Architecture of a system for collecting and storing metrics on the resource usage of Spark applications in clustered big data processing systems
Architecture of a system for collecting and storing metrics on the resource usage of Spark applications in clustered big data processing systems
Abstract
The object of the study is the process of collecting and analysing computational metrics of Apache Spark applications in conditions of processing large volumes of data on clusters. The aim of the work is to develop and substantiate the architecture of a system for collecting, transmitting and storing metrics on the use of Spark application computing resources for subsequent analysis and support for optimising their configurations. The work analyses existing approaches to monitoring Spark applications and formulates requirements for a metric collection system in an industrial cluster environment. A minimally sufficient set of metrics has been formed, reflecting key aspects of application behaviour and resource utilisation. An architectural solution has been proposed that includes the use of GraphiteSink, Logstash, Kafka, and ClickHouse, allowing for interval metric collection every 10 seconds. The system was tested in a real computing cluster, confirming its reliability, scalability, and applicability to industrial tasks. The presented system can serve as a basis for optimising distributed computing.
1. Введение
С ростом объемов данных в различных областях по данным IDC на 2025 , их обработка становится все более важной частью современных информационных систем. По оценкам IDC, общий объем данных в мире достигнет 175 зеттабайт к концу 2025 году, по сравнению с 33 ЗБ в 2018 году . Сокращение времени обработки, минимизация накладных расходов может быть достигнута путем эффективного использования вычислительных ресурсов приложений, работающих в рамках кластеров. Apache Spark — это унифицированный вычислительный движок и набор библиотек для массовой параллельной обработки данных на компьютерных кластерах. Spark поддерживает несколько широко используемых языков программирования (Python, Java, Scala и R), включает библиотеки для различных задач, обеспечивает выполнение SQL запросов, потоковою обработку данных, а также используется в рамках машинного обучения. Несмотря на развитые механизмы параллельных вычислений, обеспечение эффективного использования ресурсов остается одной из наиболее распространенных проблем в Spark-приложениях, что рассмотрено в статье . Неправильная настройка используемых ресурсов приложениями может привести к значительной деградации производительности, увеличению времени выполнения как самого приложения, так и других приложений, работающие на кластере. Совокупное влияние перечисленных факторов способствует увеличению инфраструктурных затрат и снижению общей эффективности эксплуатации вычислительных ресурсов.
Для решения задачи оптимизации используемых ресурсов приложениями Spark на кластере требуется получать достоверную информацию о нагрузке на систему и о количестве потребляемых ресурсов. Формирование устойчивого и масштабируемого подхода к сбору и структуризации метрик представляет собой ключевую задачу при работе с большими объемами данных.
Цель данной работы состоит в разработке и обосновании архитектуры системы сбора, передачи и хранения вычислительных метрик Apache Spark-приложений в кластерной среде для последующего анализа и оптимизации использования ресурсов.
Для достижения поставленной цели требуется решить следующие задачи:
- определить минимально необходимый набор метрик, отражающих поведение Spark-приложений и использование ресурсов;
- выполнить анализ существующих методов и инструментов мониторинга Spark-приложений с точки зрения применимости в условиях высоконагруженных кластеров;
- разработать архитектуру системы сбора метрик;
- провести промышленную проверку архитектуры, включая анализ зависимости между частотой сбора метрик и точностью анализа, выбрав компонентов системы (источник метрик, протокол передачи, брокер сообщений, СУБД для хранения) с учетом ограничений на нагрузку и масштаб кластера.
Объектом исследования является процесс мониторинга вычислительных характеристик Spark-приложений в распределенных средах. Предметом исследования выступают методы сбора, передачи и хранения вычислительных метаданных с целью их последующего использования для оптимизации выполнения приложений и управления ресурсами.
2. Методы и принципы исследования
2.1. Определение необходимого набора метрик
Для полноценного анализа методов сбора метрик, необходимо определить их минимально достаточный набор, обеспечивающий репрезентативную оценку поведения Spark-приложений и использования ресурсов вычислительного кластера.
