ИНФОРМАЦИОННАЯ ПОДДЕРЖКА УЧЕБНО-НАУЧНОЙ БАЗЫ ЗНАНИЙ ДЛЯ ПОДГОТОВКИ КАДРОВ В ОБЛАСТИ БИОТЕХНОЛОГИИ

Столбов Л. А.1, Корнюшко В. Ф.2, Николаева О. М.3
1Ассистент, аспирант кафедры ИСХТ МТУ, 2Доктор технических наук, профессор, академик МАН ИПТ, 3Аспирант кафедры ИСХТ МТУ
ИНФОРМАЦИОННАЯ ПОДДЕРЖКА УЧЕБНО-НАУЧНОЙ БАЗЫ ЗНАНИЙ ДЛЯ ПОДГОТОВКИ КАДРОВ В ОБЛАСТИ БИОТЕХНОЛОГИИ
Аннотация
В настоящее время разработано очень много баз данных и, основанных на них баз знаний, в различных областях знаний. Они могут представлять из себя хранилища, содержащие как статьи по различным тематикам, так и базы, содержащие свойства, характеристики и взаимосвязи в исследуемой области знания. На основе ассоциативного метода и методологии IDEF0 приведена методика построения моделей-прототипов для создания проблемно ориентированных баз знаний. Приведено формализованное иерархическое описание взаимосвязи процессов после получения первичной выборки статей до непосредственного обращения к системе поддержки принятия решения пользователем.
Ключевые слова: ассоциативный метод, проблемно ориентированные базы знаний, информационные модели.
Stolbov L. A.1, KornushkoV. F.2, Nikolaeva O. M.3
1Postgraduate MTU department of informational systems in chemical technology, 2PhD in Engineering, MTU head of department of informational systems in chemical technology, 3Postgraduate MTU department of informational systems in chemical technology
INFORMATION TECHNOLOGY IN A DESIGN OF SEMANTIC PROBLEM-ORIENTED DATABASES
Abstract
Currently various fields of knowledge databases are developed. They can contain articles on various topics and or properties, characteristics and relationships of the investigated field of knowledge. A feature of the construction of such knowledge bases is that a universal knowledge base and algorithms of their processing can be hosted in cloud servers. Construction of models-prototypes for the creation of problem-oriented knowledge bases on the basis of the associative method and the IDEF0 methodology the methodology is considered. A formalized hierarchical description of the relationship between processes after receiving the initial sample of articles to the decision support system appeal by the user is given.
Keywords: associative method, problem-oriented knowledge base, information models.
Введение
В последнее десятилетие возрастающий объем научной информации и технологии передачи информации активно изменяют образовательную среду и создают новые правила обработки научных данных, используемых в последующих работах. На данный момент существует огромное количество информации, посвященное различным областям знаний. Основная доля этой информации приходится на публикуемые статьи, хранящиеся в крупных базах данных таких (например, базы данных издательства Elsevier и тд). При возрастающем количестве статей и диверсификации областей применения тех или иных знаний, требуется все большее количество времени для отбора и систематизации требуемой информации. Таким образом, без комплекса автоматических средств обработки и систематизации данных не представляется возможным в полной мере овладеть предметной областью [1, 2].
Задача, такой систематизации данных после их получения и до обработки соответствующей системой поддержки принятия решения, формулируется следующим образом: При наличии ряда объектов, принадлежащих к предопределенному набору классов и обладающими предопределенным набором величин измерения этих объектов, идентифицировать или задать класс родства каждого из этих объектов с помощью подходящего анализа их величин измерения (признаков)[3].
Важной проблемой при создании информационной поддержки разрабатываемой проблемно ориентированной базы знаний является использование экспертов для обработки информации на отдельных этапах ее построения.
Ассоциативный метод
Метод поиска технических решений обосновываются на применении в творческом процессе семантических свойств понятий путем использования аналогий их вторичных смысловых оттенков. Основными источниками для генерирования новых идей служат ассоциации, метафоры и случайно выбраны понятия. На семантическом уровне лингвистическая информация характеризуется попарной сочетаемостью корневых основ.
