Methods for automatic data backup in scalable distributed storage
Methods for automatic data backup in scalable distributed storage
Abstract
The article examines modern methods of automatic data backup in scalable distributed storages, including cloud and hybrid environments. Key technologies for improving fault tolerance and efficiency are analyzed: Distributed Hash Table (DHT) for optimal data placement, parallel erasure coding for reducing storage costs, and adaptive algorithms for dynamically adjusting backup parameters. Special attention is paid to the use of machine learning models for predictive analysis and automatic recovery from failures. The goal of the work is to present a comprehensive approach to creating autonomous, self-optimizing backup systems that meet modern requirements for data availability and integrity.
It is proposed to use parallel coding with distributed redundancy algorithms in order to reduce the amount of space occupied, as well as increase the fault tolerance of the system itself. To automatically determine the optimal size of data blocks, the article suggests using adaptive algorithms that would take into account the current network capabilities, as well as the level of delays, which would minimize the costs associated with the redundancy process.
Algorithms for asynchronous monitoring of the state of data blocks and fault trigger mechanisms that allow automatic recovery of blocks are described.
Scientific articles were used as sources when writing the work, as well as information that is publicly available on the Internet. The data described in the article will be of interest to employees working in the IT field, as well as to the management of these companies.
1. Введение
В современную цифровую эпоху информационные системы сталкиваются с беспрецедентным ростом объемов данных. По прогнозам IDC, к 2025 году глобальный объем данных достигнет 175 зеттабайт , что делает традиционные, централизованные методы резервного копирования неэффективными и экономически нецелесообразными. Актуальность данного исследования усиливается двумя ключевыми факторами. Во-первых, экономические риски: согласно отчету IBM, средняя стоимость утечки данных в 2024 году превысила 4,9 миллиона долларов , что подчеркивает критическую важность надежных механизмов восстановления. Во-вторых, регуляторные требования: нормативные акты, такие как GDPR в Европе, устанавливают строгие правила по обеспечению целостности и доступности данных, превращая автоматизацию резервирования из технической задачи в обязательный элемент комплаенса.
Традиционные способы резервного копирования не способны эффективно справляться с объемами данных, из-за чего создается угроза утраты необходимой информации.
Автоматизация процессов резервирования данных в распределённых хранилищах позволяет решить многие проблемы. Внедрение технологий, таких как например: хеш-таблицы, параллельное кодирование стирания, адаптивная настройка параметров блоков, позволяют повысить отказоустойчивость системы, сократить задержки, а также оптимизировать использование ресурсов. В свою очередь, алгоритмы прогнозирования сбоев, восстановления данных позволяют создавать новые автономные, самооптимизирующихся системы.
Необходимость повышения надежности, доступности данных, сокращения расходов на управление распределёнными базами данных делает актуальным развитие методов автоматического резервирования. Эти подходы обеспечивают защиту данных от потерь, их быстрое восстановление, одновременно снижая затраты на обслуживание системы, что помогает организациям своевременно реагировать на изменяющиеся требования, тем самым поддерживая необходимые параметры безопасности и производительности.
В рамках исследования внимание уделяется методам, применимым как к публичным облачным хранилищам (например, Amazon S3, Google Cloud Storage), так и к гибридным системам, сочетающим локальную инфраструктуру с облачными сервисами.
Цель работы заключается в проведении анализа существующих методов, разработки новых подходов к автоматическому резервированию данных.
Научная новизна исследования заключается не в рассмотрении существующих технологий, используемых в процессе резервирования данных в масштабируемых распределенных хранилищах, по отдельности, а в предложенном комплексном подходе к их интеграции. В отличие от работ, анализирующих эти методы изолированно, данная статья предлагает концептуальную модель их синергетического взаимодействия для создания единой, самооптимизирующейся системы. Авторский вклад состоит в формулировании принципов интеграции этих методов для достижения динамического баланса между отказоустойчивостью, эффективностью хранения и скоростью восстановления данных, что является ключевой нерешенной задачей в данной области.
