Method for enhancing the robustness of facial recognition systems using augmentation and generative models
Method for enhancing the robustness of facial recognition systems using augmentation and generative models
Abstract
This paper presents an enhanced user registration methodology for passwordless facial authentication systems. The proposed approach expands the training dataset using a combination of geometric data augmentation and neural network–generated semantic alterations, such as the addition of facial hair or eyewear. These augmentations significantly improve the system’s robustness to variations in user appearance and environmental conditions. The implemented solution adopts a client-server architecture, utilizing a ResNet-based convolutional neural network for feature extraction and PostgreSQL for secure embedding storage. Experimental validation on a public benchmark dataset confirms notable improvements in verification accuracy and resilience to appearance changes when compared to a non-augmented baseline system.
1. Introduction
Facial biometric authentication systems have seen widespread adoption as a cornerstone of modern passwordless security architectures
. Their appeal lies in the convenience and non-intrusiveness of using innate physiological features to verify identity . Despite this promise, existing systems face considerable limitations in terms of robustness to variations in user appearance and environmental conditions . Subtle factors such as lighting inconsistencies, changes in facial hair, or even slight head tilts can critically degrade recognition accuracy, resulting in false rejections and poor user experience .This work addresses the fragility of facial recognition models through a comprehensive enhancement of the registration pipeline. Specifically, the authors propose a novel augmentation-based framework that leverages both geometric and semantic transformations to artificially expand the variability of user facial data during enrollment
. Furthermore, the incorporation of generative neural networks enables the synthesis of realistic facial variations — such as the presence of sunglasses or facial hair — substantially improving the system’s ability to generalize across a broad spectrum of visual scenarios .The resulting system architecture integrates these augmentative techniques with a deep convolutional neural network for feature extraction
, supported by a scalable backend for secure storage and comparison of facial embeddings . Empirical evaluations, conducted on a well-established facial recognition benchmark , validate the efficacy of the proposed approach. Compared to baseline systems without augmentation, the enhanced model exhibits marked improvements in verification accuracy and resilience to appearance-altering factors, without compromising system integrity . These contributions demonstrate a significant advancement in the design of more adaptable and user-tolerant biometric authentication solutions.2. Research methods and principles
Passwordless authentication systems based on facial biometrics are now widely adopted. However, these systems are highly sensitive to the quality of the input data. Variations in ambient lighting, camera angle, or natural changes in a user's appearance — such as facial shape alterations due to weight gain or the growth of facial hair — may cause the system to erroneously deny access. Such failures negatively affect the overall user experience.
In general terms, this issue can be mitigated by applying proper preprocessing to the initial facial images that users provide during registration.
The standard user registration pipeline in such a biometric system typically involves five main stages:
1. Biometric Data Collection. At this stage, the client-side application — either a browser or a mobile device—captures multiple photographs of the user's face from different angles. These images are then securely transmitted to the server via an encrypted communication protocol such as HTTPS.
2. Preprocessing. Once received by the server, the images undergo several preprocessing steps: Alignment of facial features; Noise reduction; Adjustment of brightness and contrast; General image quality enhancement; Resizing to a standardized resolution.
These steps are crucial to ensure high-quality feature extraction in subsequent phases.
3. Feature Extraction. Key facial features are extracted from the preprocessed images, including but not limited to: Shape and size of the forehead; Chin length; Mouth height and width; Nose width; Interocular distance.
4. Face Embedding Generation. A pretrained neural network processes the extracted features to generate a unique feature vector—known as a facial embedding — that compactly represents the user's face. This embedding serves as the foundation for future access decisions.
5. Data Storage. Upon successful embedding generation, the vector is linked to the user’s unique identifier and stored in a database. The user is then considered registered within the system. Further actions depend on the specifics of the target information-analytical system.
The user authentication process mirrors the registration pipeline, comprising: biometric data collection, preprocessing, feature extraction, embedding generation, and database search.
1. Biometric Data Collection. Similar to the registration phase, the system captures several facial images using the user's camera. However, in this phase, users are not required to alter their head position. The images are securely transmitted to the server using HTTPS or a similar secure protocol.
2. Preprocessing. The captured images are processed using the same preprocessing steps as during registration.
3. Feature Extraction. Facial features are extracted identically to the process described in the registration stage.
4. Face Embedding Generation. Embeddings are generated from the extracted features using the same methodology as in the registration process.
5. Database Search. The embedding of the input image is compared against the embeddings stored in the database. This comparison is modeled as a distance computation between vectors in a high-dimensional space. In this work, cosine distance is used to evaluate similarity between the incoming embedding and stored embeddings.
Access is granted if the computed distance falls below a predetermined threshold θ, indicating a sufficiently close match. In such a case, the input image is considered successfully verified and is associated with the user identified by the matched embedding.
