Automatic Generation of Training Data Sets Using 3d Models for Object Detection Problem
Automatic Generation of Training Data Sets Using 3d Models for Object Detection Problem
Abstract
This research proposes to create a dataset by rendering images from 3D scenes in the Blender modelling environment. The main characteristic of this approach is the possibility of introducing random variations of different aspects of the scene: scale of objects, their position in space, lighting characteristics, camera parameters, textures, background images to obtain more diverse and variable data using the developed programme. The work implements automatic generation and saving of annotation for the generated images in YOLO format. Experimental evaluation shows that this approach provides an efficient way to train detectors on synthetic data.
1. Введение
Детектирование объектов – это процесс, при котором компьютерная система автоматически находит и выделяет объекты определенного класса на визуальных данных , и позволяет компьютерам анализировать и интерпретировать визуальную информацию.
Глубокое обучение и методы машинного обучения сегодня позволяют получать хорошие результаты в задаче детектирования, но продолжаются исследования в направлении повышения точности, скорости и надежности детектирования в разнообразных сценариях .
Процесс формирования обучающей выборки и его аннотации является трудозатратным, требующим времени, ресурсов и усилий. Каждое изображение должно быть проанализировано и размечено человеком, для дальнейшего обучения нейросетевых моделей . В процессе ручной аннотации всегда присутствует вероятность человеческих ошибок: неточности в определении границ, ошибки в классификации, которые снижают качество обучения моделей. В некоторых случаях реальных данных может быть недостаточно (или они не существуют) для эффективного обучения моделей.
Цель нашей работы – повышение скорости и вариативности создания обучающего набора данных, для задач детектирования объектов на изображениях, исследование возможностей использования 3D-моделей для создания синтетических обучающих данных и оценка предложенного метода
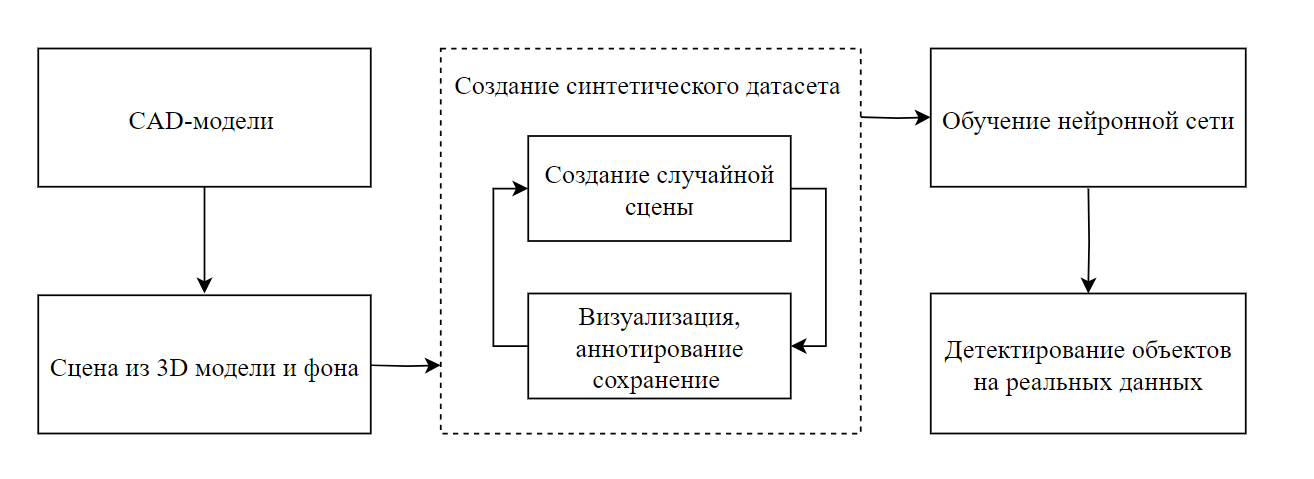
Рисунок 1 - Использование синтетических данных в обучении моделей
В реальных данных редкие случаи могут быть плохо представлены, что усложняет обучение модели. Используя возможности моделирования сцены можно генерировать больше примеры редких случаев, что экономит время и ресурсы.
