DEVELOPMENT OF DECISION MAKING SUPPORT SYSTEM WHEN SELECTING FELINOLOGICAL EXHIBITION

Бидуля Ю.В.1, Семихин Д.В.2, Семихина И.Г.3
1Кандидат филологических наук, доцент, Тюменский государственный университет
2Доцент по кафедре информационных систем, кандидат физико-математических наук, доцент, Тюменский государственный университет
3Старший преподаватель, Тюменский государственный университет
РАЗРАБОТКА СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЯ ПРИ ВЫБОРЕ ФЕЛИНОЛОГИЧЕСКОЙ ВЫСТАВКИ
Аннотация
Описана задача экспертной оценки животных при проведении фелинологической выставки. Приведены существующие стандарты оценки качества животных, являющиеся основой для принятия решения экспертом. Разработана математическая модель экспертной оценки животного. Показаны функциональные возможности программного модуля, позволяющего на основе математической модели осуществлять выбор оптимальной системы судейства для домашнего животного по его описанию.
Ключевые слова: принятие решения, экспертная оценка, фелинологическая выставка.
Bidulya Yu.V.1, Semikhin D.V.2, Semikhina I.G.3
1PhD in Philology, Associate professor, Tyumen state University
2PhD in Physics and Mathematics, Associate professor, Tyumen state University
3Assistant professor, Tyumen state University
DEVELOPMENT OF DECISION MAKING SUPPORT SYSTEM WHEN SELECTING FELINOLOGICAL EXHIBITION
Abstract
The paper describes the task of an expert evaluation of the animals at feline exhibitions. It provides existing assessment standards to evaluate the quality of animals that become the basis of the experts' solutions. The mathematical model of expert assessment of an animal is developed. The paper shows the functionality of a program module, which allows to carry out the selection of an optimum judging system for a pet by its description on the basis of a mathematical model.
Keywords: decision making, expert assessment, feline exhibition.
Сколько существует человек, примерно столько же рядом с ним существовали и кошки. Люди постоянно вносили изменения во внешний вид этих животных, селекционируя их и выводя все новые и новые породы. Для того, чтобы иметь возможность сравнить одну кошку с другой, стали организовывать выставки животных. Со временем на выставках появились новые действующие лица – эксперты, оценивающее параметры животного на выставке. Эксперт описывает животное основываясь на общепринятый стандарт той или иной породы.
Стандарт – это формализованное и структурированное описание того, как должна выглядеть идеальная кошка определенной породы.
В настоящее время существует большое количество фелинологических систем племенного разведения кошек. Одним из отличий таких систем друг от друга является свое видение того, как должна выглядеть та или иная порода. Соответственно стандарт одной и той же породы в разных системах разнится в описании.
Можно предположить, что в таком случае при описании одной и той же породы в стандартах различных систем будет использоваться свой набор слов.
Человек, знающий стандарты, прочитав описание животного, может сказать какой системе племенного разведения это животное больше соответствует. Владелец кошки не обязан знать наизусть стандарты всех систем. При этом участвовать в выставках хотелось бы максимально эффективно. В связи с чем появилась идея разработки web-сервиса, функцией которого было выдавать рекомендации владельцу животного в какой системе его лучше выставлять.
Интерфейс web-сервиса предусматривает две экранные формы: «Режим обучения» и «Режим эксперта». В первую можно вносить эталонные экспертные описания для тренировочной выборки, привязав их к системе судейства (WCF, FIFe) и указав оценку (рис. 1). Во второй накопленные данные можно использовать для анализа описания животного, полученного от эксперта на одной из выставок и получения вероятностной оценки – в какой фелинологической системе данное животное будет более высоко оценено.
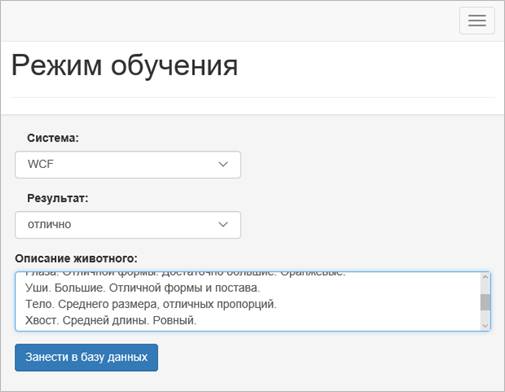
Рис. 1 - Ввод данных для тренировочной выборки
Оценка эксперта представляет текст, имеющий регламентированную структуру. Описание должно в обязательном порядке содержать оценку по каждому признаку породы (аспекту): (голова, глаза, уши, тело, хвост и т. д.). Оценки, как правило, качественные, а не количественные. Приведем пример описания животного по стандарту FIFe:
Голова. Крупная, угловатых линий. Подбородок широкий с переходом. Нос прижат.
Глаза. Средней величины, зеленые, правильного постава.
Уши. Крупные, высокого постава. Чуть разведены.
Тело. Крупное, массивное, растянутое.
Хвост. Прямой, в пропорции к телу.
