СОЗДАНИЕ МОДЕЛИ НА БАЗЕ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ, ПОЗВОЛЯЮЩЕЙ РАЗПОЗНАВАТЬ ПОЛ ЧЕЛОВЕКА ПО ГОЛОСУ
СОЗДАНИЕ МОДЕЛИ НА БАЗЕ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ, ПОЗВОЛЯЮЩЕЙ РАЗПОЗНАВАТЬ ПОЛ ЧЕЛОВЕКА ПО ГОЛОСУ
Аннотация
Искусственные нейронные сети (ИНС) широко применяются при создании информационных моделей для идентификации и классификации объектов, явлений и процессов. Наиболее простой топологией нейросети является сеть прямого распространения – перцептрон.
Описываемое исследование посвящено разработке методики для создания нейросети-перцептрона, позволяющей осуществить определение пола человека по характеристикам его голоса и её обучения на основе базы данных. При этом ставится цель разработки комплекса программ для оптимизации модели, с целью достижения наибольшей точностью распознавания. Для создания нейросетевой модели использованы средства и библиотеки языка программирования Python.
Разработанная методика создания и обучения ИНС апробирована при использовании конкретной базы статистических данных, содержащей характеристики голосов людей.
1. Introduction
The use of artificial neural networks to create models of processes and systems in the modern world is becoming more widespread due to their following advantages
:1. It is not necessary (although desirable) to comprehensively understand the mechanism of the investigated phenomenon;
2. There is no need to use cumbersome mathematical techniques in calculations;
3. Ease of mastering the methods of creating topologies of neural networks and the techniques of their machine learning;
4. Ease of use of ANN-based models, even by untrained users.
5. The use of ANN is simply indispensable when conducting new, innovative research, when it is not at all clear where to start developing a mathematical model and what methods to use
.Due to the above features, the use of neural networks in scientific research, in production, in the educational process and simply in everyday life (for obtaining, analyzing and creating information) is growing exponentially. Machine learning methods are taught everywhere, a lot of literature on this topic is published, numerous Internet resources are created and filled, new software is being developed (or special neuro-modules for the existing one).
For example, ANNs are very successfully used to solve classification and clustering problems (division into subclasses) of the collected statistical data
. The topology of a sequentially organized neural network (direct distribution network) in the form of a perceptron is well suited for this task, when the neurons of the network have inputs, and each neuron, after training the network model, acquires some weight (input signal gain) . The output signal from each neuron comes through synapse connections, usually to the inputs of other neurons.Thus, the perceptron topology is a certain input layer of neurons («sensors»), which receive the processed data, a set of intermediate layers of neurons (called hidden) and an output layer that gives the results to the experimenter
. The results can be presented in the form of numerical data, raster images, graphs – static, or dynamically changing during the processing of data entering the neural network.During intermediate processing of signals within the network (for example, perceptron), a number of mathematical functions are used, which play the role of some filters to improve the results of ANN functioning.
Development of optimal perceptron structure, which allows to obtain the most accurate information model of regularities, which the studied data array possesses, is a non-trivial task and depends on the organization and flow rate of data entering the ANN input. This problem is solved by multivariate study of perceptron topology, with its accompanying training and evaluation of results accuracy. For training and verification of results, two separate samples of data from the source array are used – training (training) and test (validation)
.Both samples should be representative, i.e. correctly reflect the essence of the investigated phenomenon or process. In addition, it has been proven that the larger the training sample, then, all other things being equal, a more accurate neural network model will be obtained.
Also, the accuracy of the model is significantly influenced by the choice of the number of hidden layers and neurons in each layer.
The purpose of the described study was to create a set of programs for working with ANN in the form of a perceptron with a variable topology, having one hidden layer. The perceptron should be optimized to obtain the most accurate results for identifying a person's gender based on the acoustic and statistical characteristics of their voice. The results of gender recognition can be used in solving a variety of applied tasks, for example, related to the creation of interfaces between artificial intelligence systems and humans, when voice filling electronic documents, when classifying target audience groups, etc.
The designed software package for the perceptron model optimization process solving the above optimization problems shall consist of the following functional parts:
1. Code that implements the process of reading data on voice characteristics from a statistical training sample and training a perceptron with a certain topology and varying the number of training eras (training iterations). Such a program will optimize the number of eras to obtain the maximum accuracy of the classification information model being created. After that, the optimal number of epochs is selected, the model is trained and written to a file for further use in the result prediction procedure.
