АВТОМАТИЗАЦИЯ ПОИСКА ОШИБОК В СИСТЕМАХ ДИСПЕТЧЕРСКОГО КОНТРОЛЯ ЖЕЛЕЗНЫХ ДОРОГ

Кавин Б.В.1, Фомин В.В.2
1 Аспирант кафедры информационных систем и программного обеспечения, ФГБОУ ВПО «Российский государственный педагогический университет им.А.И. Герцена», Санкт-Петербург, 2 Доктор технических наук, профессор кафедры информационных систем и программного обеспечения, ФГБОУ ВПО «Российский государственный педагогический университет им.А.И. Герцена», Санкт-Петербург
АВТОМАТИЗАЦИЯ ПОИСКА ОШИБОК В СИСТЕМАХ ДИСПЕТЧЕРСКОГО КОНТРОЛЯ ЖЕЛЕЗНЫХ ДОРОГ
Аннотация
Рассматривается структура, специфика и особенности организации и эксплуатации автоматизированного диспетчерского контроля железных дорог России. Раскрываются проблемы человеческого фактора и обработки информации из-за недостоверности данных. Предлагаются решения по обнаружению ошибок в накопленных банках данных на базе детерминированных алгоритмов. Определяются пути применения методов интеллектуального анализа.
Ключевые слова: мониторинг, диспетчерский контроль, программное обеспечение, интеллектуальный анализ данных.
Kavin В.V.1, Fomin V.V. 2
1 Postgraduate student of the chair of information systems and software, Herzen State Pedagogical University of Russia, Saint Petersburg, 2 PhD in Engineering, professor, Professor of the chair of information systems and software, Herzen State Pedagogical University of Russia, Saint Petersburg
AUTOMATION OF FINDING BUGS IN THE SYSTEMS OF SUPERVISORY CONTROL OF RAILWAYS
Abstract
We consider the structure, specificity and characteristics of the organization and operation of the automated dispatch control of Russian railways. Reveals the problems of the human factor and processing of unreliable data. We offer solutions for the detection of errors in the accumulated data banks on the basis of deterministic algorithms. Defined ways of using mining techniques.
Keywords: monitoring, supervisory control, software, data mining.
Для мониторинга состояния устройств железнодорожной автоматики и телемеханики на железных дорогах России используются аппаратно-программные комплексы диспетчерского контроля КДК (системы мониторинга), состоящие из трёх уровней:
- Считывание, оцифровка, первичная обработка информации и передача данных с технических устройств с использованием контроллеров (нижний уровень).
- Сбор, хранение, архивация данных, формирование информационного фонда, управление банками данных (средний уровень).
- Экспертно-аналитическая поддержка мониторинга, в том числе анализ, документирование, визуализация и индикация состояний технических устройств (верхний уровень).
Огромное количество объектов слежения, их разнообразие и особенность считывания информации, допускают значительное число «ручных» операций начального ввода данных, особенно по объектам, у которых не предусмотрены средства автоматического контроля. Базы данных формируются человеком и могут содержать неправильно введенные данные, в том числе ошибочной кодировки устройства и характеристики.
С отдельных территорий (станций) сформированная информация передаётся в пакетном режиме на центральный сервер (средний уровень) диспетчерского контроля. В центральной базе данных хранятся события об объектах, устройствах, неисправностях и формируется информационный фонд. Информационный фонд контроля постоянно накапливает приходящую информацию и представляет собой большое хранилище разнородных данных.
Технологические процедуры КДК предусматривают инструмент настройки визуализации, отображения результатов мониторинга через различные виды индикаций (рисунок 1). Чтобы отследить неисправность устройства, инженер должен привязать к соответствующему событию объекта в базе данных необходимую индикацию в пульте. Так как количество объектов и возможных событий очень велико, одной из проблем является «ручная» привязка событий к объектам и индикациям. Инженер может не привязать нужное событие к индикации, привязать не к тому объекту, привязать не к той индикации.
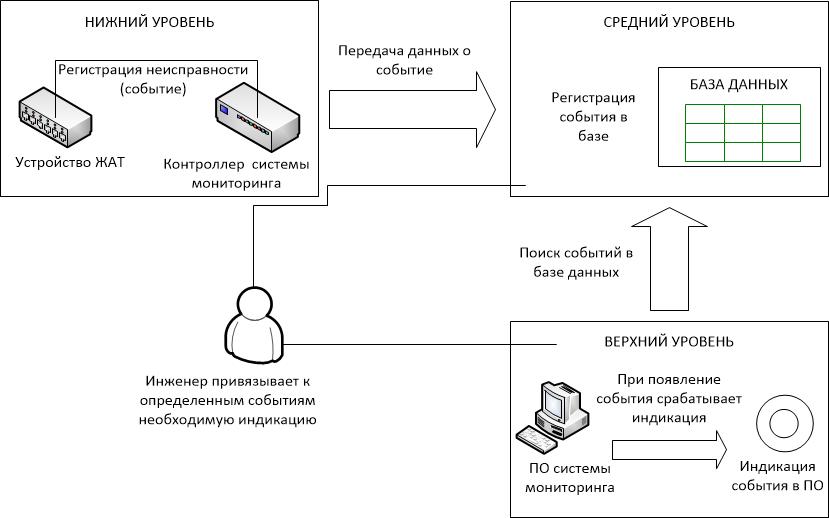
Рисунок 1. Схема привязок.
