АНАЛИЗ РЕЦЕПТОВ ПРИ ПОМОЩИ МАШИННОГО ОБУЧЕНИЯ

DOI: https://doi.org/10.23670/IRJ.2018.74.8.007
АНАЛИЗ РЕЦЕПТОВ ПРИ ПОМОЩИ МАШИННОГО ОБУЧЕНИЯ
Научная статья
Свистова С.Ф.*
Российский технологический университет, Москва, Россия
* Корреспондирующий автор (svistova.s[at]mail.ru)
Аннотация
В последнее время анализ рецептов набирает популярность с точки зрения рекомендательных систем. Рассматриваются задачи поиска и рекомендации рецептов, сочетаемости ингредиентов и даже создания новых рецептов. В данной работе мы занимаемся поиском схожих кухонь разных стран мира с помощью техник Нейросети и SimRank алгоритм. В этой статье мы применили алгоритмы машинного обучения к «гурманским» данным. Точнее, мы пытались найти сходство между кухнями разных стран и ингредиентами, анализируя ингредиенты различных рецептов с помощью методов машинного обучения.
Ключевые слова: SimRank, сбор данных, нейросети.
ANALYZING COOKING RECIPES WITH MACHINE LEARNING
Research article
Svistova S.F.*
Russian Technological University, Moscow, Russia
* Corresponding author (svistova.s[at]mail.ru)
Abstract
Recently, recipe analysis gaining popularity among recipes recommendation systems. They address problems of finding and advising recipes, good ingredient pairings and even inventing new recipes. Ingredient pairings are studied in order to supplement flavour-based heuristics with statistical approach and build the compatibility model of the components in the cuisine. In this paper we find similarities between cuisines given recipes using the following techniques: Neural Network classifier and SimRank algorithm. In this paper we applied machine learning algorithms to the "gourmet" data. More precisely, we tried to find similarities between cuisines of different countries, ingredients by analysing ingredients of the different recipes.
Keywords: SimRank, Data Mining, neural network.
Data Mining
We could not find any qualitative open-source databases of recipes, as well, recipe recommendation systems do not haste to provide their databases even for academic purposes. However, we found rather well-structured, from html point of view, New York Times website that comprises around 17000+ recipes of about 50 world cuisines, such as Asian, American, European, African, etc [5], and "mined" them using open-source Python framework scrapy [6, P. 113]. The most challenging part was to preprocess obtained data. Each recipe, using html structure was broke down into separate raw ingredients, after that a lot of human-hours were spent to sanitize these raw ingredients:
- fix typos;
- find similar ingredients with different names, e.g. "bun" and "roll";
- unite them into more extensive groups to reduce dimensionality, e.g. different kinds of noodles and macaroni makes sense to treat as "pasta".
In the end we had 7987 recipes from 48 different cuisines with 1026 distinct ingredients grouped into 111 more wide classes. Unfortunately, some cuisines were represented only with small number of recipes, such as 50 (Irish, Turkish, ...) as well as with very large number about 600 (American) or 1400 (Italian), thus, we constructed training sets in a such way, that each cuisine is sampled with 50-100 recipes giving the total training set size of 1700-3000 samples.
Neural Network (30 November 2017 - 4 December 2017)
To see if it is possible to predict if some set of ingredients can originate from the particular cuisine, using Python we have built classifier based on multilayer neural network with gradient descent back propagation [7, P. 61].
As the inputs we used vector of binary variables that denote presence of particular ingredients from the set of all ingredients.
As the output we got vector with probabilities, each of which denotes likelihood of the input set of ingredients to belong to particular cuisine. Number of the outputs is equal to the number of cuisines.
As activation functions we used logistic sigmoid function and as an output activation function we took softmax [8, P. 5].
To configure the network we used following heuristics:
- Random sample training sets that more or less uniformly spans over all cuisines.
- Number of hidden nodes inside a layer is around
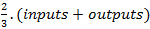
- Number of hidden layers is adjustable.
To obtain the similarity between cuisines using neural network we used following approach:
- Feed test set recipes to NN and obtain probabilities
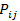 given by the output softmax activation function, where i- number of the recipe, j- number of cuisine.
given by the output softmax activation function, where i- number of the recipe, j- number of cuisine. - Consider cuisines j and k to be similar, if for each recipe i from the test set the probability is close to
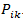 . Thus, we can define similarity as
. Thus, we can define similarity as
![]() (1)
(1)
We tried to train neural-network with different numbers of layers ![]() and different sampling sizes
and different sampling sizes ![]() . However, it almost didn’t train for
. However, it almost didn’t train for ![]() , giving either almost 100% error rate (absolute input insensitivity) or not converging at all. Training/testing errors are provided in the Table 1.