Запоминание числа прохождений траекторией точек многомерного пространства, с последующим применением порогового преобразования, позволяет выявлять фрагменты траектории заданной частоты появления, которые составляют словари событий входной информации заданной частоты встречаемости ![]() . Для лингвистической информации это, например, словари флективных морфем, корневых основ, синтаксических групп. Выявленные таким образом лингвистические единицы в дальнейшем можно использовать для обработки текстовой информации. Словарь флективных морфем можно использовать для морфологического анализа, словарь корневых основ – для выявления ключевых понятий в тексте и формирования однородной (ассоциативной) семантической сети. Каждому члену последовательности n соответствует точка
. Для лингвистической информации это, например, словари флективных морфем, корневых основ, синтаксических групп. Выявленные таким образом лингвистические единицы в дальнейшем можно использовать для обработки текстовой информации. Словарь флективных морфем можно использовать для морфологического анализа, словарь корневых основ – для выявления ключевых понятий в тексте и формирования однородной (ассоциативной) семантической сети. Каждому члену последовательности n соответствует точка ![]() , с соответствующими координатами, а всей последовательности А, соответсвует последовательность точек Â , с траекторией
, с соответствующими координатами, а всей последовательности А, соответсвует последовательность точек Â , с траекторией
Где F – отображение в многомерное сигнальное пространство.
В общем случае среди n -членных фрагментов информационной последовательности может встретиться n -членный фрагмент последовательности:
И траектория в этом случае обратится к следующей вершине. В этой точке возможно более одного продолжения траектории. Для двоичной последовательности продолжений может быть не более двух.
Ассоциативность преобразования F позволяет сохранить топологию структуры преобразуемой информации. Действительно, одинаковые фрагменты последовательности преобразуются в одну и ту же траекторию, разные - в разные траектории[4].
При этом ассоциативная связь между двумя соединениями оценивается в зависимости от количества совпадений между соответствующими библиографическими списками.Попарные ассоциативные связи для каждой пары соединениймогут быть вычислены по формуле:
где m и n – количество статей в библиографических профилях одного и другого соединения[5].
Информационные модели экспертно-алгоритмической системы сбора и обработки данных
Для построения ВЭБ-программного комплекса семантического анализа и сжатия информации для построения проблемно-ориентированных баз знаний из универсальных использован метод информационного моделирования. При этом для построения функциональных информационных моделей использвана методология IDEF0. Как правило, моделирование средствами IDEF0 является первым этапом изучения любой системы[6].
В общем случае концептуальная модель построения проблемно-ориентированной базы данных из универсальной имеет вид: (Рис. 1):

Рис. 1 - Контекстная диаграмма А0 функциональной модели
Следующим этапом информационного моделирования системы является ее иерархическая декомпозиция.
Формирование исходных данных
Проблема информационного моделирования рассмотрена на конкретном примере построения проблемно-ориентированной базы данных в области биомедицины и медицинской химии. Необходимым условием для формирования исходных данных является наличие контролируемого словаря. Контролируемый словарь может содержать названия сущностей, относящихся к конкретной предметной области. Для рассматриваемого примера-это наименования различных белков или их субъединиц, генов, химических реакций, заболеваний и др. В случае создания базы данных биомедицины и медицинской химии в контролируемый словарь наиболее целесообразно использовать наименования химических соединений в виде номера CAS и/или названия по ИЮПАК, что возможно при загрузке из системы PubChem вместе с синонимичными вариантами [7]. На этапе формирования входных данных формируется и детализируется поисковый запрос, а также готовятся файлы, необходимые для дальнейшей загрузки.
Обработка входных данных
Обработка входных данных в случае размещение базы данных на стационарных машинах будет включать в себя следующие основные этапы: обогащение перечня терминов, создание целевой и фоновой выборки, создание и обработка промежуточной базы данных (Рис. 2).
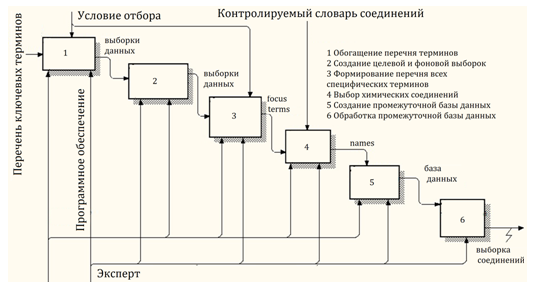
Рис. 2 - Декомпозиция «обработка входных данных»
При размещении базы данных в интернете или создании веб программного комплекса целесообразно на этом этапе подключить модули, характерные для системы поддержки принятия решения. В данном случае речь идет о N2S (name-to-structure) алгоритмы для представления соединений в форме графов и алгоритмы предсказания свойств соединений.
Для информационного наполнения базы данных используются библиографические сведения о свойствах и характеристиках химических соединений. На первой стадии проектирования базы данных используется семантическое моделирование. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования. Таким образом при данных условиях, для проблемно ориентированной базы знаний строится следующая диаграмма потоков данных (рис. 3), которая служит информационной основой построения реляционной проблемно-ориентированной базы данных по библиографическим ссылкам в области биомедицины и медицинской химии.