Apache Spark представляет собой распределенную платформу обработки данных, основанную на модели RDD. Все вычисления над данными производятся на процессоре, с хранением промежуточных результатов вычислений в оперативной памяти. Ключевой особенностью Spark является его ленивая модель вычислений: операции над данными не выполняются в момент вызова. На этапе планирования Spark разбивает всю цепочку вычислений на стадии, каждая из которых состоит из параллельно исполняемых задач. Задачи, в свою очередь, могут быть запущены на различных исполнителях, которые расположены на разных узлах кластера. Несмотря на масштабируемость, данная модель порождает ряд существенных проблем:
Наличие повторных трансформаций, кэширование больших объемов данных, неоптимальные стратегии соединений, неверные параметры shuffle — все это приводит к неоптимальному расходу ресурсов и замедлению работы приложений , ;
Неправильно выбранные параметры приложений приводят либо к переутилизации отдельных исполнителей, что влечет за собой снижение скорости обработки данных , либо к простою больших объемов ресурсов, что приводит к неоправданному увеличению эксплуатационных затрат на инфраструктуру;
Избыточная нагрузка на систему хранения данных .
Исходя из представленных проблем, необходимо собирать информацию об использовании оперативной памяти, утилизации NameNode кластера, а также о spill данных в память и на диск. Согласно статье в Spark 3.0 были существенно расширены средства мониторинга памяти, что дает возможность наиболее полного и детального анализа утилизации ресурсов приложениями: введены новые метрики, позволяющие отслеживать использование heap и off-heap памяти на уровне исполнителей и задач, а также события disk spill, в случае нехватки оперативной памяти, что критично для оптимизации ресурсоемких приложений.
Согласно официальной документации Spark , при работе приложений Spark автоматически собирает и публикует более 100 различных метрик, охватывающих уровни задач (task), стадий (stage), исполнителей (executor), драйвера (driver) и JVM. Для решения обозначенных в работе проблем были выделены и классифицированы пять ключевых категорий метрик, охватывающих наиболее критичные аспекты производительности Spark-приложений.
В Spark 3.0 добавлены точные метрики для мониторинга heap и off-heap памяти (memory.OnHeapStorageMemory, memory.OffHeapStorageMemory и др.), а также динамики использования памяти в JVM (jvm.heap.used, jvm.non-heap.used). Эти показатели позволяют своевременно выявлять утечки памяти, избыточное кэширование и неэффективные конфигурации выделяемой оперативной памяти.
Метрики memoryBytesSpilled и diskBytesSpilled фиксируют моменты, когда данные не помещаются в память и вынужденно сбрасываются на диск (disk spill). Это позволяет выявлять узкие места в конфигурации памяти при выполнении shuffle, join и sort операций и избегать дорогостоящих I/O-операций.
Метрики filesystem.hdfs.read_bytes, filesystem.hdfs.read_ops, filesystem.hdfs.write_bytes, filesystem.hdfs.write_ops позволяют оценить объем данных, проходящих через задачи и стадии. Эти данные используются для оценки влияния на файловое хранилище. Позволяют выявлять чрезмерную нагрузку на файловую систему при работе с большими объемами данных.
Метрики shuffleReadMetrics и shuffleWriteMetrics фиксируют объемы и распределение данных между узлами, включая долю локальных и удаленных блоков. Они критически важны для анализа распределения нагрузки и выбора оптимальной стратегии операции join.
Метрики task.executorRunTime, task.executorCpuTime, task.jvmGCTime, task.duration, task.peakExecutionMemory позволяют определить узкие места на уровне отдельных задач, исправить неравномерная нагрузка между исполнителями, ускорить долгие задачи, снизить перерасход CPU и время на ожидание ресурсов.
В рамках данного исследования необходимо определить в каждой группе минимальный набор базовых метрик, достаточный для:
- оценки загрузки ресурса;
- диагностики типовых проблем, таких как spill, data skew, перегруз памяти/GC .
Подобный подход соответствует практике работ по подстройке параметров для повышения быстродействия процессов, где для построения моделей производительности и автонастройки конфигураций выбирается ограниченный набор наиболее информативных параметров, покрывающих ресурсы CPU, памяти и диска .
В результате из исходного множества метрик был сформирован минимально достаточный набор из 35 показателей, список которых приведён в табл. 1. Данный набор обеспечивает покрытие всех выделенных ресурсов и стадий выполнения приложений и служит основой для дальнейшего анализа и визуализации производительности Spark-приложений. Расширение набора за счёт дополнительных счётчиков, дублирующих информацию по смыслу, было признано нецелесообразным с точки зрения объёма хранимых данных и сложности последующей обработки.
