МОРФОЛОГИЧЕСКИЙ И СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА НА ПЕРСИДСКОМ ЯЗЫКЕ С ПОМОЩЬЮ УСЛОВНЫХ СЛУЧАЙНЫХ ПОЛЕЙ

Резаиан Н.1, Новикова Г.М.2
1 Магистр кафедры информационных технологий, Российский Университет Дружбы Народов, 2 кандидат технических наук, Российский Университет Дружбы Народов
МОРФОЛОГИЧЕСКИЙ И СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА НА ПЕРСИДСКОМ ЯЗЫКЕ С ПОМОЩЬЮ УСЛОВНЫХ СЛУЧАЙНЫХ ПОЛЕЙ
Аннотация
В статье изложен подход к реализации морфологического и синтаксического анализа текста на персидском языке с применением метода условных случайных полей. Продемонстрирована корректность и эффективность данного подхода применительно к языку со свободным порядком слов в предложении. Выделены ключевые грамматические особенности языка, которые необходимо учитывать при создании подобной системы. Проанализированы результаты различных тематических групп персидских текстов на предмет корректного тегирования.
Ключевые слова: обработка естественного языка, метод условных случайных полей, скрытая модель Маркова, морфологический и синтаксический анализ.
Rezaeian N.1, Novikova G.M.2
1 Master of Information Technologies, Peoples’ Friendship University of Russia, 2 PhD in Engineering, Peoples’ Friendship University of Russia
MORPHOLOGICAL AND SYNTACTIC ANALYSIS OF PERSIAN TEXT WITH CONDITIONAL RANDOM FIELDS
Abstract
The article describes an approach to the implementation of the morphological and syntactic analysis of the text in Persian language using the method of conditional random fields. It demonstrates the correctness and effectiveness of this approach in relation to the language with a free word order in a sentence. Key grammatical features of the language that must be considered when creating such a system are highlighted. The results of various thematic groups of Persian texts for correct tagging were analysed.
Keywords: Natural Language Processing, Conditional Random Fields, Hidden Markov Model, Morphological and Syntactic analysis
Обработка естественного языка (NLP) является одним из важнейших и актуальных направлений в области синтеза искусственного интеллекта и математической лингвистики. Основные усилия здесь сосредоточены в поиске и совершенствовании подходов к анализу текста, выраженного естественным человеческим языком и возможностями компьютера «воспринимать» и перерабатывать эту информацию. Обработка естественного языка является задачей типа AI-полная задача, так как предполагает высокий уровень понимания окружающего мира и человеческих эмоций. Очевидно, что решение этих задач требует от исследователя знаний как в области лингвистики, так и в области искусственного интеллекта.
С приходом компьютерных технологий в жизнь человека тема обработки естественного языка стала интересовать многих ученых. Несмотря на полувековую историю самой проблематики и различных исследований в данной области, точкой отсчета для которых стало создание «машины Тьюринга», до сих пор не найдено удовлетворительного решения этой задачи. Большое количество исследований в данной области только подчеркивают значимость темы, поскольку создание подобной системы может стать ключом к формированию общего понятийного поля между человеком и машиной, а значит будет являться еще одним шагом в решении задачи их сближения.
Создание системы обработки текста на естественном языке дает платформу для решения сразу нескольких проблем. Смирнов И.В. в своей работе [1] выделяет три целевых блока, где возможно использование этих методов. Первый – анализ текста и информационный поиск (машинный перевод с одного языка на другой; системы, поддерживающие диалог с пользователем; поиск текстовой информации по запросу пользователя; извлечение информации из текстов; вопросно-ответные системы; автоматическое резюмирование; выявление заимствований и плагиата; кластеризация и классификация текстов; контентный анализ). Второй – синтез текстов, предполагающий автоматическую генерацию текстов с заданными характеристиками. Третий – естественно-языковое взаимодействие с компьютером (распознавание речи – перевод речи (звука) в текст, синтез речи – перевод текста в звук).
Количество научных исследований в этой области растет с каждым днем, усовершенствование методов обусловлено, в свою очередь, и наличием специфики национальных языков, что создает особую проблематику в реализации методов обработки естественного языка.
