ИССЛЕДОВАНИЕ И АНАЛИЗ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПРОГНОЗИРОВАНИЯ ОТТОКА КЛИЕНТОВ В ТЕЛЕКОММУНИКАЦИОННОЙ КОМПАНИИ

ИССЛЕДОВАНИЕ И АНАЛИЗ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПРОГНОЗИРОВАНИЯ ОТТОКА КЛИЕНТОВ В ТЕЛЕКОММУНИКАЦИОННОЙ КОМПАНИИ
Научная статья
Камалходжаева Н.1 , Шиков А.Н.2, *
2 ORCID: 0000-0002-9942-0907;
1–2 Университет ИТМО, Санкт-Петербург, Россия
* Корреспондирующий автор (shik-off[at]mail.ru)
Аннотация
Отток клиентов является серьезной проблемой, которая оказывает влияние на бизнес, основанный на взаимоотношении с клиентами, в том числе на высоко конкурентный и быстро растущий телекоммуникационный сектор. Эта область является предметом повышенного интереса как со стороны сотрудников-аналитиков компаний, так и со стороны представителей практикующих специалистов, заинтересованных в прогнозировании поведения клиентов с целью выявления оттока клиентов. Актуальность исследования определяется необходимостью телекоммуникационных компаний в удержании существующих клиентов в сочетании с высокими затратами на приобретение новых. Анализ показал нехватку эффективных подходов к прогнозированию оттока клиентов в телекоммуникационном секторе. В представленном исследовании предлагается оптимальное решение для прогнозирования оттока клиентов в телекоммуникационном секторе, путем сравнения наиболее подходящих для построения прогнозов современных методов машинного обучения. Для оценки эффективности предложенных методов применяются метрики качества: точность, auc, precision, recall и f1-score.
Ключевые слова: отток клиентов, телекоммуникационная компания, машинное обучение, модели прогнозирования, метрики качества.
RESEARCH AND ANALYSIS OF MACHINE LEARNING ALGORITHMS FOR PREDICTING CUSTOMER CHURN IN A TELECOMMUNICATIONS COMPANY
Research article
Kamalkhodzhaeva N.1 , Shikov A.N.2, *
2 ORCID: 0000-0002-9942-0907;
1–2 ITMO University, Saint Petersburg, Russia
* Corresponding author (shik-off[at]mail.ru)
Abstract
Customer churn is a serious problem that has an impact on business based on customer relations, including the highly competitive and rapidly growing telecommunications sector. This sphere is the subject of increased interest both on the part of employees-analysts of companies, and on the part of practitioners' representatives interested in predicting customer behavior in order to identify customer churn. The relevance of the study is due to the need of telecommunications companies to retain existing customers, as well as high costs of acquiring new ones. The analysis showed a lack of effective approaches to forecasting customer churn in the telecommunications sector. The presented study suggests an optimal solution for predicting customer churn in the telecommunications sector by comparing the most suitable modern machine learning methods for making forecasts. To evaluate the effectiveness of the proposed methods, quality metrics are used: accuracy, auc, precision, recall and f1-score.
Keywords: customer churn, telecommunications company, machine learning, forecasting models, quality metrics.
Введение
Телекоммуникационный сектор является одной из самых ведущих отраслей, приносящих доход, и жизненно важным источником социально-экономического роста для многих стран мира. Отток клиентов–одна из наиболее актуальных проблем современного и конкурентного телекоммуникационного сектора [1]. Поставщики услуг стали уделять больше внимания удержанию существующих клиентов, а не приобретению новых из-за связанных с этим высоких затрат [2].
Удержание существующих клиентов также приводит к повышению продаж и снижению затрат на маркетинг по сравнению с новыми клиентами. Эти факты привели к тому, что деятельность по прогнозированию оттока клиентов стала неотъемлемой частью процесса принятия стратегических решений и планирования в телекоммуникационном секторе.
Чтобы справиться с растущей проблемой оттока клиентов, данные, хранящиеся в базах данных компаний, можно преобразовать в полезную информацию, которая поможет распознать поведение оттока до того, как клиенты решат покинуть компанию; таким образом, повышается устойчивость клиентов [3].
Прогнозирование оттока было широко изучено в последнее десятилетие, особенно в следующих областях: банковский сектор, поставщики финансовых услуг, индустрия онлайн-игр, отдел кадров конкурентных организаций, рынок подписных услуг, страховые компании. Из приведенного анализа становится ясно, что отток клиентов, для различных организаций, является актуальной проблемой и имеет огромное значение для бизнеса. В то же время, прогнозирование оттока клиентов все чаще наблюдается и в телекоммуникационной отрасли по всему миру. В исследовании [4], представлен краткий обзор предыдущих исследований прогнозирования оттока клиентов в телекоммуникационной отрасли.