Таблица 1 - Ключевые метрики мониторинга нагрузки Spark-приложения
Категория | Метрика | Описание |
Использование памяти | jvm.heap.used | Объем используемой heap-памяти JVM |
jvm.heap.committed | Объем выделенной heap-памяти JVM | |
jvm.heap.max | Максимально доступный объем heap-памяти JVM | |
jvm.non-heap.used | Объем используемой non-heap памяти JVM | |
jvm.non-heap.committed | Объем выделенной non-heap памяти JVM | |
jvm.non-heap.max | Максимально доступный объем non-heap памяти JVM | |
ExecutorMetrics.OnHeapStorageMemory | Используемая on-heap память для хранения данных | |
ExecutorMetrics.OffHeapStorageMemory | Используемая off-heap память для хранения данных | |
ExecutorMetrics.OnHeapExecutionMemory | Общий объем on-heap памяти для хранения | |
ExecutorMetrics.OffHeapExecutionMemory | Общий объем off-heap памяти для хранения | |
Spill | executor.memoryBytesSpilled.count | Объем данных, сброшенных из памяти на диск на уровне executor |
executor.diskBytesSpilled.count | Объем данных, сброшенных на диск на уровне executor | |
task.memoryBytesSpilled.count | Объем данных, сброшенных из памяти на диск на уровне задачи | |
task.diskBytesSpilled.count | Объем данных, сброшенных на диск на уровне задачи | |
Ввод/вывод | executor.filesystem.hdfs.largeRead_ops | Количество больших операций чтения данных executor из hdfs |
executor.filesystem.hdfs.read_bytes | Объем данных, прочитанных executor из hdfs | |
executor.filesystem.hdfs.read_ops | Количество операций чтения данных executor из hdfs | |
executor.filesystem.hdfs.write_bytes | Объем данных, записанных executor из hdfs | |
executor.filesystem.hdfs.write_ops | Количество операций записи данных executor из hdfs | |
task.outputMetrics.bytesWritten | Объем данных, записанных задачей | |
Задачи | task.duration | Продолжительность выполнения задачи |
task.jvmGCTime | Время на сборку мусора во время выполнения задачи | |
task.resultSize | Размер результата задачи | |
task.executorRunTime | Время выполнения задачи на executor | |
task.executorCpuTime | Время использования CPU задачей | |
task.peakExecutionMemory | Пиковое использование памяти задачей | |
Shuffle-чтение | shuffleReadMetrics.totalBlocksFetched | Количество блоков, полученных в shuffle-чтении |
shuffleReadMetrics.localBlocksFetched | Локальные блоки, полученные в shuffle-чтении | |
shuffleReadMetrics.remoteBlocksFetched | Удаленные блоки, полученные в shuffle-чтении | |
shuffleReadMetrics.totalBytesRead | Общий объем байт, прочитанных в shuffle-чтении | |
shuffleReadMetrics.localBytesRead | Объем байт, прочитанных локально в shuffle-чтении | |
shuffleReadMetrics.remoteBytesRead | Объем байт, прочитанных удаленно в shuffle-чтении | |
shuffleWriteMetrics.bytesWritten | Объем байт, записанных в shuffle-записи | |
shuffleWriteMetrics.recordsWritten | Количество записей, записанных в shuffle-записи | |
shuffleWriteMetrics.writeTime | Время записи в shuffle (в наносекундах) |
2.2. Анализ существующих решений
Современные исследования в области мониторинга Apache Spark-приложений охватывают широкий спектр решений — от базовых инструментов визуализации (Spark UI, Ganglia) до комплексных систем потоковой аналитики на базе Prometheus, Kafka и Grafana , . Вместе с тем, подобные решения зачастую не адаптированы к промышленной эксплуатации в высоконагруженных кластерах, что отмечается в работе . Кроме того, в литературе слабо представлены вопросы агрегации и оптимизации хранения метрик в условиях высокой частоты сбора. По данным «ieeexplore» на 2025 год, по ключевым словам, «Spark», «Memory» и «Optimization» было найдено 5 релевантных статей выпущенных позднее 2020 года.
