Проектирование оптимальной структуры виртуальной организации с помощью алгоритмов кластеризации
Проектирование оптимальной структуры виртуальной организации с помощью алгоритмов кластеризации
Аннотация
Организационная структура виртуальной организации, как правило, динамична и изменяется в зависимости от набора задач, решаемых компанией. В статье исследуется задача определения оптимальной структуры виртуального предприятия методом выделения кластеров на множестве элементарных трудовых операций. Атрибуты, характеризующие эти операции зачастую измеряются по шкале категорий, то есть не могут быть выражены в числовом виде, поэтому для кластеризации предлагается использовать масштабируемые алгоритмы, основанные на оптимизации глобальной функции, к наиболее эффективным из подобных относится алгоритм CLOPE. Описана методика применения алгоритма для оптимизации распределения задач между подразделениями.
1. Введение
Иерархия целей организации определяется выбранными стратегическими целевыми установками, и реализуется методами, предусмотренными в миссии организации с учетом условий внешней среды . В результате анализа совокупности целей, стоящих перед организацией, формируется множество задач и элементарных трудовых операций, выполнение которых необходимо для достижения поставленных целей. Так как степень детализации целей определяется индивидуально для каждой задачи, будем считать элементарной операцию, которая может быть полностью решена отдельным исполнителем или рабочей группой без привлечения внешних ресурсов.
Многие исследователи сходятся в том, что сетевая модель взаимодействия субъектов экономики является одной из наиболее эффективных с точки зрения инновационного развития , , , . Структура сетевой, или виртуальной, организации динамична и каждый момент времени определяется тем набором задач, которые составляют «основание» иерархии целей и задач компании. Деятельность любого реального экономического субъекта состоит из большого количества слабосвязанных и разнородных задач и операций. В начале каждого производственного цикла виртуальная организация встает перед вопросом формирования структуры и распределения обязанностей между рабочими группами.
С одной стороны, создание отдельного подразделения для решения каждой элементарной задачи экономически нецелесообразно. С другой – наличие у подразделения большого количества не связанных между собой обязанностей обычно приводит к невозможности построить цельную пирамиду средне- и долгосрочных целей на уровне подразделений, и как следствие – к непониманию персоналом глобальной цели своих действий и снижению эффективности работы подразделения в целом. Поэтому эффективное распределение обязанностей между подразделениями позволяет оптимизировать структуру предприятия и повысить производительность как отдельных подразделений, так и организации в целом.
Таким образом, возникает необходимость оптимального распределения обязанностей, при котором минимизируется внешняя сцепленность и максимизируется внутренняя связность кластера задач, выполняемых каждым подразделением.
2. Методика оценки эффективности организации
Рассмотрим виртуальную организацию на этапе становления ее структуры. Допустим, в результате декомпозиции основных целей, с учетом миссии фирмы и условий внешней среды было выделено множество элементарных задач x, решение которых и составляет процесс функционирования предприятия.
Каждая элементарная задача может быть представлена в виде объекта x = {a1, a2,… am}, элементы которого ak – это параметры, характеризующие ключевые показатели задачи, такие как трудоемкость, предметная область, требования к исполнителям и т.д. Отметим, что число таких характеристик должно определяется индивидуально для каждой системы задач.
Проблема выделения ключевых параметров ak является довольно сложной и плохо формализуемой задачей. Наиболее эффективный способ ее решения, на наш взгляд, – использование экспертной оценки с целью определения наиболее значимых факторов, характеризующих процессы, лежащих в основе решения задачи. Мы выделили следующие категории характеристик, которые могут служить для описания процесса решения бизнес-задач:
– необходимые ресурсы (материальные, финансовые, интеллектуальные);
– методы и способы решения задачи;
– технологические средства решения задачи;
– область знаний, к которым относится задача;
– территориальное расположение места выполнения задачи;
– личностные особенности сотрудника, необходимые для решения задачи (методичность, коммуникативность, креативность) и т.д.
Введем основные показатели для оценки эффективности функционирования подразделений предприятия. Величина производственных издержек подразделения G(n, x1, x2… xn) является функцией числа n возложенных на подразделение задач и тех параметров ak, которые характеризуют ресурсы, необходимые для решения этих задач. При удачном сочетании обязанностей в подразделении наблюдается эффект синергии, выражаемый формулой
То есть одно крупное подразделение имеет меньшие издержки производства, чем несколько мелких подразделений, выполняющих те же задачи.
Доходность подразделения D(n, k1, k2, … kn) также определяется числом n выполняемых задач и показателями ki прибыльности задач.
Эффективность j-го подразделения можно определить следующим образом:
где – величина дисперсии задач подразделения.
