EXTRACTION OF FORMANTS AND OTHER CHARACTERISTICS AND CLASSIFICATION OF VOICE HEALTH STATUS BY MACHINE LEARNING METHODS
EXTRACTION OF FORMANTS AND OTHER CHARACTERISTICS AND CLASSIFICATION OF VOICE HEALTH STATUS BY MACHINE LEARNING METHODS
Abstract
This article is devoted to the development and analysis of machine learning methods for the automated diagnosis of voice disorders, which is an urgent task in modern medicine and speech therapy. Voice plays a key role in communication, and its pathologies can significantly reduce the quality of life of patients. Traditional diagnostic methods, including visual examination and endoscopy, require the participation of specialists and do not always ensure objectivity. In this regard, the use of machine learning algorithms opens up new opportunities for improving the accuracy of speech disorders detection and diagnosis. The paper examines the main types of voice disorders, including dysphonia, aphonia, phonasthenia, bradylalia, tachylalia, stuttering, dyslalia and rhinolalia. The etiology, symptoms, and existing correction methods are analyzed for each of them. Special attention is paid to acoustic parameters of the voice, such as pitch frequency, jitter, shimmer, and signal-to-noise ratio, which can serve as markers of pathologies.
1. Введение
Голос является одним из основных инструментов коммуникации человека, и его нарушения могут значительно повлиять на качество жизни, социальную адаптацию и профессиональную деятельность. Традиционные методы диагностики нарушений голоса, такие как визуальная оценка и эндоскопия гортани, требуют участия опытных специалистов и могут быть субъективными. Однако с развитием технологий машинного обучения , , появились новые возможности для автоматизации процесса диагностики, что позволяет повысить точность и объективность оценки.
Цель данной работы — исследование методов машинного обучения, применимых для выявления нарушений голоса. В рамках исследования были поставлены следующие задачи: рассмотреть основные виды нарушений голоса, выявить ключевые параметры голоса, которые могут быть использованы для анализа, разработать методику эксперимента и исследовать эффективность различных алгоритмов машинного обучения для классификации нарушений голоса.
2. Виды нарушений голоса
Нарушения голоса могут быть вызваны различными причинами, включая механические повреждения голосового аппарата, воспалительные процессы, гормональные изменения, а также психосоматические заболевания. В зависимости от характера и степени выраженности, нарушения голоса делятся на несколько видов :
1. Дисфония — это нарушение голоса, которое проявляется в изменении тембра, высоты тона и громкости. Дисфония может быть вызвана усталостью голосовых связок, стрессом, аллергиями или инфекциями. Симптомы включают хрипоту, изменение тембра и трудности при произношении слов.
2. Афония — полная или частичная потеря голоса. Человек с афонией может говорить только шепотом или издавать прерывистые звуки. Причины афонии включают воспаление гортани, травмы, инфекции или опухоли.
3. Фонастения — нарушение, связанное с дискоординацией работы дыхательного, артикуляционного и фонационного аппаратов. Проявления фонастении включают быстрое утомление голоса, дрожание, прерывание речи и снижение силы голоса.
4. Брадилалия и тахилалия — нарушения, связанные с изменением скорости речи. Брадилалия характеризуется замедленной речью, а тахилалия — ускоренной. Оба состояния могут затруднять коммуникацию и приводить к непониманию со стороны окружающих.
5. Заикание — нарушение, при котором человек испытывает трудности при произношении слов или фраз. Заикание может сопровождаться повторением звуков, слов или длинными паузами. Это нарушение может оказывать значительное влияние на социальную и эмоциональную жизнь человека.
6. Дислалия — нарушение звукопроизношения, при котором человек заменяет, искажает или смешивает звуки. Это может быть вызвано недостатком обучения или снижением слуховой восприимчивости.
7. Ринолалия — нарушение произношения, связанное с физиологическими дефектами речевого аппарата, такими как недостаточное закрытие небных дуг. Ринолалия проявляется в изменении тембра голоса, который становится гнусавым.
3. Диагностика нарушений голоса
Диагностика , нарушений голоса включает несколько этапов. Для дисфонии и афонии используются голосовые тесты и эндоскопия гортани, которые позволяют оценить состояние голосовых связок. Для диагностики фонастении применяются неврологические тесты и анализ речи. Брадилалия и тахилалия диагностируются с помощью оценки скорости речи и произношения звуков. Заикание выявляется с помощью специальных тестов, таких как чтение текста или акустический анализ речи. Для диагностики дислалии и ринолалии используются методы анализа звукопроизношения и аудиологические исследования.
4. Лечение нарушений голоса
Лечение нарушений голоса зависит от их типа и причин. Для дисфонии и афонии часто применяются упражнения для укрепления голосовых связок, дыхательные техники и изменение высоты голоса. Фонастения лечится с помощью логопедической терапии, направленной на улучшение координации работы голосового аппарата. Брадилалия и тахилалия требуют терапии, направленной на нормализацию скорости речи. Заикание лечится с помощью психологической поддержки, техник управления стрессом и упражнений на улучшение дыхания и речи. Для дислалии и ринолалии применяются логопедические упражнения и, в некоторых случаях, хирургические методы.
