ИССЛЕДОВАНИЕ И РАЗРАБОТКА МЕТОДОВ ТРАССИРОВКИ СОБЫТИЙ В ПАРАЛЛЕЛЬНЫХ И РАСПРЕДЕЛЕННЫХ СИСТЕМАХ

Кузичкина А.О.1, Косяков М.С.2
1Магистрант, Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, 2Кандидат технических наук, Доцент, Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики
ИССЛЕДОВАНИЕ И РАЗРАБОТКА МЕТОДОВ ТРАССИРОВКИ СОБЫТИЙ В ПАРАЛЛЕЛЬНЫХ И РАСПРЕДЕЛЕННЫХ СИСТЕМАХ
Аннотация
Работа посвящена проблеме поиска причин деградации производительности в параллельных и распределенных системах. Предложен и разработан метод трассировки событий, который помогает улучшить понимание поведения приложений и позволяет провести тщательный анализ производительности параллельных и распределенных систем. Для представления логической связи событий системы предложена модель корневого дерева. Так как логически связанные события могут выполняться в разных процессах/потоках, в работе продемонстрированы подходы реализации связывания событий при различных условиях. Предлагаемый метод трассировки подразумевает инструментирование исходного кода приложения для расстановки специальных меток, которые вызываются при наступлении соответствующих событий. В разработанной системе трассировки реализована возможность включать определённый набор меток, соответствующий интересующему сценарию работы анализируемого приложения. Метки можно включать и выключать «на лету» для работающего приложения, тем самым снижая влияние процесса трассировки на выполнение анализируемой системы. Для управления процессом трассировки и обработки полученных данных в работе реализованы соответствующие утилиты. Практическое использование разработанных методов и инструментов помогает в разработке предсказуемых и эффективных параллельных и распределенных систем и существенно упрощает поиск причин неудовлетворительной производительности.
Ключевые слова: распределенные системы, трассировка, дерево событий, инструментирование кода, анализ производительности.
Kuzichkina A.O.1, Kosiakov M.S.2
1Undergraduate Student, St. Petersburg National Research University of Information Technologies, Mechanics and Optics, 2PhD in Engineering, Associate Professor, St. Petersburg National Research University of Information Technologies, Mechanics and Optics
RESEARCH AND DEVELOPMENT OF TRACING EVENTS METHODS IN PARALLEL AND DISTRIBUTED SYSTEMS
Abstract
The paper is devoted to the problem of identifying the causes of performance degradation in parallel and distributed systems. We developed an event tracing method that helps to improve the understanding of the application behavior and allows conducting thorough analysis of the parallel and distributed systems performance. To represent the logical connection of system events, we offered a model of the root tree. Logically related events can be performed in different processes/threads. Thus, the work shows how to implement the binding of events under different conditions. Proposed method of tracing involves instrumentation of the application's source code for placing special labels which can be called when appropriate events occur. Developed system of tracing realizes the possibility to include a certain set of labels, corresponding to the interesting scenario of the analyzed application. Tags for a running application can be turned on and off “on the fly,” thereby reducing the impact of the trace process on the execution of the analyzed system. To manage the process of tracing and in order to process received data, corresponding utilities are implemented. Practical use of the developed methods and tools helps in the development of predictable and efficient parallel and distributed systems and greatly simplifies the search for causes of unsatisfactory performance.
Keywords: distributed systems, tracing, event tree, code instrumentation, performance analysis.
Современные приложения часто представляют собой сложные крупномасштабные распределенные системы. Такие системы состоят из различных программных компонентов, которые зачастую разрабатываются несколькими командами разработчиков, и могут быть развернуты на нескольких компьютерах [1, С. 9]. Программисту, который не принимает участие в создании сразу всех компонентов параллельной системы, очень трудно разобраться, как система работает, как компоненты взаимосвязаны и что за чем следует. Поверхностное понимание поведения параллельных и распределенных систем недостаточно для глубокого анализа и поиска причин проблем производительности.
Большой класс систем для поиска проблем производительности приложений составляют системы профилирования. Специальные программы, профилировщики, предоставляют данные, по которым можно определить, на выполнение каких функций ушло больше всего времени [2, С. 218]. Однако, данных, полученных при профилировании бывает недостаточно для выявления причин снижения производительности.
