Development of a software module for parallel processing of spatial queries in PostgreSQL using .NET and PostGIS
Development of a software module for parallel processing of spatial queries in PostgreSQL using .NET and PostGIS
Abstract
The article presents the development of a software module for parallel processing of spatial queries in the PostgreSQL database management system with the PostGIS extension, implemented on the .NET platform. The solution is based on the Producer-Consumer pattern and a mechanism for caching results in GeoJSON format, which significantly reduces the load on the database management system and speeds up response times for repeated queries. The process of normalising SQL queries, generating hash codes using the SHA-256 algorithm, and forming output files is described. An analysis of existing solutions was carried out, and their limitations in the area of parallel query processing were identified. The results of testing on various spatial databases are presented, confirming the increase in system performance and scalability. The prospects for further development of the module are discussed, including distributed architecture, intelligent prediction of query frequency, and expansion of web interface functionality.
1. Введение
В современном мире геопространственные данные играют ключевую роль в различных областях, таких как транспорт, экология, урбанистика, логистика и управление природными ресурсами. С развитием технологий дистанционного зондирования Земли, GPS и Интернета вещей (IoT) объемы геоданных увеличиваются экспоненциально. Это создает необходимость в эффективных методах их обработки и анализа. Одной из наиболее популярных систем для работы с геопространственными данными является PostgreSQL с расширением PostGIS, которое предоставляет широкий набор функций для выполнения пространственных запросов
, , .PostGIS соответствует стандартам Open Geospatial Consortium (OGC) и поддерживает сложные операции: буферизацию, пересечения, вычисления площадей и расстояний
, . Преимуществами PostGIS являются полноценная поддержка требований ACID и транзакций, возможна интеграция с такими GIS-инструментами, как QGIS, GRASS, GeoServer.Однако, несмотря на свои возможности, традиционные подходы к обработке запросов могут не справляться с увеличивающимися нагрузками, особенно в условиях многопользовательской среды. Разработка модуля, который позволяет обрабатывать несколько запросов параллельно, может значительно повысить эффективность работы с пространственными данными.
Новизна работы заключается в создании программного компонента на базе .NET для интеграции с PostgreSQL, обеспечивающего параллельную обработку пространственных запросов. Данный подход позволит оптимизировать использование ресурсов системы, а также сократить время отклика на запросы, что особенно важно для пользователей, работающих с большими объемами пространственной информации. В то же время разработка программного компонента на базе .NET обеспечит простоту внедрения в существующие программные комплексы, что существенно расширяет круг потенциальных пользователей решения.
Целью данной работы является разработка программного модуля, обеспечивающего параллельную обработку множества пространственных запросов в системе управления базами данных PostgreSQL.
Задачи работы:
- исследование существующих аналогов;
- разработка программного модуля;
- тестирование и отладка разработанного модуля на реальных базах данных.
Внедрение разрабатываемого модуля позволит значительно увеличить пропускную способность существующих геоинформационных систем без замены системы управления базами данных, что особенно важно в условиях ограниченных бюджетов. Решение найдет применение в транспортной логистике, градостроительном планировании, экологическом мониторинге и других областях, где требуется обработка больших объемов пространственных данных в режиме реального времени. В связи с развитием технологий искусственного интеллекта, которые основаны на обработке больших данных, эти исследования и разработки особенно актуальны.
2. Анализ аналогов
При выборе подхода к параллельной обработке запросов важно понимать, какие решения уже существуют и какие ограничения они имеют. Давайте рассмотрим три ключевых инструмента, которые часто используются в связке с PostgreSQL, но не решают проблему параллелизма в полной мере.
1. Поддержка параллелизма в PostgreSQL. Начиная с версии 9.6 СУБД PostgreSQL стала поддерживать параллельное выполнение запроса, что значительно улучшает производительность при обработке больших объемов данных, однако архитектурные ограничения не позволяют выполнять параллельную обработку нескольких независимых запросов в рамках одного однопользовательского соединения. Это фундаментальное ограничение связано с моделью выполнения запросов, где каждое соединение обслуживается отдельным процессом, обрабатывающим запросы строго последовательно, для обеспечения согласованности данных и предсказуемости работы. Это обеспечивает стабильность и соблюдение ACID-свойств, но накладывает определенные ограничения на параллелизм
, .2. Pgpool-II — это промежуточное программное обеспечение для PostgreSQL, который позволяет администраторам управлять пулами соединений БД и реализовывать репликацию данных между серверами БД. Pgpool-II работает как прокси-сервер между клиентскими приложениями и серверами PostgreSQL, перехватывая запросы от клиентов и направляя их к соответствующим серверам БД согласно настроенным правилам и политикам
, . Однако PgPool-II имеет и некоторые минусы, такие как:- Дополнительный слой сложности: PgPool-II требует отдельной настройки и обслуживания как промежуточного прокси-сервера, что увеличивает инфраструктурные затраты. В то время как прямое управление соединениями через Npgsql в коде C# даёт полный контроль без зависимостей от внешних компонентов.