2. Обзор литературы
Для анализа методов автоматического резервирования данных в распределённых хранилищах использовались различные подходы, такие как: аналитический, сравнительный, моделирующий. Первый метод направлен на изучение существующих технологий резервного копирования, их особенностей, а также выявлении роли в распределённых вычислительных системах. Сравнительный подход позволил выявить преимущества, недостатки решений, которыми обладают: хеш-таблицы, параллельное кодирование стираний, адаптированные алгоритмы, основываясь на их производительности. Моделирующий метод применялся для прогнозирования сбоев с использованием машинного обучения. Симбиоз этих подходов позволил широко рассмотреть проблему, оценить разнообразие существующих решений.
В сфере резервного копирования, восстановления данных представлены концепции, направленные на повышение надёжности, производительности, эффективности в разных эксплуатационных условиях. Одним из таких решений является метод, предложенный авторами J. Duan, B. Yang в статье , ориентированный на резервирование неструктурированных данных. Для оптимизации работы, балансировки нагрузки между серверами было предложено использовать распределенную систему, что позволило повысить эффективность обработки массивов информации.
A. Alquraan и др. в статье описали систему Slogger, предназначенную для восстановления данных в распределённых хранилищах с минимальными потерями. Асинхронная репликация, использование технологии водяных знаков позволили достичь потерь данных всего до 14,2 миллисекунд, что минимизировало время простоя при необходимости восстановления.
Q. Wang в работе предложил метод резервного копирования, использующий алгоритм сжатия DELTA. Данный подход позволяет сжать данные, что ускоряет процесс восстановления данных, включая случаи внешних воздействий, таких как атаки.
J. Mao и др. в статье предложили метод резервирования для мультидоменных SDN-сетей, включающий репликацию контроллеров. Создание резервных копий управляющих элементов в разных доменах, по их мнению, способствует снижению рисков сбоев, тем самым обеспечивая работоспособность сети.
J.J. Kim в статье предложил метод резервного копирования, основанный на кодировании стираний, предназначенный для эксаскейл-хранилищ. Такой подход позволил улучшить эффективность использования пространства, ускоряет процесс восстановления данных в распределённых системах.
D. Alimjon анализирует основные подходы к репликации в распределённых системах и подчёркивает, что традиционные схемы «ведущий–ведомый» уступают по эффективности в сценариях с высокой частотой отказов узлов и нестабильными сетевыми соединениями . Автор предлагает комбинировать модели с использованием кворм-факторов (quorum-based replication) и векторных часов для упрощённого разрешения конфликтов при записи и для достижения баланса между скоростью отклика и строгой согласованностью транзакций.
Wu J. и др. фокусируются на архитектуре «доступного, удобного, масштабируемого и устойчивого» (AUSS) сервиса для обработки и хранения научных «больших данных» . Авторы описывают многослойную микро-сервисную структуру, где модули управления метаданными, инкрементальной агрегации и распределённого индексирования развёрнуты в контейнерах с автоматическим масштабированием. Для обеспечения консистентности данных предлагается гибридный подход: в оперативной памяти — быстрое, но «слабосогласованное» кэширование, а в долговременном хранилище — согласованные транзакционные журналы. Такой подход позволяет минимизировать задержки при выборках и одновременно сохранять точность данных при длительном анализе.
Tsipi L. и др. предлагают модель "Digital Repository as a Service" (D-RaaS), в которой фокус смещён на создание слоя абстракции для хранения как структурированных, так и неструктурированных данных .
Практическую основу составляют следующие работы: в источнике , сведения которого размещены на сайте www.enterprisestorageforum.com рассматривается опыт компаний, внедривших автоматическое резервирование данных в распределённых хранилищах. Источник размещенный на сайте www.momentslog.com позволил рассмотреть преимущества, а также недостатки таких систем.