Реалии автоматизации мониторинга состояния устройств, поставили на первый план решение проблемы поиска, локализация и исправление ошибок привязки и индикации в накопленных данных.
Для решения проблемы была разработана программа (рисунок 2), которая сканирует базу данных на среднем уровне и выявляет возможные ошибки на основании шаблонов и правил, формируемых аналитиком. На вход в программу подаются база данных и правила поиска ошибок, описанные в виде кода на языке С#. Результатом работы программы являются таблицы с информацией о кол-ве ошибок и детализацией каждой ошибки.
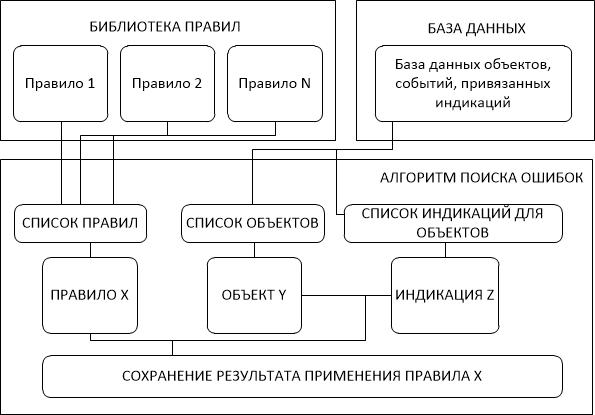
Рисунок 2. Схема работы алгоритма поиска ошибок.
Алгоритм загружает список правил из библиотеки правил, список объектов и привязанных индикаций из таблиц в базе данных. Затем последовательно проверяет, соблюдается ли правило Х для индикаций Z объекта Y, и в случае нарушения правила сохраняет информацию о возможной ошибке. В результате алгоритм группирует ошибки по станциям (области действия алгоритма) и выводит пользователю (рисунок 3).
Окно отображения результата поиска ошибок разделено на четыре блока:
1 – Вывод общей информации о количестве просканированных станций и количестве найденных ошибок.
2 – Вывод информации о названии станции и количестве найденных ошибок.
3 – Вывод информации о найденных ошибках для выделенной станции.
4 – Вывод детальной информации о выделенной ошибке.
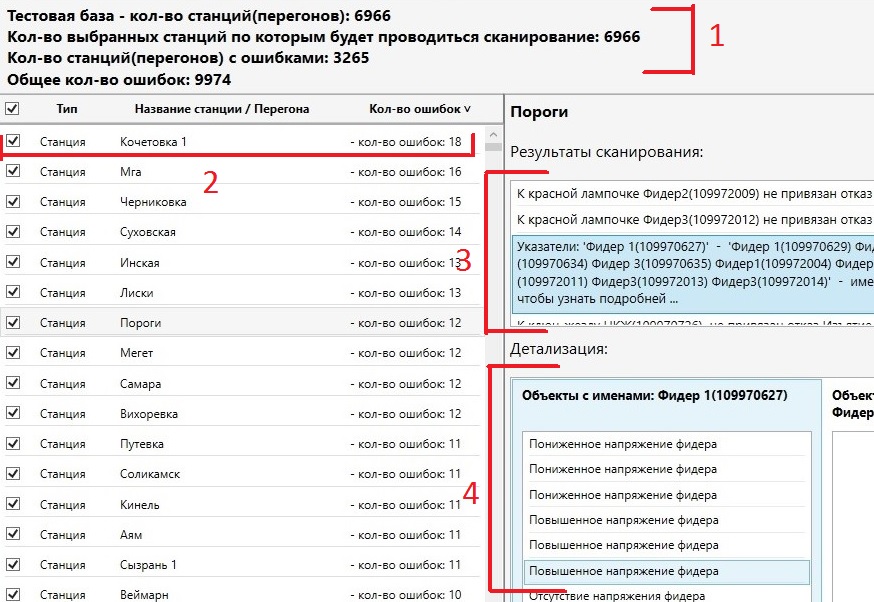
Рисунок 3. Окно вывода результата работы алгоритма.
Правила поиска объединены в библиотеку правил. Каждое правило имеет текстовое описание и алгоритм работы. Все правила реализуют общие интерфейсы и способны без дополнительного кода встраиваться в библиотеку и исполняемый код.
Пример правила:
// Сканирование светофоров // 1. Все объекты с типом 2 (светофоры) и именем '1' или '2' (предвходные) должны иметь одинаковый список отказов. // 2. Всеостальныесветофорыдолжныиметьодинаковыйсписокотказов.
foreach (DataRow traffic in dt_objects.Select("ids =" + stance.id + " and type = 2")) { if ((string)traffic["name"] == "2" || (string)traffic["name"] == "1")
{enters.Add(get_situation(traffic)); }
else {lights.Add(get_situation(traffic));}
}
В таблице 1 представлены результаты практического применения программы поиска ошибок на реальных дорогах по пяти правилам.