Часто для того, чтобы обнаружить причину потери производительности системы, требуется отследить цепочку выполняющихся событий и проанализировать распределения временных задержек между этими событиями. Такую задачу позволяют решать системы трассировки приложений. Известные авторам существующие системы трассировки имеют ряд недостатков:
1) зачастую они работают исключительно на транспортном уровне стека протоколов (X-Trace [3, С. 271]]);
2) не позволяют связать зависимые события между отдельными процессами (Magpie [4, С. 259]);
3) не поддерживают возможности ветвления событий (Pinpoint [5, С. 309]).
Целью работы является разработка метода трассировки событий в параллельных и распределенных системах. Трассировка событий существенно улучшает понимание поведения приложения и помогает выявить причины низкой производительности системы. Для достижения поставленной цели необходимо решить следующие задачи:
- выполнить инструментирование кода приложения;
- реализовать возможность управления процессом трассировки;
- разработать анализатор данных трассировки.
Поведение системы можно представить, как выполнение различных событий. Некоторые события связаны между собой логически, то есть одно событие может являться причиной возникновения другого события или же может породить несколько других независимых событий, которые могут выполняться последовательно или параллельно. Для представления логической связи событий выбрана модель корневого дерева [6, С. 214]. Узлами дерева являются события системы. Каждый узел имеет свой уникальный идентификатор PET (от англ. performance event tree tracing) и идентификатор родителя. В качестве примера представлена схема дерева (рис. 1). События B и D, изображённые на рисунке, являются взаимосвязанными, а события E, F, G – независимые и могут выполняться параллельно.
На основе предложенной модели дерева разработана система трассировки. Реализация и внедрение демонстрируется на примере параллельной распределенной системы алгоритмической торговли Tbricks компании Itiviti [7]. Чтобы отслеживать ход работы приложения, необходимо в коде приложения расставить специальные метки, которые будут вызываться при наступлении соответствующих событий. Используемый в системе трассировки механизм меток реализован в продукте LTTng компании EfficiOS [8].
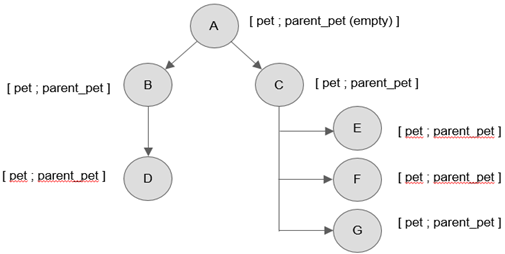
Рис. 1 – Схема дерева событий
Название метки имеет следующую структуру: «имя_сервиса:имя_метки», где под сервисом понимается компонент, в котором вызывается соответствующая метка. Для логического связывания меток между собой PET-идентификатор последней вызванной метки передается в следующую метку. PET-идентификаторы генерируются динамически во время выполнения приложения. В листинге 1 представлен макрос вызова метки.
Листинг 1 – Макрос вызова метки

Влияние трассировки на работающую систему.
Выбор событий, которые необходимо наблюдать при измерении производительности параллельного приложения, является важным фактором, поскольку это является основой для интерпретации данных о производительности. Следует отметить, что метки LTTng [8] можно включать и выключать "на лету" для запущенной системы. Накладные расходы на вызов метки составляет порядка нескольких десятков наносекунд. Если метки выключены, они не влияют на работающее приложение.
Примеры взаимосвязи событий.
Рассмотрим несколько случаев передачи PET-идентификатора. Если после вызова метки происходит вызов асинхронной функции, то есть происходит перекладка данных из одного потока в другой, нужно позаботиться о передаче PET-идентификатора в другой поток. В этом случае следует сохранить PET в передаваемом объекте. В листингах 2, 3.1 и 3.2 продемонстрирована реализация связывания меток, которые вызываются в разных потоках:
service_name:dispatch_event -> service_name:process_event.
