CONVOLUTIONAL K-MEANS CLUSTERING

СВЕРТОЧНАЯ КЛАСТЕРИЗАЦИЯ МЕТОДОМ K-СРЕДНИХ
Научная статья
Воробжанский Н.Н.*
Воронежский государственный университет, Воронеж, Россия
* Корреспондирующий автор (vorobzh[at]gmail.com)
АннотацияЗадача маркировки данных для обучения глубоких нейронных сетей представляет собой сложный и утомительный процесс, требующий получения миллионов пометок для достижения необходимых результатов. Такая зависимость от большого объема размеченных данных может быть снижена за счет использования иерархических признаков, полученных посредством методик обучения без учителя. В этой работе предлагается обучить глубокую сверточную нейронную сеть, построенную на улучшенной версии метода кластеризации k-средних, который сокращает число коррелируемых параметров в виде похожих фильтров, и таким образом увеличивает точность категоризации на тестовой выборке. Подобный метод можно назвать кластеризацией сверточных k-средних. В дальнейшем будет показано, что обучение соединениям между слоями глубокой сверточной нейронной сети улучшает ее способности обучаться на меньшем числе размеченных данных. Эксперименты показывают, что предложенный алгоритм существенно превосходит другие методики, которые обучаются фильтрам без учителя. Так, на STL-10 была получена точность на тестовой выборке в 70.5%.
Ключевые слова: алгоритм кластеризации k-средних, сверточная нейронная сеть (CNN), обучение без учителя.
CONVOLUTIONAL K-MEANS CLUSTERING
Research article
Vorobzhansky N.N.*
Voronezh State University, Voronezh, Russia
* Corresponding author (vorobzh[at]gmail.com)
AbstractThe task of marking data for deep neural network training is a complex and tedious process that requires millions of marks to achieve the necessary results. This dependence on a large amount of labeled data can be reduced by using hierarchical features obtained through unsupervised learning techniques. In this study, the authors propose a deep convolutional neural network training based on an improved version of the k-means clustering method, which reduces the number of correlated parameters in the form of similar filters, and thus increases the accuracy of categorization on test samples. Such a method can be called convolutional k-means clustering. Further into the article, the study demonstrates that learning connections between layers of a deep convolutional neural network improves its ability to learn on a smaller number of labeled data. Experiments show that the proposed algorithm is significantly superior to other methods that learn filters without supervision. Therefore, on the STL-10, the test sample demonstrated an accuracy of 70.5%.
Keywords: k-means clustering algorithm, convolutional neural network (CNN), unsupervised learning.
ВведениеДля обучения глубоких нейронных сетей требуется большое количество данных. В крупных наборах данных методы обучения с учителем прекрасно себя зарекомендовали в последние годы благодаря достижениям в параллельных вычислениях [1]. Популярные наборы данных, такие как ImageNet [2], содержат более чем один миллион размеченных образцов, но даже этого недостаточно, и исследователи нуждаются в еще более крупных наборах данных в этой области. Расширяясь, наборы видеоданных становятся все более важными в контексте применения сверточных нейронных сетей для задач распознавания событий. Во всех таких сценариях, маркировка данных необходима, чтобы алгоритм обучения с учителем мог быть использован. Однако задача маркировки данных – довольно сложное занятие, которое занимает много времени. К примеру, несколько сотен часов были потрачены на создание ImageNet и тысячи часов могут понадобиться для аннотирования самого простого набора видеоданных [3]. Исследовательское сообщество искало способы обойти эту проблему и пришло ко мнению, что серьезного прорыва можно достичь за счет использования неразмеченных данных, которые широко доступны в общем доступе в больших количествах. За последние десятилетия многочисленные исследования были посвящены обучению иерархических признаков для глубокого обучения в контексте распознавания изображений. Примеры включают в себя контролируемое, неконтролируемое, полу-контролируемое обучение. Такие методики глубокого обучения используют иерархию слоев, которые задействуют фильтры для извлечения многочисленных входных признаков и соединения для объединения извлеченных признаков вместе в качестве входных данных для следующего слоя. В более ранних исследованиях в этой области предварительное обучение без учителя было обязательным для обучения глубоких нейронных сетей посредством методик обучения с учителем. Недавние достижения в области сверточных нейронных сетей (CNN) в сочетании с большими объемами размеченных данных хорошо проявили себя в задачах распознавания образов для исправления этой проблемы [4].
