Фактологическая достоверность цитатно-осведомленной генерации научных саммари и обзорных текстов: проблемы, методы повышения качества и направления развития
Фактологическая достоверность цитатно-осведомленной генерации научных саммари и обзорных текстов: проблемы, методы повышения качества и направления развития

Аннотация
В статье рассматриваются современные подходы к цитатно-осведомленной обработке научных публикаций и генерации научных саммари и обзорных текстов. Актуальность работы обусловлена ростом объема научной информации, усложнением структуры научного цитирования и активным развитием больших языковых моделей, применяемых для автоматизированной обработки научной литературы. Рассмотрены основные направления развития цитатно-осведомленной суммаризации. Особое внимание уделено проблеме фактологической достоверности автоматически формируемых научных текстов. Проанализированы ограничения современных цитатно-осведомленных систем, связанные с неточностью цитатных данных, ошибками интерпретации публикаций, генерацией неподтвержденных утверждений и галлюцинациями больших языковых моделей. Рассмотрены существующие методы повышения качества генерации и оценки фактологической согласованности научных текстов. Показано, что современные подходы преимущественно ориентированы на отдельные этапы обработки научной информации и не обеспечивают комплексного контроля достоверности цитатно-осведомленной генерации. Сделан вывод о необходимости разработки методов, включающих проверку соответствия цитат содержанию первоисточника и контроль фактологической корректности генерируемых научных текстов.
1. Введение
В последние годы наблюдается устойчивый рост объема научной информации, сопровождающийся усложнением структуры научной коммуникации и увеличением числа взаимосвязей между публикациями. Показано, что развитие современной науки характеризуется долговременным экспоненциальным ростом количества публикаций и цитирований . Исследование , посвященное анализу динамики публикационной активности в Scopus и Web of Science, демонстрирует, что только за период 2016–2022 гг. число индексируемых научных публикаций увеличилось приблизительно на 47%. Обзоры дополнительно отмечают эффект «инфляции цитирования», связанный с увеличением объема библиографических списков и изменением практик научного цитирования.
В этих условиях активно развиваются методы автоматизированной обработки научных публикаций, объединяющие подходы информационного поиска, обработки естественного языка и анализа графов научного цитирования. Классические методы информационного поиска в современных исследованиях дополняются нейросетевыми и графовыми подходами. Активно развиваются методы анализа научных публикаций, связанные с обработкой текстовых документов статей, анализом метаданных, обработкой визуальных элементов статей, моделированием научных областей, анализом цитатных взаимосвязей, и т.д.
Одним из наиболее активно развивающихся направлений является автоматизированная суммаризация и генерация обзорных текстов. Ранние методы суммаризации основывались преимущественно на извлечении информативных предложений и статистическом ранжировании текста. Развитие трансформерных архитектур привело к переходу к абстрактивной суммаризации, при которой итоговый текст формируется генеративной моделью . Одновременно развиваются методы многодокументной суммаризации, а также подходы, учитывающие иерархическую структуру длинных научных документов .
Развитие больших языковых моделей (Large Language Model, далее — LLM) и нейросетевых архитектур существенно расширило возможности автоматизированной генерации научных текстов, однако одновременно усилило проблему фактологической достоверности и усложнило контроль качества. В связи с этим одним из активно рассматриваемых направлений стала цитатно-осведомленный подход к обработке научных публикаций, поскольку предполагается, что он может обеспечить высокую достоверность и обоснованность при построении фактологически насыщенных научных текстов.
Несмотря на активное развитие цитатно-осведомленных методов обработки научной литературы, большинство современных исследований сосредоточено на задачах поиска публикаций, анализа структуры цитирования, формирования промежуточных представлений и генерации итогового текста. При этом качество самих цитатных фрагментов и степень их соответствия содержанию цитируемой публикации рассматриваются значительно реже. Между тем именно цитатные утверждения выступают одним из основных источников информации в цитатно-осведомленных системах, а ошибки и искажения на данном этапе способны распространяться на последующие этапы обработки и приводить к снижению достоверности генерируемых научных саммари и обзорных текстов. В связи с этим актуальной является задача разработки методов контроля фактологической согласованности цитатных утверждений и оценки их соответствия содержанию первоисточника.