Для построения архитектуры введем требования к высоконагруженной системе:
- Масштабируемость. Возможность горизонтального расширения как всей системы, так и отдельных ее компонент.
- Доступность. Обеспечивать непрерывность работы системы с минимальным временем простоя.
- Минимальная нагрузка. Иметь минимальное влияние на вычислительные процессы кластера, включая в себя необходимость поддержания сложной внешней инфраструктуры.
В данной работе сделан акцент на построении отказоустойчивой архитектуры с минимальной нагрузкой на вычислительные ресурсы кластера, что позволяет восполнить существующий пробел между теоретическими разработками и практическими потребностями промышленной эксплуатации Spark-приложений.
В рамках дальнейшего анализа предлагаю следующую систему классов источников получения метрик от Spark-приложений:
- Spark UI;
- Listener;
- Встроенные в Spark коннекторы.
Первым классом источников является Spark UI, а также Spark Rest API. Они представляют агрегированные сведения, включая длительность стадий, объемы обрабатываемых данных и уровень загруженности ресурсов. Данный подход предоставляет обобщенную картину без разбивки по интервалам времени, что является минусом при анализе утилизации ресурсов приложениями. В свою очередь, вычисления в рамках Spark-приложений характеризуются тем, что могут динамически изменять используемые ресурсы в пределах выделенного пользователем максимального их объема.
Следующий класс источников основывается на отдельном сопроцессе Listener в рамках основного Spark-приложения. Пользователь может как реализовать свой сопроцесс позволяющий проводить операции по сбору и отправке метрик в систему потребитель, так и в самом Spark уже есть встроенный EventLoggingListener, сохраняющий всю информацию о событиях выполнения приложения: задания, стадии, задачи, операции ввода-вывода, использование памяти и другие параметры. Такой подход позволяет анализировать использование различных операций и их влияние на ресурсоемкость выполнения . Обработка Event Log в таком случае выполняется внешним инструментом. Существуют готовые решения, которые позволяют получать метрики, считаемые автоматически Spark-приложениями. Например, использование PrometheusServletSink в таких решениях описано в , . Он занимается обработкой Event Log сообщений после завершения работы приложения. Представляет собой готовое решение, которое выполняет собственный анализ и выводит результат пользователю в виде UI представления. Но требует отдельной инфраструктуры, плохо ложится на существующий on-prem стек, ориентирован на Kubernetes-окружение , .
Еще одним инструментом сбора метрик являются реализованные в Apache Spark коннекторы для отправки. Они заменяют требующие собственной реализации Listener, а также позволяют реализовать анализ приложения уже во время его работы, посредством выгрузки уже посчитанных Spark`ом метрик в систему потребитель. Настройка интеграции сводится к заданию двух конфигурационных параметров в Spark-приложении и не предполагает необходимость развертывания дополнительной инфраструктуры, обладающей высокой степенью сложности, в отличие от готовых систем мониторинга на основе Event Log. Сводный обзор методов оформлен в виде таблицы 2.
Таблица 2 - Сводное сравнение подходов сбора метрик Spark-приложений
Подход | Уровень детализации | Нагрузка на систему | Гибкость настройки | Требования к инфраструктуре |
Spark UI / Spark Rest API | Низкий | Низкая | Низкая | Инфраструктура хранения, сервис сбора метрик |
Listener | Высокий | Средняя | Высокая | Инфраструктура хранения, требуется реализация слушателя и подключение ко всем приложениям |
Встроенный Connector | Высокий | Низкая | Средняя | Требуется инфраструктура для приема и хранения |
2.3. Методика и архитектура предлагаемого подхода
Выбор конкретного способа сбора и отправки метрик зависит от объема метрик, количества узлов, ядер на каждом узле, объемов оперативной памяти каждого узла кластера, а также от количества работающих Spark-приложений. Введем характеристики кластера:
- 200 узлов, с характеристиками 100 Гб оперативной памяти и 20 ядер на каждом;
- ежедневная работа минимум 3000 Spark-приложений.