С другой стороны, алгоритмы обучения без учителя, такие как кластеризация методом k-средних, также увеличили количество параметров в сети и достигли передовых результатов, в случаях, когда количество размеченных данных ограничено. Хотя методики обучения без учителя, использующие алгоритм k-средних, были, в основном, использованы для обучения фильтров в нескольких исследованиях [5], [6], полученная структура имела много сходств с CNN (сверточной нейронной сетью), такие как использование свертки и субдискретизации в каждом слое. Главное различие между CNN и методиками обучения без учителя на основе k-средних применительно к распознаванию изображений заключается в количестве слоев (глубине), количестве фильтров (ширине) в каждом слое и соединениях между слоями. CNN повышают точность с помощью увеличения глубины и ширины сети. Недавние исследования показали, что на производительность значительное влияние оказала увеличенная глубина. И напротив, методики обучения без учителя для глубоких сетей не смогли масштабироваться до такой же глубины как обычные CNN. Таким образом, недавние исследования в области обучения без учителя используют большую ширину сети и 2-3 слоя с сужающимися выходными данными. В этой работе будет продемонстрировано, что изучение соединений между слоями глубокой нейронной сети играет ключевую роль в повышении производительности методик обучения без учителя.
Несмотря на то, что в ранних работах по CNN зачастую было принято полагаться на неполную схему соединений [7] для поддержания числа соединений в разумных пределах, в последнее время тренд изменился в сторону полносвязности слоев с целью использования всех возможностей, предоставляемых параллельными вычислениями. Полносвязные слои выполняют множество потенциально ненужных операций, поскольку они соединяют все объекты предыдущего слоя с каждым объектом следующего. В этом исследовании представлена улучшенная версия алгоритма кластеризации с обучением без учителя, позволяющая фильтрам обучаться различным признакам. Это достигается за счет предотвращения обучения алгоритмом излишних фильтров. Также к научной новизне этой работы можно отнести то, что изучение разреженных матриц соединений между слоями происходит посредством проецирования разреженных групп признаков в объект для следующего слоя. Было показано, что алгоритм сверточной кластеризации k-средних способен обеспечить сопоставимые иерархии признаков среднего уровня для контролируемых сетей с улучшенным обучением соединений.
Методы и принципы исследованияМетод обучения фильтрам основан на алгоритме k-средних. Классический алгоритм k-средних находит центры масс кластеров, которые минимизируют расстояние между точками в евклидовом пространстве. В этом случае, точки являются случайным образом извлеченными фрагментами изображения, а центры масс – фильтрами, использующимися для кодирования изображений. С этой точки зрения, алгоритм k-средних обучается словарю ![]() из вектора данных
из вектора данных![]() . Алгоритм обучается словарю следующим образом:
. Алгоритм обучается словарю следующим образом:
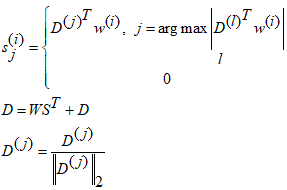 (1)
(1)
где ![]() — это кодовый вектор, ассоциированный с входом
— это кодовый вектор, ассоциированный с входом ![]() - j-ая колонка D. Матрицы
- j-ая колонка D. Матрицы ![]() имеют колонки
имеют колонки ![]() соответственно.
соответственно. ![]() - выбранные случайным образом участки входных изображений, имеющие такую же размерность как векторы словаря
- выбранные случайным образом участки входных изображений, имеющие такую же размерность как векторы словаря ![]() .
.
Описанная схема обучения обучает центры масс каждого кластера на уровне фрагмента, в то время как в CNN фильтры применяются к изображениям сверточным способом. Как можно увидеть из рис. 1, множество центров масс из обучения k-средними имеют практически такую же ориентацию и являются смещенными версиями друг друга в пространстве. Таким образом, после операции свертки они приведут к образованию излишних карт признаков на соседних областях. В следующем подразделе будут рассмотрена предлагаемая модификация алгоритма k-средних, которая сводит эту проблему к минимуму.