Целью работы является обзор и анализ современных подходов к обеспечению фактологической достоверности цитатно-осведомленной генерации научных текстов, а также исследование возможности комплексной оценки соответствия научных утверждений содержанию публикации.
Работа носит обзорно-аналитический характер и включает экспериментальную апробацию подхода к комплексной оценке соответствия научных утверждений содержанию публикации.
Для достижения поставленной цели необходимо решить следующие задачи:
– провести анализ современных подходов к цитатно-осведомленной обработке научных публикаций и генерации научных текстов;
– исследовать основные проблемы фактологической достоверности и согласованности при цитатно-осведомленной генерации;
– выполнить анализ и систематизацию современных методов повышения качества и контроля достоверности генерируемых научных текстов, и выявить ограничения существующих подходов;
– предложить и апробировать подход к комплексной оценке соответствия научных утверждений, содержащихся в цитатах, содержанию научной публикации.
Для решения поставленных задач далее рассматриваются современные подходы к цитатно-осведомленной обработке научных публикаций, проблемы обеспечения фактологической достоверности генерируемых научных текстов и методы повышения качества цитатно-осведомленной генерации.
2. Цитатно-осведомленный подход к обработке научных публикаций
Цитатно-осведомленный подход представляет собой направление автоматизированной обработки научной литературы, в рамках которого публикация рассматривается не как изолированный текст, а как элемент сети научного взаимодействия. В отличие от традиционного анализа полного текста статьи, подобные методы учитывают также цитатные контексты, извлеченные из цитирующих публикаций, и структуру связей между документами. Основой данного подхода является представление о том, что научное цитирование отражает не только факт ссылки на публикацию, но и интерпретацию, оценку и использование результатов исследования в последующих работах.
Ранние исследования в области анализа цитирования были ориентированы преимущественно на изучение структуры научных связей и библиометрических характеристик публикаций. В работе научное цитирование рассматривается как механизм формирования тематически связанных научных направлений через анализ совместного цитирования публикаций. Аналогичный подход развивался в исследовании , где методы библиометрического анализа используются для выявления структуры научных областей и взаимосвязей между исследовательскими направлениями. В классических исследованиях по этой тематике показано, что цитатный контекст содержит информацию о функции ссылки, характере научного взаимодействия и роли цитируемой работы в структуре научной аргументации.
Одной из ключевых особенностей цитатно-осведомленных подходов является использование внешнего представления публикации, формируемого на основе цитирующих документов. В исследовании показано, что совокупность цитатных предложений позволяет формировать информативные саммари научных статей даже без использования полного текста публикации. В работе авторы, анализируя цитатные контексты научных статей, установили, что цитирующие публикации часто выделяют аспекты исследования, не отраженные в авторской аннотации, вследствие чего цитатные фрагменты могут использоваться как дополнительное представление научного вклада работы.
Несмотря на некоторые различия в реализации между предлагаемыми решениями, общая схема цитатно-осведомленной суммаризации включает в себя ряд основных этапов. На рис. 1 показаны эти этапы цитатно-осведомленной суммаризации.
