Оптимизация контекста больших языковых моделей в агентных системах: от статического промпт-инжиниринга к динамической инженерии контекста
Оптимизация контекста больших языковых моделей в агентных системах: от статического промпт-инжиниринга к динамической инженерии контекста

Аннотация
В статье предложена формальная математическая модель оптимизации контекста в агентных системах — как многокритериальной задачи максимизации ожидаемого вознаграждения при ограничениях на длину контекста, объём данных, вычислительные ресурсы и качество источников. Новизна исследования состоит в возможности применять методы математической оптимизации (например, методы нелинейного программирования, эволюционные алгоритмы или reinforcement learning) для автоматизированного подбора оптимальной стратегии обогащения контекста — с учётом баланса качества ответа и ресурсных затрат.
В ходе экспериментального исследования проведена апробация предложенной математической модели. Выполнена оптимизация контекста на пяти сценариях работы LLM (простой промпт, RAG на неструктурированных данных, поиск по структурированным данным, вызов tools, механизм памяти диалога) на двух моделях (Qwen3-Ru и Qwen3.5) на примере задачи разработки консультанта для поступающих в ВУЗ. Оценка качества выполнялась методом LLM as Judge по шкале 0–9. Установлено, что наибольший прирост качества обеспечивают вызов инструментов (Δ до +3,5 балла относительно простого промпта) и механизм памяти диалога (Δ до +3,7 балла). Показано, что архитектурные решения влияют на качество сильнее, чем простое увеличение объёма контекста. Qwen3.5 демонстрирует лучшее соотношение качества и вычислительной эффективности (время выполнения тестового набора — 2 минуты против 9 минут у Qwen3-Ru).
Результаты подтверждают, что ключевым фактором эффективности LLM в прикладных задачах является не масштаб контекста, а способ его организации, структурирования и интеграции с внешними инструментами и памятью.
1. Введение
Появление больших языковых моделей (Large Language Models, LLMs) продемонстрировало беспрецедентные возможности в понимании естественного языка, его генерации и рассуждении. LLM эволюционировали от базовых систем, выполняющих инструкции, до центральных механизмов рассуждений в сложных агентных системах.
Однако производительность и эффективность этих моделей определяется не только информацией, которую они получают на этапе обучения, но и контекстом, предоставляемым на этапе инференции (вывода). По мере усложнения решаемых задач развивались методы проектирования и управления информацией — как на этапе обучения, так и на этапе предсказания.
Информационный домен — это область знаний или сфера деятельности, в рамках которой функционирует LLM и для которой требуется специфический набор данных, терминологии, правил и закономерностей. Информационный домен задаёт границы и специфику контекста, в котором модель должна демонстрировать компетентность. Например:
- медицина (термины, протоколы лечения, научные исследования);
- юриспруденция (законы, прецеденты, процессуальные нормы);
- финансы (рыночные показатели, экономические теории, нормативные акты);
- техническое образование (инженерные дисциплины, стандарты, методики обучения);
- кибербезопасность (угрозы, протоколы защиты, анализ кода).
В рамках каждого информационного домена требуются специфические подходы к формированию входных данных для LLM, поскольку универсальные методы могут не учитывать нюансы терминологии, логики рассуждений и структуры знаний конкретной области.
Статические инструкции для LLM принято называть промптом (prompt), а методы их формирования изучают в дисциплине промпт‑инжиниринга (Prompt Engineering). Эта область фокусируется на разработке оптимальных формулировок запросов, позволяющих добиться от модели точных и релевантных ответов в рамках заданного информационного домена.
Динамические методы формирования подсказок, учитывающие текущий контекст, внешние источники знаний и историю взаимодействия, изучаются в рамках инженерии контекста (Context Engineering). В отличие от статических промптов, контекстные подсказки могут включать фрагменты релевантных документов из внешних баз знаний, исторические диалоги или предыдущие шаги рассуждения, структурированные данные (таблицы, графы знаний) и т.д.
Применение методов инженерии контекста позволяет дополнить знания агента актуальной информацией за пределами предобученной базы, направить его поведение в нужное русло с учётом специфики информационного домена, повысить точность и релевантность ответов за счёт интеграции внешних данных и снизить вероятность «галлюцинаций» (вымышленных фактов) в генерации.