Для генерации синтетических обучающих выборок мы использовали бесплатный пакет Blender с открытым исходным кодом . В Blender мы создаем трехмерные модели или импортируем готовые 3D модели из CAD систем, которые в дальнейшем используем для создания синтетического набора данных. В нем мы формируем сцену с различными параметрами освещения, фонами, камерами, материалами и текстурами. Мы можем настраивать цвета, отражения, прозрачность и другие атрибуты материалов. Для создания фотореалистичных синтетических изображений, используется встроенный инструмент визуализации.
Для управления генерацией синтетического набора используется встроенный в Blender язык программирования Python. Программный интерфейс приложения взаимодействует с объектами сцены и материалами. Используя эти возможности после создания изображений, мы автоматически вычисляем аннотации для объектов на изображениях, чтобы указать их положение, класс и другие характеристики и полученного изображения, и экспортируем в нужный формат.
Альтернативным вариантом генерации синтетических обучающих выборок на основе 3d моделей является использование игровых движков, например, Unreal Engine и других. Но при использовании игровых движков мы отказываемся от фотореализма при создании синтетического набора данных. Показано, что после увеличения набора данных определенным количеством изображений происходит быстрое переобучение модели нейронной сети , что не позволит получить уверенное распознавание на реальных данных.
В работе показано, что моделирование условий освещения и расположения объектов в синтетическом наборе данных существенно улучшает способность нейросети к обобщению и адаптации к разнообразным сценариям в реальном мире.
При использовании синтетического обучения важно качество графики и реализма, особенно если модель должна работать в реальных условиях. Это может потребовать улучшения методов генерации синтетических данных, чтобы обеспечить более высокую степень реализма , .
В работах , экспериментально продемонстрировано, что модели, обученные в синтетической области, конкурируют с моделями, обученными с помощью изображений, составленных из смеси синтетических и реальных данных и обученными исключительно на реальных изображениях.
2. Создание виртуальной среды и сцен
Сбор изображений для набора данных с большой вариабельностью данных может быть затратным и трудоемким. При решении задач детектирования в системах технического зрения, например, при автоматизации сборочных процессов на производстве, часто встречается ситуация, когда различные детали и компоненты могут иметь множество вариаций и альтернатив, и в процессе производства детали могут заменяться другими версиями, что осложняет поддержку в актуальном состоянии набора данных. Синтетически сгенерированные изображения из 3D сцен могут существенно уменьшить трудозатраты на обучение модели нейронной сети, предоставив более разнообразные и контролируемые сценарии. Но если модель нейронной сети обучается на ограниченных и однотипных данных, она может переобучиться на этих данных, не обобщаясь на новые случаи . Например, если модель нейросети видела объекты только с одного ракурса съемки, или на одном фоне, она может плохо справляться с задачей детекции, либо находить ложные объекты в фоне. Нейронная сеть начинает «запоминать» их особенности, не учитывая общие закономерности или вариации.
Добавление случайных изменений в сцену позволяет избежать этой проблемы, и адаптироваться к различным условиям и вариациям, что повышает способность нейронной сети детектировать и классифицировать в реальных сценах и обнаруживать объекты на основе общих признаков, а не конкретных деталей.