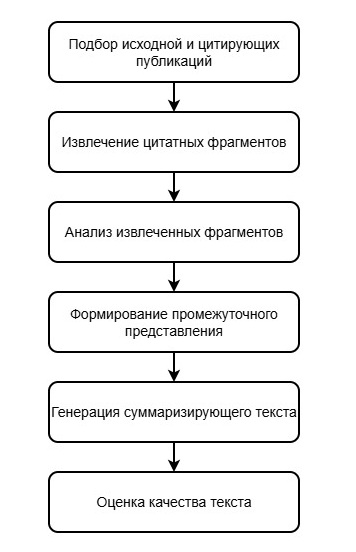
Рисунок 1 - Основные этапы цитатно-осведомленной суммаризации
Существенное развитие в современных работах получили методы, объединяющие анализ цитатных контекстов с графовыми моделями научной коммуникации. В работе предложена модель, объединяющая граф цитирования и нейросетевые представления документов для улучшения качества научной суммаризации. Появились иерархические и гетерогенные графовые архитектуры, ориентированные на моделирование локальных и глобальных связей между публикациями, разделами статьи и цитатными контекстами , .
Одним из центральных компонентов подобной обработки является анализ цитатного контекста. Под цитатным контекстом обычно понимается предложение с внутритекстовой ссылкой и окружающие его фрагменты текста, содержащие описание цитируемой работы. В исследовании предложены модели классификации функций цитирования, учитывающие структуру научной статьи и локальный контекст цитаты. В работе рассматриваются генеративные методы анализа намерений цитирования с использованием гетерогенных графов публикаций. Исследования показывают, что совместный учет цели и намерения цитирования позволяет точнее моделировать характер научного взаимодействия между публикациями.
Таким образом, современные цитатно-осведомленные подходы представляют собой комплексное направление автоматизированной обработки научной литературы, объединяющее методы анализа цитирования, многодокументной суммаризации, графового моделирования и обработки естественного языка. Современные исследования показывают, что использование цитатных контекстов и структуры научных связей позволяет формировать более информативные представления научных публикаций и учитывать особенности их восприятия в исследовательском сообществе. Одновременно развитие подобных методов приводит к усложнению задач анализа и интерпретации цитатных данных, поскольку качество итоговой суммаризации зависит не только от содержания исходных публикаций, но и от корректности выделения, интерпретации и сопоставления цитатных контекстов.
3. Проблемы фактологической достоверности и согласованности при цитатно-осведомленной генерации научных текстов
Несмотря на активное развитие цитатно-осведомленных подходов и их высокую эффективность в задачах автоматизированной обработки научной литературы, использование цитатной информации не гарантирует однозначную фактологическую достоверность формируемых саммари и обзорных текстов. В отличие от традиционной обработки отдельных документов, подобные системы опираются на совокупность взаимосвязанных источников, включающих цитатные контексты, графы цитирования и результаты генеративных моделей. Это позволяет учитывать структуру научного взаимодействия и повышать информативность итогового текста, однако одновременно приводит к возникновению дополнительных источников ошибок и искажений.
В области научной обработки текстов эти ограничения особенно значимы, поскольку в ней требуется сохранение терминологической точности, корректной интерпретации результатов исследований и проверяемости утверждений. Даже незначительные искажения содержания публикации, некорректная атрибуция результатов или генерация неподтвержденных утверждений способны привести к нарушению научной достоверности итогового обзора или саммари. В связи с этим проблема фактологической согласованности рассматривается как одно из ключевых ограничений современных систем и включает как вопросы корректности самих цитатных данных, так и проблемы генерации и оценки автоматически формируемых научных текстов.
Несмотря на то, что цитатные контексты широко используются в задачах суммаризации, построения обзоров, классификации намерений цитирования и генерации с использованием опорных фрагментов, сами цитаты не всегда корректно отражают содержание исходной публикации. В результате ошибки и искажения могут возникать уже на этапе формирования входных данных для последующей генерации текста.
Показано, что ошибки цитирования способны распространяться между публикациями по цепочке повторных ссылок, вследствие чего некорректная интерпретация результатов постепенно закрепляется в научном дискурсе. В работе отмечено широкое распространение неточного цитирования в биомедицинских публикациях и подчеркивают необходимость более строгой проверки ссылок и цитатных утверждений. В исследовании рассматривается задача автоматизированной оценки «цитатной интегрированности», включающая определение того, соответствует ли цитатное утверждение содержанию первоисточника, причем показано, что даже современные NLP-модели испытывают трудности при выявлении искажений цитирования.