Цель работы — раскрыть возможности агентных систем на базе LLM в полной мере, повысить качество диалогов и решений в заданном информационном домене за счёт применения методов контекстной инженерии. В своей работы мы разработали методику оптимизации контекста LLM к специфике предметной области и протестировали эффективность на примере создания консультанта для поступающих в высшее учебное заведение.
Исследования последних лет демонстрируют растущий интерес к способам повышения эффективности больших языковых моделей (LLM) за счёт оптимизации контекста, подаваемого на вход.
Ранние работы
в этой области были сосредоточены преимущественно на дизайне промптов (prompt engineering) — подборе формулировок запросов, которые позволяют добиться от модели более точных и релевантных ответов. В рамках этого направления были разработаны такие техники, как few‑shot prompting, chain‑of‑thought (CoT) и zero‑shot CoT, показавшие, что структурирование запроса может существенно улучшить качество генерации. Эти методы легли в основу современных подходов к контекстной инженерии .Параллельно развивались подходы, предполагающие интеграцию LLM с внешними источниками знаний. Ключевым прорывом здесь стала концепция Retrieval‑Augmented Generation (RAG)
, объединяющая возможности поиска релевантной информации (retrieval) и генерации текста на основе найденных данных. Исследования в этой сфере заложили основы для создания более сложных архитектур, включая модульные системы и агентные архитектуры, где LLM взаимодействует с инструментами поиска и базами данных.В русскоязычной научной литературе также активно исследуются различные аспекты RAG и контекстной инженерии:
Оболенский Д. М.
рассматривает применение RAG в интеллектуальных образовательных экосистемах с использованием библиотеки LangChain, языковой модели GigaChat и векторной СУБД Qdrant. Система обрабатывает описания вакансий и образовательных ресурсов для генерации персонализированных описаний рынка труда. Проведен анализ публикационной активности и научных коллабораций научно-педагогических работников . Оценка использования GigaCode в деятельности IT-компаний включает сравнение с аналогичными решениями, такими как GitHub Copilot и Amazon CodeWhisperer.Науменко А. О.
анализирует архитектуру RAG, её преимущества и ограничения по сравнению с традиционными методами обучения LLM. Автор описывает ключевые компоненты RAG (методы индексации, поиска и интеграции информации) и подчёркивает значимость технологии для повышения точности и надёжности генерируемого контента.Волков С. С., Шалыгин С. В., Лабинцев А. И.
исследуют оптимизацию контекста LLM в высшем техническом образовании, предлагая подходы к адаптации моделей для образовательных задач.Значительный объём работ посвящён решению проблемы обработки длинных последовательностей — одной из ключевых сложностей при работе с расширенным контекстом. Предложены методы сжатия контекста, иерархического управления памятью и селективного извлечения информации, позволяющие моделям эффективно оперировать большими объёмами данных без потери производительности:
Гисин В. Б.
предлагает динамическую модель внимания в трансформерах, улучшающую обработку длинных последовательностей.Болтачев Э. Ф., Фархадов М. П., Тюляков А. И.
исследуют методы токенизации текстов в финансовой сфере, что напрямую влияет на эффективность представления контекста для LLM.Особое внимание уделяется вопросам безопасности и надёжности LLM:
Унижаев Н. В.
анализирует модель угроз конфиденциальной информации в LLM, выявляя риски утечки данных при работе с контекстом.Швыров В. В., Капустин Д. А., Сентяй Р. Н.