Совокупный объем данных определяется частотой сбора метрик и размерностью результирующего набора параметров. Наиболее сбалансированным решением представляется интервальных сбор метрик с приложения, ввиду отсутствия реактивных вычислений и для снижения нагрузки как на само приложение, так и на систему приемщик. Эмпирические исследования показывают, что оптимизация частоты сбора напрямую влияет на нагрузку системы хранения . Возможность интервального сбора реализована как во встроенных коннекторах Spark, так и при использовании пользовательских Listener-компонентов. Наиболее оптимальным в базовом ключе является готовый коннектор Spark, так как не требует никаких доработок со стороны приложений и кластера. Использование Listener предполагает разработку отдельного механизма сбора и маршрутизации метрик, а также является инфраструктурно ограниченным — его требуется подключить ко всем приложениям кластера. В рамках предлагаемого решения использовался метод интервального сбора метрик с шагом 10 секунд посредством GraphiteSink. Интервал в 10 секунд между отправками, был выбран экспериментальным путем, результаты чего представлены на рисунке 1. Он позволяет соблюсти баланс между упущенными релевантными метриками и объемом отправляемых метрик из Spark-приложений, который растет линейно в зависимости от частоты.
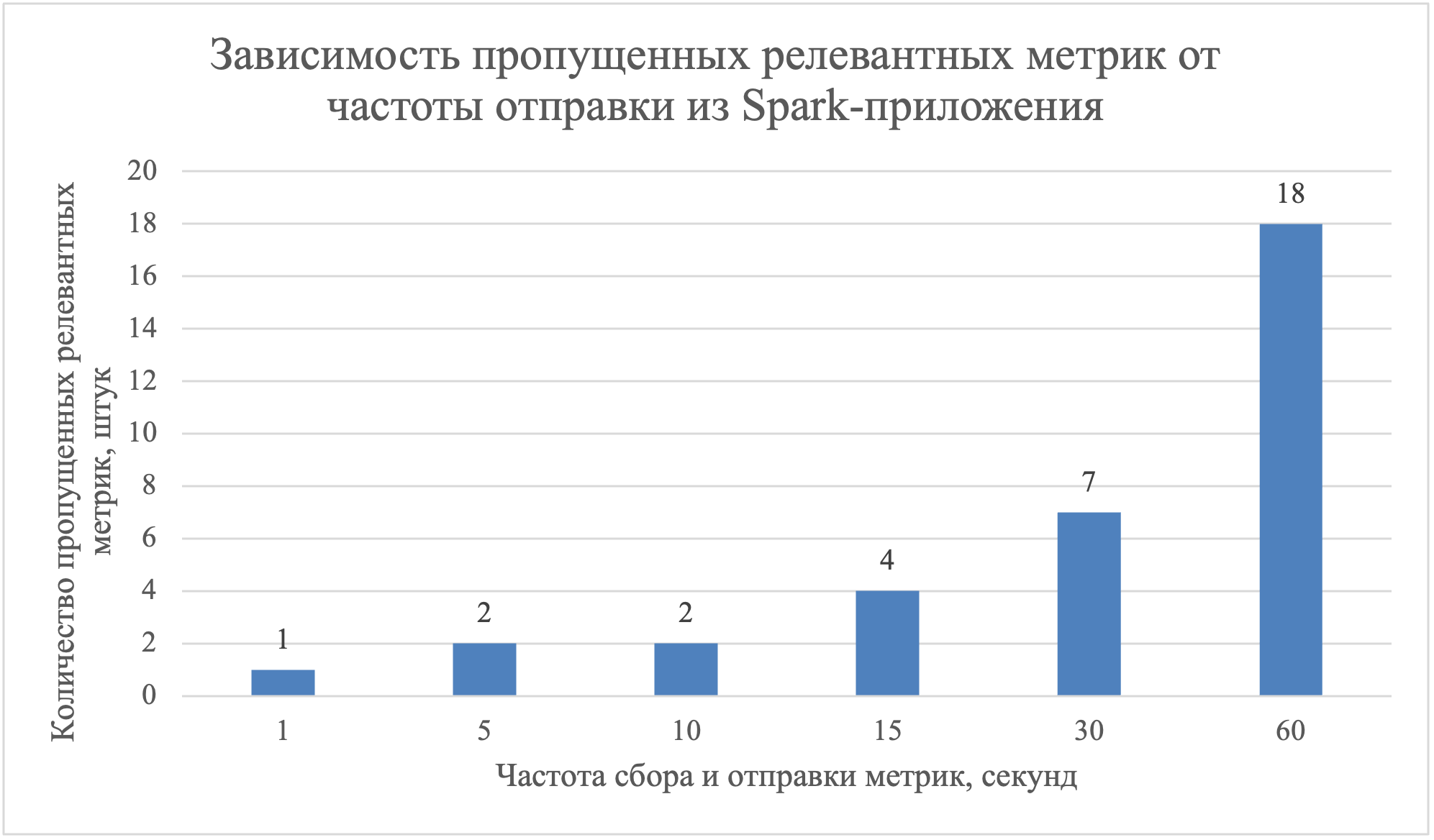
Рисунок 1 - Зависимость пропущенных релевантных метрик от частоты отправки из Spark-приложения
- на промежуточном этапе неизбежно образуется значительное число мелких файлов;
- дополнительные вычислительные ресурсы на работу потока;
- недоступность данных на время перезаписи.