Существенная проблема связана с тем, что цитирование нередко отражает не содержание работы в целом, а лишь отдельную интерпретацию результатов исследования. Авторы в работе показывают, что при цитировании исследователи часто упрощают выводы статьи, адаптируют их под собственную аргументацию или выборочно выделяют отдельные результаты, вследствие чего итоговое цитатное утверждение может существенно отличаться от оригинального текста. Аналогичные выводы представлены в работе , где показано, что без обращения к полному тексту статьи затруднительно определить, действительно ли цитата отражает значимый вклад публикации.
Поскольку в цитатно-осведомленных подходах цитатные контексты используются как источник информации для построения итогового текста, ошибки цитирования могут напрямую переноситься в генерируемые саммари и обзорные разделы. В отличие от традиционного информационного поиска, здесь возникает необходимость оценки не только релевантности цитатного фрагмента, но и степени его соответствия содержанию первоисточника.
Проблемы фактологической достоверности в цитатно-осведомленной суммаризации связаны не только с качеством самих цитатных данных, но и с другими этапами обработки научной информации. При построении научных саммари и обзорных текстов система должна выполнить поиск релевантных публикаций, сопоставление взаимосвязанных источников, устранение противоречий между ними и формирование согласованного итогового текста. Ошибки могут возникать на каждом из этих этапов: от выбора нерелевантных работ до искажения смысла при объединении информации из нескольких публикаций. В результате даже при использовании корректных цитатных контекстов итоговый текст может содержать фактологические несоответствия, чрезмерные обобщения или неподтвержденные выводы.
Существенное влияние на развитие автоматизированной обработки научной литературы оказало распространение больших языковых моделей, которые в последние годы стали основным инструментом генерации научных саммари и обзорных текстов . LLM способны эффективно выполнять абстрактивную генерацию, в том числе на основе цитатно-осведомленного подхода, формируя новый текст на основе множества источников и длинных контекстов. Однако одновременно с ростом качества генерации усилилось внимание к проблеме фактологической достоверности результатов. Исследования, анализирующие феномен галлюцинаций в системах генерации естественного языка, показывают, что модели способны добавлять сведения, отсутствующие в источнике, либо искажать исходное содержание текста . В работе авторы развивают данное направление применительно к большим языковым моделям и предлагают расширенную таксономию галлюцинаций.
Для цитатно-осведомленной генерации особую проблему представляет галлюцинирование библиографической информации и научных ссылок. В ряде работ фиксируются случаи появления сфабрикованных ссылок и некорректной библиографии. В работе рассматриваются случаи генерации правдоподобных, но несуществующих научных публикаций при подготовке академических текстов. Аналогичные наблюдения представлены в исследовании , где анализируется генерация ложных библиографических описаний, имитирующих публикации из рецензируемых журналов. Исследование , посвященное использованию LLM при подготовке систематических обзоров, показывает, что модели допускают ошибки при подборе литературы, пропускают релевантные публикации и генерируют библиографические записи с некорректными метаданными. В работе [26], посвященной анализу генеративных моделей в медицинском контенте, дополнительно подчеркивается высокий уровень фабрикации и неточности ссылок, вследствие чего авторы делают вывод о необходимости обязательной внешней проверки библиографических данных.
Помимо ошибок в библиографических данных, существенную проблему представляет фактологическая несогласованность генерируемого текста с исходными публикациями. Исследования по абстрактивной суммаризации показывают, что даже современные генеративные модели способны формировать факты, отсутствующие в исходных документах, сохраняя при этом грамматическую связность и внешнюю убедительность текста . Дополнительно подчеркивается, что модель может одновременно генерировать как корректные, так и неподтвержденные утверждения, вследствие чего проверка должна выполняться на уровне отдельных атомарных фактов, а не только документа в целом . Помимо этого, показано, что генеративные модели нередко опускают существенные детали исследования и склонны к излишним обобщениям.