В работе К.А. Харитонова и М.В. Ступиной предлагается новый алгоритмический подход к инкрементальному резервному копированию с учётом особенностей облачной архитектуры. Авторы формулируют задачу минимизации избыточности хранимых данных и пропускной способности сети, предлагая гибридную стратегию, сочетающую дифференциальные и блочные инкременты.
Д.И. Екубджонов и Р.Ф. Гибадуллин фокусируются на оценке производительности технологий объектно-реляционного отображения (ORM) при взаимодействии с Microsoft SQL Server, что имеет прямое отношение к системам резервного копирования данных, использующим ORM-слой для инвентаризации и управления метаданными бэкапа . В своей работе авторы проводят сравнительный эксперимент с распространёнными фреймворками ORM и родными средствами ADO.NET, демонстрируя, что использование ORM может приводить к значительному росту временных затрат на операции выборки и записи метаданных по сравнению с «сырыми» SQL-запросами. При этом отмечается, что грамотная конфигурация кэша ORM и применение батчевой вставки позволяют сократить задержки почти до уровня чистого ADO.NET, однако полный паритет производительности достигается лишь при сложной дополнительной оптимизации, что ограничивает применимость ORM-решений в высоконагруженных гибридных хранилищах.
Общая тенденция к увеличению ёмкости систем хранения данных отмечена в работе , где показано, что к 2025 года объём глобальных данных превысит 175 зеттабайт, при этом частота отказов дисковых накопителей останется на стабильно высоком, но всё ещё высоком уровне. Источник использовался для демонстрации стоимости утечки данных.
Методология исследования основана на аналитическом и сравнительном подходах. Анализ опирается исключительно на вторичные данные: научные статьи из рецензируемых журналов (IEEE, ACM), материалы конференций (VLDB, Big Data) и техническую документацию ведущих поставщиков облачных услуг (Acronis, Oracle, HPE). Сравнение технологий (DHT, кодирование стирания, адаптивные алгоритмы) проводилось по следующим ключевым критериям:
– Отказоустойчивость: способность системы выдерживать отказы узлов без потери данных.
– Эффективность хранения: избыточность данных, или отношение общего объема хранимых данных к исходному.
– Скорость восстановления (RTO): время, необходимое для восстановления данных после сбоя.
– Производительность: влияние процесса резервирования на задержки при чтении/записи.
Моделирующий метод упоминается в контексте анализа работ, посвященных применению машинного обучения для прогнозирования сбоев. Собственные экспериментальные исследования в рамках данной работы не проводились.
3. Результаты и обсуждения
Системы хранения данных сталкиваются с задачей обеспечения отказоустойчивости на фоне роста объёмов информации. Принцип "Write Once, Read Many" (далее — WORM) предполагает сохранение данных в неизменном виде, что устраняет возможность их повреждения, тем самым повышая стабильность хранения.
Реализация этого подхода в распределённых системах требует учёта особенностей распределения информации, разработки механизмов для восстановления данных. Технология распределённых хеш-таблиц соответствует принципу однократной записи, минимизирует ошибки, ускоряет процесс доступа к данным. Использование Distributed Hash Table позволяет организовать распределение информации на основе идентификаторов . Ниже на рисунке 1 будут представлены задачи, которые решает данный метод.