Специфика обработки естественного языка для персидских текстов
Процесс автоматической обработки текста неразрывно связан со структурными особенностями самого языка. Грамматический строй персидского языка может быть охарактеризован как флективно-аналитический, а синтаксис характеризуется относительно свободным порядком слов в предложении, что порождает ряд сложностей при создании системы автоматической обработки текста.
Мы выделили следующий перечень проблем и особенностей, с которыми может столкнуться исследователь при анализе персидского текста и которые важно учитывать как на этапе предварительной обработки, так и в ходе морфологического и синтаксического анализа: проблема индивидуальных различий в написании слова, проблема определения границ именной группы (так называемая изафетная конструкция), возможная потеря информации по причине различий в диалектах, проблема смысловой множественности (феномен омонимичности в персидских словах), проблема ошибочной пунктуации (полностью или частично искажающей смысловые значения), проблема сложных предикатов, проблема омографов (порождаемая, в частности, отсутствием в персидской письменности способа выражения кратких гласных «а», «о», «е» в середине слова), большое количество словоформ персидского глагола (спрягается по лицам и числам), особенности суффиксального образования множественного числа существительных, проблема притяжательных местоимений, выраженных с помощью изафетных цепей или местоименных энклитик.
Этапы предварительной обработки текста
Нормализация или графематический анализ представляет собой первичный этап автоматической обработки, решающий задачу трансформации входного текста в простую каноническую форму. Графематический анализатор выступает в роли, своего рода, текстового препроцессора, результатом работы которого должна стать линейная последовательность слов, включающая также элементы пунктуации. С его помощью происходит удаление нетекстовых символов, разделение цепочки символов на слова, выделение цифр, чисел, дат, неизменяемых оборотов и сокращений, деление на предложения и абзацы.
Многие исследователи, занимающиеся проблемой обработки естественного языка, зачастую даже не выделяют этот этап как самостоятельный, переходя сразу к этапу токенизации. В рамках решения наших задач нормализация текста представляет особое значение, так как по сегодняшний день в персидском языке не существует жестких норм правописания. Например, многие слова вариативны в чтении и написании, у различных авторов мы встречаем как раздельное, так и слитное написание предлогов и приставок, многие буквы, изначально предназначенные только для арабизмов, употребляются вопреки этимологии в исконных словах и т.п. В общей сложности, мы выделили 24 проблемы в процессе автоматической обработки текста на персидском языке, которые решает этап нормализации. Обозначим некоторые из них: приведение цифр в тексте к персидскому написанию, исправление арабских букв в персидских словах, исправление в датах точек на слеш, удаление избыточных пробелов (дополнительные пробелы в различных словоформах), удаление знаков буквенного удвоения, устранение каллиграфических особенностей написания текста (напр.: дополнительное тире внутри слова), удаление диакритических знаков.
В своей работе на этапе нормализации мы использовали метод регулярных выражений, позволивший создавать комбинации последовательностей любой сложности и, в целом, подойти к процессу реализации графематического анализа с большей гибкостью. В результате, мы получили выходной текст в виде цепочки последовательностей в единой форме.
Следующим этапом предварительной обработки текста является этап токенизации, предполагающий выделение базовых элементов текста (токенов), ограниченных с двух сторон разделительными символами, пробелами или знаками пунктуации. Элементами здесь выступают слова, числа, даты, сокращения, аббревиатуры, составные предлоги и т.д. Токенизация позволяет выделить дискретные единицы текста, являющиеся основой для дальнейшей работы на этапах морфологического и синтаксического анализа. В результате токенизации каждому элементу присваивается соответствующий тип: слово, число, дата, адрес и т.д.
Морфологический анализ (Part-Of-Speech Tagging)
Этап предварительной обработки текста позволяет получить исходный текст, пригодный для корректного проведения морфологического и синтаксического анализа. Следующим шагом в этой цепочке является стемминг, процесс нахождения основы слова, которая и в персидском языке необязательно совпадает с морфологическим корнем слова. По нашей оценке стемминг позволяет до 15% увеличить эффективность обработки текста на персидском языке. Технически этот этап предполагает удаление суффикса и приставки в персидских словах, что, правда, не всегда приводит к корректному результату. Чтобы избежать ошибочного определения основы слова, необходимо учитывать ряд грамматических особенностей, таких как, написание притяжательных местоимений с помощью изафетных цепей, совпадение суффикса с частью основы слова, различные позиции отрицательной частицы внутри глагола, особенности построения некоторых форм прошедшего времени глагола, полностью видоизменяющих начальную словоформу, соединительные буквы у существительных.