Листинг 2 – Структура кода, описывающая блок данных, передаваемый из одного потока в другой

Листинг 3.1 – Функция, в которой вызывается метка перед передачей блока данных, извлеченного из полученного сообщения, в другой поток для обработки
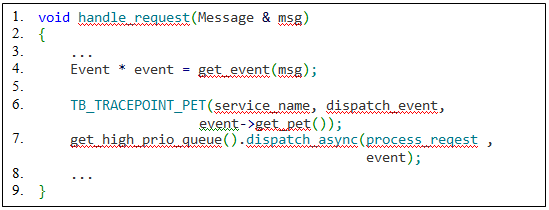
Листинг 3.2 – Функция, в которой обрабатывается блок данных и вызывается соответствующая метка
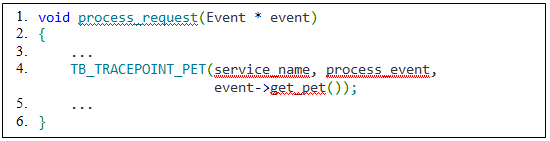
В случае, когда один сервис пересылает сообщение другому сервису, и метки в этих сервисах логически связаны, необходимо сохранить PET-идентификатор в сообщении перед отправкой. В листингах 4 и 5 продемонстрирована реализация связывания меток, которые вызываются в разных процессах:
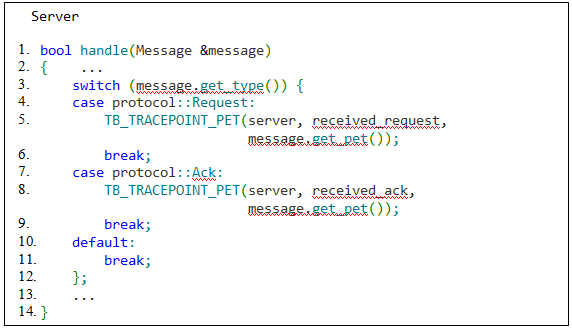
client:send_request -> server:received_request.
Листинг 4 – Функция клиента для отправки сообщения с запросом серверу и с вызовом соответствующей метки
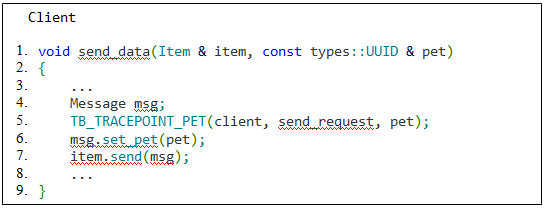
Листинг 5 – Функция сервера для обработки сообщения и с вызовом меток в соответствии с типом полученного сообщения
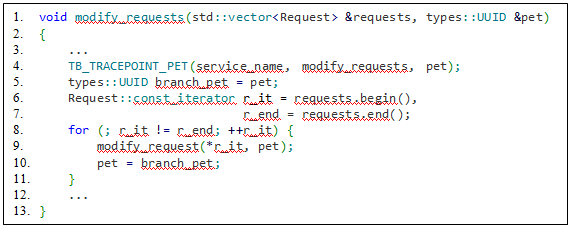
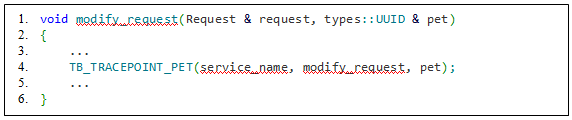
Рассмотрим случай, когда одно событие является родителем для нескольких дочерних, но дочерние события выполняются последовательно друг за другом. А значит время задержки на выполнение каждого дочернего события, начиная со второго, будет включать в себя задержку на выполнение всех предыдущих событий. По результатам замеров оказывается трудно определить, это проблема накапливания задержки или проблема в том, что событие выполняется долго. Решение этой ситуации пока не реализовано, но планируется в будущем для усовершенствования системы трассировки. Реализация подобного связывания событий продемонстрирована в листингах 6.1 и 6.2:
service_name:modify_requests -> service_name:modify_request
-> service_name:modify_request
-> service_name:modify_request
...
Листинг 6.1 – Функция модификации набора запросов
Листинг 6.2 – Функция модификации одного запроса с вызовом соответствующей метки
Управление процессом трассировки и анализ.
