Развитие генеративных состязательных сетей в современном глубоком обучении
Развитие генеративных состязательных сетей в современном глубоком обучении
Аннотация
В данной статье представлен обширный исторический контекст генеративных состязательных сетей (ГСС), от их технологических и теоретических истоков в ранних парадигмах генеративных моделей до сложных архитектур, лежащих в основе современных исследований. Работа охватывает широкий спектр областей, связанных с ГСС, включая основные вероятностные и нейронные генеративные модели, предшествовавшие состязательному обучению. В ней исследуется концептуальный прорыв ГСС в 2014 году и определяются ключевые архитектурные достижения, которые сформировали их путь от создания до настоящего времени, а именно: условные GAN, DCGAN, StyleGAN и BigGAN. В ней также рассматриваются текущие реальные приложения в различных областях и определяются возникающие тенденции, такие как гибридные генеративные модели и этические проблемы, связанные с искусственными медиа. Обсуждение заканчивается рассмотрением текущих исследовательских задач и перспектив, таких как интерпретируемость, стабильность обучения, эффективность данных и внедрение ИИ с учетом этических аспектов. Исследование представляет собой основанный на исторических данных, но в то же время футуристический обзор эволюции и потенциала ГСС в машинном обучении.
1. Introduction
Generative modeling is one of the fundamental pillars of machine learning (ML) and is responsible for learning data distributions as complex as possible and sampling new points that are close to those observed during training. Among a number of innovations in this space, Generative Adversarial Networks (GANs) have been some of the most groundbreaking of the last decade. GANs were introduced by Ian Goodfellow and others in 2014 that transformed generative modeling as a minmax game between two neural networks, that generate extremely realistic artificial samples without ever having to calculate explicit probability
.The impact of GANs has been extensive across many applications ranging from image creation and video generation to medical imaging, data augmentation and creative work . Success with GANs was not an isolated phenomenon
. It came after years of studies in developing probabilistic models, latent variable models, and neural networks. Such early methods, although frequently limiting representational capacity or scalability, created fundamental work for the adversarial training paradigm.As shown in figure 1, this paper gives a historical account of the evolution of the GANs, starting with a comprehensive coverage of pre-GAN generative models like Gaussian Mixture Models, Hidden Markov Models, Variational Autoencoders and Restricted Boltzmann Machines. Then it highlights the evolution of the GANs, also giving a mention of their theoretical evolution and early troubles. Next, the development of GAN architectures from 2014 to the present is emphasized, and how each innovation solved an existing constraint and expanded the boundaries of what could be achieved by generative models.
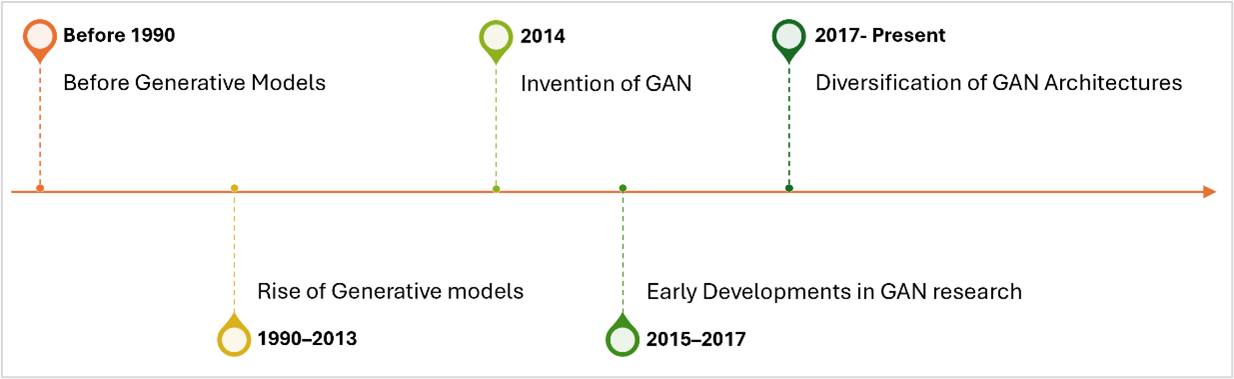
Figure 1 - Time line of the development of GANs
2. Period before Generative Models
Prior to GANs, the approach for generative modeling was in a series of probabilistic and neural-based methods that attempted to comprehend and replicate the underlying structure of data . Although they were typically suboptimal in terms of both generative quality and scalability, they were the theoretical and algorithmic platforms on which GANs would ultimately be developed.