- Задержки для коротких запросов: для высоконагруженных сценариев с миллионами быстрых запросов PgPool-II может стать узким местом из-за накладных расходов на маршрутизацию. Прямые подключения через Npgsql минимизируют задержки.
3. PgAdmin и Dbeaver. Данные инструменты предоставляют удобные интерфейсы для работы с PostgreSQL с расширением PostGIS для работы с пространственными данными, но не поддерживают асинхронную параллельную обработку запросов. Данные программы в основном предназначены для синхронного выполнения запросов
, , что означает, что каждый запрос выполняется последовательно, и вы ждете завершения одного запроса, прежде чем отправить следующий.Как показал наш анализ, ни в одной из этих СУБД не реализованы технологии параллельной обработки запросов к базам данных.
3. Проектирование модуля
Проектная часть работы направлена на создание программного модуля, обеспечивающего параллельную обработку пространственных запросов в базу данных PostgreSQL. Основная цель — преодоление ограничений стандартных подходов к выполнению запросов в условиях высокой нагрузки и многопользовательского доступа.
Для полноценного представления работы программного модуля также будет проектироваться и разрабатываться упрощённая версия клиентской части системы «клиент-сервер», отображающая алгоритм работы со стороны обычного пользователя этой базы данных. Система «клиент-сервер» подразумевает использование клиент-серверной архитектуры — это модель организации вычислительных систем, в которой задачи распределены между клиентами и серверами. Основные компоненты:
- Клиенты — это устройства или приложения, которые запрашивают информацию или услугу у сервера. Клиенты могут быть как программными приложениями (например, веб-браузеры, мобильные приложения), так и аппаратными устройствами (например, смартфоны, планшеты, терминалы). В нашем случае клиентская часть системы будет отвечать за отправление запросов и визуализацию полученных ответов.
- Сервер — это компьютер, который предоставляет запрашиваемую информацию или услугу клиентам. Серверы могут выполнять различные функции, такие как хранение данных, обработка запросов, вычисления и т. д.
Для обеспечения повышенной производительности по сравнению с последовательным режимом работы, узким местом которого являются задержка и ожидание завершения работы над текущей задачей перед переходом к следующей, необходима бесперебойная работа системы, а именно параллельная асинхронная обработка запросов. Для достижения этой цели предлагается использовать такой паттерн, как «Производитель-Потребитель» — это шаблон проектирования, который организует параллельную обработку задач, разделяя систему на два ключевых компонента: производителей (producers) и потребителей (consumers). Производители — отвечают за генерацию данных или задач, помещают элементы в общий буфер или очередь. Потребители — отвечают за обработку данных или задач, извлекают элементы из общего буфера или очереди. Буфер/очередь — общая структура данных, которая выступает посредником между производителем и потребителем, хранит произведённые элементы до их потребления, обеспечивая баланс между скоростью их создания и обработки.
Несмотря на индивидуальность каждого пользователя и его причины для написания того или иного запроса к базе данных, есть не малая вероятность поступления одинаковых или же повторяющихся запросов, не обязательно идущих подряд. Они могут приходить с некими временными интервалами, будь то считанные секунды, минуты, а может и часы. По этой причине, а также и для достижения ещё большей производительности возникает необходимость кэширования результатов запросов. Кэширование представляет собой процесс хранения копий данных во временном хранилище (кэше) для быстрого доступа к ним в будущем. Таким образом, результат каждого запроса будет храниться в кэш-памяти сервера на протяжении заранее установленного времени, после которого будет удалён из кэш-памяти. При поступлении же этого запроса повторно до окончания этого промежутка времени, уже обработанный результат этого запроса будет немедленно передан клиенту без запроса к базе данных, при этом внутренний таймер данного запроса обновиться и отсчёт времени начнётся заново.
Для описания работы программы следует построить UML-диаграмму последовательности, но для начала давайте разберёмся, что она из себя представляет и как её читать. Диаграмма последовательности или же взаимодействия (interaction diagram) описывает взаимодействие групп объектов в различных условиях их поведения
, . Для написания нашей диаграммы последовательности понадобятся следующие элементы:- Объекты (участники): представлены прямоугольниками с названием. Каждый объект соответствует компоненту системы.
- Линии жизни: вертикальные пунктирные линии, показывающие период активности объекта.
- Сообщения: стрелки между линиями жизни, обозначающие передачу или вызов методов.
- Фрагменты взаимодействия: блоки, структурирующие логику. Мы будем использовать такие блоки как:
- «par» (параллельно) — обозначает параллельное выполнение операций.
- «alt» (альтернативно) — указывает на условные ветвления.
Исходя из этого мы можем построить UML диаграмму (рисунок 1).