Мы вносим случайные изменения ко всем элементам сцены для каждого изображения синтетического набора данных, который используется во время процесса обучения нейронной сети. Случайным изменениям подвергаются следующие характеристики (рисунок 2):
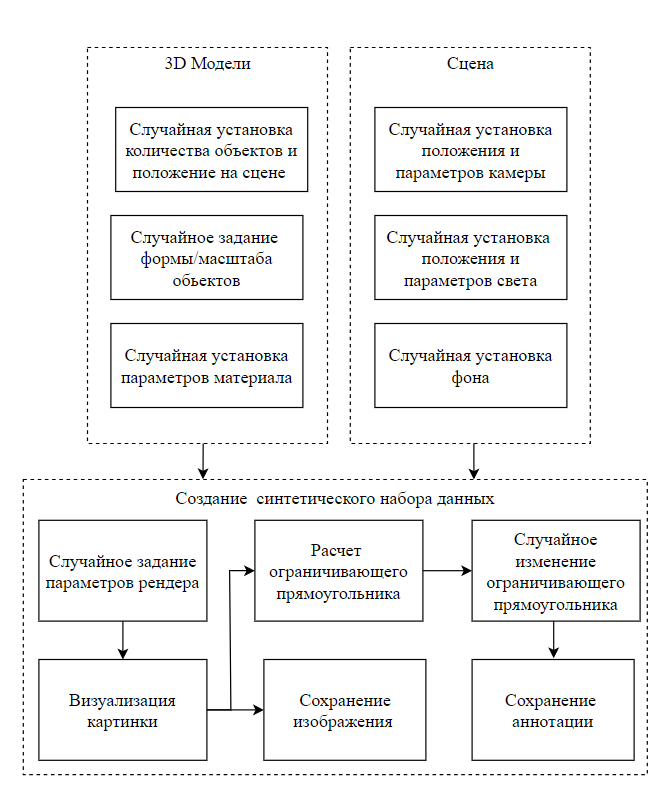
Рисунок 2 - Схема генерации синтетических данных
В процессе генерации изображений синтетической сцены применяются изменения в масштабе объектов, что обеспечивает разнообразие в размерах и помогает нейросети обучаться на разных масштабах представления. Размер каждого объекта в сцене варьируется на основе случайного числа, выбранного из диапазона от 0,5 до 3. Оно отображает масштабирования объекта по каждой оси. Затем к этому масштабному коэффициенту добавляем случайное изменение в пределах 10% от начального размера по каждой оси. Таким образом, форма немного меняется и варьируется. Внесение небольших изменений в форму производит больше вариативности в наборе данных.
Для внесения случайных вариаций в освещение сцены в процессе обучения нейронной сети было использовано 3 источника света. Положение каждого источника света генерировалось случайным образом над сценой. Для каждого источника света также изменялась интенсивность света случайным образом с диапазоном от 10 до 100 процентов. Такое изменение интенсивности формируют набор данных как в ярком, так и в тусклом освещении, как может быть в реальных условиях. Кроме того, направление света менялось в пределах ±45 градусов поворотом на случайный угол вокруг своей оси.
Апробация методики выполнялась на макетах реальных объектов, полученных на 3D принтере. Для фотореалистичности и учета технологии FDM-печати, в синтетических сценах был создан материал, имитирующий фактуру поверхности. В материале, который применяется при визуализации каждой сцены, варьируются различные характеристики: изменяется толщина и ширина слоя печати, чтобы передать детали и особенности процесса печати, что добавляет текстурные эффекты и создает эффект визуального объема. Также применяются случайные коррекции цвета, насыщенности, яркости, блеска и отражения материала, что создает вариативность в отображении материала и его внешних характеристик.
При реализации изменения фонового изображения и добавления разных окружений в сцену, был использован метод генерации фона с учетом максимизации фонового беспорядка. Целью этого подхода является использование непредсказуемого фонового изображения, чтобы модель нейросети избегала простых признаков и могла лучше учиться на более сложных аспектах и их взаимодействиях с окружением. Для максимального разнообразия и реализма фоновых изображений, в синтетическом наборе данных было подготовлено 500 изображений, представляющих текстуры дерева. Эти изображения представляют собой различные вариации текстур дерева с разными размерами и структурами. Во время генерации сцены каждый раз, случайным образом, выбирается одно из фоновых изображений из этого набора. Фоновые изображениям могут быть повернуты на угол от 0 до 90 градусов, масштабированы по размеру сцены, или изменена их яркость и контрастность до 20%.