Методология решения этапа стемминга различна. Традиционные подходы предполагают использование базы данных суффиксов и приставок. Слабость этого метода в том, что эти морфемы могут совпадать с частью основы слова, и система автоматически будет их отсекать, создавая множественные ошибки при обработке текста. В соответствии с обозначенными проблемами в нашем решении этого этапа был использован алгоритм Kstemming, переработанный с учетом грамматических особенностей персидского языка. В алгоритм были добавлены различные словари персидского языка, такие как, словарь, содержащий все основы слов (за исключением глагольных форм), словарь особых форм глаголов и существительных единственного и множественного числа (инфикс), словарь с глагольными основами, словарь суффиксов и приставок.
Алгоритм работает по принципу деления слов на глагольные и неглагольные формы, задавая для них различную последовательность этапов обработки, описанных на рисунках 1 и 2.
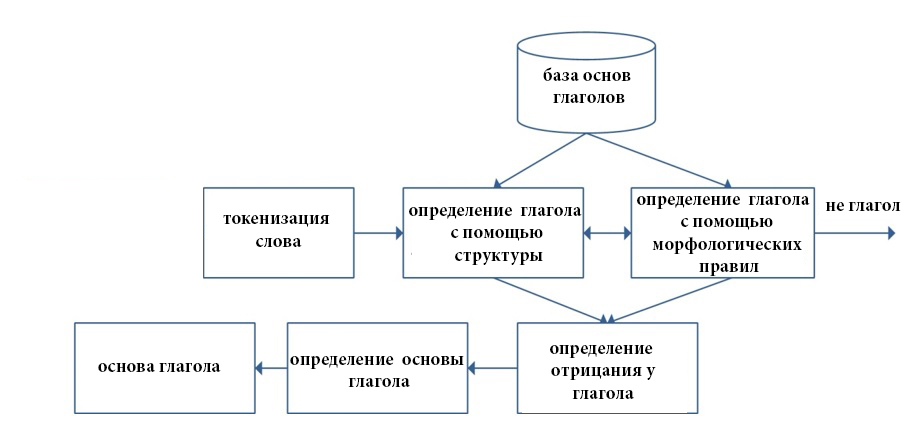
Рис. 1 – Определение основы глагола
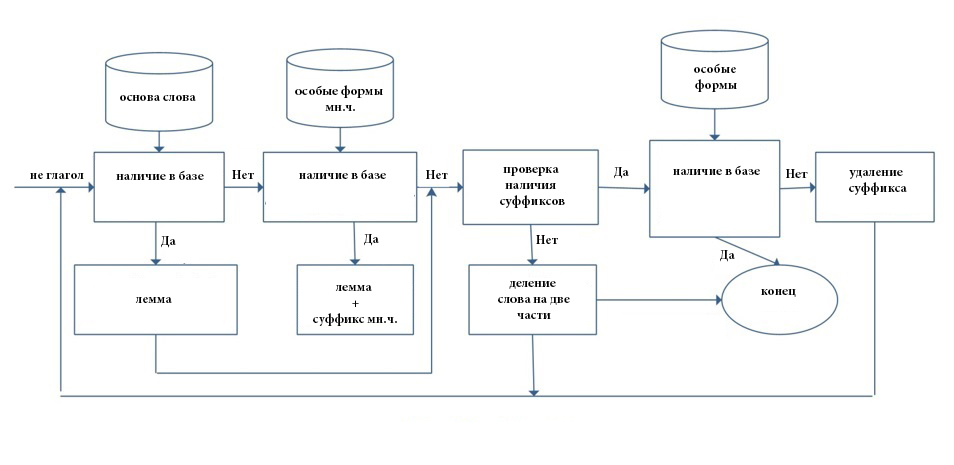
Рис. 2 – Определение основы не глагола
Этап морфологического анализа финализируется установлением морфологических признаков слов текста. Эта задача может рассматриваться как задача разметки или тегирования текста – установления тегов (морфологических признаков). Набор устанавливаемых признаков при этом непосредственно зависит от языка. В персидском языке, где отсутствуют грамматические падеж и род, часто ограничиваются установлением части речи.