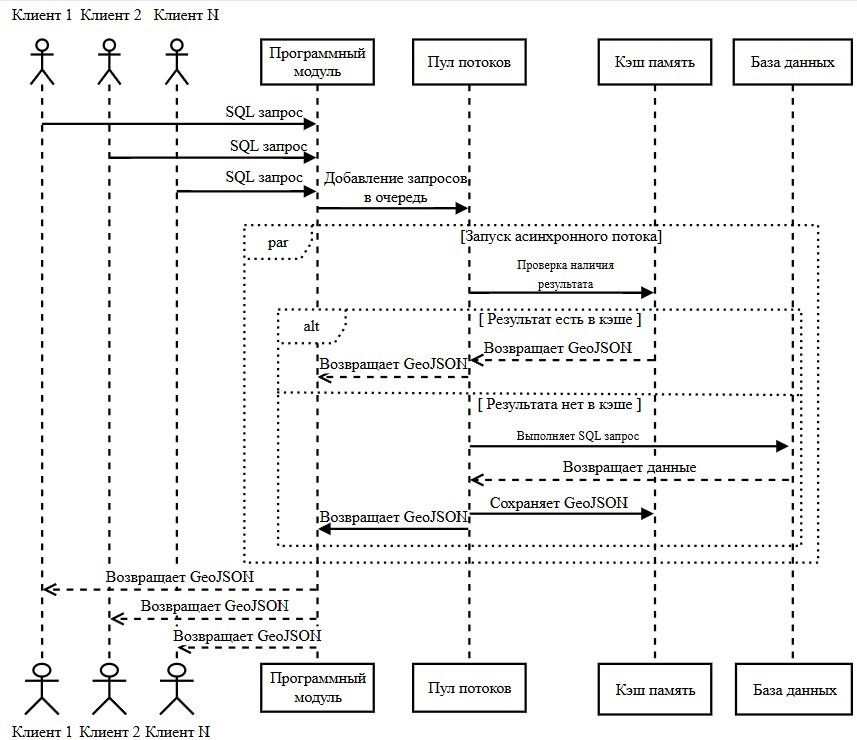
Рисунок 1 - Диаграмма последовательности алгоритма работы программы
Клиентские приложения (Клиент 1, Клиент 2 и Клиент N) инициируют работу системы, отправляя SQL запросы к пространственным данным. Пример пространственного SQL запроса представлен в листинге 1.
Листинг 1 — Пример пространственного SQL запроса
1SELECT a.name AS city1,
2 b.name AS city2,
3 ST_Distance(a.geom::geography, b.geom::geography) / 1000 AS distance_km,
4 ST_MakeLine(a.geom, b.geom) AS geom
5FROM public.ne_10m_populated_placesz8 a,
6 public.ne_10m_populated_placesz8 b
7WHERE a.name < b.name AND a.name ='Kazan' AND b.name ='Moscow'Подобные запросы поступают в программный модуль, который выступает центральным координатором системы. Важно отметить, что модуль принимает запросы от неограниченного количества клиентов одновременно, что подчёркивает масштабируемость решения.
Программный модуль выполняет критически важную функцию диспетчеризации — он не обрабатывает запросы самостоятельно, а распределяет их в пул потоков. Схематичное представление принципа работы пула потоков приведено на рисунке 2. Такой подход позволяет оптимально использовать вычислительные ресурсы сервера. Пул потоков обеспечивает истинную параллельность обработки — каждый запрос выполняется в отдельном потоке, при этом система автоматически балансирует нагрузку между доступными ядрами процессора.
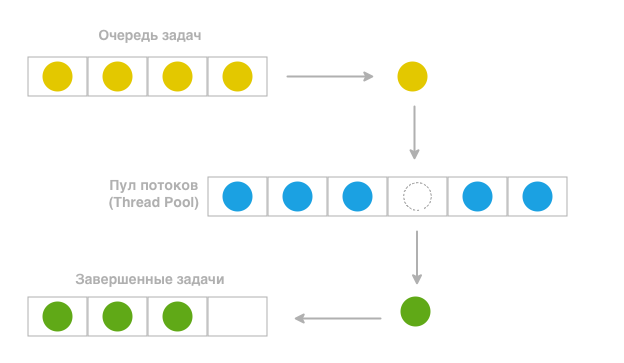
Рисунок 2 - Схема работы пула потоков
Таблица 1 - Примеры хэширования
Входные данные | Выход хэша |
Меня зовут Тоби | cacb5418163039b016be9746818a2926f68fd1e4bad1b04f6791f6aabb5e8c52 |
Меня зовут Тони | 9cd2444dc56929bdb97123add1f007643effa88bf1ed061eee1eead4e15ac7f9 |
Меня зовут Тоби, и это мой проект | 9abbaa0c54fcd028ac51bede2608d06e8d3a026784e34adfac14fadd143d212c |
На основе этого хэш-кода, как по ключу, происходит поиск готового результата в кэше. В результате этого поиска возможны два исхода:
1. Если результат найден, он выгружается из кэша и сохраняется в виде GeoJSON файла, пропуская этап с обращением к базе данных PostgreSQL + PostGIS и обработкой запроса.