Для разнообразия сцен в синтетических наборах данных мы проводили вариацию параметров камеры: фокусное расстояние и точку обзора. Мы варьировали фокусное расстояние на значения, отличающиеся на ±20% от начального значения, что формирует разные планы фокуса и глубину резкости в изображениях. Перемещая точку обзора, мы создаем вариацию в угле, под которым модель видит объект.
При генерации изображений было использовано разное количество сэмплов в настройках визуализации каждого изображения, изменяемое случайным образом в диапазоне от 15 до 100 сэмплов. Количество сэмплов оказывает влияние на качество и «шумность» результирующего изображения. При использовании меньшего количества сэмплов, например, 15, изображение может содержать больше «шума» и артефактов. В результате получаются менее четкие и более «шумные» изображения. При использовании большего количества сэмплов, например, 100, мы получаем более точную и менее «шумную» картинку.
Для дополнительного разнообразия в синтетических сценах мы также вводили случайное изменение размеров прямоугольника, охватывающего объект на изображении (bound box), изменяя размеры границ на величину от -5% до +5% от их исходного размера.
Каждое изображение в генерируемом синтетическом наборе формируется с помощью объединения двух компонентов: фонового слоя и объектов переднего плана, которые формируются из трехмерных моделей.
На рисунке 3 представлены некоторые изображения, которые созданы с использованием нашего алгоритма.

Рисунок 3 - Примеры визуализации сцен с аннотацией в обучающем наборе данных
Аннотации сохраняются вместе с соответствующими сгенерированными изображениями в формате YOLO в текстовых файлах.
Для построения обучающего и проверочного набора данных было сгенерировано 10 0000 аннотированных изображений, каждое из которых представляет собой уникальную сцену.
3. Обучение модели детектирования на синтетических данных
Мы использовали архитектуру YOLOv8n для обучения нейронной сети на синтетических данных. YOLO (You Only Look Once) – это архитектура нейронной сети, разработанная для решения задачи детектирования объектов на изображениях и видео. Эта архитектура представляет собой значительное улучшение в сравнении с более ранними методами детектирования R-CNN и Faster R-CNN, и получила широкую популярность благодаря своей эффективности и скорости работы .
Нейросеть была обучена на протяжении 800 эпох, что обеспечивает полный цикл прохода через весь тренировочный набор данных. В процессе обучения, система достигла показателя метрики mAP50 99% (рисунок 4а). Этот говорит об эффективности обучения модели по синтетически сгенерированным тренировочным данным. При этом, метрика dfl_loss на всем протяжении обучения уменьшается, что означает, что модель становится лучше в прогнозировании границ объектов (рисунок 4б).