предлагают методы использования LLM с поддержкой рассуждений для анализа безопасности программного кода, демонстрируя возможности контекстной инженерии в прикладных задачах.Несмотря на существенный прогресс, анализ более 1400 исследований
выявил критическую асимметрию в возможностях современных LLM. Модели, усиленные методами контекстной инженерии, демонстрируют впечатляющую способность понимать сложные и объёмные контексты. Однако, при генерации развёрнутых, логически связных и детализированных текстов они сталкиваются с заметными ограничениями: ответы могут терять последовательность, содержать фактические ошибки или излишне повторяться. Этот разрыв между способностями к восприятию и генерации представляет собой важнейший нерешённый вопрос, определяющий направления будущих исследований в области контекстно‑ориентированного ИИ.2. Методы и принципы исследования
Пусть имеется некоторый набор задач, которые необходимо решить с помощью агента. Например: написать код на языке Python, проконсультировать покупателя или поступающего в ВУЗ и т.д. Множество задач в таком наборе теоретически бесконечно, однако на практике мы имеем дело с ограниченным набором двоек «запрос — ответ»:
где:
Вероятностная авторегрессионная (большая языковая) модель генерирует выходную последовательность путём максимизации условной вероятности:
где:
В инженерии промптов контекст C формируется как композиция запроса пользователя и статичной инструкции по решению задачи. В инженерии контекста C представляет собой динамически структурированный набор информационных компонентов
где:
Конечный результат формируется за несколько итераций извлечения информации и генерации промежуточных рассуждений. Максимизация ожидаемого качества вывода агента формализуется как задача оптимизации. Пространство поиска включает в себя множество функций генерации и композиции контекста F.
Тогда целевая функция имеет вид:
где:
F^* — оптимальный набор функций генерации контекста;
Эта задача оптимизации имеет ряд ограничений.
1) Ограничение на длину контекста модели:
где:
Это ограничение частично компенсируется сжатием информации (summarization), селективным отбором наиболее релевантных фрагментов и методами управления иерархической памятью.
2) Ограничение на объём доступных документов.
где:
3) Ограничение на выборку задач.
где:
Ограниченная выборка не в полной мере отражает реальное распределение задач и недостаточно покрывает краевые случаи (edge cases).
4) Вычислительные ограничения.
где:
Эти ограничения в совокупности формируют многокритериальную оптимизационную задачу, где необходимо балансировать между:
- качеством ответа;
- объёмом используемого контекста;
- затрат на сбор данных;
- репрезентативностью выборки;
- вычислительными ресурсами.
Таким образом, исследование направлено на оценку эффективности различных подходов к управлению контекстом в больших языковых моделях при решении предметно‑ориентированных задач. В рамках данной работы для решения задачи оптимизации применяется метод полного перебора.
3. Основные результаты
В качестве тестовых моделей выбраны две LLM:
- Qwen3 с адаптацией к русскому языку ;
- Qwen3.5 без адаптации, но с улучшенной архитектурой .
Для каждой модели тестируются пять сценариев взаимодействия, чтобы понять, как разные методы работы с контекстом влияют на качество ответов:
1. Простой промпт — модель получает только запрос пользователя и базовую инструкцию без дополнительного контекста.
2. RAG на неструктурированных данных — к запросу добавляется контекст из внешних источников, разбитый на чанки фиксированного размера.
3. Поиск по структурированным данным — модель использует заранее подготовленные структурированные данные (например, таблицы, JSON) для формирования ответа.
4. Вызов tools — модель может вызывать внешние инструменты (функции) для получения актуальной информации (например, поиск данных в таблицах).
5. Механизм памяти диалога — модель учитывает историю взаимодействия с пользователем, чтобы давать более согласованные и последовательные ответы.
Оценка качества ответов выполняется методом LLM as Judge . Для этого используется отдельная языковая модель в роли эксперта. Ей подаются на вход эталонный ответ (ground‑truth) и ответ тестируемой модели (response).
Шкала оценок:
0 — ответ полностью не соответствует эталонному (неверная информация, нерелевантен);
1–3 — существенные ошибки или пропуски, основная суть частично угадана;
4–6 — в целом релевантный ответ, но есть неточности, неполнота или небольшие ошибки;
7–8 — хороший ответ, близкий к эталонному, незначительные недочёты;
9 — практически идентичен эталонному, без ошибок.
Каждый сценарий тестируется на выборке из 30 типовых задач (например, консультации по поступлению в вуз, поиск стоимости обучения, уточнение количества мест).
Для каждого ответа вычисляется оценка по указанной шкале, затем рассчитывается средний балл по сценарию и модели.
