УСКОРЕНИЕ РАБОТЫ МЕТОДА ВИОЛЫ-ДЖОНСА ДЛЯ РАСПОЗНАВАНИЯ ОБЪЕКТОВ НА ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЯХ

Шипицин С.П.1, Кавалеров М.В.2
1ORCID: 0000-0001-7370-4074, магистрант, Пермский национальный исследовательский политехнический университет; 2доцент, кандидат технических наук, Пермский национальный исследовательский политехнический университет
УСКОРЕНИЕ РАБОТЫ МЕТОДА ВИОЛЫ-ДЖОНСА ДЛЯ РАСПОЗНАВАНИЯ ОБЪЕКТОВ НА ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЯХ
Аннотация
Среди алгоритмов обнаружения объектов в изображениях наиболее популярным методом является метод Виолы-Джонса, реализованный в библиотеке OpenCV. Тем не менее, как и в других детекторах, основанных на принципе окна сканирования, количество требуемых вычислений увеличивается с размером обработанного изображения, что снижает эффективность системы распознавания в реальном времени, особенно в видеопоследовательности. В этой статье авторы предлагают простой подход - исключение некоторых областей кадра в зависимости от проработки предыдущих, чтобы увеличить скорость. Эффективность предлагаемого подхода была экспериментально подтверждена на методе Виолы-Джонса и увеличивается с увеличением общей точности системы.
Ключевые слова: распознавание образов, метод Виолы-Джонса, видеопоследовательность.
Shipitsin S.P.1, Kavalerov M.V.2
1ORCID: 0000-0001-7370-4074, Graduate student, Perm National Research Polytechnic University, 2Associate professor, PhD in Engineering, Perm National Research Polytechnic University
ACCELERATING THE OPERATION OF THE VIOLA-JONES METHOD FOR OBJECTS RECOGNITION IN VIDEO SEQUENCES
Abstract
Among the algorithms for object detection in images, the most popular is the Viola-Jones method implemented in the OpenCV library. However, as in other detectors based on the principle of scanning window, the number of required calculations increases with the size of the processed image, which reduces the efficiency of the real-time recognition system, especially in case of a video sequence. In this paper, the authors propose a simple approach – to exclude the certain areas of the frame, depending on the previous one, in order to increase the speed of processing. The effectiveness of the proposed approach was experimentally confirmed by the Viola-Jones method and increases with increasing of overall system accuracy.
Keywords: pattern recognition, Viola-Jones method, video sequence.
В современном мире всё более широкое применение находят системы распознавания образов, в частности, визуальных. Чрезвычайно высокая востребованность подобных систем обусловила необходимость как повышения качества распознавания с позиции уменьшения процента ошибок, так и минимизации требуемых вычислительных ресурсов. Предложенный в 2001 году метод Виолы-Джонса [1] благодаря своей относительно высокой точности и быстродействию завоевал популярность среди исследователей и разработчиков. В течение последних лет был предложен ряд алгоритмов, расширяющих возможности данного метода, однако, по мнению авторов, потенциал улучшения ещё не исчерпан. В соответствии с этим предположением была поставлена задача - разработать алгоритм, увеличивающий быстродействие распознавания образов методом Виолы-Джонса на видеопоследовательностях.
Как известно, работа оригинального метода базируется на принципе сканирующего окна: изображение сканируется окном поиска переменного масштаба, и к каждому положению окна применяется классификатор. Окно поиска перемещается по изображению с определённым шагом, и, чем этот шаг меньше, тем выше точность распознавания. Соответственно, чем выше разрешение исходного изображения, тем больше вычислений требуется произвести. Вместе с тем, повышение разрешения изображения выгодно, поскольку позволяет распознавать мелкие объекты.
Исследователи в своих работах предлагают различные способы ускорить алгоритм [2, C. 481-482]. Было предложено несколько аппаратных реализаций [3], [4], в том числе на ПЛИС [5], [6], но за счёт своей специфики такие решения требуют высоких единовременных затрат и являются недостаточно гибкими для адаптации к другим условиям эксплуатации. Реализации на GPU [7], [8], хоть и достаточно эффективны, влекут за собой высокие накладные расходы и не могут быть применены во встраиваемых системах. Метод, предложенный в работе [9], предполагает сканирование сцены в поисках регионов-кандидатов и в связи с этим имеет существенный недостаток – необходимо точно знать, сколько объектов находится на изображении. Метод визуального поиска, представленный в работе [10], даёт довольно существенное ускорение, однако применялся только к одиночным объектам, и неясно, как он будет работать на множественных. Адаптивное изменение шага движения сканирующего окна даёт ускорение до двух раз, но предназначен для относительно однородных изображений и на зашумлённых данных неэффективен. Большинство этих способов работают как со статическими изображениями, так и с видеопоследовательностями.