2.1. Probabilistic Generative Models
These early generative models were based on conventional probability theory. Models like Gaussian Mixture Models (GMMs) used straightforward yet efficient methods for modeling data as a combination of several Gaussian distributions. Likewise, Hidden Markov Models (HMMs) were very popular for modeling sequences, particularly in speech processing and bioinformatics . These models handled temporal dependencies and structure, but were incapable of modeling complex high-dimensional data like images or audio.
2.2. Latent Variable Models
The concept of including latent variables in generative models enabled them to have more expressive and general models. For example, Factor Analysis and Principal Component Analysis employed linear assumptions when discovering hidden structure in data. Their linearity, however, prevented them from producing better generative work . This was surmounted with Bayesian networks and directed graphical models that added probabilistic dependencies across variables, providing stronger abstractions of data distributions.
2.3. Energy-Based and Neural Generative Models
Deep Learning introduced a new generation of generative models that employed neural networks to learn difficult data representations. Deep Belief Networks (DBNs) and their stacked variants, Restricted Boltzmann Machines (RBMs), were a breakthrough . They were able to represent binary and continuous data in terms of energy functions and were trained by contrastive divergence.
Another key advancement was the Variational Autoencoder (VAE), which emerged around 2013. VAEs introduced a probabilistic method for training neural networks to synthesize data by maximizing a lower bound on the likelihood of the data given the network . The method allowed for continuous latent spaces and controllable generation but resulted in blurry or low-resolution outputs because it had an explicit reconstruction loss.
2.4. Shortcomings of these models
Even though these were major breakthroughs, these models had some common weaknesses such as explicit likelihood estimation, overly simplistic assumptions over data distributions, and the inability to generate high-quality outputs . This backdrop formed the ground for developing GANs that revolutionized the concept of generative modeling through adversarial learning.
3. Emergence of GANs
3.1. Overview of a GAN
The principle of GANs is the concurrent training of two networks: a generator (G) and a discriminator (D). The generator attempts to generate realistic data from random noise, consequently the discriminator attempts to identify whether a sample of data is from the training data or from the generator . The two networks are concurrently trained in a minimax game given in equation 1.
This adversarial architecture motivates the generator to enhance its outputs so that the discriminator is unable to tell real from fake, effectively learning to replicate the actual data distribution as illustrated in figure 2.

Figure 2 - Generated images from the GAN:
(a) – MNIST; (b) – TFD
Note: the final (right) column is the training image from the datasets
Although theoretically valid, the early GAN model had some very practical training issues. These were optimization instability, mode collapse (in which the generator simply generates only a limited variety of outputs), and sensitivity to hyperparameters. Furthermore, there was not an effective measure to calculate the generative performance, therefore monitoring progress during training was difficult .
Despite these problems, GANs showed a sharp advantage over previous models. They had the ability to produce high-dimensional, crisp, and high-resolution outputs, particularly in the case of image generation. With this success, GANs became the center of mainstream discussion in ML.
3.3. Instant Impact and Adoption
The adversarial training framework was a probability-based generative modeling. It provided flexible, implicit modeling of challenging data distributions without requiring the explicit density function or the reconstruction loss. GANs were soon applied to image generation, including synthetic faces and handwritten digits, quickly attracting attention in academia and industry .
The beauty and richness of the GAN architecture spawned an outbreak of research activity to address training stability, create variants, and extend adversarial training to tasks beyond image generation, such as image-to-image translation, super-resolution, and domain adaptation .
4. Gan Evolution
After their initial success, GANs developed instantly, with researchers proposing several architectural modifications in an effort to fill the gaps of the initial model and to increase its ability. From 2014 up to the present, several most significant variants were suggested, with each having new methods for increasing training stability, output quality, and controllability.
4.1. Significant Architectural Enhancements
Deep Convolutional GAN (DCGAN) :
DCGAN brought architectural revolution with fully convolutional architecture, replacing fully connected layers with transposed convolutions in the generator and strided convolutions in the discriminator. Coupled with the use of batch normalization, it stabilized training and significantly enhanced the quality of high-dimensional image generation.
Conditional GAN (cGAN) :
cGANs generalized the GAN architecture by adding auxiliary information, in the form of class labels, to both the generator and discriminator. Conditioning at generation allowed cGANs to exert greater control over the output, making them effective for applications such as image translation, label-conditional synthesis, and data augmentation.
StyleGAN and StyleGAN2 :
NVIDIA developed StyleGAN, which proposed a new architecture that introduced style information at various stages of the generator through an intermediate latent space and Adaptive Instance Normalization (AdaIN). This allowed unprecedented manipulation of image features, allowing the generation of photorealistic, high-resolution faces. StyleGAN2 extended the architecture to enhance image quality, training stability, and elimination of visual artifacts, setting the standard for contemporary image synthesis.