Указанные ограничения существенно снижают применимость HDFS в качестве системы хранения метрик в рассматриваемом сценарии.
Clickhouse представляет собой более предпочтительное решение с точки зрения производительности и устойчивости хранения. Примеры успешного применения ClickHouse для потоковой аналитики приведены в , . Учитывая значительное количество метрик и характерную стабильность их значений на протяжении фиксированных временных интервалов, требуется реализация механизма агрегации, позволяющего эффективно минимизировать объём сохраняемой информации, в результате чего повторяющиеся значения агрегируются в единственное представление в пределах заданного окна, на котором они имеют эффект. Для реализации агрегации применяется движок AggregatingMergeTree, обеспечивающий свёртку всех строк с одинаковыми ключами в единую запись, представляющую агрегированное состояние по заданным функциям в пределах одного сегмента данных. Такой подход способствует сокращению объема хранимых данных и снижению нагрузки на систему визуализации.
Последним элементом, который необходимо выбрать — это система передачи данных от Spark-приложения к системе хранения данных. В GraphiteSink отсутствует возможность прямой интеграции с ClickHouse по стандартным интерфейсам передачи данных. Коннектор поддерживает передачу метрик по протоколу UDP в систему, которая имеет возможность принимать такого вида сообщения. Наиболее используемыми такими инструментами являются Logstash и Ni-Fi. Ni-Fi требует больших вычислительных ресурсов и является кластерным решением, характеризующимся высокой сложностью развертывания и сопровождения. Logstash представляет собой легковесное решение для маршрутизации и трансформации потоков данных между компонентами распределенной системы. В контексте рассматриваемой архитектуры данный инструмент обеспечивает оптимальный баланс между производительностью и гибкостью настройки. При этом Logstash требует наличия приёмника данных. Возможна прямая запись в ClickHouse, однако такой подход не обеспечивает необходимого уровня отказоустойчивости из-за потенциальной недоступности ClickHouse в периоды обслуживания или при пиковых нагрузках. Потеря метрик в подобной конфигурации приведёт к нарушению целостности исторических данных, что может привести к снижению достоверности и полноты последующего анализа метрик. Необходимо использовать брокер для минимизации недоступности, а также для дальнейшей балансировки нагрузки при записи в Clickhouse. Для задач в области обработки больших данных целесообразно применение Kafka, зарекомендовавшей себя как промышленный стандарт брокеров сообщений.
В результате сформирована следующая архитектура системы:
- Spark-приложение — в режиме выполнения вычислений считает метрики использования ресурсов, а также метрик о сути вычислений;
- GraphiteSink — встроенный подпроцесс в Spark, позволяющий экспортировать метрики во внешнюю систему, в данном случае по протоколу UDP;
- Logstash — инструмент для маршрутизации и преобразования сообщений между источниками и приемниками данных;
- Kafka — брокер сообщений, для балансировки нагрузки и минимизации риска неуспешности вставки данных;
- AggregatingMergeTree Clickhouse – база данных для хранения метрик, для дальнейшего анализа и визуализации.
Взаимодействие в рамках архитектуры системы представлено на рисунке 2.