Для запуска трассировки была реализована соответствующая утилита на языке Perl. В качестве входных параметров указываются процессы приложения, для которых запускается трассировка, и набор активируемых меток.
Данные трассировки представляют собой список вызванных в ходе работы приложения меток с PET-идентификаторами и временем вызова. Для связывания событий, зафиксированных в ходе выполнения приложения, в деревья и расчёта перцентилей временных задержек между событиями на языке C++ реализован анализатор.
На рис. 2 представлен результат трассировки сценария работы алгоритмической системы Tbricks, в котором при получении с биржи котировок на ценные бумаги выполняется их обработка и на биржу отправляются обновлённые квоты.
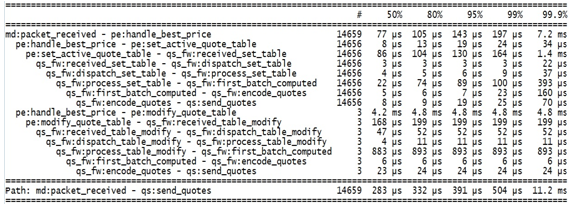
Рис. 2 – Распределение временных задержек между событиями системы алгоритмической торговли Tbricks
Представленные на рис. 2 результаты свидетельствуют о том, что в рассматриваемом сценарии работы алгоритмической системы Tbricks наибольший вклад в общую временную задержку вносят процедура обработки котировок (pe:handle_best_price – pe:modify_quote_table) и процедура обработки запроса на модификацию таблицы с квотами (qs_fw:process_table_modify – qs_fw:first_batch_computed).
Наличие системы трассировки позволяет настроить автоматические запуски процесса трассировки для приложения. Это позволяет отслеживать изменения производительности системы на всех этапах её разработки, вовремя обнаруживать проблемы и быстрее находить причины их возникновения. На рис. 3 изображён график изменения производительности для вышеописанного сценария работы системы алгоритмической торговли Tbricks, который был построен в программе Tableau [9].
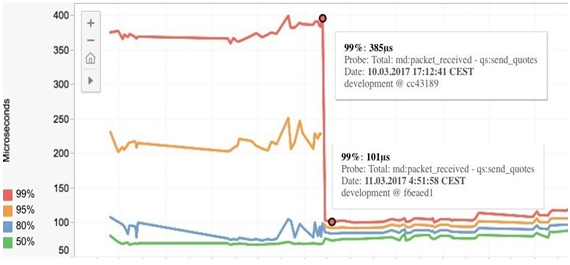
Рис. 3 – График изменения производительности сценария отправки квот в системе алгоритмической торговли Tbricks за месяц
Как видно из графика, изменения, сделанные 11 марта, существенно уменьшили задержку при отправке обновленных квот на биржу в ответ на полученные котировки.
Таким образом, в данной работе разработан метод трассировки событий в параллельных и распределенных системах. Предложенная модель корневого дерева позволяет представить логически связанные события системы и тем самым помогает понять сложное поведение распределенного приложения. Апробация предложенных подходов и разработанных инструментов проводилась на примере системы алгоритмической торговли Tbricks. Используемые LTTng метки для отслеживания выбранных событий системы можно включать и выключать «на лету» для работающего приложения, что позволяет снизить влияние трассировки на работу анализируемой системы. Продемонстрированы подходы реализации связывания событий в различных случаях. Для управления процессом трассировки и анализа полученных данных реализованы соответствующие утилиты. Применение предложенного метода трассировки событий позволяет проводить тщательный анализ работы параллельных и распределенных систем и существенно помогает при поиске причин проблем производительности в этих системах.
Авторы выражают признательность коллеге Осипову Е.В. за плодотворное сотрудничество по тематике работы и полезные замечания.
Список литературы / References
- Косяков М. С. Введение в распределенные вычисления / М. С. Косяков – Санкт-Петербург : НИУ ИТМО, 2014. – 155 с.
- Brendan Gregg. Systems Performance: Enterprise and the Cloud. First edition / Brendan Gregg. – Upper Saddle River (New Jersey): Prentice Hall, 2013. – 729 p.