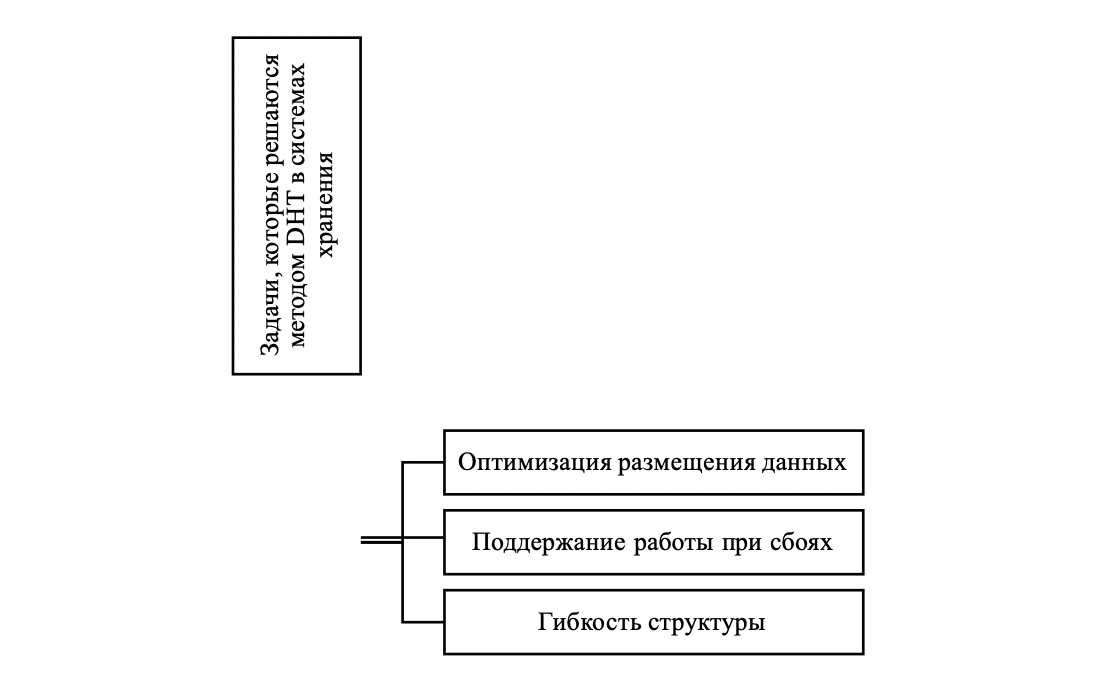
Рисунок 1 - Задачи, которые решаются методом DHT в системах хранения
Примечание: источник [3]
1. Восстановление данных без дублирования, позволяет снизить затраты, связанные с хранением информации.
2. Оптимизация процесса кодирования, организовано таким образом, что операции резервирования выполняются быстрее, уменьшая нагрузку на систему.
3. Надёжность хранения, гарантирует постоянную доступность информации.
Этот метод находит применение в структурах, где необходимо эффективно использовать ресурсы, алгоритмы адаптируются под изменяющиеся условия работы, что даёт возможность гибко настраивать параметры системы. Для наглядности на рисунке 2 будет описано на чем основывается подход адаптивного алгоритма.
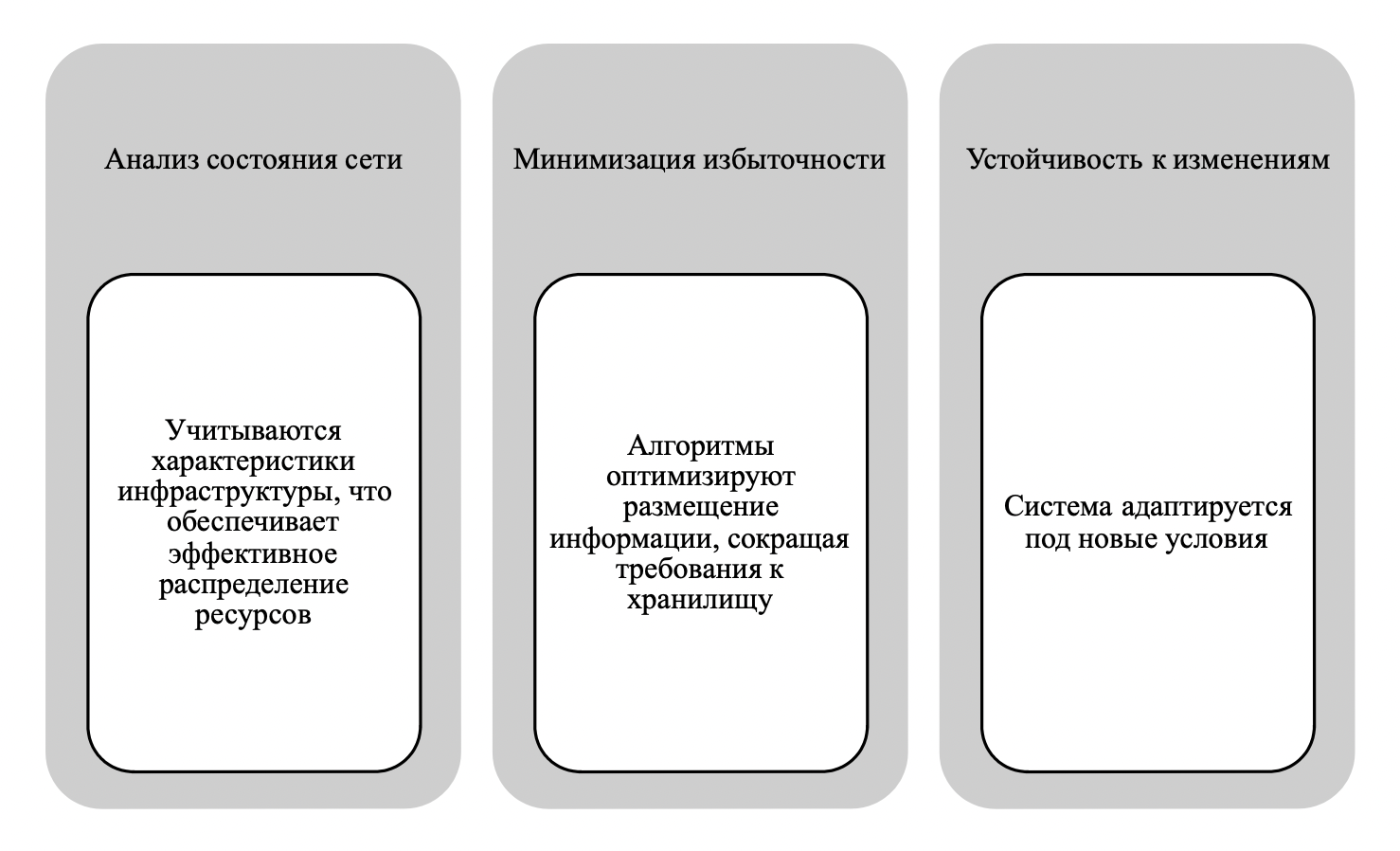
Рисунок 2 - Адаптивный алгоритм
Примечание: источники [6], [10]
Машинное обучение используется в системах резервирования для анализа предыдущих отказов, что способствует адаптации к изменениям в инфраструктуре. Алгоритмы выполняют следующие функции: обнаружение неисправностей; снижение числа ложных срабатываний из-за ошибок; обновление системы, за счет обучения, которое подстраивается под изменения в инфраструктуре .
Далее рассмотрим примеры использования самообучающихся моделей в различных организациях.
Так, компания Acronis предоставляет облачные платформы для резервного копирования, охватывающие более 500 000 предприятий по всему миру. Разработанная система автоматизирует процессы резервирования, акцентируя внимание на защите данных, ее особенностью является восстановление информации за 15 секунд, поддержка разных методов копирования: полное, инкрементное, дифференциальное.
CrashPlan ориентирован на малый бизнес, предлагая облачную защиту данных с возможностью восстановления после атак программ-вымогателей, а также настройку сохранения файлов. Сервис стал востребованным среди более 50 000 пользователей, что подтверждает его эффективность при обеспечении неограниченного хранилища без прерывания работы организаций.
Платформа Oracle Cloud предназначена для защиты данных в гибридных структурах. Она предоставляет инструменты для восстановления после сбоев, что позволяет работать с крупномасштабными базами данных и приложениями. Платформа ориентирована на производительность, масштабируемость, безопасность.