На следующем этапе проводится проверка качества построенной проблемно-ориентированной базы данных путем применения ее для решения задач анализа информации и задач прогнозирования. Для проверки качества полученных результатов могут быть использованы критерии качественной, феноменологической оценки решения или известные статистические методы [8-9].

Рис.3 - Диаграмма потоков данных
Выводы
- Рассмотрена методика семантического подхода к выборке библиографической информации из универсальных баз знаний. Для рационального использования всего объема данных по требуемой научной тематике целесообразно использовать проблемно – ориентированную базу данных.
- Показана возможность эффективного применения ВЭБ-программных алгоритмов для анализа и обработки данных.
- Разработан комплекс информационных моделей, позволяющий на основе применения ассоциативного метода и экспертно-алгоритмической системы сбора и обработки данных проводить реинтеграцию универсальных баз знаний для построения проблемно-ориентированных баз библиографической информации в области медицинской химии и биотехнологии.
Литература
- Угольникова О. А., Демич Ю. А., Лисица А. В., Кистанова В. Ю., Корнюшко В.Ф., Арчаков А.И., Швец В.И. Использование ассоциативного анализа для обработки научных публикаций в области систем доставки лекарств. // Вестник МИТХТ, 2010, т.V, № 2, с. 91-96.
- Mario Aldape-Pérez, Cornelio Yáñez-Márquez, Oscar Camacho-Nieto, Itzamá López-Yáñez, Amadeo-José Argüelles-CruzCollaborative learning based on associative models: Application to pattern classification in medical datasets//Computers in Human Behavior, 2014
- Duda, R. O., Hart, P. E., & Stork, D. G. Pattern classification (2nd ed.) // New York: Wiley (2001).
- Харламов А. А. Когнитивный подход к анализу текстов в технологии автоматического смыслового анализа текстов TEXTANALYST
- Rogers DJ, Tanimoto TT. A Computer Program for Classifying Plants //Science, 1960, 132, 1115-1118.
- Угольникова О. А. и соавт. Алгоритмический подход к группированию активных соединений с использованием ассоциативного библиометрического анализа // Алгоритмы, методы и системы обработки данных: сборник научных статей. 2009. Выпуск 14. с. 184-190.
- Маклаков С.В. Создание информационных систем с AllFusion Modeling Suite. // М.: “ДИАЛОГ-МИФИ”,2005. – 432 с.
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика - Database Systems: A Practical Approach to Design, Implementation, and Management Third Edition. // 3-е изд. — М.: «Вильямс», 2003. — С. 1436.
- Pedersen T.B., Jensen C.S., Dyreson C.E. A Foundation for Capturing and Querying Complex Multidimensional Data. // Information Systems. 2001. v. 26, № 5, p.45-55.
References
- Ugol'nikova O. A., Demich Ju. A., Lisica A. V., Kistanova V. Ju., Kornjushko V.F., Archakov A.I., Shvec V.I. Ispol'zovanie associativnogo analiza dlja obrabotki nauchnyh publikacij v oblasti sistem dostavki lekarstv. // Vestnik MITHT, 2010, t.V, № 2, s. 91-96.
- Mario Aldape-Pérez, Cornelio Yáñez-Márquez, Oscar Camacho-Nieto, Itzamá López-Yáñez, Amadeo-José Argüelles-CruzCollaborative learning based on associative models: Application to pattern classification in medical datasets//Computers in Human Behavior, 2014
- Duda, R. O., Hart, P. E., & Stork, D. G. Pattern classification (2nd ed.) // New York: Wiley (2001).
- Harlamov A. A. Kognitivnyj podhod k analizu tekstov v tehnologii avtomaticheskogo smyslovogo analiza tekstov TEXTANALYST
- Rogers DJ, Tanimoto TT. A Computer Program for Classifying Plants //Science, 1960, 132, 1115-1118.
- Ugol'nikova O. A. i soavt. Algoritmicheskij podhod k gruppirovaniju aktivnyh soedinenij s ispol'zovaniem associativnogo bibliometricheskogo analiza // Algoritmy, metody i sistemy obrabotki dannyh: sbornik nauchnyh statej. 2009. Vypusk 14. s. 184-190.
- Maklakov S.V. Sozdanie informacionnyh sistem s AllFusion Modeling Suite. // M.: “DIALOG-MIFI”,2005. – 432 s.
- Konnolli T., Begg K. Bazy dannyh. Proektirovanie, realizacija i soprovozhdenie. Teorija i praktika - Database Systems: A Practical Approach to Design, Implementation, and Management Third Edition. // 3-e izd. — M.: «Vil'jams», 2003. — S. 1436.
- Pedersen T.B., Jensen C.S., Dyreson C.E. A Foundation for Capturing and Querying Complex Multidimensional Data. // Information Systems. 2001. v. 26, № 5, p.45-55.