- Fonseca R., Porter G., Katz R. H., Shenker S., Stoica I. X-Trace: A Pervasive Network Tracing Framework. / R. Fonseca, G. Porter, R. H. Katz, S. Shenker, I. Stoica // Proceedings of the 4th USENIX Symposium on Networked Systems Design and Implementation. – 2007. – P. 271–284.
- Barham P., Donnelly A., Isaacs R., Mortier R. Using Magpie for request extraction and workload modelling. / P. Barham, A. Donnelly, R. Isaacs, R. Mortier // Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation – 2004. – P. 259–272.
- Chen M. Y., Accardi A., Kiciman E., Lloyd J., Patterson D., Fox A., Brewer E. Path-based failure and evolution management. / M. Y. Chen, A. Accardi, E. Kiciman, J. Lloyd, D. Patterson, A. Fox, E. Brewer // Proceedings of the 1st USENIX Symposium on Networked Systems Design and Implementation. – 2004. – P. 309–322.
- Cormen T. H., Leiserson C. E., Rivest R. L. Introduction to Algorithms, 3rd Ed. / H. Cormen, C. E. Leiserson, R. L. Rivest // The MIT Press, 2009. – 1328 p.
- Официальный сайт компании Itiviti [Электронный ресурс] – URL: http://www.itiviti.com (дата обращения: 11.03.2017).
- Официальный сайт проекта LTTng фирмы EfficiOS: Документация [Электронный ресурс] – URL: http://lttng.org/docs/v2.9/ (дата обращения: 11.03.2017).
- Официальный сайт продукта для визуализации данных Tableau: Документация [Электронный ресурс] – URL: https://www.tableau.com/support/desktop (дата обращения: 11.03.2017).
Список литературы на английском языке / References in English
- Kosyakov M. S. Vvedenie v raspredelennye vychislenija [Introduction to distributed computing] / M. S. Kosyakov – Saint-Petersburg: ITMO University, 2014. – 155 p. [in Russian]
- Brendan Gregg. Systems Performance: Enterprise and the Cloud. First edition / Brendan Gregg. – Upper Saddle River (New Jersey): Prentice Hall, 2013. – 729 p.
- Fonseca R., Porter G., Katz R. H., Shenker S., Stoica I. X-Trace: A Pervasive Network Tracing Framework. / R. Fonseca, G. Porter, R. H. Katz, S. Shenker, I. Stoica // Proceedings of the 4th USENIX Symposium on Networked Systems Design and Implementation. – 2007. – P. 271–284.
- Barham P., Donnelly A., Isaacs R., Mortier R. Using Magpie for request extraction and workload modelling. / P. Barham, A. Donnelly, R. Isaacs, R. Mortier // Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation – 2004. – P. 259–272.
- Chen M. Y., Accardi A., Kiciman E., Lloyd J., Patterson D., Fox A., Brewer E. Path-based failure and evolution management. / M. Y. Chen, A. Accardi, E. Kiciman, J. Lloyd, D. Patterson, A. Fox, E. Brewer // Proceedings of the 1st USENIX Symposium on Networked Systems Design and Implementation. – 2004. – P. 309–322.
- Cormen T. H., Leiserson C. E., Rivest R. L. Introduction to Algorithms, 3rd Ed. / H. Cormen, C. E. Leiserson, R. L. Rivest // The MIT Press, 2009. – 1328 p.
- Oficial'nyj sajt kompanii Itiviti [Official website of the company Itiviti] [Electronic resource] – URL: http://www.itiviti.com (accessed: 11.03.2017). [in Russian]
- Oficial'nyj sajt proekta LTTng firmy EfficiOS [Official website of the project LTTng by EfficiOS: Documentation] [Electronic resource] – URL: http://lttng.org/docs/v2.9/ (accessed: 11.03.2017). [in Russian]
- Oficial'nyj sajt produkta dlja vizualizacii dannyh Tableau: Dokumentacija [Official website of the product for data visualization Tableau: Documentation] [Electronic resource] – URL: https://www.tableau.com/support/desktop (accessed: 11.03.2017). [in Russian]