Множитель H учитывает отрицательный эффект, который возникает в случае, когда на подразделение возлагается много разнородных задач. Этот эффект тем больше, чем дальше расположены друг от друга задачи подразделения в пространстве переменных ak. Эффективность организации в целом определяется как сумма
Таким образом, проблема проектирования наиболее эффективной структуры организации в предложенной модели сводится к максимизации функционала F.
3. Решение задачи оптимизации структуры
Сложность решения поставленной задачи заключается в определении аналитического вида функций Dj, Gj и Hj. Если для описания функций доходности и издержек существуют различные экономические модели, то построить аналитическую модель эффекта «распыления», который описывает функция Н, вряд ли возможно. Кроме того, задача осложняется тем, что переменными являются не только значения элементов ak объектов x, но и число n этих объектов.
Отметим, что из предложенного выше вида функции H следует, что она принимает наименьшее значение в том случае, когда задачи функционального подразделения максимально близки друг к другу в пространстве переменных ak. Следовательно, для нахождения наиболее выгодных для подразделения комбинаций, необходимо разделить множество элементарных задач x на компактные группы в соответствии с их характеристиками. Эта задача известна как задача кластеризации и методы ее решения достаточно хорошо изучены. В общем виде кластеризацию можно описать как объединение объектов в группы на основании их сходства по ряду признаков. На сегодняшний день известно несколько десятков алгоритмов кластеризации, работающих с разными типами характеристик объектов и по-разному трактующими понятие сходства.
Все атрибуты объектов можно разделить на числовые и категориальные . Иерархические методы кластеризации позволяют работать только с категориальными атрибутами. При этом проводится последовательное объединение объектов на основании равенства определенных признаков и соответственное уменьшение числа кластеров.
Большинство алгоритмов кластеризации числовых атрибутов основаны на оптимизации некоторой функции, определяющей степень близости объектов, входящих в кластер. Часто в качестве такой функции выступает расстояние от центра кластера до входящих в него объектов.
В рамках решения задачи оптимизации структуры используются одновременно и числовые, и категориальные характеристики задач. Например, возможны следующие конфигурации объектов, описывающих организацию со свойствами «сфера деятельности», «размер бизнеса» и «количество сотрудников»:
х1 = {торговля, средний, 120};
х2 = {образование, малый, 25}.
Если для оценки расстояния между этими объектами используется иерархический алгоритм с мерой сходства, нам необходимо привести значения атрибута «Количество сотрудников», измеренные по шкале отношений к порядковой шкале (т.е. дискредитировать атрибут). Например, так:
х1 = {торговля, средний, больше 100};
х2 = {образование, малый, меньше 100}.
Такая операция допустима, поскольку порядковая шкала слабее шкалы отношений, но при дискредитации всегда утрачивается часть информации об объекте. В данном случае мы потеряем сведения о точном числе сотрудников.
Если же использовать в качестве метрики евклидово расстояние, то возникают проблемы с категориальными атрибутами, поскольку перевод значений из слабой шкалы в более мощную недопустим. Дополнительную сложность создает потенциально различная степень важности атрибутов при принятии решения о группировке задач.
Наиболее перспективными механизмами кластеризации объектов со смешанными атрибутами нам представляются масштабируемые алгоритмы, оптимизирующие не локальные функции расстояния до центра кластера, а глобальную функцию. К этому типу относятся алгоритмы CLOPE , , LargeItem и др. Как правило, эффективность алгоритмов оценивается с использованием таких параметров как временная сложность и потребность в использовании памяти. Алгоритм CLOPE имеет временную сложность O(N*k), тогда как LargeItem – O(N*lnN). В остальном характеристики этих алгоритмов довольно похожи: оба являются нетребовательными к памяти, простыми в реализации, работают с произвольным количеством кластеров . Таким образом, именно алгоритм CLOPE представляется наиболее эффективным для решения задач кластеризации категориальных данных. Рассмотрим принцип его работы.
Например, нужно кластеризовать следующее множество объектов: x1={a, b}, x2={a, b, c}, x3={a, c, d}, x4={d, e}, x5={d, e, f}. Сравним два варианта разбиения:
1) {x1, x2, x3}; {x4, x5} и 2) {x1, x2}; {x3, x4, x5}.
Для первого и второго вариантов разбиения в каждом кластере рассчитаем количество вхождений в него каждого элемента и представим эти разбиения виде гистограмм .