Методы и принципы исследования
Основная цель исследования – исследовать эффективность алгоритмов, применяемых для прогнозирования оттока клиентов и 11 основных моделей прогнозирования с целью выявления наиболее точного. На рисунке 1 представлена схема предлагаемого исследования оттока клиентов.
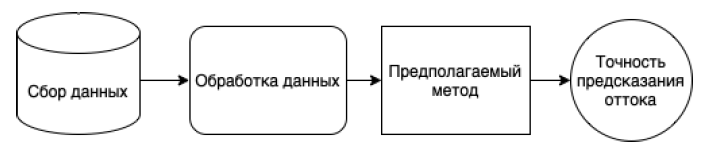
Рис. 1 – Порядок исследования оттока абонентов
Исследования проводились с использованием языка программирования Python, в облачной среде для работы с кодом Google Colab. Для работы с данными была использована библиотека pandas, для визуализации и анализа данных библиотеки matplotlib и seaborn, для предобработки данных, а также для обучения и тестирования алгоритмов применялась библиотека sklearn.
Набор данных в нашем датасете содержит 7043 записи о клиентов телекоммуникационной компании. Данные содержат демографическую информацию о клиентах, их подключенные услуги и платежи.
В ходе предварительной обработки данных были обнаружены пропуски в 11 данных, которые, в последствии были удалены, так же все категориальные столбцы были преобразованы в числовые с помощью метода one-hot-encoding.
Данные были разбиты на обучающие и тренировочные в соотношении 80/20 и обучены на 11 алгоритмах машинного обучения, наиболее подходящих для прогнозирования, выявленных в ходе анализа предметной области. Таким образом, были выбраны следующие модели: логистическая регрессия (Logistic Regression), метод опорных векторов (SVM), случайные леса (Random Forest), метод kNN, дерево решений (Decision Tree), наивный байесовский классификатор (Naïve Bayes Classifier), AdaBoost, нейронная сеть (Neural Network), градиентный бустинг (Gradient Boosting Classifier), XGBoost, ExtraTreesClassifier.
В ходе анализа, было обнаружено, что в данных присутствует дисбаланс данных, что приводит к неверной оценке алгоритмов прогнозирования. Дисбаланс классов в тренировочных данных значительный. На рисунке 2 представлены значения оттока в исследуемом датасете: метка 1–представляющая отток, содержит 1 869 записей, в то время как метка 0–означающая "не отток", содержит 5 163 записи. Модели должны учитывать это. Для устранения дисбаланса в обучающих данных можно применить технику недостаточной выборки.
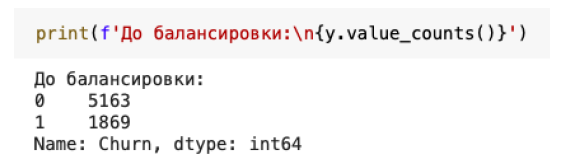
Рис. 2 – Соотношение оттока и не оттока в данных
В таблице 1 представлены результаты (метрики качества) обученных и протестированных моделей для предсказания оттока клиентов до применения техники балансировки данных.
Таблица 1 – Метрики качества исследованных моделей (до балансировки)
|
Метод |
accuracy, % |
auc |
precision |
recall |
F1-score |
|
Логистическая регрессия |
79,6 |
0,707 |
0,75 |
0,71 |
0,72 |
|
Метод опорных векторов |
80,1 |
0,705 |
0,76 |
0,71 |
0,72 |
|
Случайные леса |
79,18 |
0,682 |
0,73 |
0,68 |
0,70 |
|
Метод k-ближайших соседей |
77,26 |
0,697 |
0,71 |
0,70 |
0,70 |
|
Дерево решений |
71,79 |
0,651 |
0,65 |
0,65 |
0,65 |
|
Наивный Байесовский классификатор |
74,84 |
0,752 |
0,71 |
0,75 |
0,72 |
|
AdaBoost |
79,18 |
0,694 |
0,74 |
0,71 |
0,72 |
|
Искусственная нейронная сеть |
79,1 |
0,709 |
0,74 |
0,71 |
0,72 |
|
Градиентный Бустинг |
79,96 |
0,706 |
0,75 |
0,71 |
0,72 |
|
XGBoost |
80,6 |
0,714 |
0,76 |
0,71 |
0,73 |
|
ExtraTreesClassifier |
77,33 |
0,674 |
0,71 |
0,67 |
0,69 |
С целью повысить качество предсказания алгоритмов и решения проблемы дисбаланса, была применена техника SMOTE, в результате чего удалось нейтрализовать дисбаланс данных и повысить точность моделей [5].

Рис. 3 – Применение техники SMOTE к данным
На рисунке 4 представлены значения оттока и не оттока в данных после балансировки.

Рис. 4 – Соотношение оттока и не оттока в данных после балансировки данных техникой SMOTE
В таблице 2 представлены результаты обученных и протестированных моделей после применения техники балансировки данных.