Figure 3 - Image styles created using StyleGAN
BigGAN showed the strength of scale architecture by scaling batch size, depth of residual blocks, self-attention, and class-conditional inputs. Trained with high-performance hardware, it attained state-of-the-art image generation quality, showing that model and training scale could achieve revolutionary boosts in fidelity and diversity.
4.2. Broadcast Applications
Applications of GANs diverged much more widely than image generation. Given below are several sectors of applications .
Healthcare: GANs have been applied in the creation of synthetic medical images, the restoration of low-quality scans, and the augmentation of sparse disease datasets to aid diagnosis models.
Art and Creativity: GAN-based software enabled users to co-create visual art, create new patterns of design, or mix painting styles in an interactive manner.
Entertainment and Media: In film, gaming, and virtual reality, GANs have been applied in character creation, texture generation, and even video frame interpolation.
Cybersecurity and Privacy: Threat modeling through the generation of adversarial examples has also been helped by GANs, along with privacy-preserving learning through anonymization.
Data Augmentation : Samples generated by GANs have been utilized in the tasks of supervised few-data learning to enhance model robustness and generalization.
5. Emerging Trends
While GANs continue to evolve, many new trends have started influencing the direction of research and use. The trends capitalize on the achievements as well as the open issues yet to be filled .
Hybrid Generative Models:
Researchers are now increasingly mixing GANs with other generative models like Variational Autoencoders (VAEs) and Diffusion Models to harness the power of each model. Hybrid models try to reproduce the quality of GANs with tractability and stability of probability-based methods.
Self-Supervised and Few-Shot Learning:
There is a growing emphasis on effective use of data, where the GANs are adjusted to train effectively with sparse labeled samples or few-shot environments. This kind of development is crucial for real-world use, particularly when the data is sparse or expensive to obtain.
Multi-Modal Generation :
The most recent developments enabled GANs to handle multi-modal inputs and outputs, i.e., create images from text descriptions or create video based on audio input. Classic models perform better when they are dealing with a single modality e.g., text, images, or audio. However, if they are asked to work with two different types of data at the same time, they perform poorly. GANs on the other hand, have proven to be a viable option in this area, capable of learning and generating across various modalities of data in an integrated and coherent way. Cross-modal capabilities are significantly broadening the scope for utilizing generative AI, especially in creative applications, interactive media, and building multimodal AI systems.
Interpretable and Controllable GANs :
New methods, like StyleGAN's latent space disentanglement and semantic manipulation techniques, have made it possible to fine-grain control a single feature in outputs. The effect is that users can modify top-level attributes like age, expression, or background, without requiring a retrain. Consequently, interpretable latent representations are emerging in areas such as design, where exact edits must be made, simulation, where controlled variation is essential, and medicine, where interpretability can enhance clinical decision-making and trust in AI-driven diagnosis.
However, these have caused ethical and societal problems. The broad applications of GANs for creating hyper-realistic media have caused concern over deepfakes, disinformation, and identity forgery . Deepfakes, in which video or audio is edited to essentially make it appear as if actual people are saying things that they never actually said in the first place, significantly threaten privacy, consent, and trust in digital media
. Manipulation through GAN-generated forged news images or manipulated speech misleads public discourse and can be taken advantage of in political or social debate. Identity impersonation through GANs to generate virtual faces or biometric feature cloning is also a security threat, especially in authenticating systems. In response, increased effort is invested in developing detection devices, watermark techniques, and advocating ethical guidelines to promote responsible usage of synthetic media.6. Conclusion
Generative Adversarial Networks (GANs) have had a very significant impact on the paradigm of generative modeling in artificial intelligence, making it possible for highly realistic data generation in images, audio, video, and text. This work traced the historical evolution of GANs from early probabilistic and neural generative models of the pre-GAN era to the beginnings of adversarial learning, to diversification and real-world deployment of GAN architectures.
By situating GANs within the broader generative modeling landscape, their advent plugged long-standing holes in earlier approaches were highlighted, particularly in terms of likelihood estimation and generation quality. The widespread creation of GAN variations from DCGAN and StyleGAN through BigGAN to conditional models is a testament to a rich research ecosystem continually pushing the boundaries of what generative AI can achieve.
However, as technology improves, there are long-term challenges. Instability in training, mode collapse, ambiguity in testing, and ethics continue to be challenges. New directions like hybrid models, multimodal generation, and explainable architecture present widespread paths of innovation, and demands for ethical oversight and good deployment are a testament to increasing societal applicability of GAN technologies.
The history of GANs tells not only a story of technical progress but also a story about the relationship between theory, application, and responsibility in the generative AI era. As research on GANs embarks on its second decade, its destiny will no longer be in more realistic images or quicker models but in making rational and responsible contributions to scientific and societal advancement.