Синтаксический анализ (Parsing)
Проблема синтаксического анализа текста является на сегодняшний день одной из наиболее актуальных в компьютерной лингвистике. Связано это с тем, что до сих пор не создано эффективного инструмента, как с точки зрения качественных показателей обработки текста, так и с точки зрения самого подхода для его проведения.
Задача синтаксического анализа состоит в описании синтаксической структуры предложения. В работе [2] выделяют две основные модели ее представления: структура зависимостей и структура непосредственно-составляющих. Использование той или иной модели определяется грамматическими особенностями самого языка. Так языкам с фиксированной последовательностью слов в предложении в большей степени релевантна вторая модель, а языкам с произвольным порядком слов, к каковым относится и персидский, первая. Именно поэтому в нашей работе мы использовали структуру зависимостей, основной принцип которой заключен в том, что в синтаксической связи всегда одно слово главное, а другое зависимое, что и определяет саму направленность этой связи. Как правило, синтаксическую структуру предложения представляют в виде дерева зависимостей, в узлах которого стоят слова, а ориентированные дуги между узлами в виде стрелок, отображаемых обычно над предложением, обозначают синтаксические зависимости.
Методологические решения этапов морфологического и синтаксического анализа при автоматической обработке текста были предложены исследователями в следующих моделях: скрытая модель Маркова (СММ), преобразование на основе обучения (Transformation/Rule-based tagger), система на основе памяти (Memory-based System), модель максимальной энтропии Маркова (ММЭМ).
Разработанные до сих пор системы синтаксического анализа, такие как Pattern Matching Parsing, Syntactic or grammer based Parsing и т.д., имеющие основной целью обработку текста на английском языке, не очень успешно работают при анализе персидских текстов. Отдельных законченных свободно распространяемых анализаторов персидского языка пока не так много. Ознакомившись с некоторыми из них, мы пришли к выводу, что эффективность таких анализаторов не очень высока. Во многом, на наш взгляд, это связано с выбором методов, не вполне удовлетворяющих решению самой задачи. В настоящей статье вводится понятие «условных случайных полей» (CRF) – структуры моделирования последовательности. Модель условных случайных полей является дискриминативной моделью, которая во многом имеет все преимущества ММЭМ, но при этом решает проблему смещения метки, суть которой обозначена в работе [3] как тенденция модели максимальной энтропии отдавать предпочтение тем скрытым состояниям, которые имеют меньшую энтропию распределения последующих состояний. Возможность применения в нашей работе метода условных случайных полей при создании системы автоматической обработки текста обусловлено появлением в недавнем времени корпуса на персидском языке, отсутствие которого ранее, при разработке анализаторов, не позволяло использовать данный метод. Рассмотрим подробнее схему работы самого алгоритма.
Метод условных случайных полей (CRF)
Метод условных случайных полей относится к статистическим методам классификации, позволяющим анализировать «контекст» классифицируемого объекта. Одним из главных достоинств этой модели является то, что она не требует моделировать вероятностные зависимости между так называемыми наблюдаемыми переменными.
Общая модель условного случайного поля
Определение 1. Для любой случайной величины ![]() его множеством соседей ∂i называется множество смежных с
его множеством соседей ∂i называется множество смежных с ![]() вершин:
вершин: ![]() . Таким образом, многомерная случайная величина V и система зависимостей её компонент образуют ненаправленный граф G = (V, E).
. Таким образом, многомерная случайная величина V и система зависимостей её компонент образуют ненаправленный граф G = (V, E).