Таблица 2 – Метрики качества исследованных моделей (после балансировки)
|
Метод |
accuracy, % |
auc |
precision |
recall |
f-score |
|
Логистическая регрессия |
80,78 |
0,808 |
0,81 |
0,81 |
0,81 |
|
Метод опорных векторов |
80,78 |
0, 808 |
0,81 |
0,81 |
0,81 |
|
Случайные леса |
83,69 |
0,84 |
0,84 |
0,84 |
0,84 |
|
Метод k-ближайших соседей |
79,14 |
0,792 |
0,79 |
0,79 |
0,79 |
|
Дерево решений |
81,22 |
0,812 |
0,81 |
0,81 |
0,81 |
|
Наивный Байесовский классификатор |
77,3 |
0,774 |
0,77 |
0,77 |
0,77 |
|
AdaBoost |
82,04 |
0,82 |
0,82 |
0,82 |
0,82 |
|
Искусственная нейронная сеть |
82,38 |
0,823 |
0,83 |
0,82 |
0,82 |
|
Градиентный Бустинг |
83,45 |
0,835 |
0,83 |
0,83 |
0,83 |
|
XGBoost |
83,3 |
0,833 |
0,83 |
0,83 |
0,83 |
|
ExtraTreesClassifier |
83,25 |
0,832 |
0,83 |
0,83 |
0,83 |
Сравнение современных алгоритмов прогнозирования до и после балансировки данных приведено в таблице 3.
Таблица 3 – Сравнение современных алгоритмов прогнозирования до и после балансировки
|
Метод |
До балансировки, % |
После балансировки, % |
|
Логистическая регрессия |
79,6 |
80,78 |
|
Метод опорных векторов |
80,1 |
80,78 |
|
Случайные леса |
79,18 |
83,69 |
|
Метод k-ближайших соседей |
77,26 |
79,14 |
|
Дерево решений |
71,79 |
81,22 |
|
Наивный Байесовский классификатор |
74,84 |
77,3 |
|
AdaBoost |
79,18 |
82,04 |
|
Искусственная нейронная сеть |
79,1 |
82,38 |
|
Градиентный Бустинг |
79,96 |
83,45 |
|
XGBoost |
80,6 |
83,3 |
|
ExtraTreesClassifier |
77,33 |
83,25 |
В результате проведения экспериментов до балансировки данных, наилучшие результаты показала модель XGBoost с точностью предсказания 80.6%. XGBoost является моделью медленного обучения, основанная на концепции бустинга.
В результате исследования, наиболее эффективными моделями являются алгоритм случайного леса (RandomForest: 83.69%), градиентный бустинг (GradientBoostingClassifier: 83.45%) и XGBoost (XGB: 83.3%). Алгоритмы ExtraTreesClassifier и Neural Network показали хорошие результаты: 83.25% и 82.38%. Алгоритм AdaBoost показал средние результаты: 82.04%. Различия между показателями AUC и точности в среднем не столь значительны. Алгоритм дерева решений (Decision Tree) превосходит по производительности логистическую регрессию и метод опорных векторов на на 0.44%. Метод опорных вектором (SVM) и логистическая регрессия (LR) показали одинаково средний результат: 80.78%. Метод k-ближайших соседей (KNN) не так часто встречается в литературе и не показывает столь высоких результатов: 79.14%. Наивный байесовский классификатор показал самый низкий результат–77.3% из всех протестированных алгоритмов.
Актуальность темы и во многом результаты настоящего исследования коррелируют с опубликованными материалами других ученых по вопросам прогнозирования оттока клиентов [6], [8], [9], [10].
Согласно результатам данного исследования, наиболее подходящим методом, который можно было бы предложить, является алгоритм случайного леса и градиентный бустинг. Из протестированных моделей XGBoost показал наилучшие результаты на несбалансированных наборах данных и после балансировки данных.
Заключение
Отток–неизбежная проблема в телекоммуникационной отрасли. В любом случае, как бы это ни было проблематично, распознать причины оттока абонентов можно с помощью нескольких методик. Прогнозирование играет важную роль в определении оттока клиентов. В данной исследовательской работе для телекоммуникационных компаний были предложены 11 моделей прогнозирования оттока клиентов с целью выявления наиболее оптимального и более точного алгоритма.
Для оценки результатов предложенного подхода применяется сравнительное исследование и метрики качества: точность, auc, precision, recall и f1-score. Поскольку набор данных был несбалансированным и отток составлял 27% среди клиентов, была применена техника SMOTE для балансировки данных, с целью повышения точности предсказаний алгоритмов. По результатам исследования был проведен сравнительный анализ полученных результатов.