Таким образом, на данный момент достаточно остро стоит проблема фактологической согласованности и достоверности при цитатно-осведомленной генерации научных текстов. Это привело к развитию ряда методов, направленных на повышение качества такой генерации.
4. Методы повышения достоверности и качества цитатно-осведомленной генерации научных текстов
Повышение достоверности цитатно-осведомленной генерации связано не с одним отдельным методом, а с совокупностью подходов, действующих на разных этапах обработки научной литературы: от поиска и отбора источников до формирования внутреннего представления данных, генерации текста и последующей оценки результата. Это обусловлено тем, что фактологические искажения могут возникать на различных этапах формирования текста. Поэтому современные исследования все чаще рассматривают генерацию научных текстов как многоэтапный процесс, включающий поиск, фильтрацию, ранжирование, структурирование и проверку информации.
Одним из наиболее распространенных направлений является использование RAG-подходов (retrieval-augmented generation). В таких системах генерация дополняется предварительным поиском релевантных документов или фрагментов текста, которые затем передаются модели в качестве внешнего контекста. RAG рассматривается как способ повышения качества генерации за счет обращения к актуальным внешним данным и проверки генерируемых утверждений
, . Вместе с тем подобные методы не устраняют проблему полностью, поскольку итоговая достоверность зависит не только от генеративной модели, но и от качества поиска, полноты корпуса, корректности ранжирования и способности модели правильно связать утверждение с найденным фрагментом.Другим направлением являются методы, использующие структуру научного текста и графовые связи между публикациями. Структурно-ориентированная и дискурсивно-ориентированная суммаризация позволяют учитывать функциональное деление статьи на разделы, риторические роли фрагментов и особенности научной аргументации
, . Иерархические модели направлены на обработку длинных научных документов за счет многоуровневого представления текста и последовательной агрегации информации . Графо-ориентированные подходы дополнительно учитывают связи между публикациями, цитатами, разделами и смысловыми единицами, что особенно важно для цитатно-осведомленной генерации, поскольку научный обзор строится не только на содержании отдельных работ, но и на характере отношений между ними . Данные методы преимущественно повышают полноту и структурную согласованность текста, но сами по себе не гарантируют фактологическую корректность генерируемого текста.Применяются подходы с использованием планируемой и управляемой генерации, где текст формируется не напрямую, а через промежуточные представления. Показано, что предварительное построение структуры текста повышает тематическую согласованность и снижает вероятность хаотичного объединения разнородных фрагментов
. Тем не менее планирование решает преимущественно проблему организации материала, а не его достоверности.Отдельное направление исследований составляют методы оценки и проверки фактологической согласованности. Для этой цели применяются семантические метрики, вопросно-ответные подходы, модели естественно-языкового вывода и подход с LLM в качестве эксперта. Метрики на основе лексического совпадения позволяют оценивать близость формулировок, однако плохо отражают фактологическую корректность научного текста. BERTScore и близкие к нему семантические метрики позволяют учитывать смысловое сходство, но также не всегда выявляют логические противоречия. NLI-подходы направлены на проверку того, следует ли утверждение из источника, а вопросно-ответные методы позволяют оценивать покрытие ключевой информации. В последние годы также развиваются схемы, в которых LLM выступает в роли оценивающей модели, однако такие оценки подвержены смещениям и требуют независимой проверки. Следовательно, оценочные методы являются необходимым компонентом контроля, но их результаты зависят от выбранных источников, качества извлеченного подтверждения и устойчивости самих моделей оценки.
Для систематизации рассмотренных методов и подходов целесообразно представить их в виде классификации по этапам цитатно-осведомленной суммаризации и основному направлению повышения качества, а также по основным недостаткам этих методов. Сформированная по результатам рассмотрения современных методов классификация показана в табл. 1.