Определение 2. Пусть G = (V, E) — неориентированный граф с множеством вершин V и множеством ребер E. Набор случайных величин ![]() образует Марковское случайное поле (Markov Random Field, MRF) по отношению к G, если выполнены следующие условия
образует Марковское случайное поле (Markov Random Field, MRF) по отношению к G, если выполнены следующие условия
Определение 3. Полный подграф графа G называется кликой. Пусть ![]() — клика, а
— клика, а ![]() — ограничение реализации
— ограничение реализации ![]() на
на ![]() , то есть
, то есть ![]() , где
, где ![]() . Пусть
. Пусть ![]() — это множество всех клик графа G = (V, E). Определим функцию-фактор Ψc (vc) как некоторую функцию
— это множество всех клик графа G = (V, E). Определим функцию-фактор Ψc (vc) как некоторую функцию ![]()
Определение 4. Дискретное распределение называется распределением Гиббса [1], если ![]() , где Z — нормирующая константа, называемая статистической суммой, такая что:
, где Z — нормирующая константа, называемая статистической суммой, такая что: ![]()
Определение 5. Условным случайным полем (УСП) (Conditional Random Field, CRF) называется MRF, у которого множество вершин разбито на два непересекающихся множества ![]() , где X и Y — множества наблюдаемых и скрытых переменных соответственно. Всюду далее мы будем использовать следующее обозначение
, где X и Y — множества наблюдаемых и скрытых переменных соответственно. Всюду далее мы будем использовать следующее обозначение ![]() и
и ![]() . Также мы будем предполагать, что значения случайных величин из x и y принадлежат некоторым конечным пространствам
. Также мы будем предполагать, что значения случайных величин из x и y принадлежат некоторым конечным пространствам ![]() и
и ![]() соответственно. Задача предсказания состоит в том, чтобы оптимальным образом восстановить значения y, при условии, что нам даны наблюдаемые x. Таким образом, в соответствии с теоремой Хаммерслея-Клиффорда нужно максимизировать
соответственно. Задача предсказания состоит в том, чтобы оптимальным образом восстановить значения y, при условии, что нам даны наблюдаемые x. Таким образом, в соответствии с теоремой Хаммерслея-Клиффорда нужно максимизировать ![]() , где
, где ![]() — статистическая сумма. Функции-факторы
— статистическая сумма. Функции-факторы ![]() в подавляющем большинстве случаев является экспонентой от линейной комбинации некоторых признаков с весами, которые нужно определить в процессе обучения:
в подавляющем большинстве случаев является экспонентой от линейной комбинации некоторых признаков с весами, которые нужно определить в процессе обучения: ![]() . Стоит также отметить, что наиболее трудоемкой в смысле вычислительной сложности является задача оценки статистической суммы Z(x), так как количество слагаемых в ней растет экспоненциально по размеру x. Поэтому в общем случае при вариационном выводе и на этапе обучения Z(x) не вычисляют точно, а лишь приблизительно оценивают [4].
. Стоит также отметить, что наиболее трудоемкой в смысле вычислительной сложности является задача оценки статистической суммы Z(x), так как количество слагаемых в ней растет экспоненциально по размеру x. Поэтому в общем случае при вариационном выводе и на этапе обучения Z(x) не вычисляют точно, а лишь приблизительно оценивают [4].
Вычислительный эксперимент
На этапе обучения условных случайных полей нами был использован корпус на персидском языке (Дадеган), содержащий десять миллионов слов. Помимо морфологического и синтаксического тегирования данный корпус включает в себя также тегирование по темам, что позволяет нам не только реализовать этапы морфологического и синтаксического анализа автоматической обработки текста, но также и протестировать гибкость нашей модели при обработке текстов различных тематических групп.
В общей сложности корпус насчитывает 60 различных тем. На этапе эксперимента нами было выбрано пять из них: спорт, политика, история, наука, литература. Каждая тема насчитывает 200 предложений, которые, в свою очередь, состоят из 25 слов. Итого, каждая тематика насчитывает 5 000 слов.
Результаты эксперимента описаны в таблице № 1.
Таблица 1
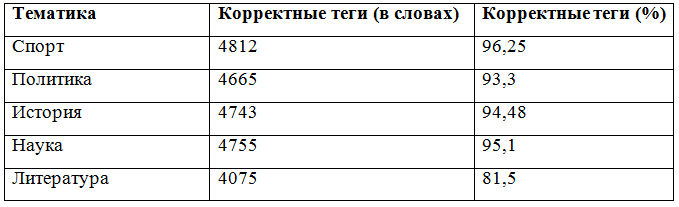
Как видно из данных, обозначенных в таблице, результаты, полученные при обработке текстов с тегом «литература» ниже, чем у других категорий. На наш взгляд, это связано с переизбытком в литературных текстах всевозможных риторических фигур: метафоричности, метонимии, фразеологизмов, гиперболизации и т.д. А использование в таких текстах авторской грамматики и авторской структуры литературной фразы зачастую идет вразрез со стандартной грамматической формой предложения.