Представленное исследование относится к конкретному набору данных, использованному для данного исследования и результаты могут отличаться от результатов использования других наборов данных.
|
Конфликт интересов Не указан. |
Conflict of Interest None declared. |
Список литературы
HaddenJ. Computer assisted customer churn management: state-of-the-art and future trends/J. Hadden, A. Tiwari, R.Royet al. // Comput. Oper. Res.–2007. –No34(10). –P.2902–2917.
Amin AA prudent based approach for customer churnprediction/ A. Amin, R.Faisal, R. Muhammad et al. //11th International Conference, BDAS 2015, Ustro ́n, Poland. –2015. –P.320–332.
Пономарёв А.А. Варианты использования больших данных в телекоммуникационном бизнесе/ А.А.Пономарёв.–2015.
Камалходжаева Н.Анализ применения алгоритмов машинного обучения для прогнозирования оттока клиентов в телекоммуникационных компаниях /Н. Камалходжаева, А.Н. Шиков//Сборник статей XXIIМеждународнойнаучно-практической конференции «Современные научные исследования: Актуальные вопросы, достижения и инновации» г.Пенза 10 декабря 2021 года. в 2 частях Ч. 1. –Пенза: МЦНС «Наука и Просвещение». –2021.–С. 138–142.
Мальчиц В.С.Обработка данных для машинного обучения и применение метода опорных векторов для реализации классификатора новостей / В.С. Мальчиц, А.Н. Гетман// Вестник Амурского государственного университета. Серия: Естественные и экономические науки.–2019. –No87. –С. 8–13.
Грищенко Д.А. Анализ методов моделирования и прогнозирования оттока клиентов/ Д.А. Грищенко, А.В.Катаев// Вестник науки и образования.–2018.–No5(41).–С.21–23.
Ланкевич К.Ossкомплекс как инструмент контроля лояльности клиентов оператора связи/ К. Ланкевич, Н.Хабаев, М. Скоринов// T-Comm. –2016.–No5.–С. 36–40.
Мхитарян С.В.Управление оттоком клиентов в условиях цифровой экономики/ С.В. Мхитарян, Т.А. Тультаев, И.В. Тультаеваи др. // КЭ.–2018.–No10.–С.1661–1672.
Пономарёв А.А. Варианты использования больших данных в телекоммуникационном бизнесе / А.А. Пономарёв// Компьютерные инструменты в образовании. –2015.–С. 3–8.
Токанов О.С. Bigdataв телекоммуникационном бизнесе/ О.С. Токанов// Наука и образование сегодня.–2018.–No7 (30).–С.25–28.
Список литературы
HaddenJ. Computer assisted customer churn management: state-of-the-art and future trends/J. Hadden, A. Tiwari, R.Royet al. // Comput. Oper. Res.–2007. –No34(10). –P.2902–2917.
Amin AA prudent based approach for customer churnprediction/ A. Amin, R.Faisal, R. Muhammad et al. //11th International Conference, BDAS 2015, Ustro ́n, Poland. –2015. –P.320–332.
Пономарёв А.А. Варианты использования больших данных в телекоммуникационном бизнесе/ А.А.Пономарёв.–2015.
Камалходжаева Н.Анализ применения алгоритмов машинного обучения для прогнозирования оттока клиентов в телекоммуникационных компаниях /Н. Камалходжаева, А.Н. Шиков//Сборник статей XXIIМеждународнойнаучно-практической конференции «Современные научные исследования: Актуальные вопросы, достижения и инновации» г.Пенза 10 декабря 2021 года. в 2 частях Ч. 1. –Пенза: МЦНС «Наука и Просвещение». –2021.–С. 138–142.
Мальчиц В.С.Обработка данных для машинного обучения и применение метода опорных векторов для реализации классификатора новостей / В.С. Мальчиц, А.Н. Гетман// Вестник Амурского государственного университета. Серия: Естественные и экономические науки.–2019. –No87. –С. 8–13.
Грищенко Д.А. Анализ методов моделирования и прогнозирования оттока клиентов/ Д.А. Грищенко, А.В.Катаев// Вестник науки и образования.–2018.–No5(41).–С.21–23.
Ланкевич К.Ossкомплекс как инструмент контроля лояльности клиентов оператора связи/ К. Ланкевич, Н.Хабаев, М. Скоринов// T-Comm. –2016.–No5.–С. 36–40.
Мхитарян С.В.Управление оттоком клиентов в условиях цифровой экономики/ С.В. Мхитарян, Т.А. Тультаев, И.В. Тультаеваи др. // КЭ.–2018.–No10.–С.1661–1672.
Пономарёв А.А. Варианты использования больших данных в телекоммуникационном бизнесе / А.А. Пономарёв// Компьютерные инструменты в образовании. –2015.–С. 3–8.
Токанов О.С. Bigdataв телекоммуникационном бизнесе/ О.С. Токанов// Наука и образование сегодня.–2018.–No7 (30).–С.25–28.