, giving either almost 100% error rate (absolute input insensitivity) or not converging at all. Training/testing errors are provided in the Table 1.
Table 1 – NN training/testing error rates, %
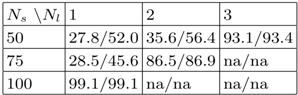
Also we faced that with increasing number of layers, NN performs worse, both qualitatively and in terms of time. The best testing results we obtained for sampling size ![]() and one layer, getting test set classification rate as large as 54,4%.
and one layer, getting test set classification rate as large as 54,4%.
Then, we imagined of several custom sets of ingredients to see to which cuisine the best obtained NN classifier relates it:
- Pasta, Tomato, Olive ⇒ Italian;
- Pasta, Mushroom, Soy sauce ⇒ Japanese, Chinese, Korean;
- Olive, Salad, Cheese ⇒ Greek, Mediterranean, Italian
- Sausage, Olive, Potato, Onion ⇒ Spanish, Portuguese;
- Sausage, Beer ⇒ German;
- Sausage, Bread ⇒ American;
- Mushroom, Cream, Wine, Cheese ⇒ Italian, French.
It can be seen, that predictions are quite reasonable for these sets.
SimRank
To find similarity between cuisines in a more, probably, natural way is to calculate pairwise similarity. The most basic homogeneous SimRank algorithm allows to find similarity between interconnected objects of different classes. The notion of similarity is intuitively described as follows: "Objects ![]() from the set of classes J are similar if they are connected with similar objects". We used following classes
from the set of classes J are similar if they are connected with similar objects". We used following classes ![]()
Objects of class are connected only with objects of class , objects of class are connected only with objects of class and . This way, ingredients are similar (read pairwise-compatible) if they are used in similar recipes, recipes are similar if they are cooked inside the similar cuisines and comprise similar ingredients, cuisines are similar if they contain similar recipes. The connections can be represented as undirected graph with respective column-stochastic adjacent matrix . It is not hard to see, that it is a tripartite graph. Let be similarity matrix with each element denoting pairwise similarity between objects ![]() add ,
add , ![]() - identity matrix. Then, SimRank can be formulated in iterative manner:
- identity matrix. Then, SimRank can be formulated in iterative manner:
![]()
where ![]() - decay factor. Algorithm can be terminated when
- decay factor. Algorithm can be terminated when ![]() , where ∈ is some tolerance. From statistical mathematics and Markov Chains it is known, that SimRank, eventually, converges for a graph as described above. We implemented this algorithm in Python and applied it to the recipe data with decay factor c=0.8, tolerance
, where ∈ is some tolerance. From statistical mathematics and Markov Chains it is known, that SimRank, eventually, converges for a graph as described above. We implemented this algorithm in Python and applied it to the recipe data with decay factor c=0.8, tolerance ![]() for sampling sizes
for sampling sizes ![]() . Similarity matrix for
. Similarity matrix for ![]() gave following results for cuisine similarity and ingredients compatibility:
gave following results for cuisine similarity and ingredients compatibility:
- Top most pairwise-similar cuisines appeared to be Mediterranean, Greek, Turkish, Moroccan, Spanish, Portuguese, Italian, which is, indeed, true as they are all part of Mediterranean cuisine family.
- From pairwise ingredient similarity we got several funny facts, for instance, Chocolate and Cocoa are the most compatible, as well as Cocoa and Cacao, which revealed preprocessing error when we accidentally treated them differently. Other top most-similar pairs are Cocoa-Vanilla, Olive-Garlic, Soy Sauce-Soy, Coffee-Cocoa.