5. Параметры голоса и акустический анализ
Голос представляет собой сложный акустический сигнал, который можно разложить на ряд параметров, отражающих его свойства. Основные параметры голоса включают:
– Частота общего тона (ЧОТ) , — основная частота колебания голосовых связок. ЧОТ зависит от пола, возраста и эмоционального состояния человека. Обычно женский голос имеет частоту 180–250 Гц, а мужской — 100–130 Гц. Вычисляется с помощью дискретного преобразования Фурье (ДПФ).
– Форманты , — акустические характеристики звука, которые определяют тембр и разборчивость речи. Они представляют собой резонансные частоты голосового тракта. Представлены на рисунке 1.
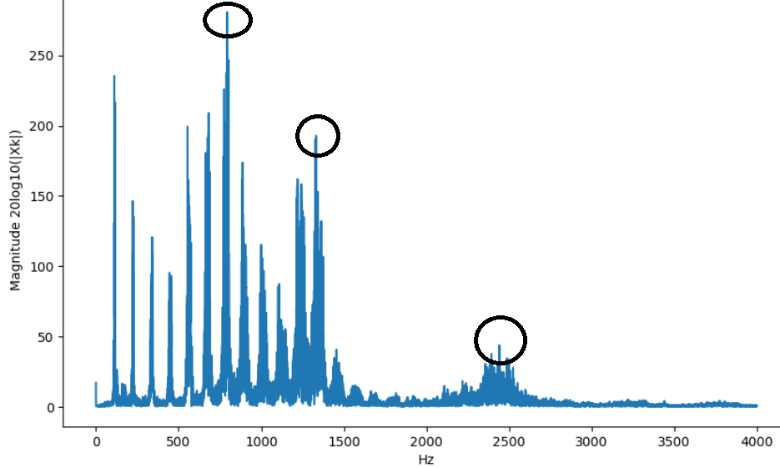
Рисунок 1 - Частотные характеристики голоса
Примечание: слева направо выделены пики — форманты
где N – количество периодов основного тона;
Ti – длина периода основного тона.
– Shimmer , — изменение амплитуды голоса во времени. Shimmer также измеряется в процентах и указывает на вариабельность громкости голоса. Вычисляется по формуле 2. Точки для вычисления Shimmer`а видно на рисунке 2.
где N – количество периодов основного тона;
Ai – Амплитуда пика основного тона.
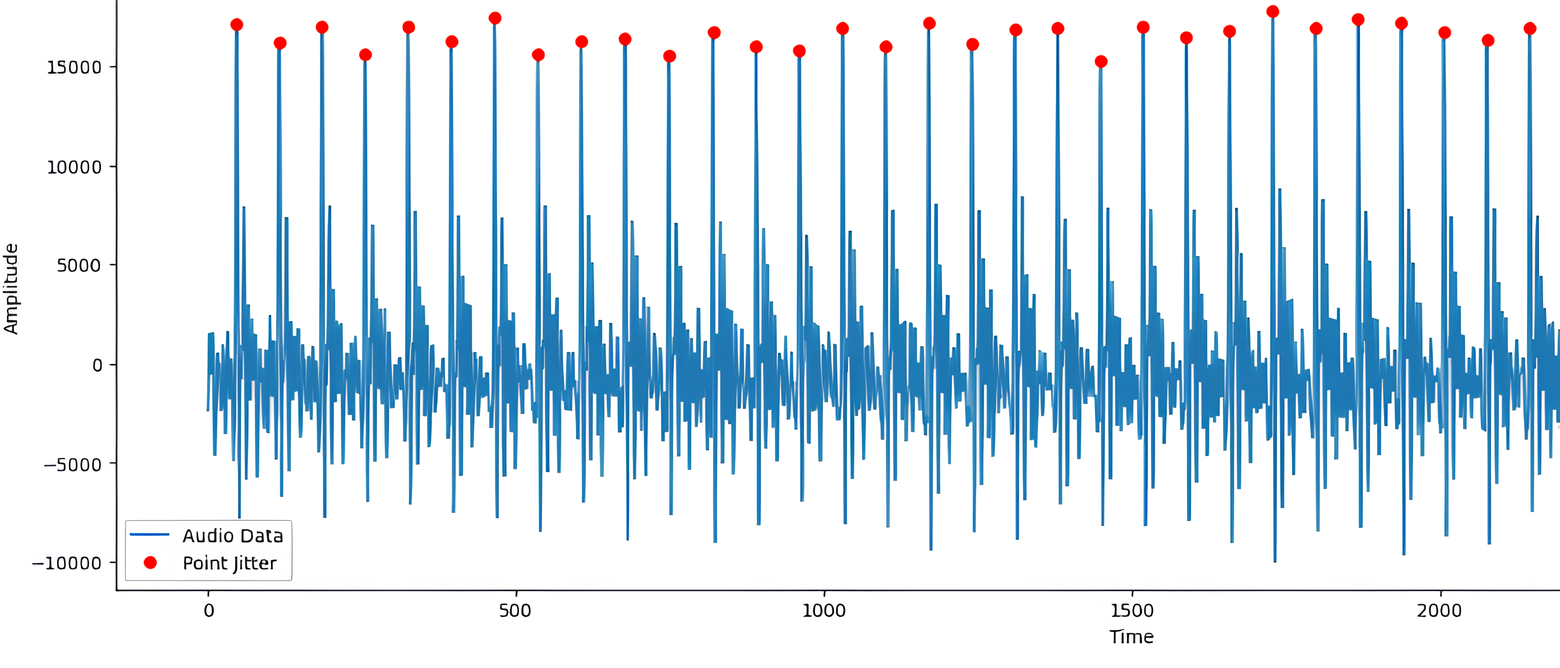
Рисунок 2 - Аудиозапись голоса
Примечание: точками отмечены периоды и амплитуды основного тона
Акустический анализ голоса позволяет извлекать эти параметры и использовать их для диагностики нарушений. Например, повышенный уровень Jitter и Shimmer может указывать на наличие дисфонии или афонии.