В рамках настоящей статьи авторы предлагают использовать для уменьшения объёма вычислений характерную особенность видеопоследовательностей – незначительные отличия соседних кадров. Так, например, если на некотором кадре последовательности классификатор распознаёт требуемый объект, в следующих кадрах этот объект не нужно распознавать повторно, достаточно только отслеживать его перемещения. Значит, область кадра, которую занимает этот объект, можно с некоторыми допущениями полностью исключить из обработки классификатором. Подобный подход позволит, с одной стороны, уменьшить объём вычислений, необходимых для обработки одного кадра, а с другой, сохранить точность распознавания, оставляя сам кадр в неизменном виде.
В общем виде алгоритм достаточно прост и выглядит следующим образом:
- Имеется исходное изображение, представленное в виде матрицы M×N (рис. 1);
- В зависимости от требований конкретного приложения формируется бинарная маска в виде матрицы того же размера (рис. 2), которая показывает, какие области изображения требуется обрабатывать, а какие - нет;
- В основном цикле классификатора проверяется условие нахождения ключевых точек сканирующего окна (рис. 3) внутри маски — если определённое их количество приходится на область, не подлежащую обработке, алгоритм сразу переходит к следующему шагу. В противном случае производится стандартная обработка классификатором.
- Распознанные на данном кадре объекты в совокупности с распознанными ранее и исключёнными из обработки формируют общий выходной вектор.

Рис. 1 – Исходное изображение

Рис. 2 – Условная маска после распознавания левого автомобиля
Рис. 3 – Варианты расположения ключевых точек сканирующего окна
В зависимости от величины и количества исключённых областей такой подход способен значительно снизить требуемое для полной обработки кадра количество вычислений. Следует, однако, учитывать, что при формировании маски неизбежно возникают накладные расходы, поэтому такой подход применим не во всех случаях, и для конкретного приложения может потребоваться дополнительное исследование эффективности. Так, например, представляется нецелесообразным формирование маски точно по контуру распознанного объекта в связи с большой сложностью; вместо этого, пожертвовав незначительной частью точности, можно просто использовать параметры сканирующего окна, в котором был распознан этот объект.
На основе описанного алгоритма была разработана экспериментальная модификация стандартной функции библиотеки OpenCV, подразумевающая использование простой бинарной маски обработки областей. Использовалась база изображений автомобилей Иллинойсского университета в Урбане-Шампейне.
В качестве основной использовалась следующая реализация: стандартный шаг сканирующего окна OpenCV, коэффициент масштабирования s=1,1, минимальный размер сканирующего окна 10×10 пикселей, размеры исходных изображений - 300×150, 600×300, 900×450 пикселей. Исследовалось только изменение скорости распознавания на простых масках, так как адекватность формирования маски и, соответственно, изменения эффективности распознавания сильно зависит от конкретного приложения.
Зависимости времени обработки от размеров изображения и относительной величины отбрасываемой области показаны на рис. 4. Здесь представлены четыре зависимости: время обработки изображения без каких-либо преобразований; время обработки с применением маски, занимающей четверть изображения; время обработки с применением маски, занимающей половину изображения; время обработки с применением маски, занимающей всё изображение целиком. Последняя зависимость является контрольной и показывает, насколько увеличиваются накладные расходы на работу с маской при использовании тестового кода, позволяя оценить его эффективность.