Таблица 1 - Средние оценки качества ответов
Примечание: по шкале 0–9
Сценарий | Qwen3-Ru | Qwen3.5 |
Простой промпт | 4,0 | 3,8 |
RAG на неструктурированных данных | 5,1 | 4,8 |
Поиск по структурированным данным | 5,1 | 5,1 |
Вызов tools (поиск по таблицам) | 7,1 | 7,3 |
Механизм памяти диалога | 7,3 | 7,5 |
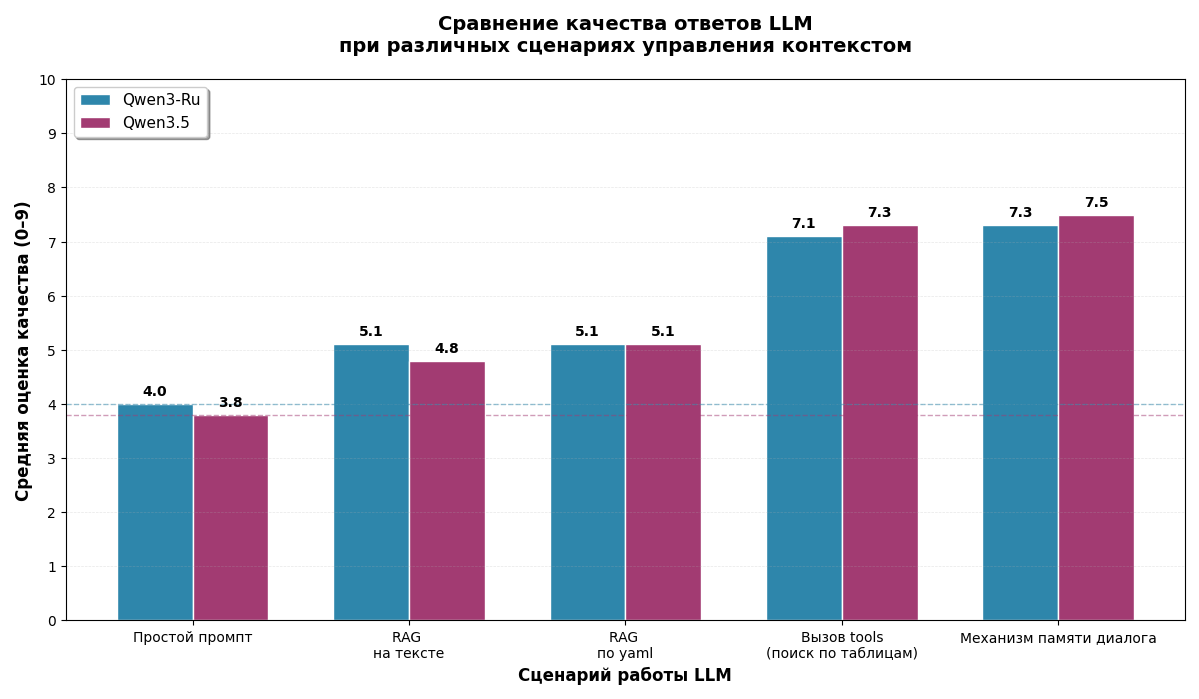
Сравнение качества ответов при различных сценариях управления контекстом
Таблица 2 - Распределение оценок по диапазонам
Диапазон оценок | Qwen3-Ru | Qwen3.5 |
0-3 | 3 | 0 |
4-6 | 2 | 5 |
7-8 | 16 | 21 |
9 | 7 | 2 |
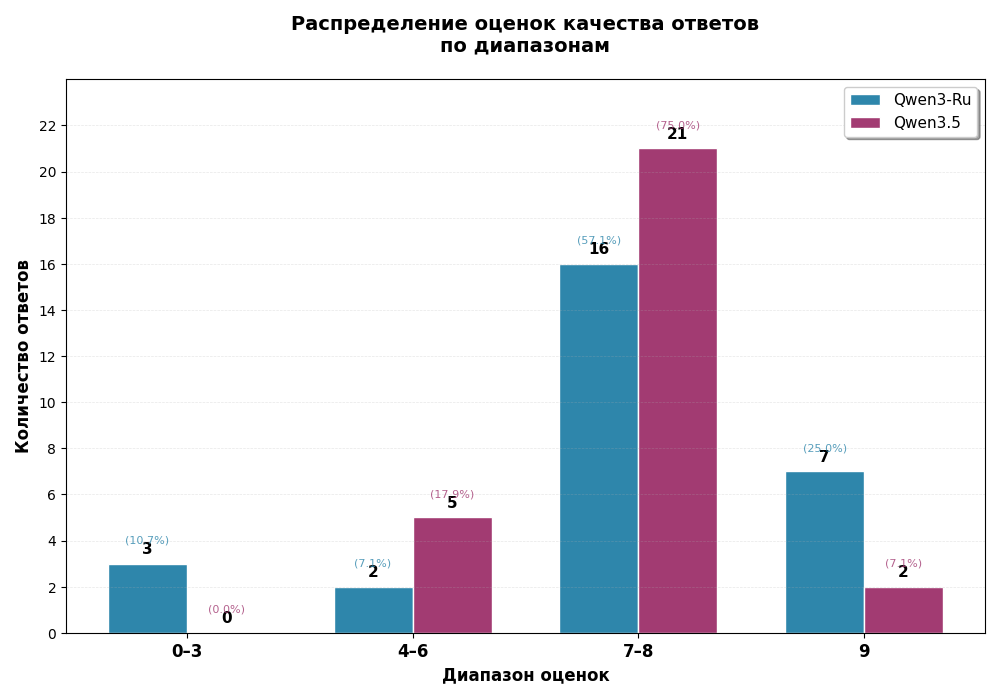
Рисунок 2 - Распределение оценок качества ответов по диапазонам
4. Обсуждение
Результаты показывают, что качество ответов напрямую зависит от сложности и структуры контекста
Наибольший прирост качества обеспечивают механизмы вызова инструментов и памяти диалога. Tools позволяют вынести часть вычислений за пределы языковой модели, повышая точность, особенно в задачах с фактами и числами. Память, в свою очередь, обеспечивает накопление релевантного контекста и согласованность ответов в многошаговых сценариях. Это указывает на то, что архитектурные решения (интеграция инструментов и управление состоянием) оказывают более сильное влияние, чем простое увеличение объёма контекста.
Сравнение моделей показывает, что Qwen3.5 обеспечивает более стабильные результаты и существенно более высокую вычислительную эффективность, несмотря на отсутствие языковой адаптации. При сопоставимом среднем качестве она демонстрирует меньшее количество ошибок и лучшее соотношение «качество/время». В целом, результаты подтверждают, что ключевым фактором повышения качества является не масштаб контекста, а эффективность его организации и использования.
5. Заключение