The proposed solution is based on the principle of data augmentation — a widely used technique for increasing dataset size when the original data volume is insufficient. The core idea is to generate multiple slightly modified versions of each input element, thereby enlarging the dataset.
Data augmentation can be applied to a variety of data types, including text, time series, and images. It is extensively utilized in neural network training to improve generalization performance, increase dataset diversity, and reduce overfitting.
Depending on the data type, different augmentation techniques can be employed. For image datasets, common transformations include:
- rotation (typically within ±15 degrees);
- scaling;
- horizontal flipping;
- contrast adjustment;
- blur addition (to simulate a smudged lens);
- noise injection (to mimic poor lighting or low-quality camera artifacts).
Each of these transformed images is used during the registration phase to generate additional embeddings for the same user. This significantly increases the variety of facial representations available for that user, improving recognition accuracy during future authentication attempts.
While this augmentation process greatly enhances recognition accuracy, it does not fully address the issue of natural changes in appearance.
To mitigate the impact of significant natural changes in facial appearance, generative neural networks can be introduced as an additional augmentation layer.
Using generative models, the system can simulate realistic modifications to a face, such as the addition of a beard, sunglasses, or makeup. These synthetic alterations provide further variations that the recognition system can learn to generalize from.
By incorporating such generated images into the registration dataset, the number of embeddings per user increases, resulting in improved robustness of the recognition model.
However, it is essential to ensure that the generated variations do not deviate excessively from the original facial features. Overly distorted images may harm recognition accuracy rather than enhance it. Thus, careful control over the extent of modification is necessary to maintain a balance between diversity and fidelity to the original appearance.
3. Main results
Based on the proposed solution, an access control system was developed following a standard three-tier architecture consisting of a client, a server, and a database management system. PostgreSQL was chosen for storing user embeddings.
The application is structured around two primary operational stages: user registration and user authentication.
During registration, the system receives a batch of user facial images with a resolution of 300x300 pixels along with a unique user identifier (UUID), all transmitted over a secure HTTPS connection. Each image undergoes a series of preprocessing steps aimed at improving image quality. These steps include alignment, noise reduction, brightness and contrast adjustment, and normalization of size and resolution. The goal of preprocessing is to ensure that subsequent stages operate on consistent and high-quality input data.
Following preprocessing, the system performs image augmentation to artificially increase the dataset. This involves generating modified versions of the original images by applying transformations such as rotation, flipping, and scaling. These augmented versions enrich the pool of facial representations and help enhance the model’s robustness.
In addition to geometric transformations, the system also applies semantic augmentations that simulate changes in appearance. These modifications, generated using neural networks, include the addition of facial hair, the application of digital makeup, and the overlay of sunglasses. The resulting set of images forms an extensive augmented dataset that reflects a wide range of possible variations in a user's facial appearance.
Once the augmented image set is finalized, embeddings are generated for each image by extracting the key facial features. These embeddings are then averaged to produce a single composite embedding vector that represents the user’s face in a stable and generalized form. The averaged embedding is subsequently linked to the user’s UUID and stored in the PostgreSQL database, thereby completing the registration process.
User authentication follows a similar logic to registration but operates on a single image instead of a batch. The client sends a 300x300 pixel facial image to the server over a secure HTTPS connection. The server then processes the image to extract key facial features and generates an embedding vector. This embedding is compared with the embeddings stored in the database to identify a match. If the similarity score exceeds a predefined threshold, the authentication is considered successful; otherwise, access is denied.
To convert facial images into embedding vectors, the system employs a deep convolutional neural network. The implementation uses the face_recognition library, which is based on the ResNet architecture. This architecture applies a sequence of convolutional layers that use learnable filters to extract spatial features from the input image. The result of each convolution is passed through a non-linear activation function, specifically ReLU, which introduces non-linearity into the model and enables it to learn complex patterns.
Pooling layers are applied between convolutions to reduce the spatial dimensions of feature maps while preserving the most informative features. In this implementation, max pooling is used, which selects the maximum value within a sliding window, thereby maintaining the most dominant features.
A key component of ResNet is the use of residual connections, which facilitate the training of deep networks by adding the output of a previous layer to the output of a subsequent layer. These skip connections help preserve the flow of gradients during backpropagation, allowing the network to learn more effectively without degradation.
After several convolutional and pooling layers, the resulting feature maps are passed to fully connected layers that perform the final transformation. The output of the final fully connected layer is a fixed-length vector, typically 128 dimensions, which serves as the face embedding. This vector compactly represents the essential characteristics of a face and is used for comparison against existing embeddings in the database.
The application exposes two core API endpoints that handle user registration and authentication. The /add_user endpoint is responsible for registering a new user in the system. Upon receiving a request, it expects a batch of facial images along with the user’s unique identifier. The system first validates the input data to ensure completeness and verifies that the identifier is a valid UUID. The submitted images are then loaded and converted into NumPy arrays, after which they undergo preprocessing, including quality enhancement and normalization.