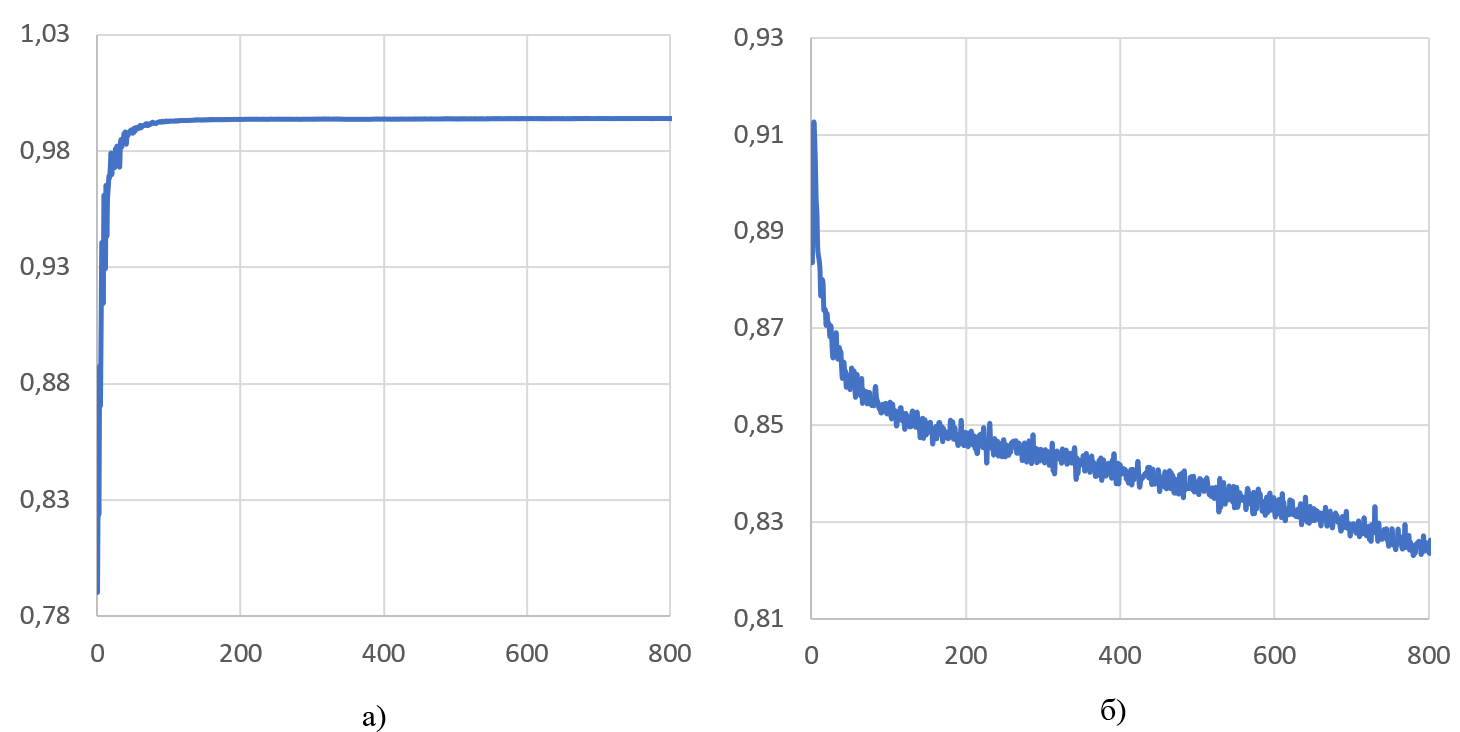
Рисунок 4 - Динамика метрики mAP50 (а) и dfl_loss (б) на обучающем наборе данных
4. Тестирование на реальных данных
Для валидации и оценки обученной нейронной сети на синтетических данных был сформирован набор данных, включающий в себя 800 реальных фотографий деталей, изготовленных с использованием 3D-принтера методом FDM печати. Фотографии были сделаны на поверхности с текстурой, имитирующей структуру дерева. Набор данных включает в себя разнообразные снимки деталей в различных контекстах, освещении и ракурсах. На рисунке 5 показан результат детектирования на реальном изображении. Используя ограничительные рамки, полученные в результате обработки алгоритмом детектирования, обученным на синтетических данных нейросети, каждый объект выделен и отмечен соответствующим уровнем уверенности распознавания.