Решения Hewlett Packard Enterprise предназначены для гибридных облачных сред, обеспечивая автоматическую защиту виртуальных машин и других приложений. Система помогает формировать гибкие политики резервного копирования, аварийного восстановления, ускоряя время восстановления данных, масштабируемость решения позволяет своевременно реагировать на изменение объема данных.
Платформа Zoolz предлагает функции резервного копирования, адаптированные под нужды бизнеса. Она включает инструменты для управления файлами, их восстановления.
Практическая значимость этих методов особенно высока в отраслях с повышенными требованиями к сохранности и доступности данных. Так, к примеру, в финансовом секторе, где даже минутный простой может привести к миллионным убыткам, решения на базе Oracle Cloud с технологией Zero Data Loss Recovery Appliance используются для обеспечения непрерывности банковских операций и соответствия требованиям регуляторов (например, Basel III). В здравоохранении для хранения электронных медицинских карт (EHR) применяются гибридные облачные решения от HPE, которые гарантируют как быстрое восстановление данных в случае сбоя оборудования в клинике, так и долгосрочное архивирование в соответствии с законодательством (например, HIPAA в США). Автоматическое резервирование здесь критически важно для непрерывности ухода за пациентами .
В свою очередь для внедрения автоматического резервирования данных в распределённых хранилищах требуется учёт нескольких факторов. Во-первых, необходимо оценить объём информации, подлежащей защите, что позволяет выбрать подходящие методы копирования, во-вторых, следует выработать стратегии восстановления, ориентированные на особенности каждой организации.
Интеграция гибридных облачных решений позволяет подойти качественнее к процессу масштабирования инфраструктуры по мере увеличения объёмов данных, а также обеспечения непрерывного доступа к информации при возникновении проблем, влияющих на работоспособность серверных систем. Настройка систем на выполнение операций по заранее заданным политиками исключает зависимость от ручного вмешательства, непосредственным элементом автоматизации становится проверка целостности резервных копий, что снижает риск ошибок в процессе восстановления данных.
Использование распределённых хранилищ, находящихся в разных географических регионах, даёт гарантию сохранности информации при отказе оборудования в одном из узлов сети, что в свою очередь минимизирует вероятность потери данных.
Применение шифрования как для хранения данных, так и для их передачи защищает информацию от несанкционированного доступа. Механизмы аутентификации, интегрированные с такими технологиями, предоставляют несколько уровней защиты, что усиливает общий контроль за безопасностью. Программные решения от Acronis реализуют шифрование на всех этапах обработки данных .
Мониторинг состояния резервных копий требует создания системы, которая будет своевременно сообщать о сбоях в процессе их создания или сохранения. Такая настройка позволяет минимизировать риски, связанные с неполадками. Программы, например, CrashPlan, обеспечивают централизованное управление резервным копированием, упрощая контроль над процессом.
Для повышения эффективности защиты информации необходимо наличие разработанного плана восстановления данных, он должен содержать процедуры, направленные на быстрое восстановление в случае сбоев, атак программ-вымогателей или других катастрофических ситуаций. Решения от разработчиков, таких как например: Oracle, HPE, предлагают функции восстановления с минимальными задержками, что обеспечивает бесперебойную работу системы при непредвиденных обстоятельствах . Далее в таблице 1 будут представлены преимущества и недостатки автоматического резервирования данных в масштабируемых распределенных хранилищах.