2. Если совпадений по поиску нет — запрос выполняется в СУБД. Программа независимо взаимодействуют с СУБД PostgreSQL, расширенной функционалом PostGIS для работы с геоданными. Это взаимодействие включает выполнение пространственных запросов, например таких как расчёты расстояний, анализ пересечений географических объектов или выборки данных по пространственным критериям. После выполнения каждого запроса PostgreSQL возвращает результаты в табличном формате, которые дальше претерпевают преобразование полученных табличных данных в стандартизированный формат GeoJSON , , которые пул потоков передаёт обратно в основной программный модуль. Пример GeoJSON файла представлен в листинге 2.
Листинг 2 — Файл NewYork.geojson
1{
2 "type": "FeatureCollection",
3 "features": [
4 {
5 "type": "Feature",
6 "properties": {
7 "name": "New York City"
8 },
9 "geometry": {
10 "type": "Point",
11 "coordinates": [
12 -73.99571754361698,
13 40.72156174972766
14 ]
15 }
16 }
17 ]
18}Завершающая стадия работы системы включает кэширование полученного GeoJSON файла. Использование кэширования сокращает время отклика для повторяющихся запросов и снижает нагрузку на базу данных. После чего готовые результаты в удобном для клиентов виде возвращаются каждому из отправителей запросов. Выбор GeoJSON формата обусловлен тем, что он поддерживается большинством ГИС-платформ, веб-картографических сервисов (таких как Leaflet, OpenLayers, Mapbox) и мобильных приложений
, . Это обеспечивает простую интеграцию модуля с существующими системами без необходимости дополнительных преобразований данных на стороне клиента.Важно подчеркнуть, что вся обработка в потоках происходит асинхронно – клиенты получают результаты по мере готовности, без блокировки основного потока выполнения.
4. Реализация проекта
Основной задачей модуля является эффективная обработки множества запросов одновременно. Для этого была реализована система, основанная на паттерне «Производитель-Потребитель», где:
- производитель — мониторит директорию с SQL запросами и добавляет их в очередь;
- потребитель — представляет собой пул потоков, выполняющий запросы к базе данных.
Данный паттерн был реализован через механизмы библиотеки Task Parallel Library (TPL) и «BlockingCollection<Task>» в .NET, что обеспечивает потокобезопасную организацию очереди задач, а также позволяет эффективно распределять задачи между потоками, используя ресурсы процессора и задавать границы, ограничивая максимальную ёмкость коллекции
, . В рамках нашей реализации было ограничено количество одновременно выполняемых задач до 4. Производитель (листинг 3) реализован как цикл для мониторинга директории, который каждые 5 секунд вызывает функцию «ProcessAvailableQueriesAsync».Листинг 3 — Цикл для проверки новых запросов
1try {
2 while (!_cts.Token.IsCancellationRequested) {
3 await ProcessAvailableQueriesAsync(connectionString, queriesDirectory, outputDirectory);
4 await Task.Delay(5000, _cts.Token);
5 }
6}
7catch (OperationCanceledException) {
8 Console.WriteLine("Работа приложения прервана...");
9}
10finally {
11 _taskQueue.CompleteAdding();
12 await Task.WhenAll(consumers);
13}
Метод «ProcessAvailableQueriesAsync» (листинг 4) в свою очередь сканирует директорию с SQL запросами и создаёт задачи обработки, которые добавляются в очередь через «_taskQueue.Add()».
Листинг 4 — Метод «ProcessAvailableQueriesAsync»
1static async Task ProcessAvailableQueriesAsync(string connectionString, string queriesDirectory, string outputDirectory)
2{
3 var queryFiles = Directory.GetFiles(queriesDirectory, "*.sql");
4 if (queryFiles.Length == 0) return;
5 Console.WriteLine($"\nНайдено {queryFiles.Length} SQL-файлов для обработки");
6 foreach (var filePath in queryFiles)
7 {
8 _taskQueue.Add(ProcessSingleQueryFileAsync(connectionString, filePath, outputDirectory));
9 }
10}Метод «.GetFiles()» в нашем коде принимает два параметра:
- путь к директории, который является обязательным параметром;
- шаблон поиска или же фильтр — параметр, позволяет фильтровать файлы по конкретным критериям, в данном случае по расширению файла «.sql».
Потребители (листинг 5) реализованы как пул из определённого числа фоновых задач (число задач устанавливается администратором), запускаемых через «Task.Run», которые, в свою очередь, непрерывно извлекают и выполняют задачи из очереди с помощью метода «GetConsumingEnumerable()», обеспечивая параллельное выполнение заданного числа запросов одновременно.
Листинг 5 — Потребитель задач
1consumers[i] = Task.Run(async () =>
2{
3 foreach (var task in _taskQueue.GetConsumingEnumerable())
4 {
5 try
6 {
7 await task;
8 }
9 catch (Exception ex)
10 {
11 Console.WriteLine($"Ошибка при выполнении задачи: {ex.Message}");
12 }
13 }
14});Нормализация SQL запросов и генерация хэша — критически важные этапы для корректной работы кэширования. Давайте рассмотрим их более подробно.