Following this, the system performs data augmentation on each image, generating additional variations using geometric and semantic transformations. These transformations may include changes in orientation, scale, and mirroring, as well as simulated appearance modifications such as the addition of facial hair or makeup. For every augmented image, a facial embedding is computed. All resulting embeddings are then averaged into a single representative vector, which is associated with the user’s identifier and stored in the PostgreSQL database. The endpoint returns a structured JSON response indicating the success or failure of the operation.
The /verify_user endpoint handles user authentication. It accepts a single facial image, which is loaded, preprocessed, and converted into a NumPy array. An embedding vector is generated from the facial features of the image and compared against the embeddings stored in the database. The system uses the face_distance metric to quantify similarity between faces. If a stored embedding is found within the specified distance threshold—indicating a sufficiently high similarity—the system returns a success response along with the corresponding user identifier. If no match is found, the system responds with an error message indicating that the authentication has failed.
To evaluate the effectiveness of the developed method, a comparative analysis was conducted between two models: one employing image augmentation and the other operating without it. The publicly available Labeled Faces in the Wild dataset was used for testing, as it is a widely accepted benchmark for assessing facial recognition systems.
For both systems, a training set consisting of 100 unique individuals was created, with five images allocated to each person. The test set included two randomly selected images for each of the 100 registered individuals, along with two images for each of 100 unregistered individuals. Each test image was then modified using three synthetic transformations: the addition of a beard, sunglasses, and digital makeup. As a result, each face in the test set was represented by four images — one original and three modified — yielding a total of 1,600 test samples, with 800 belonging to registered users and 800 to unregistered ones.
Before the test set was used, each image was validated to ensure that a face could be successfully detected using the face_recognition library. Any image in which a face could not be detected was replaced.
Each image in the test set was then used to initiate an authentication attempt. The system was required to determine whether the image belonged to one of the registered users.
To calculate the verification accuracy, the system had to determine whether a test image belonged to one of the registered identities. The result of this decision was represented as a binary variable, where a value of one indicated successful verification and zero indicated failure. Overall verification accuracy was computed as the proportion of correctly verified instances over the total number of test samples.
To assess robustness against appearance changes, the system was evaluated under the assumption that it should reliably recognize a user’s face despite visual alterations. For each individual in the dataset, one randomly selected appearance modification was applied. The outcome was again represented as a binary variable indicating whether the modified image was successfully verified. The final robustness score was calculated as the ratio of successful verifications to the total number of modified samples.
The false acceptance rate was determined by presenting the system with images of individuals who were not present in the registration database. The system was expected either to correctly reject the input or, if a match was found, to return the identity of the corresponding registered user. A false acceptance was recorded when the system incorrectly identified an unregistered individual as someone in the database. The false acceptance rate was calculated by dividing the number of incorrect identifications by the sum of correctly rejected and incorrectly accepted samples.
The results of testing both systems are summarized in the table below. The system utilizing data augmentation achieved a verification accuracy of 92.5%, while the system without augmentation reached 88.2%. In terms of robustness to appearance changes, the augmented system showed a performance of 78.1% compared to 65.4% for the baseline. The user registration time, however, was significantly longer for the augmented system — 16.3 seconds on average versus 0.7 seconds without augmentation. The false acceptance rate was slightly higher for the augmented model at 3.1%, compared to 1.8% in the non-augmented version.
4. Discussion
The system incorporating data augmentation demonstrated superior verification accuracy and significantly improved robustness to changes in facial appearance. Although the difference in the false acceptance rate between the two systems was only 2%, this is not sufficient to be considered a critical disadvantage. However, the average registration time for a new user reached 16.3 seconds, which is notably long from a user experience perspective — especially if the system requires the user to wait for a server response. In practical scenarios, such as when registration occurs through an invitation link or a one-time password, there is no need to delay system access until the registration process completes. In such cases, it is reasonable to grant immediate access, as the user has already been verified through other means. Furthermore, in situations where a registration request is reviewed manually by a system administrator, the increased processing time becomes irrelevant. The results could be shown as a graph, see fig. 1.