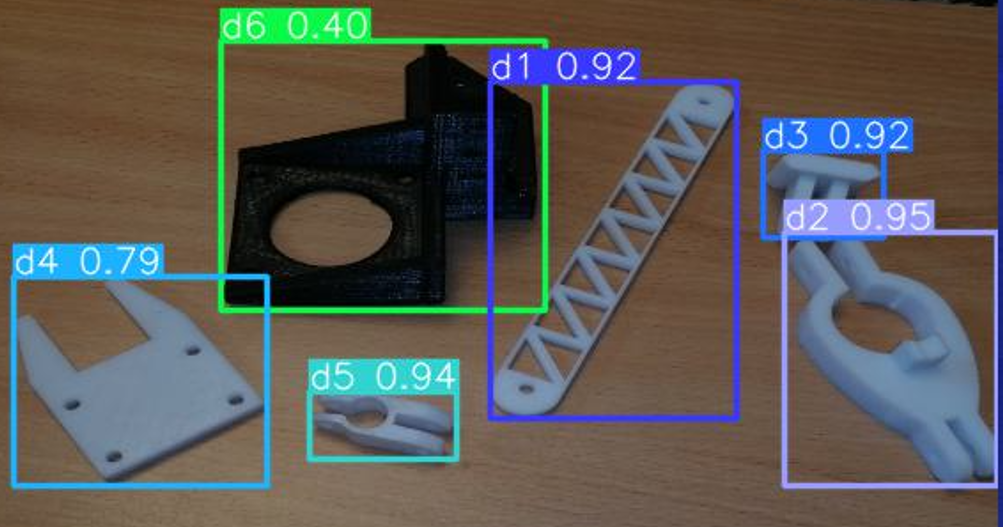
Рисунок 5 - Пример детектирования объектов с границами на реальном изображении
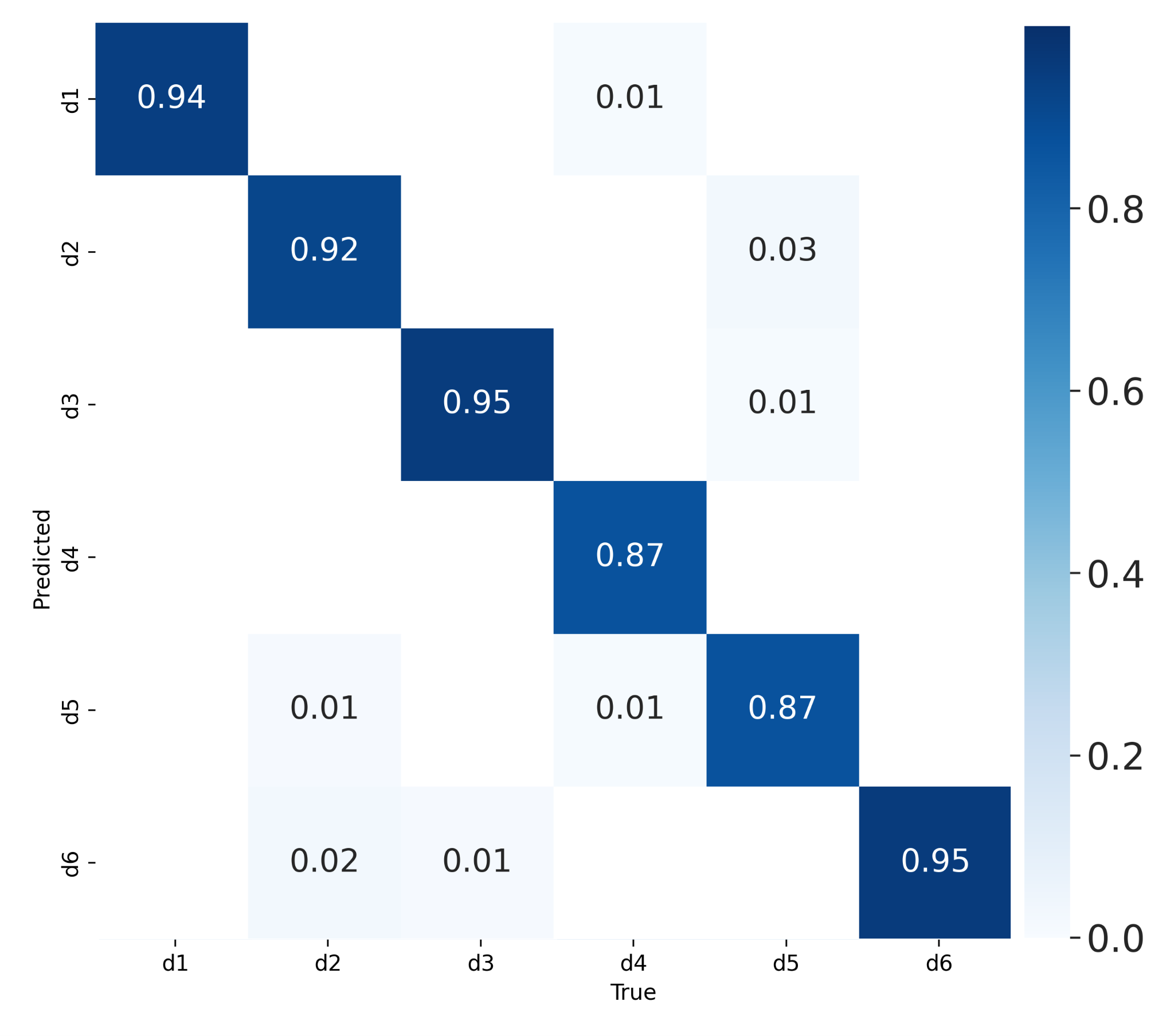
Рисунок 6 - Матрица ошибок для тестового набора данных

Рисунок 7 - Тепловая карта активаций нейронной сети
5. Результаты/обсуждение
Синтетические методы генерации обучающей серии изображений обуславливают преимущества в задачах технического зрения, например в системах детектирования деталей узлов сборки, развернутой на автоматизированном производстве, где необходимо вести учет сотен и тысяч сборочных деталей, подверженных частым изменениям. Аннотирование такого огромного количества изображений уже само по себе является очень дорогостоящей задачей. Постоянное обновление обучающих данных из-за изменений в номенклатуре усложняет эту задачу и масштабирование её становится практически невозможным.
Вместе с этим, 3D-модели деталей доступны на этапе проектирования изделий. То есть имея только модель детали, мы уже можем обучить нейронную сеть. Именно по этим причинам мы считаем, что методы генерации полностью синтетических данных необходимы для обеспечения гибкости при развертывании и обновлении систем детектированияобъектов в быстро меняющихся реальных сценариях для производственных процессов. Наше тестирование показывает, что можно качественно обучить модель нейронной сети YOLOv8n, используя только синтетические данные.
Мы предлагаем метод генерации набора данных из синтетических изображений, в котором мы избегаем необходимости ручного аннотирования.
