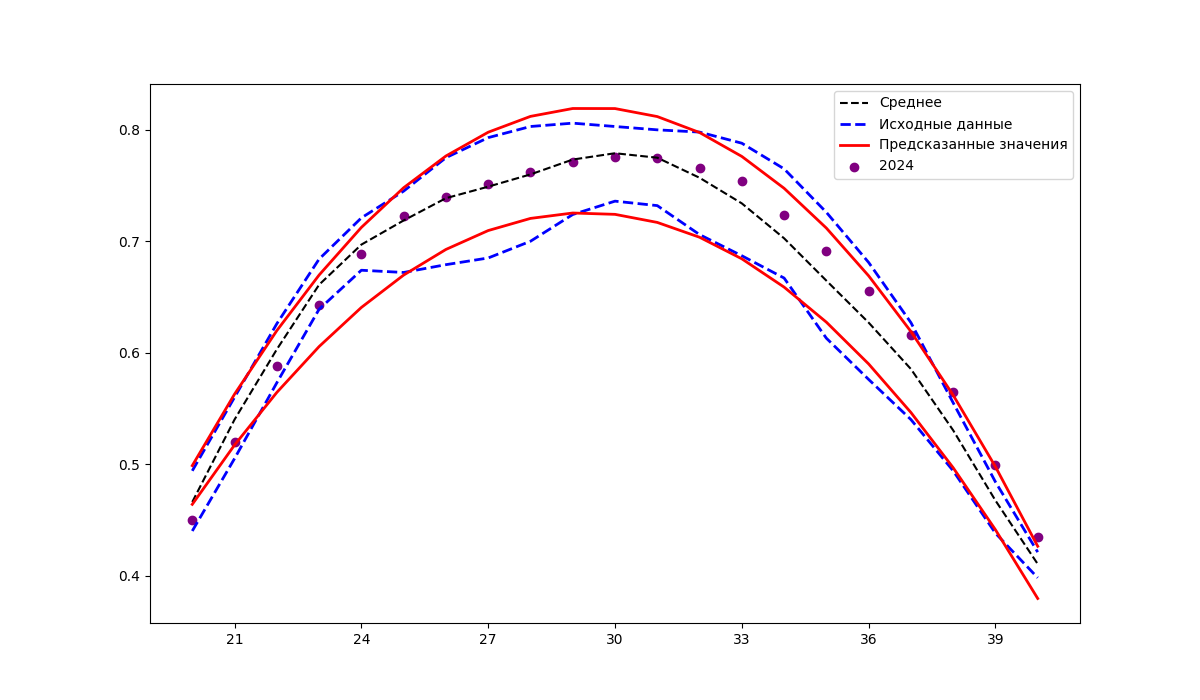
Прогнозирование значений индекса NDVI на 2024 год на основе данных за 2021–2023 года
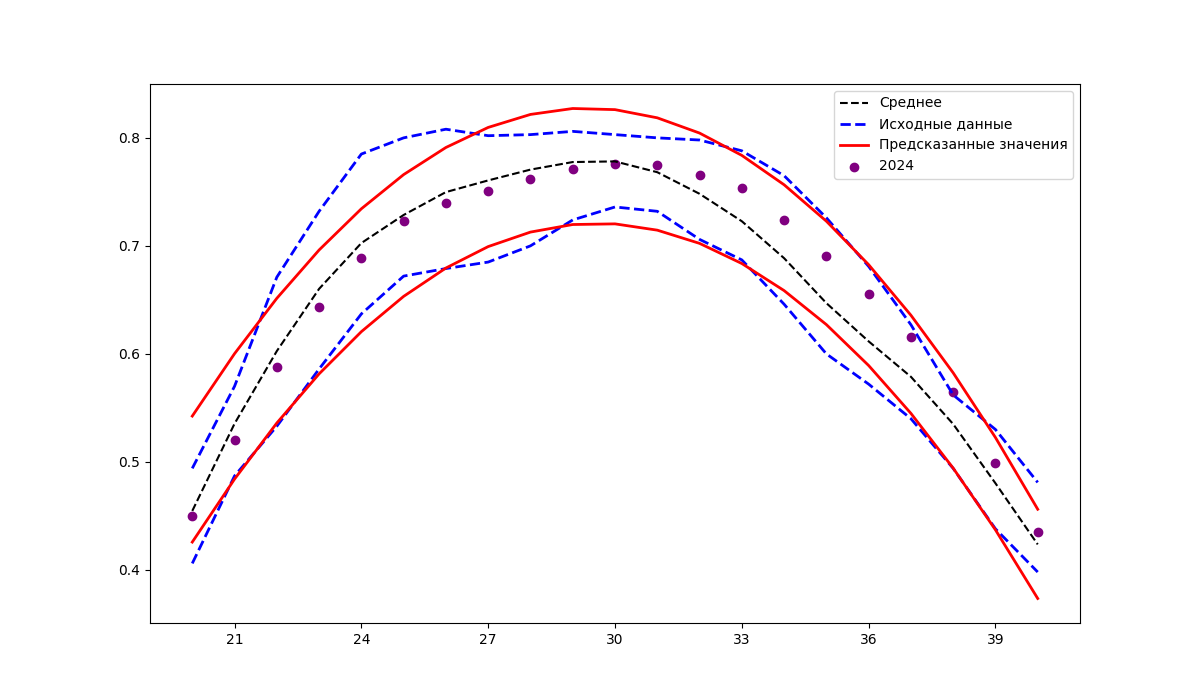
Прогнозирование значений индекса NDVI на 2024 год на основе данных за 2019–2023 года
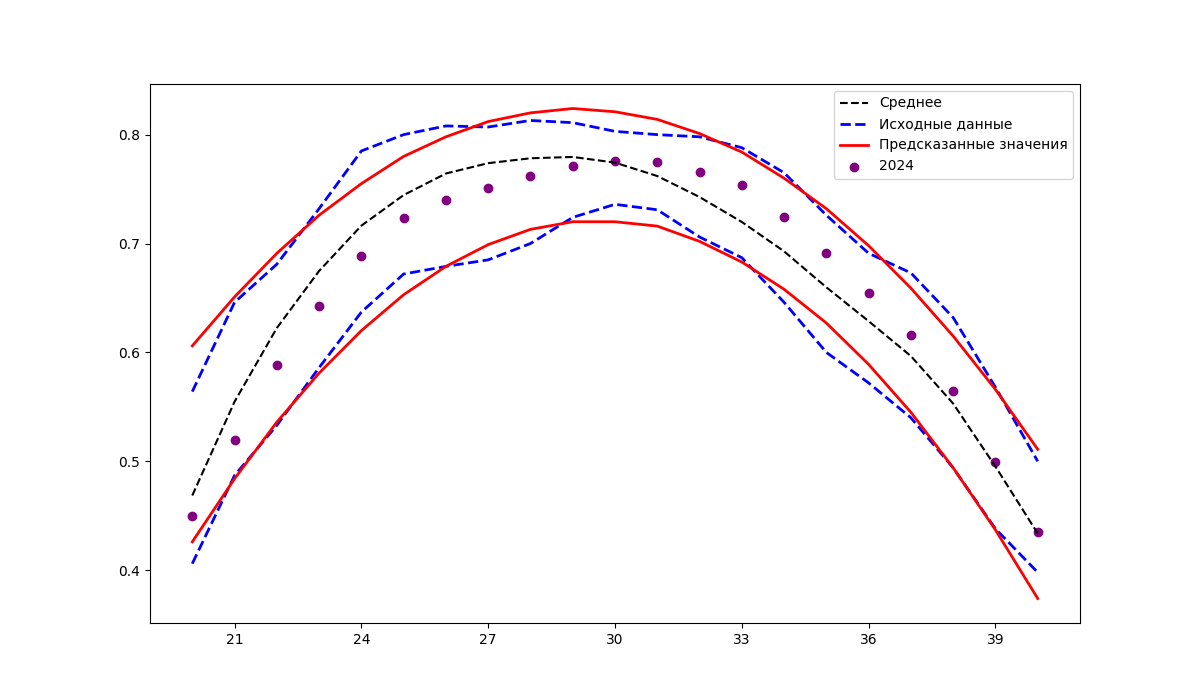
Прогнозирование значений индекса NDVI на 2024 год на основе данных за 2014–2023 года
Пример 4. Выбор аппроксимирующей функции для временных рядов NDVI.
Анализируя рисунки 2–4, можно заметить, что изменение фактических значений индекса NDVI (точки на рисунках) во времени имеет более сложный характер, чем аппроксимирующая функция (красные линии). Задача выбора вида функции для аппроксимации данных достаточно хорошо исследована. Если рассматривать ее в контексте данных, использованных авторами, то можно отметить работу , основной целью которой явилась оценка возможности аппроксимации временных рядов индексов вегетации пахотных земель Хабаровского края с использованием нелинейных функций. Для аппроксимации временных рядов NDVI в использованы следующие функции: Гаусса, двойная гауссиана, двойная синусоида, ряд Фурье (первые четыре слагаемых), двойная логистическая. Расчеты проводились на данных временного ряда NDVI для полей гречихи, залежи, многолетних трав, пара, сои Хабаровского края за 2021 год.