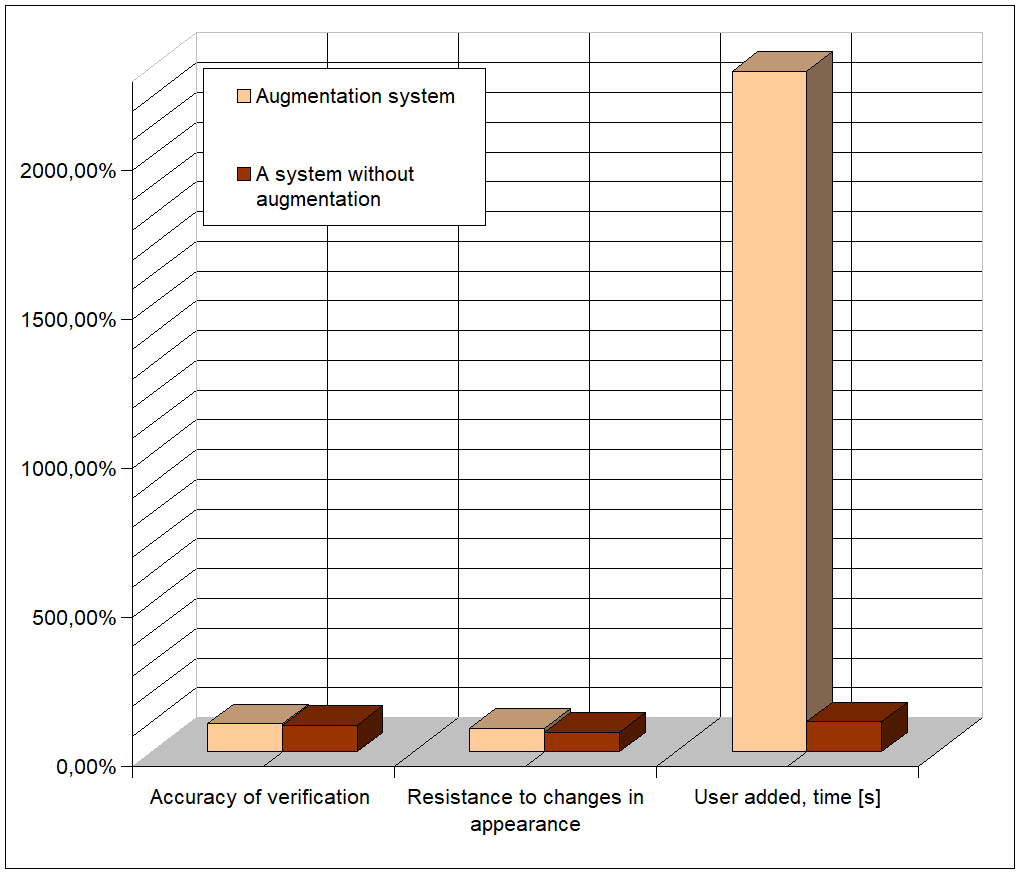
Figure 1 - Accuracy Comparison of Facial Recognition Systems Under Different Conditions
The trade-off between accuracy and registration latency revealed in this study highlights a fundamental design consideration for biometric systems: optimization for context. While augmentation-based approaches excel in scenarios where latency can be decoupled from user interaction (e.g., asynchronous verification), their adoption in real-time applications demands further innovation. Future work could explore:
1. Edge Computing Solutions — Offloading augmentation tasks to edge devices to reduce server-dependent delays.
2. Progressive Enrollment — Allowing users to complete registration incrementally while using the system, mitigating perceived latency.
3. Adaptive Augmentation — Dynamically adjusting the complexity of augmentation based on network conditions or user priority.
Moreover, the synthetic variations introduced during augmentation (e.g., sunglasses, facial hair) could be refined using domain adaptation techniques to better align with real-world edge cases. Finally, longitudinal studies assessing user tolerance for registration delays across different demographics would help tailor these systems to specific use cases, from enterprise security to consumer applications.
5. Conclusion
This study focused on the development and evaluation of a passwordless authentication method based on facial biometrics for use in information and analytical systems. The research included an analysis of existing approaches to facial recognition, highlighting their strengths and limitations — most notably, their sensitivity to changes in user appearance and lighting conditions. To overcome these limitations, a new method was proposed and tested, involving data augmentation through generative models as part of the training process for the facial recognition system.
The comparative evaluation of two models — one using augmentation and the other without — demonstrated that image augmentation, including geometric transformations and simulated artifacts such as facial hair, glasses, and makeup, significantly improves both verification accuracy and robustness to appearance changes. Specifically, the verification accuracy increased from 88.2% to 92.5%, and robustness to appearance variations improved from 65.4% to 78.1%. These results confirm the hypothesis that augmentation enables the model to better generalize across varying conditions, such as lighting and facial angle, while also handling intentional changes in appearance more effectively.
Despite its advantages in recognition accuracy and robustness, the augmented model exhibited a higher false acceptance rate (3.1% compared to 1.8%) and a substantially longer user registration time (16.3 seconds versus 0.7 seconds). These drawbacks require further investigation and optimization.
The increased registration time is primarily attributed to the need for numerous image transformations, which in turn demand significant computational resources. However, as shown, this delay is not a critical factor in scenarios such as invitation-based or administrator-approved registration workflows.