Таблица 1. Результаты запуска алгоритма для 5 правил.
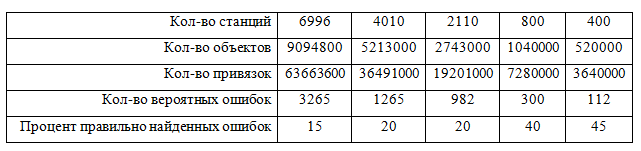
Полученные результаты выявили следующие проблемы:
- Процент правильно найденных ошибок увеличивается с уменьшением кол-ва сканируемых станций (область действия алгоритма). Проблема связана с тем, что к разным группам станций нужно писать разные правила и чем меньше групп мы сканируем, тем больше процент корректности результатов.
- Кол-во найденных ошибок слишком мало и на практике мы смогли покрыть только 5-10% от общего числа содержащихся ошибок.
Исследование причин неточности алгоритма говорит о том, что «вручную» написанные правила поиска ошибок не дают необходимой эффективности.
Существует два варианта решения этой проблемы:
- Постоянное пополнение, изменение и расширение библиотеки правил, что является трудоемкой работой и опять с учётом ненадёжного человеческого фактора.
- Применение методов интеллектуального анализа данных для автоматического построения библиотеки правил [4].
Применение методов интеллектуального анализа данных [1,5] обусловлено практикой эффективного применения методов кластеризации и классификации в разнородных, слабоструктурированных данных в различных областях человеческой деятельности [3]. Высокий потенциал алгоритмов интеллектуального анализа раскрывается при обработке больших объёмов информации с применением технологий big-data и internet [2].
Для поиска ошибок в базе данных все объекты необходимо разделить на группы согласно основным признакам (тип, имя, расположение объекта и т.д.), т.е. классифицировать. Для каждого класса объектов найти наиболее часто встречающийся набор характеристик и принять эту последовательность за шаблон класса.
В качестве основных признаков объекта выделим следующие характеристики:
- Имя – текстовое значение, кратко описывающее объект. Может быть любым, но обычно, в рамках класса, соответствует некоторому регулярному выражению.
- Тип объекта – числовое значение, соответствующее одному из заданных устройств.
- Расположение объекта - числовое значение, соответствующее одному из возможных расположений объекта.
- Неисправности – числовое значение неисправности объекта. Каждый объект может иметь любое кол-во неисправностей.
- Индикация неисправностей - числовое значение, соответствующее коду индикации для неисправности, определяет отображение заданной неисправности объекта на пульте диспетчера. Каждая неисправность имеет свою индикацию.
- Шаблон класса. У объекта каждого класса должны быть одни и те же неисправности и индикации неисправностей, т.е. определённый набор характеристик. Наиболее часто встречающийся набор таких характеристик (например, у 90% объектов класса) определяется шаблоном объекта.
Задачей алгоритма интеллектуального анализа является поиск вероятных ошибок в базе объектов, с максимальным значением правильных предположений.
Литература
- Дюк В.А., Фомин В.В. Интеллектуальный анализ данных в гуманитарных областях // Программные продукты и системы. 2008. № 3. С. 60-62.
- Сикулер Д.В., Фомин В.В. Концепция internet-системы интеллектуальной обработки данных. В сборнике: Некоторые актуальные проблемы современной математики и математического образования материалы LXIV научной конференции. СПб.: БАН, 2011. С. 206-209.
- Фомин В.В., Миклуш В.А. Интеллектуальные информационные системы. Санкт-Петербург, 2013. 150 с.
- Фомина И.К. Решение проблем, связанных со сложной системотехнической структурой предметных областей при интеллектуальном анализе данных // Журнал университета водных коммуникаций. № 2. С. 180-184.
- Флегонтов А.В., Дюк В.А., Фомина И.К. Мягкие знания и нечеткая системология гуманитарных областей // Программные продукты и системы. 2008. № 3. С. 97-102
References
- Djuk V.A., Fomin V.V. Intellektual'nyj analiz dannyh v gumanitarnyh oblastjah // Programmnye produkty i sistemy. 2008. № 3. S. 60-62.
- Sikuler D.V., Fomin V.V. Koncepcija internet-sistemy intellektual'noj obrabotki dannyh. V sbornike: Nekotorye aktual'nye problemy sovremennoj matematiki i matematicheskogo obrazovanija materialy LXIV nauchnoj konferencii. SPb.: BAN, 2011. S. 206-209.
- Fomin V.V., Miklush V.A. Intellektual'nye informacionnye sistemy. Sankt-Peterburg, 2013. 150 s.
- Fomina I.K. Reshenie problem, svjazannyh so slozhnoj sistemotehnicheskoj strukturoj predmetnyh oblastej pri intellektual'nom analize dannyh // Zhurnal universiteta vodnyh kommunikacij. 2009. № 2. S. 180-184.
- Flegontov A.V., Djuk V.A., Fomina I.K. Mjagkie znanija i nechetkaja sistemologija gumanitarnyh oblastej // Programmnye produkty i sistemy. 2008. № 3. S. 97-102