Заключение
В статье нами было дано описание разработанной системы морфологического и синтаксического анализа текста на персидском языке с помощью условных случайных полей. Существование аналогичных анализаторов на других языках на практике показало их непригодность в работе с персидскими текстами, что объясняется отсутствием их грамматической адаптации. В работе было выделено несколько «узких мест», в частности, обозначена важность этапа нормализации при обработке текста, по причине отсутствия до сих пор четких норм правописания на персидском языке. Этот шаг позволил минимизировать ряд возможных ошибок, возникающих на последующих этапах работы с текстом.
Одной из целей исследования было тестирование нашей системы на предмет ее гибкости в работе с текстами различных тематических групп. Анализ показал снижение результатов только в теме с тегом «литература», что обусловлено особенностями построения подобных текстов и наличия в них большого количества риторических фигур. Для получения более высоких результатов при обработке подобных тематических категорий необходимо увеличение корпуса текстов. Показатели с другими тематическими тегами очень близки друг к другу. Корректность тегов в процессе морфологического анализа при использовании метода условных случайных полей составила – 97,1%, в процессе синтаксического анализа – 89,6%.
Таким образом, данный подход можно рассматривать в качестве единой универсальной системы в части обработки текстов на персидском языке различных тематических групп и дающей высокие показатели корректной обработки в процессе морфологического и синтаксического анализа.
Литература
- Смирнов И.В. Введение в анализ естественных языков : учебно-методическое пособие –Москва РУДН,2014-85 с.
- Антонова А.Ю., Соловьев А.Н. Метод условных случайных полей в задачах обработки русскоязычных текстов. «Информационные технологии и системы — 2013», Калининград, 2013.
- Charles Sutton, Andrew McCallum An introduction to Conditional Random Fields
- Романенко А.А. Применение условных случайных полей в задачах обработки текстов на естественном языке.
- Смирнов И.В., Шелманов А.О. Семантико-синтаксический анализ естественных языков
- Statistical Method for NLP, Maximum Entropy Markov Model, Sammer Maskey, March 2010
- Jinho D. Choi, Joel Tetreault, Amanda Stent It Depends: Dependency Parser Comparison Using A Web-based Evaluation Tool. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 2015
- Dependency Parsing, Sandra dubler, Rayan McDonald, Joakim Nivre
- Michael Collins Log-Linear Models And Long-Linear Tagiing Models
- Lafferty J., McCallum A., Pereira F. «Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data». Proceedings of the 18th International Conference on Machine Learning. 282-289. 2001
- The CoNLL-2009 shared task: Syntactic and semantic dependencies in multiple languages / Jan Hajic, Massimiliano Ciaramita, Richard Johansson et al. // Proceedings of the Thirteenth Conference on Computational Natural Language Learning: Shared Task / Association for Computational Linguistics. - 2009.
References
- Smirnov I.V. Vvedenie v analiz estestvennyh jazykov : uchebno-metodicheskoe posobie –Moskva RUDN,2014-85 s.
- Antonova A.Ju., Solov'ev A.N. Metod uslovnyh sluchajnyh polej v zadachah obrabotki russkojazychnyh tekstov. «Informacionnye tehnologii i sistemy — 2013», Kaliningrad, 2013.
- Charles Sutton, Andrew McCallum An introduction to Conditional Random Fields
- Romanenko A.A. Primenenie uslovnyh sluchajnyh polej v zadachah obrabotki tekstov na estestvennom jazyke.
- Smirnov I.V., Shelmanov A.O. Semantiko-sintaksicheskij analiz estestvennyh jazykov
- Statistical Method for NLP, Maximum Entropy Markov Model, Sammer Maskey, March 2010
- Jinho D. Choi, Joel Tetreault, Amanda Stent It Depends: Dependency Parser Comparison Using A Web-based Evaluation Tool. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 2015
- Dependency Parsing, Sandra dubler, Rayan McDonald, Joakim Nivre
- Michael Collins Log-Linear Models And Long-Linear Tagiing Models
- Lafferty J., McCallum A., Pereira F. «Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data». Proceedings of the 18th International Conference on Machine Learning. 282-289. 2001
- The CoNLL-2009 shared task: Syntactic and semantic dependencies in multiple languages / Jan Hajic, Massimiliano Ciaramita, Richard Johansson et al. // Proceedings of the Thirteenth Conference on Computational Natural Language Learning: Shared Task / Association for Computational Linguistics. - 2009