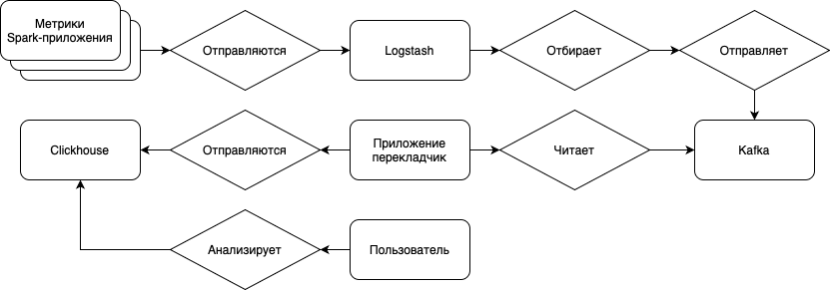
Рисунок 2 - Архитектура системы сбора и хранения метрик
3. Оценка эффективности и практическая применимость
В целях верификации работоспособности и оценки применимости разработанной архитектуры была проведена её опытная эксплуатация в условиях реального кластера, включающего 200 вычислительных узлов, каждый из которых обладает 100 Гб оперативной памяти и 20 вычислительными ядрами. Система использовалась в течение рабочего дня при запуске более 3000 Spark-приложений, функционирующих в рамках типичной загрузки производственной среды.
Сбор метрик осуществлялся с использованием встроенного коннектора GraphiteSink с интервалом в 10 секунд. Передача данных происходила через Logstash с маршрутизацией через Kafka в ClickHouse, где происходила агрегация и долговременное хранение информации с использованием движка AggregatingMergeTree.
Результаты эксперимента были представлены в виде интерактивных дашбордов, включающих ключевые метрики:
- Executor HDFS reads / writes — отображают динамику операций чтения и записи с HDFS в разрезе по исполнителям, отражая фрагментированную и конкурентную нагрузку на систему хранения, представлены на рисунке 3;
- HDFS Read Rate — демонстрирует пиковые значения пропускной способности при интенсивной фазе чтения, что позволяет выявлять узкие места в I/O, также представлены на рисунке 3;
- Executor Heap Usage / Driver Heap Usage — позволяют анализировать использование кучи в динамике, как на уровне отдельных исполнителей, так и на уровне управляющего драйвера и представлены на рисунке 4.
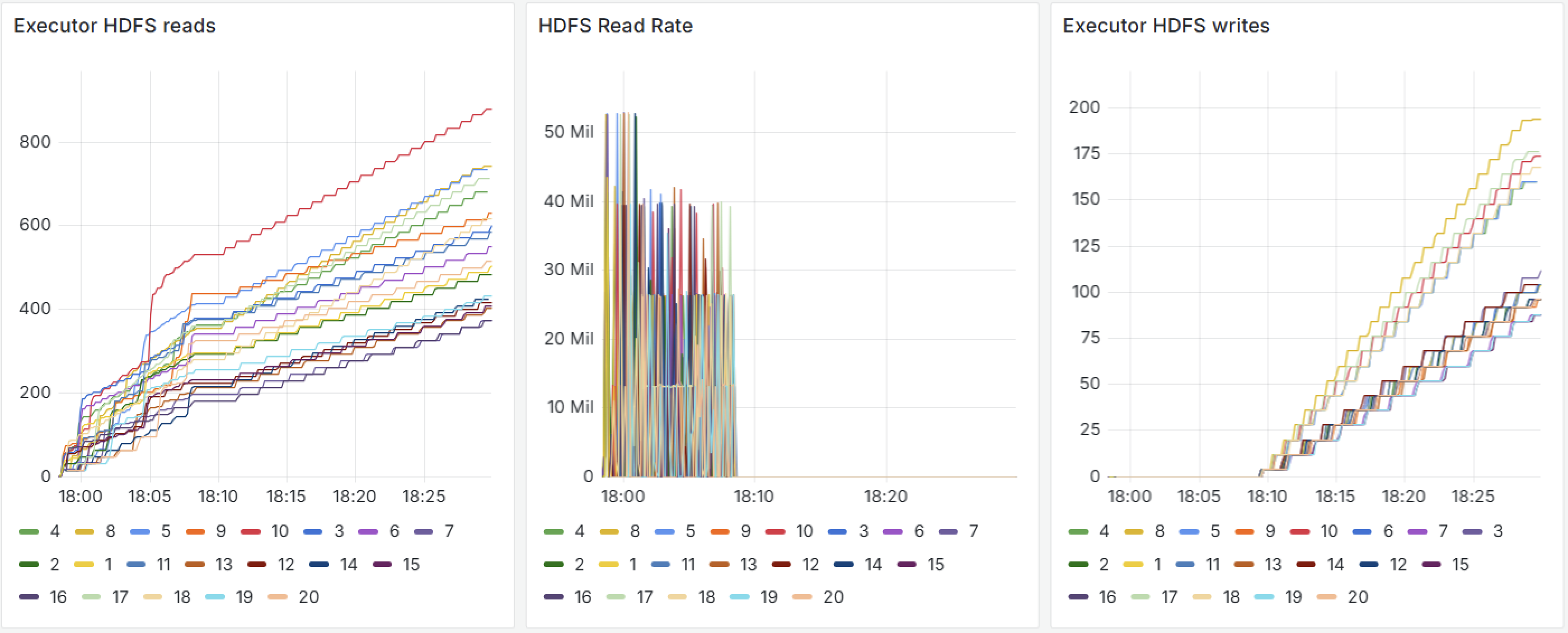
Рисунок 3 - Визуализация метрик input-output операций случайного приложения

Рисунок 4 - Визуализация метрик утилизации оперативной памяти случайного приложения
Практическая применимость разработанного решения подтверждается следующими наблюдениями:
- стабильная работа при высокой интенсивности поступления метрик (свыше 3000 приложений в сутки);
- снижение числа утраченных метрик за счет использования промежуточного брокера Kafka;
- повышению эффективности визуального анализа благодаря предварительной агрегации данных в ClickHouse и интеграции с системой визуализации.
Таким образом, разработанная архитектура демонстрирует высокую степень масштабируемости, устойчивость к нагрузке и пригодность для внедрения в промышленные системы мониторинга вычислительных процессов. Полученные результаты также создают предпосылки для построения надстройки в виде рекомендательной системы по оптимизации параметров Spark-приложений на основе анализа собранных вычислительных метаданных.
4. Заключение