2. A program for training the perceptron with varying the number of neurons in the intermediate hidden layer, which will make it possible to optimize the topology of the perceptron to maximize the accuracy of the model being created. After optimizing the number of learning eras and the topology of the perceptron, its final training is carried out, and the information computational model thus formed for identifying a person by voice is recorded in a file.
3. A program for applying a created computational model to a test sample of voice data in order to finally assess the accuracy of the obtained gender classification results.
2. Research methods and principles
Basis of the method of creation and training of ANN applied in work was very well-known Keras module (earlier TensorFlow module, which is a superstructure) intended for performance of functions of machine learning and built in many systems realizing such opportunities
. As examples of program simulators of complex systems, it is possible to call, for example, the Simulink complex for MatLAB or domestic SimInTech. Work, more «transparent» for the developer, with the Keras module is possible by means of application of programming languages of high level, – in particular, for performance of the described work the Python language is chosen. Work with neuronets usually requires also connection of libraries for import, convertings and processings of databases and also for a conclusion of graphic results for the further analysis .To train an artificial neural network, a database (dataset) was used, designed for voice analysis, imported from the Kaggle website
. This database was created specifically for the purpose of identifying a male or female voice, based on the acoustic features of speech. The data set consists of characteristics of 3168 recorded voice samples (samples) of people of different ages, including those characterized by various speech features (their nature is not specified), pre-processed by software acoustic analysis of wav sound files in the frequency range 0 Hz-280 Hz (human vocal range). The authors of the dataset applied batch processing of sound files by the method of statistical spectral analysis specan, implemented in the R programming language . The output of this method is 20 generalized characteristics presented in csv format. The last, 21st, characteristic is the gender of a person.Let's consider the list of characteristics presented in the dataset:
1. meanfreq – is average frequency (in kHz);
2. sd – is a standard deviation of frequency;
3. median – is median frequency (in kHz);
4. Q25 – is the first quantile (in kHz);
5. Q75 – is the third quantile (in kHz);
6. IQR - is interquantum range (in kHz);
7. skew – is a distortion (asymmetry measure);
8. kurt – is a measure of sharpness of peaks of a signal;
9. sp.ent – is spectral entropy;
10. sfm – is spectral planeness;
11. mode – is mode frequency (in kHz);
12. centroid – is frequency centrodes (in kHz);
13. meanfun – is average value of the main frequency measured on an acoustic signal (in kHz);
14. minfun – is the minimum main frequency measured on an acoustic signal (in kHz);
15. maxfun – is the maximum main frequency measured on an acoustic signal (in kHz);
16. meandom – is the average value of the dominating frequency measured on an acoustic signal (in kHz);
17. mindom – is a minimum of the dominating frequency measured on all acoustic signal (in kHz);
18. maxdom – is a maximum of the dominating frequency measured on all acoustic signal (in kHz);
19. dfrange – is the range of the dominating frequency measured on all acoustic signal (in kHz);
20. modindx – is the index of modulation. Pays off as the saved-up absolute difference between the next measurements of the main frequencies, divided into frequency range;
21. label – is a tag: male or female voice.
This database was broken into two samples: the training, containing 3164 records (lines) with characteristics of voices, and the test, containing 4 lines (two first and two last lines of initial base – this rule is chosen randomly), 2 of which correspond to a tag of a male voice and 2 – a tag women's. For quantitative assessment of accuracy of recognition of a floor, the tag of «male» (men's) was replaced with 0, and the tag of «female» (women's) – on 1, i.e. was made normalization of recognizable parameter. Thus, the greatest approach of the forecast to 0 means the best identification of a male voice and vice versa.
As an integrated development environment (IDE) for Python the Pycharm program very convenient both for writing of the code of the application, and for connection of additional libraries of functions and also for debugging of programs and a conclusion of results of researches in a graphic look was used
. The course of implementation of the application program for training of neural network model is displayed step by step in the IDE Pycharm console.The code of the program performing functions of import of data from training sample and training of a perceptron with the set number of neurons of the hidden layer, but with variation of amount of the training eras consists of the following structural elements:
1. Block of connection of external modules: Keras described above which will be used for the choice of the ANN model (so-called network of direct distribution), creation of layers of neurons, the graphic evident image of topology of model. For a conclusion of characteristics of work of neural network model in a graphic look it is also necessary to connect the Matplotlib module, and for processing of the database one more Numpy module is used
.2. Import and transformation to a matrix form of the initial training database, the last a column of which (identifier of a gender of the person) is the output parameter of model (target variable), and the first 20 columns, contain the input parameters which are statistical characteristics of voices of individuals.
3. The matrix of the described training parameters is divided into an entrance matrix from 20 columns and an output matrix from one column.