Рис. 1 – Фильтры обученные на STL-10 с помощью k-средних и сверточных k-средних: а) метод k-средних; б) сверточный метод k-средних
Для того чтобы снизить избыточность между фильтрами на соседних областях, был предложен новый метод извлечения фрагментов из изображений. Этот метод существенно снижает избыточность в центрах масс, получившихся в результате выполнения алгоритма k-средних, и оставляет только необходимый базис. Стандартный алгоритм k-средних извлекает случайные участки из входных изображений, чьи размеры соответствуют размерам центров масс. Напротив, предложенный метод использует более широкие окна в качестве входов для того, чтобы решить какой фрагмент извлечь для кластеризации.
Окна выбираются таким образом, чтобы быть в два раза больше, чем размер фильтра и извлекаются случайным образом из входных изображений. Центры масс алгоритма k-средних сворачивают окно целиком для вычисления меры сходства на каждом участке извлеченной области. Участок, соответствующий наибольшей активации из окна, считается наиболее похожим на центр масс. И наконец, участок на этой области (наибольшая активация) извлекается из окна и присваивается соответствующему центру масс. Измененный процесс обучения словаря можно записать следующим образом:
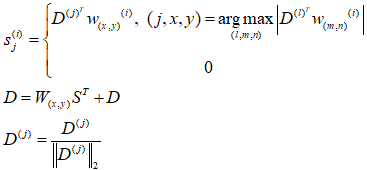 (2)
(2)
где ![]() - j-ая колонка словаря, которая соответствует
- j-ая колонка словаря, которая соответствует ![]() ядру 3D-фильтра и
ядру 3D-фильтра и ![]() - окно размером
- окно размером ![]() - индекс входного участка,
- индекс входного участка,![]() - извлеченный участок из области
- извлеченный участок из области ![]() размером
размером ![]() .
.
После того, как скоррелированные фильтры удалены, у новых фильтров появляется больше возможностей для обучения дополнительным признакам. Фильтры, которые обучаются с помощью k-средних и сверточных k-средних представлены на рис. 1. Как можно увидеть, фильтры, которые обучались на уровне участков с помощью алгоритма k-средних имеют похожие признаки, но на разных областях внутри участка.
В работе также изучаются способы обучения соединениям от одного слоя сети к следующему. В то время как полносвязные слои используют все признаки предыдущего слоя при переходе к следующему слою, в работе используются неполные соединения, которые более эффективны при вычислениях. Эти неполные соединения используют несколько групп, каждая из которых включает ограниченную порцию признаков предыдущих слоев. Используется матрица разреженных соединений, которая ограничивает локальное рецептивное поле. Следовательно, становится возможным избежать низкой эффективности алгоритма k-средних, когда входные данные обладают большой размерностью.
Метод использует обучение с учителем на ограниченном наборе данных во время обучения весам соединений между слоями. Соединения описываются полносвязной матрицей весов, агрегирующей карты признаков. Таким образом, одно значение в матрице весов отражает то, насколько этот признак важен для соответствующей группы. Для обучения взаимосвязям между картами и организации их в группы добавляется сверточный слой с заранее заданным неполным соединением. Добавляется линейный классификатор после сверточного слоя и обучается система посредством обратного распространения ошибки. Интуиция этой настройки заключается в том, что, так как новым фильтрам обучаются из групп признаков и каждая матрица весов агрегирует признаки, чей выход находится в заранее определенной группе, матрица весов в действительности вынуждена обучаться правильным соединениям между входными картами признаков и предопределенными группами в процессе обучения. Таким образом, даже несмотря на то, что соединения сверточного слоя были предопределены, матрица весов обеспечила достаточную гибкость для определения соединений на практике.
Необходимо заметить, что матрица весов, агрегирующая карты признаков, может быть рассмотрена как одномерный полносвязный сверточный слой с активированным смещением. Такой подход позволяет ограничить локальное рецептивное поле для алгоритма k-средних. После того как завершится контролируемое обучение соединениям, выученные фильтры удаляются из сети и остается только матрица соединений. Затем алгоритм сверточных k-средних применяется вновь к предварительно обученной матрице соединений для обучения фильтрам для следующего слоя. Детали и экспериментальные результаты представлены в следующем разделе.
Основные результатыЭксперименты были проведены, сочетая
1) выученные с учителем и без учителя фильтры
2) выученные с учителем фильтры и случайные соединения между слоями.