В данной работе рассмотрена проблема оптимизации использования вычислительных ресурсов в Apache Spark-приложениях при обработке больших объемов данных в условиях кластерных вычислений. На основе анализа существующих решений в области мониторинга и анализа вычислительных метрик предложена интегрированная архитектура сбора, передачи и хранения метаинформации о вычислениях, направленная на повышение эффективности эксплуатации кластерных ресурсов.
Научная новизна исследования заключается в следующем:
- обоснован выбор метрик, отражающих ключевые характеристики ресурсопотребления и поведенческой логики Spark-приложений, включая информацию о DAG, spill, утилизацию памяти и узлов кластера;
- предложена архитектура отказоустойчивой системы сбора метрик с минимальной нагрузкой на вычислительные ресурсы кластера с использованием GraphiteSink и Logstash с маршрутизацией через Kafka в ClickHouse, что обеспечивает надежность, отказоустойчивость и масштабируемость системы;
- экспериментально определен и обоснован оптимальный интервал сбора метрик (10 секунд), обеспечивающий баланс между точностью наблюдений и снижением нагрузки на инфраструктуру хранения.
Реализация предложенной архитектуры позволяет сформировать устойчивую систему мониторинга и анализа, пригодную для интеграции в среду промышленных кластеров с высокой интенсивностью выполнения приложений. Система обеспечивает не только сбор, но и структурированное представление данных, пригодное для последующего автоматического анализа и визуализации.
В то же время работа имеет ряд ограничений, которые необходимо учитывать при дальнейшем развитии:
- в рамках исследования не проводилось формализованное сравнение производительности предложенного решения с существующими промышленными реализациями (например, Prometheus + Thanos);
- система предполагает единый протокол передачи метрик (UDP), что может потребовать дополнительных мер по обеспечению надежности при масштабировании;
- архитектура ориентирована на статический набор метрик и требует ручного обновления при изменении требований к мониторингу;
- агрегирование метрик на стороне ClickHouse требует тонкой настройки для конкретных сценариев анализа, особенно при построении сложных витрин.
В дальнейшем данную систему сбора и хранения метрик вычислений Spark-приложений можно будет использовать для построения систем автоматизированного анализа производительности Spark-приложений и принятия решений по их настройке.
Таким образом, представленная система может быть рассмотрена как универсальная основа для создания интеллектуальной инфраструктуры мониторинга и оптимизации вычислительных процессов в распределенных средах.