Таблица 1 - Современные методы повышения качества цитатно-осведомленной суммаризации
Этап суммаризации | Методы | Основная направленность | Ограничения |
Подбор публикаций | Семантический поиск. RAG-методы. | Повышение обоснованности за счет поиска подтверждающих фрагментов | Зависимость от внешних данных и корректности подтверждающих фрагментов |
Извлечение и анализ цитат | Анализ контекстов. Анализ функций и намерений цитат. | Учет интерпретации и использования в последующих исследованиях | Возможная неточность интерпретации факторов анализа |
Формирование промежуточного представления | Структурная суммаризация. Дискурсивная суммаризация. Иерархическая суммаризация. Графовая суммаризация. | Повышение связности, полноты и структурной согласованности формируемого текста | Не обеспечивают проверку фактологической корректности исходных фрагментов |
Генерация суммаризирующего текста | Управляемая генерация. Плановая генерация. Пошаговая генерация. | Повышение логической согласованности и упорядоченности формирования текста | Возможен перенос ошибок входных данных, отсутствует проверка достоверности источников |
Существующие методы позволяют снижать отдельные риски цитатно-осведомленной суммаризации, однако в большинстве случаев охватывают лишь отдельные этапы обработки. RAG-подходы повышают обоснованность генерации, но не гарантируют корректность найденных фрагментов; графовые и структурные методы улучшают организацию материала, но не проверяют достоверность каждой цитаты; планируемая генерация повышает связность текста, но не устраняет ошибки исходных данных; оценочные методы позволяют выявлять часть несоответствий, но зависят от качества извлеченных подтверждений. Поэтому ключевым ограничением современных подходов остается их фрагментарность.
Таким образом, анализ современных исследований показывает, что большинство существующих подходов ориентировано на повышение качества поиска, суммаризации, структурирования или генерации научных текстов, а также на оценку качества итогового результата. Вместе с тем задача оценки соответствия цитатных утверждений содержанию цитируемой публикации во многих исследованиях остается вспомогательной либо вовсе не рассматривается. Между тем именно цитатные фрагменты являются одним из основных источников информации в цитатно-осведомленных системах, а ошибки на данном этапе способны распространяться на последующие этапы обработки. Это обосновывает необходимость разработки методов комплексной оценки соответствия цитатных утверждений содержанию первоисточника и контроля их фактологической согласованности.
5. Комплексный подход к оценке соответствия научных утверждений содержанию публикации
Проблема оценки достоверности фактологической согласованности формируемых саммари и обзорных текстов по-прежнему остается одной из наиболее существенных. При этом для цитатно-осведомленного подхода существенное влияние на достоверность оказывает качество исходных цитатных фрагментов и ихсоответствие содержанию цитируемых работ. При этом исследования показывают, что использование отдельных метрик качества не позволяет в полной мере оценивать достоверность научных утверждений, поскольку различные подходы, как правило, отражают лишь отдельные аспекты согласованности текста с исходной информацией
. В связи с этим предлагается использование комплексного подхода к оценке фактологической согласованности и соответствия цитирующих предложений содержанию цитируемой работы, основанного на совместном применении нескольких типов метрик. В рамках данного подхода оценка соответствия научного утверждения содержанию публикации выполняется с использованием совокупности метрик, что позволяет учитывать различные аспекты согласованности анализируемых текстовых фрагментов.В качестве набора данных для экспериментальной проверки был использован корпус SciFact, предназначенный для задач верификации научных утверждений
. Данный корпус содержит научные утверждения, связанные с ними публикации и размеченные подтверждающие фрагменты текста, позволяющие определить, подтверждается ли утверждение содержанием научной статьи (класс SUPPORT), противоречит ему (класс CONTRADICT) или не имеет достаточного подтверждения (класс NOT_ENOUGH_INFO). Несмотря на то, что SciFact не содержит внутритекстовых цитирований в явном виде, структура задачи является концептуально близкой к задаче оценки соответствия цитатных фрагментов содержанию цитируемой публикации. В рамках цитатно-осведомленного подхода цитатный контекст рассматривается как внешнее утверждение о содержании научной работы, сформированное другим автором. В обоих случаях требуется сопоставление научного утверждения с фрагментом исходной публикации и оценка степени их фактологической согласованности. В связи с этим корпус SciFact может использоваться в качестве тестовой среды для экспериментальной апробации подходов к комплексной оценке соответствия научных утверждений содержанию первоисточника.Предлагаемый подход к оценке фактологической согласованности включает несколько последовательных этапов обработки научного утверждения и текста публикации. Основные этапы приведены на рис. 2.