Эксперименты призваны продемонстрировать важность обучения соединениям. Пусть имеется двухслойная нейронная сеть. Первый слой имеет 96 фильтров размерами . Сверточный слой применяется с шагом 4 и формируемый результат корректируется ReLU. Между извлечением признаков первого и второго слоев предварительно определяются группы как 4 последовательных карты признаков, что в итоге дает результат в виде 24 групп. Из каждой группы можно обучиться 64 фильтрам, размер фильтра второго слоя выбран , это исходит из выбора предопределенной неполной схемы соединений. После свертки с фильтрами применяется операция субдискретизации для снижения размерности. Функция активации ReLU следует за операцией подвыборки. Используется линейный классификатор с 2 слоями с 512 скрытыми нейронами и дропаут регуляризацией.
Для обучения фильтрам без учителя применяется сверточный алгоритм k-средних к немаркированным данным. Случайное соединение относится к случаю, когда фильтры первого слоя соединены со вторым по предопределенной схеме соединения. Контролируемое соединение относится к случаю, когда обучается матрица контролируемых соединений перед заранее определенной схемой соединения. Фильтры второго слоя и матрица соединений обучаются вместе, это заставляет матрицу соединений организовать карты признаков таким образом, чтобы каждая группа содержала объекты, которые необходимо объединить вместе. Чтобы обучиться фильтрам второго слоя неконтролируемым способом с контролируемыми соединениями, необходимо исправить обученную с учителем матрицу соединений и обучить локальные фильтры для каждой группы методом сверточных k-средних.
В таблице 1 представлены результаты этих экспериментов.
Таблица 1 – Точность классификации на тестовой выборке STL-10 и 2 слоев сети
| Первый слой | Соединение | Второй слой | Точность, % |
| С учителем | С учителем | С учителем | 60.5 |
| Без учителя | Случайное | С учителем | 63.8 |
| Без учителя | Случайное | Без учителя | 64.3 |
| Без учителя | С учителем | С учителем | 65.9 |
| Без учителя | С учителем | Без учителя | 66.7 |
Во-первых, обучение всей сети с помощью обучения с учителем дает более низкую точность, как и ожидалось, так как имеет место быть переобучение на ограниченном наборе размеченных данных. Обучение без учителя для первого слоя обеспечило значительное повышение производительности по сравнению с сетью, обученной полностью с учителем. В экспериментах контролируемое обучение соединениям повышает производительность для каждого случая, хотя обучение без учителя все же дает более высокую производительность. Алгоритм обучения K-средних требует увеличения количества фильтров для получения сопоставимых результатов в сравнении с контролируемым алгоритмом обратного распространения ошибки. Несмотря на то, что контролируемый алгоритм может более эффективно представлять данные с меньшим количеством фильтров, он теряет точность и переобучается на обучающем наборе при увеличении количества фильтров. Напротив, неконтролируемый алгоритм (сверточный k-средних) плохо работает с небольшим количеством фильтров. Эта разница может быть из-за того, что контролируемый алгоритм обучается отличительным признакам, тогда как k-средних обучается любым часто встречающимся признакам.
Наконец, сравним метод с опубликованными современными методами на наборе данных STL-10. В рамках сравнения, в основном, обратим внимание на алгоритмы, которые обучаются фильтрам без учителя. Подход с использованием нескольких словарей (Coates & Ng, 2011b [6]; Lin & Kung, 2014 [8]) – это объединение представлений, которые вычисляются в разных слоях (т. е. выходных значений), в виде вектора признаков изображения. Используются те же параметры обучения и предварительная обработка, которые использовались в других экспериментах.
Для анализа результатов классификации используются двухслойные сети. Однако, увеличивается размер сети, шаг в первом слое заменяется на операцию подвыборки , которая увеличивает точность. Дополнительно увеличивается точность за счет подхода с несколькими словарями. Так, для двух слоев с мультисловарной сетью используется аналогичная сеть из эксперимента с двумя слоями, в котором были получены 64 фильтра из каждых 24 групп на выходе из первого слоя. Эта сеть объединяется с однослойной сетью с 512 фильтрами. Однослойная сеть также включает активацию ReLU и операцию подвыборки для уменьшения размера вывода до 512 × 4 × 4. Как видно из табл. 2 [9], [10], [11], двухуровневая сеть с несколькими словарями обеспечивает точность 70,5%. Необходимо обратить внимание, что это значение значительно выше, чем у всех ранее представленных неконтролируемых методов обучения. При этом сеть на порядок меньше (по количеству параметров) чем сети, использованные в (Coates & Ng, 2011b; Lin & Kung, 2014). В табл. 3 приведены для сравнения методики контролируемого и частично контролируемого обучения, как можно увидеть, предложенный алгоритм обладает достаточно высокой точностью и находится с ними примерно на одном уровне по точности.