Таблица 1 - Преимущества и недостатки, присущие автоматическому резервирования данных в масштабируемых распределенных хранилищах
Преимущества | Недостатки |
Масштабируемость — распределённые системы позволяют распределять или уменьшать объём хранилища, адаптируясь под рост данных. | Зависимость от сети — производительность и доступность данных способны гарантировать качество интернет-соединений. Возникающие проблемы с сетью приводят к задержке восстановления или доступа к данным. |
Избыточность данных — данные хранятся в нескольких точках, что повышает их доступность, а также защищенность. Так, к примеру, в случае сбоя на одном из серверов данные остаются доступными на других платформах. | Необходимость высоких затрат для работы распределенного местоположения. |
Быстрое восстановление данных. Позволяет сократить время простоя, тем самым ускорить процессы восстановления после сбоев. | Риски при возникающих сбоях, приводят к использованию позднего времени для восстановления данных, что затрудняет доступ к необходимой информации. |
Возможность интеграции с облачными решениями, что дает дополнительные преимущества в плане масштабируемости. | Проблемы с соблюдением нормативных требований. При использовании глобальных облачных хранилищ данные могут физически размещаться в разных юрисдикциях. Это создает сложности с соблюдением законов о суверенитете данных (например, требование хранить персональные данные граждан РФ на территории России согласно ФЗ-152) и трансграничной передаче данных (например, GDPR). |
Примечание: источники [9], [11]
Таким образом, современные технологии резервирования данных создают эффективные решения для хранения информации. Методы однократной записи блоков, DHT, стирающее кодирование, адаптивные алгоритмы, а также самообучающиеся модели обеспечивают стабильную работу систем, позволяют сократить лишние затраты.
4. Заключение
Проведённое исследование систематизирует подходы к автоматическому резервированию данных и на этой основе формулирует совокупность научных результатов, обеспечивающих целостное решение задачи построения отказоустойчивых и экономически эффективных хранилищ.
Предложена концептуальная модель интегрированной системы резервирования, в которой в единую архитектуру сведены три технологических уровня. Уровень размещения, реализуемый на базе распределённой хэш-таблицы (DHT), обеспечивает оптимальное географическое и логическое распределение блоков, снижая вероятность локальных отказов и повышая доступность. Уровень хранения опирается на параллельные схемы кодирования стирания, достигая требуемой избыточности при максимальной эффективности использования дискового пространства по сравнению с традиционной репликацией. Уровень адаптации, использующий адаптивные алгоритмы и методы машинного обучения, формирует контур обратной связи: параметры системы (размер блока, коэффициент избыточности и др.) динамически подстраиваются под текущую сетевую нагрузку и прогнозируемый профиль отказов узлов.
Оценка экономической и технической эффективности подтверждает преимущество комплексного подхода над изолированным применением отдельных методов. Так, замена тройной репликации кодированием стирания, согласно данным источника [7], позволяет сократить затраты на хранение. Дополнение системы адаптивными механизмами управления конфигурацией даёт дополнительное уменьшение сетевого трафика и операционных издержек относительно статических настроек. Интеграция указанных уровней в рамках единой модели обеспечивает аддитивный эффект и более благоприятный компромисс между стоимостью, производительностью и надёжностью.
Выявлен выраженный синергетический эффект от использования прогнозных моделей. Применение машинного обучения для предиктивного анализа состояния узлов переводит систему из реактивного в проактивный режим: помимо обработки факта отказа, инициируется упреждающее восстановление и перераспределение данных, что существенно повышает итоговую устойчивость и сокращает время деградации сервиса.
Научная новизна и оригинальность результатов заключаются в разработке целостной архитектурной концепции, противопоставляемой работам, фокусирующимся на отдельных компонентах — методах кодирования или репликации , Новизна состоит не в создании новых элементных технологий, а в их систематическом синтезе и формализации принципов взаимодействия, обеспечивающих интеллектуальную оркестровку уровней. В отличие от аналитических обзоров , , констатирующих частные проблемы производительности или описывающих отдельные алгоритмы, предложенная модель выступает теоретической основой проектирования распределённых хранилищ нового поколения с встроенными механизмами самоадаптации.
Тем самым работа вносит вклад в теорию распределённых систем, предлагая концептуально выверенное и практико-ориентированное решение одной из ключевых задач области — построения полностью автономных, экономически эффективных и отказоустойчивых систем резервирования и хранения данных.