Нормализация запросов — это процесс приведения SQL запроса к унифицированному формату, который позволяет идентифицировать семантически идентичные запросы, даже если они имеют синтаксические различия
, . Это критически важно для корректной работ кэша, так как два логически одинаковых запроса с разными пробелами, регистром или переносами строк должны генерировать одинаковый ключ, а именно хэш-код.Процесс нормализацию в свою очередь состоит из нескольких ключевых операций:
4.1. Удаление лишних пробелов и переносов строк
Любой SQL запрос может содержать случайные пробелы, табуляции или переносы строк, которые не оказывают никакого влияния на его смысл, но делают его уникальным для системы. Для примера рассмотрим два SQL запроса с незначащими пробелами и без незначащих пробелов (листинг 6):
Листинг 6 — Примеры запросов
1-- запрос с незначащими пробелами
2SELECT * FROM cities WHERE population > 1000000;
3
4-- запрос без незначащих пробелов
5SELECT * FROM cities WHERE population > 1000000;Фактически это два одинаковых запроса, результаты обработки которых будут полностью идентичны, однако технически эти запросы различаются. Что приводит к излишней нагрузке системы и соответственно снижению производительности, которой можно было бы избежать. Для этого следует предпринять следующие действия:
- все последовательности пробелов заменить на один пробел;
- специальные управляющие последовательности (escape sequences), которые используются для записи пробельных (непечатных) символов (whitespace characters), а именно символы переноса строк «\r\n», «\n» и табуляции «\t» заменяются на один пробел;
- удаляются пробелы в начале и конце строки (для выполнения данной операции существует метод «.Trim()»).
Код реализующий эти действия представлен в листинге 7, где используется метод «Replace» класса «Regex», а также одноимённый метод, но и из класса «String». Использование метода «Regex.Replace()» с регулярным выражением «\s+» гарантирует, что между словами всегда будет не более одного пробела.
Листинг 7 — Удаление лишних пробелов и переносов строк
1string normalizedQuery = Regex.Replace(
2 query
3 .Replace("\r\n", " ")
4 .Replace("\n", " ")
5 .Replace("\t", " "), // Замена табуляции
6 @"\s+", // Шаблон для любых пробельных символов
7 " " // Замена на один пробел
8).Trim(); // Удаление пробелов по краям4.2. Приведение к нижнему регистру
SQL запросы нечувствительны к регистру ключевых слов, таких как SELECT, FROM, WHERE и другие, то есть такие слова как SELECT и select являются эквивалентными. Приведение к нижнему регистру стандартизирует запросы, уменьшая количество всевозможных уникальных запросов и тем самым значительно снижая количество хранимых в кэш-памяти файлов-дубликатов с результатами одних и тех же запросов
, . Для примера рассмотрим 2 запроса представленных в листинге 8, в нём приведён SQL запрос до приведения к нижнему регистру и после.Листинг 8 — Примеры запросов с разными регистрами
1-- Пример запроса до приведения к нижнему регистру
2SELECT Name FROM Cities;
3
4-- Пример запроса после приведения к нижнему регистру
5Select name from cities;Однако стоит учесть, что это не затрагивает строковые литералы и идентификаторы в кавычках (например WHERE name = «Москва»), что важно для сохранения семантики. То есть запросы, где текст внутри кавычек написан в нижнем регистре и в верхнем регистре не будут считаться идентичными, а значит и результаты этих запросов могут отличаться, в зависимости от того был ли предусмотрен данный аспект в базе данных (листинг 9).
Листинг 9 — Пример запроса с нижним регистром
1-- Пример запроса с нижним регистром в кавычках
2SELECT * FROM Cities WHERE name = «Kazan»;
3
4-- Пример запроса с верхним регистром в кавычках
5SELECT * FROM Cities WHERE name = «KAZAN»;4.3. Удаление комментариев
Комментарии в SQL запросах — это текстовые пояснения, которые игнорируются СУБД при выполнении, но могут влиять на уникальность хэша запроса. Например, два семантически одинаковых запроса с разными комментариями будут считаться разными, что приведёт к промахам кэша и избыточной нагрузке на БД. Удаление комментариев – важный этап нормализации для обеспечения корректной работы системы кэширования.
Примеры запросов до нормализации и после нормализации представлены в листингах 10 и 11 соответственно.
Листинг 10 — Пример запроса до нормализации
1SELECT a.name AS city1, -- Москва
2 b.name AS city2, -- Нью Йорк
3 ST_Distance(a.geom::geography, b.geom::geography) / 1000 AS distance_km, -- подсчёт расстояния между двумя объектами a и b
4 ST_MakeLine(a.geom, b.geom) AS geom /* для создания линии
5 между этими двумя точками */
6FROM public.ne_10m_populated_placesz8 a,
7 public.ne_10m_populated_placesz8 b
8
9WHERE a.name < b.name AND a.name ='Moscow' AND b.name ='New York'Листинг 11 – Запрос после нормализации
1select_a.name_as_city1,_b.name_as_city2,_st_distance(a.geomgeography,_b.geomgeography)_1000_as_distance_km,_st_makeline(a.geom,_b.geom)_as_geom_from_publi
2c.ne_10m_populated_placesz8_a,_public.ne_10m_populated_placesz8_b_where_a.name_b.name_and_a.name_='moscow'_and_b.name_='new_york'Далее будет описан процесс по генерации хэш-кода запроса.