4. Implementation of the Sequental() function from the Keras module to build an ANN – direct distribution (perceptron), to which then using the add function, layers of the Dense type are added: input, intermediate (hidden) and output. For each layer, an activation function is set: for the first two layers of the ReLU type (Rectified Linear Unit), and for the output layer – sigmoid (used to determine the probability of an event in gradations from 0 to 1).
5. Special modules for Graphviz and Pydot network topology output are connected, with which a conditional image of the ANN is recording to the file.
6. The created ANN model is compiled using the Compile() function with the selected binary crossentropy loss function used for binary classification (0 or 1)
, as in this case. The method of optimizing the Adam model (considered at the moment one of the most effective) is also chosen.7. Training of built ANN model on training sample with specified number of cycles (epochs) or iterations of training. This quantity will be optimized using the second created program study input. After completing each era of training, the quality of training is evaluated using the algorithm built into the Keras module and recorded in a special array.
8. After the end of the training process, using the functions of the Matplotlib module, a graph is plotted between the accuracy of training the model and the number of eras. Since this process is necessary to optimize the specified value of epochs, the coordinates of the point characterized by the highest accuracy of model training are plotted on the graph.
At the next stage, the algorithm of the above program was changed as follows: at a certain given value of the number of epochs in the cycle, the number of neurons of the hidden layer changes. This is done in order to optimize a given number of neurons, at which the maximum accuracy of learning the model is achieved. During iterations of the cycle, these two characteristics are written into arrays, according to which, using the commands of the Matplotlib module, a graphical dependence of learning accuracy on the number of neurons of the hidden layer is plotted, on which a point is marked with coordinates corresponding to the optimal value of the number of neurons.
The third version of the program uses the same algorithm for creating and training a model at the identified optimal values of the number of neurons of the hidden layer and learning eras. The information model created in this way is written to a Keras file.
A separate part of the described set of programs is a code for testing the accuracy of identifying the gender of a person from the initial data, which is 20 characteristics of votes. This code uses the previously created Keras model. The algorithm for recognizing a person's gender by voice consists of the following blocks:
1. Connection of Keras and Numpy modules.
2. Load the generated Keras model using the load_model() function.
2. Import a previously created test file with voice characteristics and extract input parameters from it.
3. Identification of the sex of individuals using input parameters used in the model.predict function and thus obtaining an array of output parameters. Output results to the program console.
In order to finally assess the accuracy of the generated Keras model, the results obtained in the execution of this program for determining the sex of individuals are compared with the sex labels contained in the test sample.
3. Main results
Let us consider the results of using the above software package to create and use an information model for determining a person's sex by the characteristics of his voice. The structure of the database used for this and the principle of its division into training and test samples are described in the previous section.
According to the number of voice characteristics, which are input parameters of the model, equal to 20, the number of neurons of the ANN input layer is also selected equal to 20. Using the second program from the developed software complex with a change in the number of neurons of the hidden layer in the cycle, this number is taken equal to 20 (then we will prove that this value is sufficient). The output layer of the ANN consists of only one neuron, because the output parameter is set to a binary value - the gender of the person, which can be 0 (man) or 1 (woman).
For the described network, the first program created displays a graphical image of the topology shown in Figure 1.
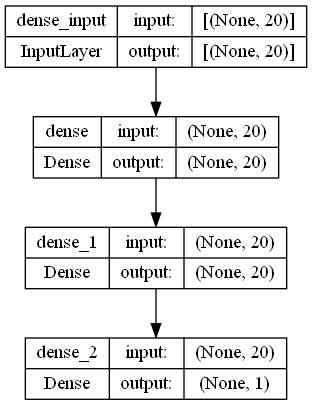
Figure 1 - Topology of created ANN
At the first stage, with a given number of neurons of the hidden layer equal to 20, using the first program, the quality of the created model is plotted as a percentage of the number of learning epochs. This relationship is shown in Figure 2.
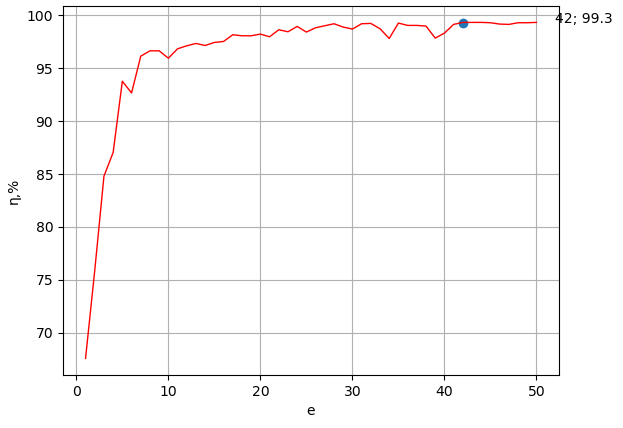
Figure 2 - Impact of number of learning eras on ANN learning quality
The graphical dependence displayed by the second program is shown in Figure 3.