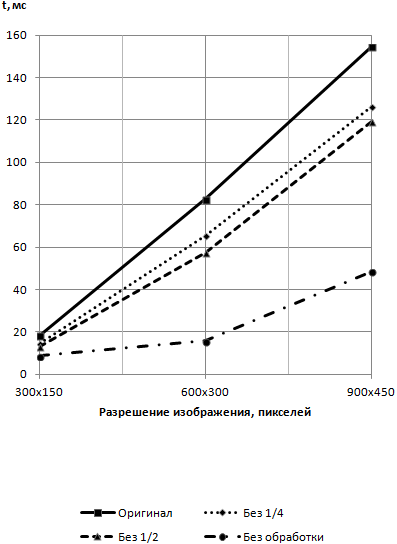
Рис. 4 – Зависимости времени обработки от размеров изображения и относительной величины отбрасываемой области
Как видно из представленного графика, время обработки действительно уменьшается при использовании предложенного подхода отбрасывания областей обработки. Между тем, уменьшение это достаточно незначительное; кроме того, различие времени обработки масок ½ и ¼ минимально, а контрольное время «холостой» работы классификатора растёт быстрее, чем время полной обработки. Совокупность этих факторов позволяет судить о том, что тестовый код недостаточно эффективен на фоне стандартного кода OpenCV и требует доработки для практического применения. Так, дополнительный выигрыш времени на разрешении 900×450 может составить 20 мс и больше, если довести зависимость времени обработки маски от размера изображения до линейной, как это удалось сделать для времени стандартной обработки изображения. Между тем, тестирование показало, что сам принцип вполне работоспособен, и чем больше размер исходного изображения, тем больший выигрыш в скорости можно получить.
Следует отметить, что использованные для эксперимента параметры (коэффициент масштабирования s=1,1, минимальный размер сканирующего окна 10×10 пикселей) подходят для распознавания достаточно крупных объектов, и относительный объём вычислений здесь невелик. Для распознавания объектов небольшого размера целесообразно уменьшать коэффициент масштабирования и минимальный размер сканирующего окна, но при уменьшении этих параметров до 1,05 и 5×5 соответственно время работы классификатора увеличивается примерно в четыре раза. В таких условиях применение предложенного подхода может уже очень существенно снизить время вычислений, если не в относительной, то в абсолютной величине.
В рамках настоящей работы был предложен простой алгоритм-расширение метода Виолы-Джонса на видеопоследовательности, с помощью которого можно значительно снизить количество вычислений, требуемых для обработки одного кадра. Посредством эксперимента показано снижение времени работы классификатора при использовании предложенного подхода.
Тем не менее, несмотря на преимущества, ограничения такого подхода очевидны и не позволят применять его повсеместно, однако в ряде приложений он может серьёзно повысить эффективность функционирования системы.
Список литературы / References
- Viola P., Jones M. Rapid object detection using a boosted cascade of simple features //Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. – IEEE, 2001. – V. 1. – P. I-I.
- Castrillón M. et al. A comparison of face and facial feature detectors based on the Viola–Jones general object detection framework //Machine Vision and Applications. – 2011. – V. 22. – №. 3. – P. 481-494.
- Cho J. et al. Parallelized architecture of multiple classifiers for face detection //Application-specific Systems, Architectures and Processors, 2009. ASAP 2009. 20th IEEE International Conference on. – IEEE, 2009. – P. 75-82.
- Hiromoto M., Sugano H., Miyamoto R. Partially parallel architecture for adaboost-based detection with haar-like features //IEEE Transactions on Circuits and Systems for Video Technology. – 2009. – V. 19. – №. 1. – P. 41-52.
- Brousseau B., Rose J. An energy-efficient, fast FPGA hardware architecture for OpenCV-compatible object detection // Field-Programmable Technology (FPT), 2012 International Conference on. – IEEE, 2012. – P. 166-173.
- Acasandrei L., Barriga A. FPGA implementation of an embedded face detection system based on LEON3 //Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV). – The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2012. – P. 1.
- Hefenbrock D. et al. Accelerating Viola-Jones face detection to FPGA-level using GPUs //Field-Programmable Custom Computing Machines (FCCM), 2010 18th IEEE Annual International Symposium on. – IEEE, 2010. – P. 11-18.
- Oro D. et al. Real-time GPU-based face detection in HD video sequences //Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on. – IEEE, 2011. – P. 530-537.
- Lampert C. H., Blaschko M. B., Hofmann T. Beyond sliding windows: Object localization by efficient subwindow search //Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. – IEEE, 2008. – P. 1-8.
- Butko N. J., Movellan J. R. Optimal scanning for faster object detection //Computer vision and pattern recognition, 2009. cvpr 2009. ieee conference on. – IEEE, 2009. – P. 2751-2758.