Генерация хэш-кода — завершающий этап подготовки SQL запроса к кэшированию. Этот процесс преобразует нормализованную строку запроса в уникальный идентификатор, который используется для быстрого поиска результатов в кэше. Основная задача хэш-функции — обеспечить минимальную вероятность коллизий (ситуаций, когда разные запросы получают одинаковый хэш) при сохранении высокой производительности.
Для кодирования был выбран алгоритм SHA-256 в качестве основы для генерации хэш-кода. Причина такого выбора обусловлена криптографической устойчивостью и широкому применению в современных системах. SHA-256 преобразует входные данные в 256-битный (32-байтовый) хэш, который практически исключает вероятность коллизии для различных входных строк. Такой подход сокращает объём полезных данных и ускоряет сравнение ключей, сохраняя при этом достаточный уровень уникальности.
Сам же процесс генерации хэш-кода начинается с преобразования полученной ранее нормализованной строки запроса в массив байтов с использованием кодировки UTF-8. Для выполнения данного преобразования используется метод «Encoding.UTF8.GetBytes(normalizedQuery)», где «normalizedQuery» — это строка полученная после всех этапов нормализации. Затем для полученного массива байтов вычисляется хэш-сумма с помощью метода «ComputeHash» экземпляра «sha256». Полученный массив «hashBytes»преобразуется в строку с помощью метода «BitConverter.ToString(hashBytes, 0, 8)». Входными параметрами данного метода являются:
- «hashBytes» — массив байтов;
- «0» — индекс символа начала строки;
- «8» — длина строки, которую мы хотим получить.
Выходным параметром является строка в шестнадцатеричном формате, разделённая дефисами. В дальнейшем для удаления этих дефисов мы применим метод с заданными входными параметрами «Replace(“-”, “”)», в результате чего получим непрерывную шестнадцатеричную строку, однако, чтобы уменьшить количество возможных вариантов и тем самым оптимизировать скорость проверки кэш на поиск файлов с этим же хэш-кодом, мы приведём все символы к нижнему регистру с помощью метода «ToLower()». В результате всех этих преобразований мы получим уникальный идентификатор для каждого запроса — хэш-код. Полный листинг функции по генерации хэш-кода представлен в листинге 12.
Листинг 12 — Генерация хэш-кода
1string hashString;
2using (var sha256 = SHA256.Create())
3{
4 byte[] hashBytes = sha256.ComputeHash(Encoding.UTF8.GetBytes(normalizedQuery));
5 hashString = BitConverter.ToString(hashBytes, 0, 8).Replace("-", "").ToLower();
6}Сгенерированный хэш-код используется как часть имени файла для сохранения результатов в формате GeoJSON, что гарантирует, что повторяющиеся запросы будут ссылаться на один и тот же файл, даже если исходный текст запроса отличался незначительными синтаксическими вариациями. А с учётом того, что данный GeoJSON также будет храниться в кэше, то хэш-код, записанный в имени этого файла, будет служить ключом для проверки был ли уже выполнен данный запрос ранее.
Что же касается остальной части имени каждого GeoJSON файла, то она формируется из уже полученной нами нормализованной строки. Данная строка обрезается до 100 символов, из неё удаляются недопустимые символы, которые нельзя использовать при переименовании файла, а пробелы заменяются на подчёркивания. Описанное преобразование обеспечивает читаемость имени файла и добавляет дополнительный уровень защиты от конфликтов, например «использование недопустимых символов при переименовании файла». Для примера рассмотрим запрос, представленный в листинге 13.
Листинг 13 — Пример SQL запроса
1select *
2from public.ne_10m_populated_placesz8
3where public.ne_10m_populated_placesz8.name='Kazan'Этот запрос выбирает все поля для объекта из таблицы «ne_10m_populated_placesz8» из схемы «public», где поле «name» принимает значение «Kazan». Путём описанных выше преобразований мы получаем следующее имя для этого файла:
select_from_public.ne_10m_populated_placesz8_where_public.ne_10m_populated_placesz8.name_=_'Kazan'_51f3ca9b69a80c00
Полный код этого ключевого элемента отвечающий и за нормализацию и за генерацию хэш-кода, а также за формирование имени файла представлен в листинге 14. В этом элементе также используется функция «RemoveCommentsOptimized», отвечающая за удаление комментариев всех видов. На этом моменте реализация второго ключевого элемента отвечающего за нормализацию и генерацию хэша, а также за формирование имени выходного файла завершается.