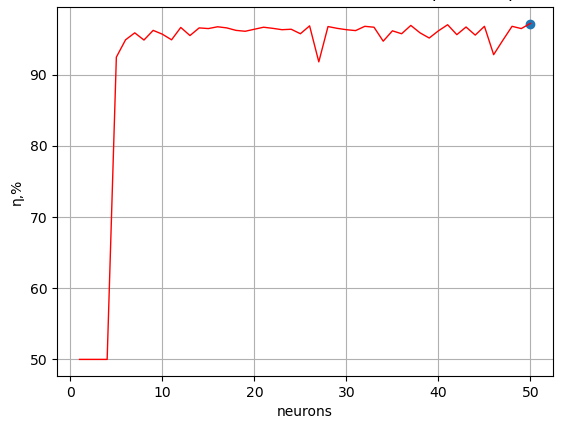
Figure 3 - Influence of the number of hidden layer neurons on the quality of ANN training
4. Discussion
From the Figure 3, we can conclude that with an increase in the number of neurons of the hidden layer above n=20, the quality of learning the model practically does not change, therefore this value was taken further as a constant. In addition, at values of n close to 20, the quality of training practically does not change (it is the most stable).
The next step is to create an information model in the form of a Keras file with the identified values e=42 and n=20. After that, this Keras model is used to determine the gender of people by voice characteristics from a test sample using the last program created.
Recall that the test sample contains data on 4 people - 2 men and 2 women. The theoretical values of the floor labels for them should be an array [0,0,1,1].
As a result of the classification program according to the created model, the following array of values was output:
[[0.17256354]
[0.02689704]
[0.9710675]
[0.87886876]].
The result proves the high quality of the information model created using the ANN – the values given in the first two cases of diagnostics are close to 0, and in the last two cases – to 1 and deviate greatly from the average possible value (uncertain result) equal to 0.5. Therefore, it can be stated that this model can be successfully used to determine the gender of a person by his statistical voice characteristics.
5. Conclusion
Thus, a number of important tasks are solved in the presented work:
1. The expediency and relevance of the use of ANN in science and technology is justified, in particular for solving the problem of identifying a person's gender by voice.
2. Algorithm of ANN topology optimization was created to solve the above problem.
3. Python programs have been written using the Keras machine learning module and other plug-in libraries to implement the created algorithm.
4. A procedure has been developed for the preliminary preparation of a database for training and testing the Keras model.
5. The procedure for using written programs has been tested.
As a result, it can be stated that the goal of the described research work has been achieved. The created methodology for training and optimization of ANN is recommended for use to solve the problems of identification and classification of processes and phenomena.
In practice, the recognition of a person's gender by voice can be applied in the systems of providing telephone services, tourism and hotel business, in the technical means of automatic information and reference services and access to information personalized for customers of different genders. Keras models created using the created software package can be integrated into existing systems of the specified purpose. Such integration in most cases should not be a big problem, because at present keras models, as noted above, are used everywhere.
Since the described work carried out a qualitative check of the accuracy of determining the gender of a person by the characteristics of his voice for only four people randomly selected from the sample, at the next stage of research it is planned to carry out a quantitatively substantiated assessment of the accuracy of the identification model, as well as when varying its parameters and topology. To do this, in the created software package, the model testing program must be supplemented with functions for assessing the ratio of the number of accurate forecasts to the total number of processed samples. In the course of this work, according to the generally accepted tradition of database processing in machine learning, 70% of the dataset should be allocated to the training sample, and 30% to the verification sample. The obtained forecast accuracy can be compared with the used systems for recognizing a person's gender by voice, the most advanced of which have an accuracy of slightly more than 90%. One such method is to use the Gaussian mixture model (GMM). It should be borne in mind that, since a person's voice can change depending on age, emotional state, health, hormonal background and a number of other factors, it fundamentally cannot be absolutely accurate.
Since the limitation of the accuracy of the considered model is the use of a simple direct propagation network – perceptron, in the future, using the developed software complex, it is necessary to study other types of artificial neural networks. That is, this problem is a very promising direction in the development of machine learning technologies.