Исследование и разработка метода трансформации устной речи в документ на примере программного обеспечения с использованием технологий распознавания речи
Исследование и разработка метода трансформации устной речи в документ на примере программного обеспечения с использованием технологий распознавания речи

Аннотация
Документирование является важной составляющей исследовательской и аналитической деятельности, обеспечивая достоверность данных, воспроизводимость результатов и систематизацию полученной информации. Однако традиционные методы ведения записей остаются трудоемкими, требуют значительных временных ресурсов и подвержены ошибкам, обусловленным человеческим фактором. В связи с этим актуальной задачей является разработка средств автоматизации процессов документирования. В статье предлагается механизм динамического протоколирования, направленный на автоматическое формирование структурированных протоколов на основе голосовых записей. Предложенная методология включает запись и предварительную обработку аудиосигнала, его очистку от шумов и искажений, преобразование устной речи в текст с использованием современных языковых моделей, а также двухэтапное извлечение ключевых тезисов посредством применения регулярных выражений и методов обработки естественного языка. Реализация данного подхода позволяет повысить точность обработки информации и обеспечить эффективное структурирование полученных данных. Научная новизна заключается в разработке целостного подхода к автоматизации документирования на наименее формализованных этапах исследовательского процесса. Практическая значимость работы определяется сокращением временных затрат, снижением нагрузки на специалистов и минимизацией ошибок рутинного документирования, а также возможностью применения разработанного решения в научной и профессиональной деятельности.
1. Введение
Современная исследовательская и профессиональная деятельность в медицине, криминалистике, судебной экспертизе и научных исследованиях, требует тщательного и своевременного документирования. Протоколы экспериментов, истории болезни, отчеты о следственных действиях и полевые наблюдения являются основой для дальнейшей деятельности. Однако традиционный процесс документирования остается ресурсоёмким этапом работы. Он требует от специалистов одновременного выполнения двух задач: непосредственного проведения исследования (или иной профессиональной деятельности) и параллельного фиксирования результатов, что приводит к когнитивной перегрузке, увеличению времени выполнения работ и, как следствие, риску пропуска важных деталей и субъективным ошибкам, которые обусловлены «человеческим фактором».
Проблема усугубляется в условиях, где основным источником данных является речь. К таким условиям относятся мозговые штурмы, оперативные совещания, административные обходы в медицинских учреждениях или осмотры мест происшествий. Например, в некоторых исследованиях, связанных с изучением процесса приема врачей УЗИ описывается, что прием врача длится в среднем 17 минут 52 секунды, из которых 40–60% времени составляло заполнение врачом связанной медицинской документации и заполнение полей структурированного электронного медицинского документа (СЭМД) «Протокол инструментального исследования»
. Существующие решения для автоматизации документооборота, ориентированные на формализованные данные и заранее заданные шаблоны, оказываются малоэффективными для обработки неструктурированной устной речиВ таком случае, решением будет являться разработка системы автоматического протоколирования на основе технологий речевой аналитики. Такой подход предполагает автоматическое преобразование аудиозаписи рабочего процесса в структурированный текстовый документ (протокол), предварительно выделив семантически значимые тезисы. Данный метод обеспечивает обработку информации с минимальной задержкой и исключает наличие орфографических или пунктуационных ошибок в протоколе.
2. Методы и принципы исследования
Целью исследования является разработка программного комплекса для автоматического динамического протоколирования на основе голосового ввода, обеспечивающего преобразование спонтанной устной речи в структурированный текстовый документ с минимальной задержкой и без передачи данных во внешние сервисы. Основную задачу исследования можно разбить на несколько подзадач и формализовать следующим образом:
Для подзадачи распознавания речи (далее ASR) необходимо ввести следующие обозначения . Пусть —
где
Одновременно с этим, задача извлечения семантически значимой информации (Information Extraction)
Не менее значимой является и задача формирования структурированного документа (Document Generation — далее
где
Таким образом, итоговая задача формулируется как разработка композитной функции
Прежде чем приступить к разработке решения, необходимо проанализировать и сравнить уже существующие сервисы и оценить их по ключевым критериям: режим работы, точность обработки русского языка, гибкость настройки и применимость в условиях строгой конфиденциальности. Для анализа были рассмотрены три решения для распознавания речи: Yandex SpeechKit, Microsoft Azure Cognitive Services (Speech) и Vosk, однако у них были обнаружены такие недостатки: отсутствие оффлайн-режима для облачных решений, влекущее за собой риски безопасности, невозможность передачи персональных данных, невозможность использования иностранных разработок в государственных учреждениях РФ, высокая стоимость и значительная сложность кастомизации.
Среди решений для обработки русского языка в части извлечения именованных сущностей (NER) активно используются такие библиотеки, как: Natasha, DeepPavlov и Tomita‑Parser.
Natasha является оффлайн‑решением с открытым исходным кодом, ориентированным на задачи токенизации, лемматизации, извлечения именованных сущностей и синтаксического разбора. Основные преимущества Natasha над Tomita-Parser и DeepPavlov, который основан на BERT , заключаются в том, что данное решение работает оффлайн, хорошо адаптировано к морфологии русского языка, а также обладает легковесной и модульной архитектурой. Основной недостаток состоит в том, что для узкоспециализированных терминов и доменов модель требует дообучения.