6. Методология эксперимента
Для анализа нарушений голоса использовалась база данных VOICED , содержащая записи голоса 208 человек, из которых 58 были здоровыми, а 150 — с патологиями. Для извлечения параметров голоса использовались библиотеки языка программирования Python , такие как Numpy , Librosa . Эти библиотеки позволяют анализировать аудиозаписи и извлекать такие параметры, как ЧОТ, Jitter и Shimmer, форманты. Пример извлеченных параметров, для обучения моделей машинного обучения, представлен на рисунке 3.

Рисунок 3 - Пример таблицы параметров
7. Существующие подходы машинного обучения
Для классификации нарушений голоса были рассмотрены различные алгоритмы машинного обучения , , :
1. Метод k-ближайших соседей (KNN) — алгоритм, который классифицирует объекты на основе majority vote среди k-ближайших соседей в пространстве признаков. KNN не строит явную модель, но требует хранения всех обучающих данных. Эффективен для задач с четкой кластерной структурой.
2. Линейная регрессия (Linear Regression) — алгоритм для задач регрессии, который строит линейную зависимость между целевой переменной и входными признаками, минимизируя сумму квадратов ошибок. Позволяет оценить важность признаков через коэффициенты.
3. Стохастический градиентный спуск (SGDClassifier) — алгоритм оптимизации, используемый для обучения линейных моделей (логистической регрессии, SVM и др.). Обновляет веса на небольших пакетах данных, что делает его эффективным для больших наборов данных.
4. Логистическая регрессия — алгоритм, используемый для бинарной классификации. Он моделирует связь между входными признаками и вероятностью принадлежности к классу.
5. Дерево решений — алгоритм, который строит структуру в виде дерева для классификации или регрессии. Каждый узел дерева представляет признак, а ветви — возможные значения.
6. Случайный лес — ансамбль деревьев решений, который строит множество моделей и усредняет их прогнозы. Случайный лес снижает риск переобучения и повышает устойчивость к шуму в данных.
7. Градиентный бустинг — метод, который последовательно строит слабые модели для исправления ошибок предыдущих. К этой категории относятся такие алгоритмы, как LightGBM, CatBoost и XGBoost.
8. Результаты анализа
Наиболее эффективными оказался метод линейной классификации: логистическая регрессия, который показали точность 70%. Наименее эффективными были дерево решений (56%). Анализ важности признаков показал, что наиболее значимыми параметрами для классификации являются Shimmer, Jitter (рисунок 4). Использовалась метрика accuracy, также все модели показывали одинаковую метрику AUC-ROC, равную 60%.
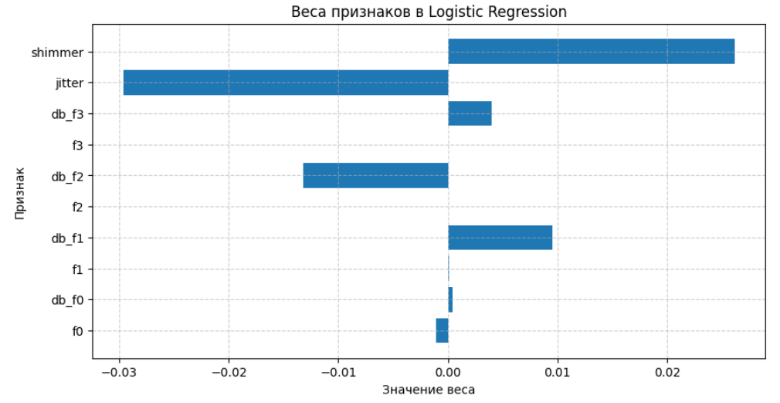
Рисунок 4 - Веса признаков в логистической регрессии
9. Заключение
Исследование подтвердило перспективность применения машинного обучения для выявления нарушений голоса. Методы линейной классификации показали высокую эффективность, а анализ важности параметров позволил выявить ключевые признаки для дальнейшего улучшения моделей. Дальнейшие исследования могут привести к созданию автоматизированных систем диагностики и мониторинга нарушений голоса, что улучшит качество реабилитации пациентов.