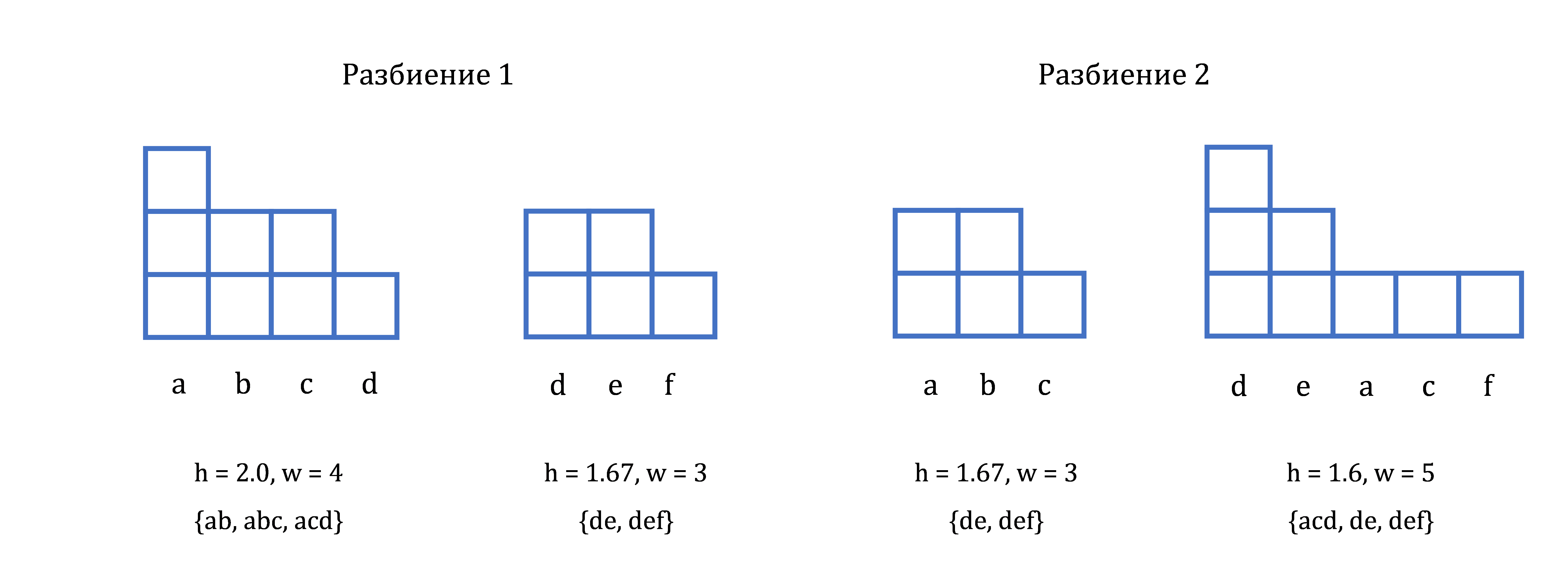
Рисунок 1 - Гистограммы разбиений исходного множества объектов
В том случае, если разные разбиения дают одинаковое значение h можно использовать дополнительный параметр сравнения – градиент g = h/w = s/w2. Чем выше показатель g(q), тем лучше разбиение q. Глобальная функция сходства p(q) может быть рассчитана по формуле:
где r – параметр отталкивания, который регулирует степень сходства объектов внутри кластера, r>1.
Итак, рассмотренный алгоритм дает возможность выделить кластеры схожих задач, после чего можно оптимизировать структуру организации путем определения отдельного функционального подразделения для решения каждой выделенной группы задач. Степень сходства задач в кластере можно регулировать изменяя параметр r : чем выше значение r, тем мельче будут кластеры и тем больше кластеров будет выделено.
4. Заключение
Таким образом, задача формирования оптимальной структуры виртуального предприятия была сведена нами к задаче выделения кластеров на множестве элементарным задач, решение которых необходимо для функционирования организации. Выбор атрибутов, характеризующих эти задачи, зависит от специфики деятельности организации, однако можно выделить ряд общих параметров, таких как необходимые ресурсы, методы и способы решения задачи, территориальное расположение и др. Поскольку большинство перечисленных параметров являются категориальными, для кластеризации предлагается использовать масштабируемые алгоритмы, наиболее эффективным из которых можно считать алгоритм CLOPE.
Отметим, что предложенный способ оптимизации структуры подходит для виртуальной организации любой отрасли. Конкретный вид структуры зависит от того, с какой степенью детализации будет выполнен анализ целей и задач на начальном этапе, а также от того по какому признаку будут сгруппированы полученные элементарные задачи. Так, если в качестве наиболее весомого параметра кластеризации выбрана принадлежность задачи к определенному бизнес-процессу, то выделенные подразделения могут рассматриваться как процессные команды и т.д.