Главной особенностью предлагаемого подхода к автоматическому параллельному документированию является его автономность. Метод ориентирован на широкий спектр пользователей, включая государственные структуры, где вопрос конфиденциальности данных является приоритетным. Для обеспечения безопасности данных применяется оффлайн-распознавание речи на основе языковых моделей.
Современные языковые модели позволяют решать задачи с высокой точностью, будучи предварительно обученными на больших массивах текстовых данных, что избавляет от необходимости размечать объемные обучающие выборки для каждой конкретной задачи, требуя относительно небольшого набора данных для точечного дополнительного обучения (fine-tuning).
Для нашей задачи оптимальным решением является оффлайн-модель VOSK, разработанная российской компанией Alpha Cephei . Ее преимущества включают: автономность обработки данных, кроссплатформенность, низкая задержка при работе в реальном времени, а также наличие предварительно обученных моделей для русского языка различного размера (от 45 МБ до 2.5 ГБ) (Таблица 1). В данном случае это позволяет найти баланс между нефункциональными требованиями и точностью распознавания.
Таблица 1 - Русскоязычные версии языковой модели Vosk
Модель | Вес модели | Уровень тестирования | Примечание |
vosk-model-ru-0.42 | 1.8 Gb | 4.5 (our audiobooks) 11.1 (open_stt audiobooks) 19.5 (open_stt youtube) 36.0 (openstt calls) 4.4 (golos crowd) 17.9 (sova devices) | Большая смешанная российская модель для серверов |
vosk-model-small-ru-0.22 | 45 Mb | 22.71 (openstt audiobooks) 31.97 (openstt youtube) 29.89 (sova devices) 11.79 (golos crowd) | Облегченная широкополосная модель для Android/iOS и RPi |
vosk-model-ru-0.22 | 1.5 Gb | 5.74 (our audiobooks) 13.35 (open_stt audiobooks) 20.73 (open_stt youtube) 37.38 (openstt calls) 8.65 (golos crowd) 19.71 (sova devices) | Большая смешанная российская модель для серверов |
vosk-model-ru-0.10 | 2.5 Gb | 5.71 (our audiobooks) 16.26 (open_stt audiobooks) 26.20 (public_youtube_700_val open_stt) 40.15 (asr_calls_2_val open_stt) | Большая узкополосная российская модель для серверов |
Для использования системы в узких предметных областях со своей собственной терминологией (например, медицине или юриспруденции) модель Vosk поддерживает возможность расширения на специализированных текстовых корпусах. Данная функция обеспечивает точность распознавания профессиональной терминологии и адаптивность решения к конкретным условиям эксплуатации. При этом ключевыми требованиями к модели являются не только точность и безопасность, но и интерпретируемость результатов. Последнее особенно важно в медицине т.к. тем самым повышает уровень доверия к прогнозам модели.
После конвертации голоса в текст возникает задача выделения семантически значимых участков для занесения их в шаблон документа/протокола. Классический подход подразумевает разработку синтаксического анализатора, включающего лексический и синтаксический этапы . Однако данный метод хоть и эффективен для формализованных языков (языков программирования), оказывается неподходящим для обработки устной речи, характеризующейся высокой вариативностью и нестандартными конструкциями.
Альтернативным решением выступает технология распознавания именованных сущностей (NER) , позволяющая извлекать из текста объекты заданных категорий (имена, даты, локации, медицинские термины) на основе семантических, а не синтаксических признаков. В отличие от парсеров, NER-системы, основанные на машинном обучении, не требуют ручного описания грамматических правил. Они обучаются на размеченных текстах и способны выявлять сущности по контексту, демонстрируя устойчивость к морфологическим и синтаксическим вариациям.
Для решения данной проблемы была выбрана библиотека Natasha (Рисунок 1). Выбор обусловлен соответствию ключевым требованиям: отсутствию необходимости передачи данных внешним сервисам, поддержки русского языка и высокой точностью распознавания.

Рисунок 1 - Пример работы семантического анализатора Natasha
1. Морфологический анализ на основе модели pymorphy3, обеспечивающей лемматизацию и определение грамматических характеристик слов.
2. Синтаксический анализ с использованием алгоритмов извлечения зависимостей (dependency parsing), что позволяет учитывать контекстные связи между словами.
3. Распознавание сущностей с применением правил, основанных на комбинации морфологических признаков, словарей и контекстных шаблонов. Так, для извлечения имён используются правила, учитывающие падежные окончания, типичные для имен собственных в русском языке.
4. Нормализация извлеченных значений — приведение сущностей к стандартному формату (например, унификация формата дат).
Таким образом, применение NER-библиотеки Natasha позволяет решить задачу структурирования текстовых данных, полученных в результате транскрибации аудиозаписей. Данное решение дополняется препроцессингом и нормализацией данных, включающий парсинг отчетов, преобразование данных в структурированную форму и устранение дубликатов, что может послужить основой для создания надежных систем обработки медицинских данных и обеспечить их целостность и пригодность для последующего использования. Разработанная система динамического протоколирования представляет собой последовательность связанных между собой функциональных компонентов, где результат каждого модуля служит входными данными для последующего.