В нашей работе рассмотрена проблема повышения качества функционирования агентных систем на основе больших языковых моделей за счёт оптимизации контекста, подаваемого на этапе предсказания. Показано, что традиционный статический промпт-инжиниринг, ориентированный на подбор формулировок инструкций, обладает ограниченной эффективностью в прикладных задачах, требующих актуальных знаний, работы с внешними источниками и поддержания связности диалога. Обоснована необходимость перехода к динамической инженерии контекста — подходу, предполагающему структурированное извлечение, фильтрацию и композицию разнородных информационных компонентов (инструкций, внешних знаний, вызовов инструментов, промежуточных рассуждений, памяти и состояния) с учётом специфики информационного домена.
Предложена формальная постановка задачи оптимизации контекста как многокритериальной максимизации ожидаемого вознаграждения при ограничениях на длину контекста, объём доступных данных, вычислительные ресурсы и качество источников. В отличие от существующих работ, фокусирующихся на отдельных аспектах (RAG, память или инструменты), представленная формализация задаёт единую рамку для сравнения и комбинирования различных механизмов управления контекстом.
Полученные результаты подтверждают выдвинутую гипотезу: ключевым фактором эффективности LLM в прикладных задачах является не масштаб контекста сам по себе, а способ его организации, структурирования и интеграции с внешними инструментами и механизмами памяти. Это открывает перспективы для дальнейших исследований в области адаптивной композиции контекста, автоматического выбора наиболее релевантных информационных компонентов в зависимости от типа задачи, а также разработки гибридных архитектур, сочетающих преимущества инструментов, памяти и структурированных знаний в едином фреймворке динамической инженерии контекста.