Листинг 14 — Функция нормализации и генерации хэша
1static string GenerateGeoJsonFileName(string query, string outputDirectory) {
2 string withoutComments = RemoveCommentsOptimized(query);
3 string normalizedQuery = Regex.Replace(
4 withoutComments.Replace("\r\n", " ").Replace("\n", " ").Replace("\t", " "),@"\s+"," ").Trim().ToLower();
5 string hashString;
6 using (var sha256 = SHA256.Create())
7 {
8 byte[] hashBytes = sha256.ComputeHash(Encoding.UTF8.GetBytes(normalizedQuery));
9 hashString = BitConverter.ToString(hashBytes, 0, 8).Replace("-", "").ToLower();
10 }
11 string safeQueryName = new string(normalizedQuery.Where(c => !Path.GetInvalidFileNameChars().Contains(c)).ToArray()).Replace(" ", "_").Replace("__", "_").Trim('_');
12 safeQueryName = safeQueryName.Length > 100 ? safeQueryName.Substring(0, 100) : safeQueryName;
13 string fileName = $"{safeQueryName}_{hashString}.geojson";
14 return Path.Combine(outputDirectory, fileName);
15}Взаимодействие с базой данных обязательный элемент данного программного модуля. Осуществляться оно будет с помощью библиотеки Npgsql, которая предоставляет асинхронные методы для выполнения запросов и работы с геопространственными данными. Также будет использоваться расширение «NetTopologySuite», интегрированное в «Npgsql». Данное расширение позволяет преобразовывать результаты запросов в пространственные объекты типа «Geometry» (точки, линии, полигоны), которые затем сериализуются в формат GeoJSON. Выполняться весь процесс взаимодействия будет в рамках метода «ExecuteQueryToGeoJsonAsync», входными параметрами которого являются строка подключения к базе данных и сам SQL запрос, а выходным параметром результант запроса в формате GeoJSON файла.
Настройка подключения начинается с создания экземпляра «NpgsqlDataSourceBuilder», где указывается строка подключения к базе данных:
Host=localhost;Username=postgres;Password=123;Database=DatabaseName
В данной строке указывается адрес сервера, в данном случае это локальный хост, имя пользователя для подключения к базе данных — «postgres», пароль пользователя — «123» и название конкретной базы данных — «DatabaseName», к которой происходит подключение.
После создания экземпляра и подключения к базе данных вызывается метод «UseNetTopologySuite()» из ранее упомянутого расширения для активации поддержки геопространственных типов данных PostGIS. Далее нужно обеспечить выполнение асинхронного подключения к базе данных, для этого будет использован метод «OpenConnectionAsync()», что позволяет не блокировать основной поток при ожидании ответа от СУБД. Установка «CommandTimeout = 300» гарантирует, что запросы длительностью до 300 секунд не будут прерваны раньше времени. Данную настройку следует изменить в зависимости от размеров базы данных и сложности запросов, в связи с чем она может настраиваться индивидуально для каждой базы данных.
После успешного выполнения запроса происходит чтение результата с помощью «NpgsqlDataReader», который последовательно обрабатывает каждую строку результата, и в цикле с помощью «await reader.ReadAsync()» извлекаются значения из столбцов. Если столбец содержит геометрию, то есть является типом «Geometry», то значения данного столбца сохраняются отдельно для последующего преобразования в GeoJSON, все остальные атрибуты добавляются в коллекцию свойств «properties» объекта.
Преобразование результатов в GeoJSON выполняется с использованием метода «Wrtie(geometry)» класса «GeoJsonWriter» из «NetTopologySuite». Данный метод сериализует геометрию в JSON-совместимый формат, а благодаря «JsonSerializer» из класса «Systems.Text.Json» собирает полный объект «FeatureCollection» – объект JSON, содержащий коллекцию функцию GeoJSON.
Настройка «UnsafeRelaxedJsonEscaping» отключает экранирование символов, то есть замена в тексте управляющих (служебных) символов на соответствующие им последовательности символов, что важно для корректного отображения координат в веб-клиентах.
Также для представления полной картины взаимодействия с базой данных с клиентской стороны был реализован небольшой сайт способный отправлять SQL запросы и принимать GeoJSON результаты, при этом визуализируя их на карте мира.
Алгоритм действий для работы с сайтом следующий:
Рисунок 3 - Домашняя страница сайта
Рисунок 4 - Страница регистрации
Рисунок 5 - Страница для входа в аккаунт
Листинг 15 — Пример пространственного SQL запроса
1select *
2from public."ne_10m_admin_1 z8"
3where public."ne_10m_admin_1 z8".name='Grodno'
Рисунок 6 - Страница для обработки запросов

Рисунок 7 - Визуализация результата SQL запроса
Рисунок 8 - Список свойств выбранного объекта
5. Тестирование
Разработанный программный модуль был протестирован на производительность и корректность работы ключевых компонентов. Основное внимание уделялось проверке параллельной обработке запросов и эффективности кэширования. Для тестирования были использованы различные базы данных PostgreSQL с расширением PostGIS, а именно:
- База данных «NaturalEarth» содержащая информацию о городах, водоёмах, островах и многих других объектах планеты Земля. Источником этих данных является электронный ресурс «Natural Earth». Общий вес базы данных составляет 193 МБ.