Таблица 2 – Точность классификации на STL-10 и 2 слоях сети (обучение фильтрам без учителя)
| Алгоритм | Точность, % |
| Coates & Ng (2011) (1 слой) | 61.5 |
| Hui (2013) (3 слоя) | 65.8 |
| Lin & Kung (2014) (3 слоя и мультисловарь) | 66.4 |
| Предложенный метод | 70.5 |
Таблица 3 – Точность классификации на STL-10 и 2 слоях сети (обучение фильтрам с учителем и с частичным привлечением)
| Алгоритм | Точность, % |
| Swersky (2013) | 69.5 |
| Zhao (2015) (автокодировщик с частичным контролем) | 73.7 |
| Dosovitskiy (2014) | 71.9 |
Предложенный алгоритм был реализован на языке Python с использованием фреймворка TensorFlow и выполнен на персональном компьютере с процессором Intel Core i7-4770, 16 GB RAM и графическим процессором NVIDIA Titan X GPU с 12 GB RAM, время выполнения составило около 9 часов, что является приемлемым значением, учитывая размер выборки STL-10 (более ста тысяч изображений). Алгоритм возможно запустить на процессорах серии Intel Core i5, 8 GB RAM и видеокартах с 2 GB памяти, однако время выполнения вырастет в несколько раз.
ЗаключениеБыл разработан новый алгоритм, который сочетает в себе сильные стороны кластеризации без учителя, метода k-средних и сверточных нейронных сетей, для условий, когда лишь очень малая часть входных данных является размеченной. Алгоритм модифицирует стандартный метод кластеризации k-средних, так что при использовании с CNN он не обучается избыточным фильтрам на соседних областях. Также была предложена настройка обучения с учителем для обучения подходящим соединениям между слоями. Эксперименты показали, что предложенный алгоритм имеет наибольшую эффективность в сравнении с актуальными методиками, которые обучаются фильтрам в нейронной сети без учителя.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References
- Szegedy C. Going deeper with convolutions / C. Szegedy et al. // 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015. P. 1-9.
- Deng J. Imagenet: A large-scale hierarchical image database / J. Deng et al. // In CVPR. 2009. P. 248–255.
- Russakovsky O. ImageNet Large Scale Visual Recognition Challenge / O. Russakovsky et al. // International Journal of Computer Vision (IJCV). April 2015. P. 1–42.
- Krizhevsky A. Imagenet classification with deep convolutional neural networks / A. Krizhevsky, I. Sutskever, G. Hinton // In Advances in neural information processing systems. 2012. P. 1097–1105.
- Coates A. The importance of encoding versus training with sparse coding and vector quantization / A. Coates, A. Ng // In ICML. 2011. P. 921–928.
- Coates A. Selecting receptive fields in deep networks / A. Coates, A. Ng // In Advances in Neural Information Processing Systems. 2011. P. 2528–2536
- LeCun Y. Gradient-based learning applied to document recognition / LeCun Y., Bottou L., Bengio Y., Haffner P. // Proceedings of the IEEE. 1998. Vol. 86, № 11. P. 2278–2324.
- Lin T. Stable and efficient representation learning with nonnegativity constraints / T. Lin, H. Kung // In ICML. 2014. P. 1323–1331.
- Hui K. Direct modeling of complex invariances for visual object features / K. Hui // In Proceedings of the 30th International Conference on Machine Learning (ICML-13). 2013. P. 352–360.
- Swersky K. Multi-task bayesian optimization / K. Swersky, J. Snoek, R. Adams // In Advances in Neural Information Processing Systems. 2013. P. 2004–2012.
- Dosovitskiy A. Discriminative unsupervised feature learning with convolutional neural networks / A. Dosovitskiy et al. // In Advances in Neural Information Processing Systems. 2014. P. 766–774.