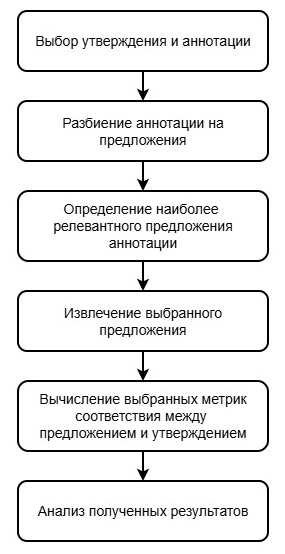
Рисунок 2 - Основные этапы комплексной оценки соответствия научных утверждений информации из первоисточника
После выделения и извлечения наиболее релевантного фрагмента выполняется комплексная оценка степени его соответствия исходному научному утверждению. В рамках предлагаемого подхода используются четыре метрики, совместно используемые в составе единой схемы оценки достоверности и соответствия источнику: ROUGE, BERTScore, QA и NLI. Метрика ROUGE применяется для оценки лексического совпадения и близости текстовых формулировок
. В эксперименте использовалась метрика ROUGE-L, которая соответствует совпадениям на уровне наибольшей общей текстовой подпоследовательности. Метрика BERTScore используется для оценки семантического сходства между текстовыми фрагментами . Метрика QA основана на вопросно-ответном подходе, который позволяет оценить полноту передачи ключевой информации . Метрика NLI позволяет определить, следует ли рассматриваемое утверждение из фрагмента текста (entailment), противоречит ему (contradiction) либо не имеет достаточного подтверждения (neitral) .Применение этих четырех метрик позволяет учитывать текстовое сходство, семантическую близость, фактологическую точность и логическую связность утверждений. Одновременное использование этих метрик позволяет компенсировать ограничения отдельных метрик и получить более устойчивую оценку фактологической согласованности и достоверности. Подобный подход может рассматриваться как один из перспективных способов комплексной оценки соответствия цитатных утверждений содержанию цитируемой научной публикации в задачах цитатно-осведомленной обработки научной литературы.
Для экспериментальной проверки предлагаемого подхода была сформирована выборка научных утверждений из корпуса SciFact, включающая утверждения классов SUPPORT и CONTRADICT. Для каждого класса в выборку входило 300 утверждений. Для каждого утверждения выполнялся поиск наиболее релевантного фрагмента аннотации научной публикации, после чего вычислялись значения метрик ROUGE-L, BERTScore, QA и NLI. После этого были вычислены медианные значения показателей метрик для классов SUPPORT и CONTRADICT. Результаты приведены в табл. 2.