Шерсть. Отличной текстуры и длины. Отличный воротник. Мрамор четко выражен.
Кондиция. Выставочная.
Анализ экспертных заключений показал, что лексика описания не ограничивается стандартом, эксперт волен выражать свое мнение так, как ему удобно. Стандарт указывает лишь на приоритеты оценок, которые выражаются неявно, в описательной форме.
Цель исследования. Предположим, что для конкретного животного существует некоторая зависимость между значениями признаков и описанием стандарта породы, которая выражается в том, какими оценочными словами или терминами эксперт описывал животное на выставке. Тогда, имея в качестве входных данных набор оценок экспертов для одного и того же животного, можно с некоторой вероятностью прогнозировать, по какому стандарту породы выставочные результаты окажутся наиболее успешными.
Такого рода зависимости выявляются методами математической лингвистики путем кластеризации или классификации текстов.
Методика эксперимента. Для реализации данного приложения применялся наивный байесовский классификатор, обученный на униграммах и биграммах. Суть метода состоит в следующем.
- Формируется тренировочная выборка из текстов оценок в уже известных стандартах и известным результатом оценки: «отлично», «хорошо» или «удовлетворительно». Были сформированы следующие класссы:
WCF-excellent, WCF-good, WCF-fair, FIFe-excellent, FIFe-good, FIFe-fair.
- Каждый текст подвергается предварительной обработке, включающей следующие преобразования:
- Замена множественных пробелов на одинарный;
- Удаление знаков препинания и специальных символов;
- Перевод всех символов в нижний регистр;
- Разбиение на отдельные слова;
- Выделение основы каждого слова (стемминг) с применением алгоритма Портера [1] для русского языка.
- Для каждого класса оценки в определенном стандарте вычисляются частоты вхождения слова (вернее, его основы).
- Для каждого слова вычисляется вероятность принадлежности классу по формуле [2]:
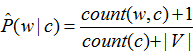 (1)
(1)
где P(w|c) - вероятность обнаружения слова w в документе класса c, предположительно независимая от длины документа и вычисляемая с применением аддитивного сглаживания Лапласа;
count (w,c) – число раз, когда слово w встречается во всех документах класса с;
count (c) – число слов во всех документах класса с;
V – объем словаря всех документов (число уникальных слов).
Вычисленные вероятности являются результатом обучения классификатора и далее применяются для классификации пользовательских текстов оценок, введенных в систему.
- Пользовательский текст, введенный в окно программы, подвергается обработке, согласно пунктам 2 и 3.
- Для пользовательского текста вычисляются вероятности принадлежности одному из классов, определенных в пункте 1 по формуле:
P(c|d)=P(c) P(w1|c) P(w2|c) … P(wn|c) (2)
где P(c|d) – вероятность принадлежности текста d классу с;
P(c)=Nс/N – вероятность класса с, Nc – количество текстов для каждого класса, N – общее количество текстов;
n – количество уникальных слов в тексте d.
Далее полученные классы ранжируются по величине вероятности P(c|d). В зависимости от места в рейтинге той или иной оценки можно предположить о наиболее подходящем стандарте для оценки животного, описание которого было введено пользователем. К примеру, результат ранжирования может выглядеть так:
- WCF-excellent,
- FIFE-fair,
- WCF-good,
- WCF-fair,
- FIFE-excellent,
- FIFE-good.
Для окончательного заключения была разработана система правил для каждого типа ранжирования.
Результаты. Тренировочная выборка была составлена из 48 текстов оценок животных одной породы, из них 30 текстов — оценки в стандарте WCF, и 18 текстов — в стандарте FIFE.
Результат работы классификатора оценивался при помощи следующего показателя: фактическое количество призовых мест на выставках для данного животного, полученное путем опроса пользователей системы – владельцев животных. Эти данные вводятся при регистрации на сайте. В качестве критерия использовался показатель точности: отношение числа совпадений оценки в стандарте, выданной системой, и фактических результатов выставок, к общему числу текстов, отнесенных системой к данной оценке.
Результаты эксперимента приведены в таблице 1.
Таблица 1 – Результат оценки работы классификатора
| Стандарт | Оценка | Число правильных оценок системы | Число ошибочных оценок | Точность |
| WCF | excellent | 20 | 4 | 0,83 |
| WCF | good | 8 | 3 | 0,73 |
| WCF | fair | 2 | 1 | 0,67 |
| FIFE | excellent | 12 | 1 | 0,92 |
| FIFE | good | 5 | 2 | 0,71 |
| FIFE | fair | 1 | 0 | 1,00 |
В дальнейшем планируется расширить классификацию на другие стандарты породы, а также изучить влияние признаков породы на оценку экспертов в каждом стандарте. Разработанная система будет использоваться для сбора экспериментальных данных.
Список литературы / References
- Willett P. The Porter stemming algorithm: then and now// Program: Electronic Library and Information Systems. – 2006. – Vol. 40, fasc. 3. – P. 219–223.
- JurafskyD., Martin J. H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech RecognitionPearson. – Prentice Hall, 2009. – 988 p.