На рисунке 5 показаны результаты применения сложных функций для аппроксимации интервальных данных сезонных значений индекса NDVI для посадок картофеля. Результаты расчетов показывают, что использование интервала значений вместо одной точечной оценки позволяет значительно точнее описать сезонную динамику вегетационного индекса. Цветными линиями на рисунке показаны результаты аппроксимации интервала значений с помощью различных нелинейных функций. Видно, что сложные функции (двойная гауссиана, ряд Фурье) способны уловить основные тренды сезонного развития культуры — фазы всходов, активной вегетации и увядания. Однако ключевым преимуществом интервального подхода здесь является то, что модель оценивает не просто линию тренда, а целый «коридор» возможных состояний. Это позволяет с большей надежностью планировать агротехнические мероприятия (например, сроки внесения удобрений или полива), так как становится понятен диапазон, в котором может варьироваться состояние посевов под влиянием неучтенных факторов, Аппроксимирующие функции, таким образом, описывают не только ожидаемое среднее значение индекса, но и границы его возможной изменчивости в каждый момент времени.
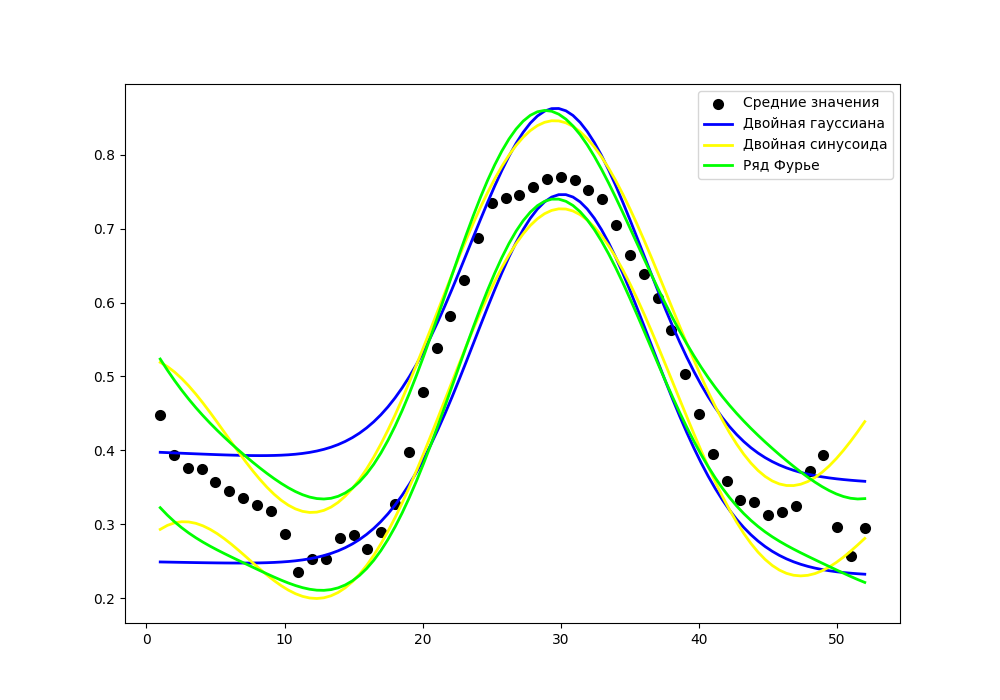
Прогнозирование значений индекса NDVI для полей картофеля
4. Заключение
Проведенное исследование демонстрирует преимущества интервального подхода к прогнозированию в задачах агромониторинга по сравнению с традиционной парадигмой точечных оценок. Сравнительный анализ пяти методов интервальной регрессии на синтетических и реальных спутниковых данных сервиса ВЕГА-Science позволил выявить их сильные и слабые стороны. В частности, установлено, что усложненные методы (линейная и параметризованная модели) наиболее эффективны при работе с контролируемой структурой неопределенности, в то время как на реальных данных, преобразованных с учетом инструментальных погрешностей, метод минимакса показал наилучшие результаты.
Практический результат работы заключается в обосновании перехода от иллюзорно-точных «точка-прогнозов» к реалистичным «коридор-прогнозам». Это особенно важно для управления сельскохозяйственным производством в регионах с суровыми и изменчивыми климатическими условиями, таких как Хабаровский край. Интервальный прогноз, в отличие от точечного, количественно оценивает неопределенность, предоставляя лицу, принимающему решения, диапазон возможных значений. Как показали эксперименты с многолетними данными, использование исторических интервалов (5–10 лет) позволяет строить прогнозные коридоры, которые с высокой вероятностью накрывают фактические значения даже при использовании относительно простых аппроксимирующих функций. Это открывает возможности для более надежной оценки рисков (засух, неурожаев) и планирования агротехнических мероприятий. Таким образом, интервальный анализ является не просто математическим уточнением, а необходимым инструментом для получения достоверных и практически значимых результатов в условиях естественной неопределенности природных систем.