- База данных «Volga-fed-district» содержащая значительные объёмы пространственные данных Приволжского федерального округа. Источником этих данных является электронный ресурс «download.geofabrik.de» предоставляющий свободный доступ к пространственным данным OpenStreetMap. Общий вес базы данных составляет 4138 МБ.
Для тестирования производилась практически единовременная отправка 20 запросов, в которых было 3 разных повторяющихся запроса. Запросы относились к разным данным из разных таблиц для каждой базы данных. При этом перед тестированием был выполнен 1 запрос для установления корректного подключения к базе данных, данный запрос не повторялся ни с одним из запросов, которые использовались для тестов.
Результаты этих тестов следующие:
1. Для базы данных «NaturalEarth». Время выполнения уникальных запросов составляет в среднем 214 миллисекунд на запрос, что превышает показатели последовательного режима обработки запросов (в среднем 127 миллисекунд на запрос) из-за дополнительных операций нормализации, генерации хэш-кода и управления потоками. Однако следует учитывать, что общее время последовательных запросов равно сумме времени выполнения всех запросов, в то время как в параллельном режиме работы общее время обработки всех запросов значительно ниже и практически равна времени обработки самого долгого процесса. Таким образом, за время выполнения в среднем 2–3 последовательных запроса, в параллельном же режиме уже успеют обработаться большая часть всех запросов, а при повышении вероятности повторяющихся запросов этот процесс в параллельном режиме будет выполняться ещё быстрее, так как вместо тех же 214 миллисекунд на обработку запроса результат, которого имеется в кэше, затрачивается всего 5 миллисекунд.
2. Для базы данных «Volga-fed-district». Время выполнения 20 запросов разной степени сложности с 3 повторяющимися запросами в последовательном режиме суммарно составляет 14,802 секунды, в то время как выполнение этих же запросов в параллельном режиме, то есть при практически одновременной отправке этих запросов через сайт, в среднем происходит за 5,365 секунд. Это подтверждает эффективность реализации параллелизма и кэширования: повторяющиеся запросы, результаты которых уже находились в кэше, обрабатывались мгновенно, а распределение нагрузки между потоками позволило сократить общее время выполнения в 2,76 раза. Максимальное время обработки одного сложного запроса в параллельном режиме составило 5,565 секунды, что свидетельствует о корректной работе системы с ресурсоёмкими операциями.
Результаты демонстрируют, что модуль успешно масштабируется для работы с большими объёмами данных, обеспечивая стабильную производительность даже при высокой нагрузке.
6. Заключение
В ходе проведённой работы была разработана программная система для параллельной обработки пространственных запросов в системе управления базами данных PostgreSQL с использованием расширения PostGIS и платформы .NET. Предложенное решение основано на применении паттерна «Производитель-Потребитель» в сочетании с механизмом кэширования результатов в формате GeoJSON, что позволило существенно снизить нагрузку на базу данных и обеспечить высокую скорость отклика при повторных обращениях.
Проведённое тестирование показало, что разработанный модуль демонстрирует высокую масштабируемость и стабильную производительность даже при интенсивном потоке запросов. Для крупных наборов пространственных данных удалось сократить общее время обработки более чем в два раза по сравнению с последовательным режимом, а при высоком количестве повторяющихся запросов производительность возрастала ещё значительнее благодаря мгновенной выдаче уже кэшированных результатов.
К числу основных достоинств разработанной системы относится возможность интеграции в существующую инфраструктуру без замены используемой базы данных, поддержка большого числа одновременных клиентских подключений, использование универсального формата передачи данных GeoJSON, обеспечивающего совместимость с популярными геоинформационными платформами и веб-сервисами, а также оптимизация работы за счёт нормализации запросов и предотвращения избыточных вычислений.
Перспективы дальнейшего развития решения заключаются в создании распределённой архитектуры, обеспечивающей ещё более высокую пропускную способность и отказоустойчивость; внедрении алгоритмов интеллектуального анализа данных, позволяющих прогнозировать частоту запросов и заранее формировать кэш; расширении возможностей веб-интерфейса с реализацией визуального построения пространственных запросов; совершенствовании системы хранения кэша с применением высокопроизводительных технологий и механизмов репликации; внедрении гибкой приоритезации запросов в зависимости от их значимости; создании подсистемы мониторинга и аналитики, позволяющей отслеживать производительность, выявлять узкие места и адаптировать параметры работы модуля в зависимости от текущей нагрузки.
Таким образом, разработанное решение не только обеспечивает значительное ускорение обработки пространственных запросов, но и формирует основу для построения масштабируемых геоинформационных систем, способных эффективно функционировать в условиях постоянного роста объёмов геоданных и ужесточения требований к скорости их анализа.