На начальном этапе система обрабатывает полученную аудиозапись с использованием библиотеки NAudio. Модуль выполняет комплексную подготовку звукового сигнала, включая фильтрацию фоновых шумов, нормализацию амплитуды и коррекцию артефактов записи.
Затем, преобразование подготовленной голосовой записи в текстовые данные осуществляется при помощи оффлайн-модели VOSK. Локальный характер обработки исключает необходимость передачи данных внешним сервисам, гарантируя информационную безопасность.
Последний этап обработки реализован на базе NER-библиотеки Natasha и включает многоуровневый анализ текста. Модуль последовательно выполняет токенизацию входного текста, морфологический анализ с определением грамматических характеристик, идентификацию и классификацию именованных сущностей (имена собственные, временные метки, организации, термины предметной области). Для обработки специализированных шаблонов данных модуль дополнен механизмом правил на основе регулярных выражений.
Система включает специализированный модуль, который преобразует извлеченные сущности в структурированные данные протокола. На основе предварительно настроенных шаблонов документов модуль автоматически распределяет выявленные токены по соответствующим разделам протокола, обеспечивая семантическую корректность.
Все компоненты разработанной системы инкапсулированы в единый программный контейнер, что обеспечивает кроссплатформенность и упрощает развертывание. Архитектура предусматривает механизм адаптации к предметным областям через дополнительное обучение акустических моделей распознавания и расширение словарных баз извлечения сущностей.
3. Основные результаты
Для валидации разработанного метода было проведено тестирование в условиях, имитирующих медицинский клинический обход. Рассмотрим работу системы на конкретном примере. Так, в качестве входных данных будет выступать следующая аудиозапись устной речи врача:
«Пациент Иванов Сергей Петрович, 1985 года рождения. На момент осмотра предъявляет жалобы на острые боли в эпигастральной области, тошноту. Назначен эзомепразол 40 мг раз в день, контрольное эндоскопическое исследование через 14 дней».
В результате транскрибации текст был распознан с минимальными ошибками: «пациент иванов сергей петрович 1985 года рождения на момент осмотра предъявляет жалобы на острые боли в эпигастральной области тошноту назначено эзомепразол 40 миллиграмм раз в день контрольное эндоскопическое исследование через 14 дней».
Извлеченные сущности были автоматически распределены по заранее заданному шаблону истории болезни, формируя структурированную запись.
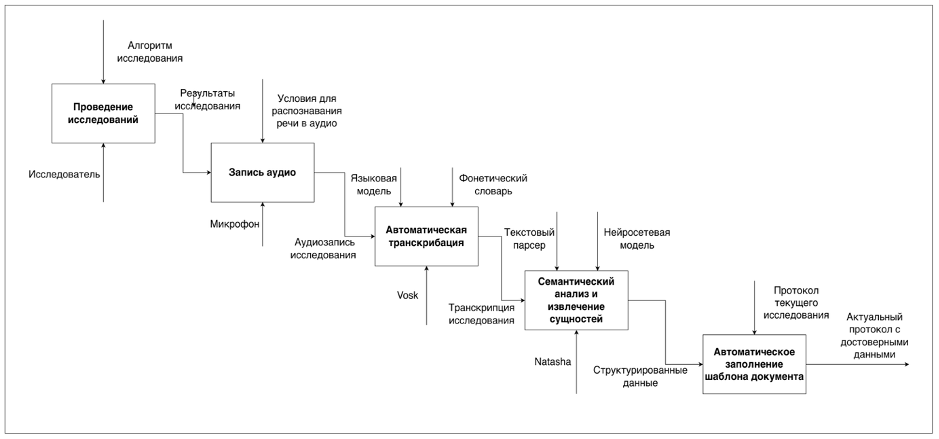
Рисунок 2 - Блок-схема процесса документирования
4. Заключение
В результате проведенной работы разработан и апробирован метод автоматизированного формирования структурированных документов на основе распознавания устной речи. Новизна предложенного подхода состоит в сквозной обработке речевого потока — от транскрибации до заполнения шаблона документа — без участия оператора и без изменения базовой архитектуры системы при смене предметной области.
Ключевыми результатами являются сокращение временных затрат на документирование примерно на 54% по сравнению с ручным заполнением, а также обеспечение корректной автоматической структуризации данных для различных типов документации путём настройки шаблонов и правил извлечения сущностей.
Данное прикладное решение может применяться в создании таких отчетных форм, как структурные электронные медицинские документы, документы приема и выдачи товаров со складов, отчеты и записи научных исследований, протоколы следственных действий.
Перспективы развития системы связаны с расширением библиотеки готовых шаблонов за счет интеграции различных профессиональных областей и созданием инструментов для самостоятельной настройки схем документирования конечными пользователями, что может позволить унифицировать процесс автоматизации документооборота в организациях различного профиля без необходимости разработки специализированных программных решений для каждой отдельной задачи.