Таблица 2 - Медианные значения метрик соответствия для классов SUPORT и CONTRADICT
Класс утверждений | ROUGE-L | BERTScore | QA | NLI (Entailment) | NLI (Contradiction) |
SUPPORT | 0,3914 | 0,8721 | 0,6727 | 0,8156 | 0,1034 |
CONTRADICT | 0,2966 | 0,8339 | 0,3931 | 0,1836 | 0,7452 |
Полученные результаты показывают, что различные типы метрик характеризуют разные аспекты фактологической согласованности научных утверждений. Для утверждений класса SUPPORT наблюдаются более высокие значения QA-score и entailment, тогда как для класса CONTRADICT характерен рост contradiction. При этом сравнительно высокие значения BERTScore для части противоречащих утверждений свидетельствуют о том, что семантическое сходство само по себе не гарантирует фактологической корректности утверждения. Таким образом, результаты подтверждают целесообразность комплексного использования нескольких типов метрик при оценке соответствия научного утверждения содержанию публикации.
Полученные результаты согласуются с выводами ряда современных исследований, посвященных оценке фактологической согласованности научных текстов. Так, в работе Kryściński и соавт.
показано, что традиционные метрики, основанные на текстовом сходстве, не позволяют надежно оценивать фактологическую корректность текста, поскольку не учитывают логическую согласованность утверждений с источником. Аналогичный эффект наблюдается и в проведенном эксперименте, где для части утверждений класса CONTRADICT сохраняются ненулевые значения ROUGE-L и сравнительно высокие значения BERTScore. В исследованиях и показано, что различные метрики чувствительны к разным типам фактологических ошибок и отражают различные аспекты качества текста. Полученные результаты подтверждают данный вывод: семантические, вопросно-ответные и логические метрики демонстрируют различную степень разделения утверждений классов SUPPORT и CONTRADICT, что свидетельствует о необходимости их совместного использования. Результаты также согласуются с выводами работ, в которых показана высокая эффективность методов естественно-языкового вывода при выявлении фактологических несоответствий . В проведенном эксперименте именно показатели entailment и contradiction обеспечивают наиболее выраженное различие между подтверждающими и противоречащими утверждениями. Вместе с тем, в отличие от работ или , ориентированных преимущественно на оценку фактологической достоверности итоговых саммари и генерируемых текстов, предлагаемый подход направлен на оценку соответствия отдельных научных утверждений содержанию публикации и может использоваться для контроля качества цитатных фрагментов в задачах цитатно-осведомленной обработки научной литературы.
6. Заключение
В работе проведен анализ современных исследований в области цитатно-осведомленной обработки научных публикаций, генерации научных саммари и обзорных текстов, а также методов обеспечения их фактологической достоверности. Показано, что большинство существующих подходов ориентировано на задачи поиска источников, извлечения информации, суммаризации и генерации текста, а также на оценку качества итогового результата.
В результате анализа литературы выявлено, что задача оценки соответствия цитатных утверждений содержанию цитируемой публикации рассматривается значительно реже, чем задачи поиска, обработки и генерации научной информации. При этом именно цитатные фрагменты являются одним из основных источников информации в цитатно-осведомленных системах и могут содержать искажения или неполные интерпретации результатов первоисточника, влияющие на качество последующих этапов обработки.
Для решения данной задачи предложен подход к комплексной оценке соответствия научных утверждений содержанию публикации, основанный на совместном использовании лексических, семантических, вопросно-ответных и логических метрик. Проведенная апробация на корпусе SciFact показала, что различные типы метрик отражают различные аспекты фактологической согласованности научных утверждений и позволяют выявлять как семантические совпадения, так и логические противоречия между утверждением и содержанием публикации.
Научная новизна работы заключается в акцентировании внимания на задаче оценки соответствия цитатных утверждений содержанию цитируемой публикации, которая в большинстве рассмотренных исследований остается второстепенной по отношению к задачам поиска, суммаризации и генерации текста. В отличие от существующих подходов, ориентированных преимущественно на оценку качества итогового результата, предложенный подход направлен непосредственно на контроль фактологической согласованности научного утверждения и содержания первоисточника на основе комплексного использования нескольких типов метрик.
Полученные результаты подтверждают перспективность развития методов контроля соответствия цитат содержанию первоисточника как одного из направлений повышения достоверности цитатно-осведомленной генерации научных саммари и обзорных текстов.