Visualization
In order to visualize similar cuisines we used scikit-learn machine-learning library and applied Agglomerative Clustering algorithm to similarity matrices [9, P. 205], [10, P. 603]. After that, we created a 2D projection of cuisines using GraphViz library, uniting them into groups according to the output of the clustering algorithm. For SimRank and ![]() on the figures 1 and 2 this projection can bee seen (for
on the figures 1 and 2 this projection can bee seen (for ![]() it is same as for
it is same as for ![]() ). We can notice that the latter case shows slightly more logical results, for instance, Latin American, South American, Mexican, Caribbean and Southwestern cuisines became separated from the Mediterranean cluster, also German and Austrian were merged, though American and Jewish were united for some reason. In both cases Asian cuisines are broke into several groups. Some of the cuisines are not clustered as they comprise small number of recipes, e.g. Icelandic, Pakistani, Barbecue all represented by one. For cuisine comparison and clustering, however, neural network classifier approach, along with similarity matrix
). We can notice that the latter case shows slightly more logical results, for instance, Latin American, South American, Mexican, Caribbean and Southwestern cuisines became separated from the Mediterranean cluster, also German and Austrian were merged, though American and Jewish were united for some reason. In both cases Asian cuisines are broke into several groups. Some of the cuisines are not clustered as they comprise small number of recipes, e.g. Icelandic, Pakistani, Barbecue all represented by one. For cuisine comparison and clustering, however, neural network classifier approach, along with similarity matrix ![]() obtained using proposed metric1, does not show very good results, which can bee seen on the figure 3. Some pairings such as Latin American-Mexican, Asian-Vietnamese or Spanish-Italian are preserved, but mostly, strange combinations as Austrian-Japanese can be noticed. Since the classifier is not very accurate by itself and our metric could additionally worsen the results, it is expected.
obtained using proposed metric1, does not show very good results, which can bee seen on the figure 3. Some pairings such as Latin American-Mexican, Asian-Vietnamese or Spanish-Italian are preserved, but mostly, strange combinations as Austrian-Japanese can be noticed. Since the classifier is not very accurate by itself and our metric could additionally worsen the results, it is expected.