Путем включения большего количества трехмерных моделей, можно увеличить разнообразие генерируемых данных в синтетических сценах, что дополнительно обогатит синтетический набор данных и обеспечит модель машинного обучения большим количеством данных для обучения. Добавление фоновых элементов формирует более разнообразные и реалистичные сцены.
6. Заключение
Предложенный метод автоматической генерации обучающих наборов данных с использованием 3D-моделей для задачи детектирования объектов показал свою эффективность и применимость. В ходе эксперимента, где модель обучалась на синтетических данных и затем была протестирована на реальных изображениях, отмечается высокий уровень истинно положительной классификации объектов, располагающийся в диапазоне от 87% до 95%. Обычно процесс создания датасета включает съемку изображений или видео с исходными объектами, а также разметку данных с выделением и описанием объектов обучения. В среднем на подготовку одного кадра может уходить от 1 до 2 минуты. Использование синтетических данных, при наличии 3D моделей, существенно сокращает время, затрачиваемые на подготовку набора данных. Для создания сцены и фоновых изображений требуется не более 30 минут, а дальнейшая генерация изображений с аннотациями происходит автоматически, за 15-60 секунд на кадр. Например, для разметки набора данных, аналогичного созданному в работе, с 10 000 изображений потребуется примерно 300 человеко-часов, в то время для синтетической генерации необходимо порядка 60 часов машинного времени.