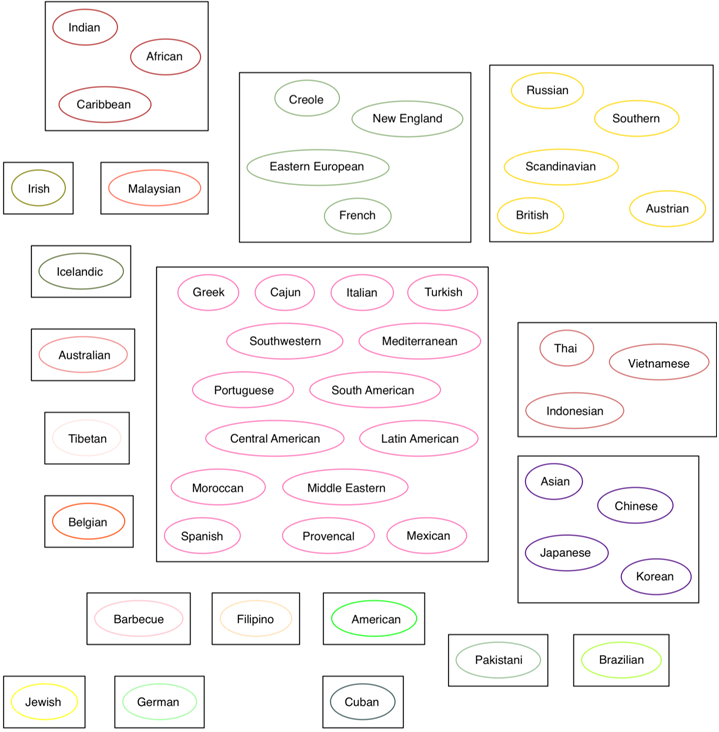
Fig. 1 – Cuisine clustering for SimRank, ![]()
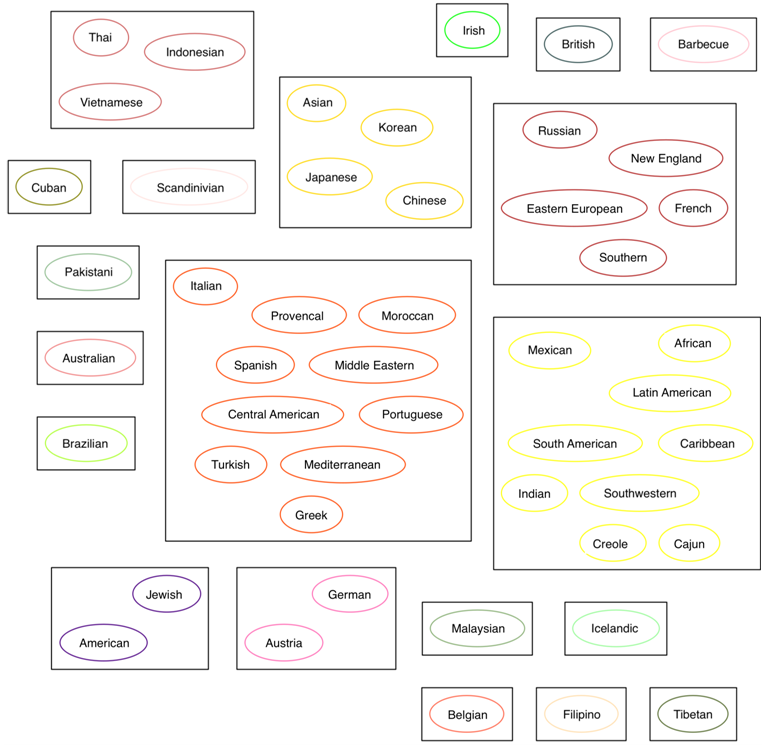
Fig. 2 – Cuisine clustering for SimRank, ![]()
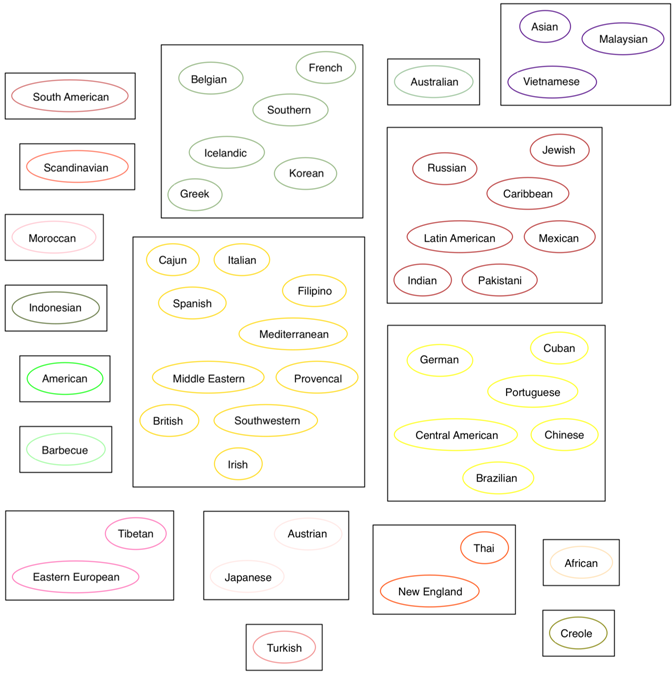
Fig. 3 – Cuisine clustering for NN, ![]()
Conclusion
In this paper we tried to find similarities between cuisines and compatibility between different ingredients given set of recipes using two statistical approaches. SimRank gave rather reasonable results of the cuisines clustering, whereas Neural Network classifier achieved at least 50% classification rate for -classification problem, giving some nice predictions for out-of-the-head sets of ingredients. Overall process showed us that it is not always possible to automate everything while solving particular data mining + machine learning problem and a lot of manual preprocessing and specific expertise may be need.
| Конфликт интересов Не указан. | Conflict of Interest None declared. |
Список литературы / References:
- Forbes P. Content-boosted matrix factorization for recommender systems: experiments with recipe recommendation / Forbes P., Zhu M. // Proceedings of the fifth ACM conference on Recommender systems. – ACM, 2011. – P. 261-264.
- Balabanović M. Fab: content-based, collaborative recommendation / Balabanović M., Shoham Y. // Communications of the ACM. – 1997. – Т. 40. – №. 3. – P. 66-72.
- Wan E. A. Neural network classification: A Bayesian interpretation // IEEE Transactions on Neural Networks. – 1990. – Т. 1. – №. 4. – P. 303-305.
- Jeh G. SimRank: a measure of structural-context similarity / Jeh G., Widom J. //Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. – ACM, 2002. – P. 538-543.
- New York Times, Cooking, URL: https://cooking.nytimes.com (accessed: 23.11.2017)
- Mitchell R. Web Scraping with Python: Collecting More Data from the Modern Web – "O'Reilly Media, Inc.", 2018.
- Hirose Y. Back-propagation algorithm which varies the number of hidden units / Hirose Y., Yamashita K., Hijiya S. // Neural Networks. – 1991. – Т. 4. – №. 1. – P. 61-66.
- Bouchard G. Efficient bounds for the softmax function, applications to inference in hybrid models. – 2007.
- Kurita T. An efficient agglomerative clustering algorithm using a heap // Pattern Recognition. – 1991. – Т. 24. – №. 3. – P. 205-209.
- Wilks D. S. Cluster analysis // International geophysics. – Academic press, 2011. – Т. 100. – С. 603-616.