Методы визуального представления больших данных с использованием Plotly и Matplotlib
Методы визуального представления больших данных с использованием Plotly и Matplotlib

Аннотация
В статье рассматривается комплексный подход к визуализации статистических данных в среде Jupyter Notebook. Особое внимание уделяется анализу современных методов графического представления информации, выбору оптимальных инструментов и библиотек, а также когнитивным особенностям восприятия визуализаций. Показаны преимущества интеграции Plotly и Matplotlib для создания как статических, так и интерактивных графиков, рассмотрены вопросы оптимизации работы с большими массивами данных и применения параллельных вычислений. Продемонстрирована практическая значимость использования Jupyter Notebook для анализа, документирования и представления данных в образовательной, научной и бизнес-среде. Перспективы исследования связаны с внедрением методов машинного обучения и облачных сервисов для автоматизации выбора оптимальных визуализаций и расширения возможностей коллективной работы.
1. Введение
Современный цифровой мир характеризуется беспрецедентным ростом объемов генерируемых данных, что создает актуальную потребность в разработке эффективных методов их визуального представления. Грамотная визуализация статистических данных не только помогает выявить скрытые закономерности и взаимосвязи, но и значительно облегчает процесс аналитики, делая сложную информацию доступной для восприятия различными категориями пользователей. Однако многие существующие подходы к визуализации зачастую не учитывают когнитивные особенности человеческого восприятия информации, что может приводить к серьезным искажениям передаваемой информации и принятию ошибочных решений на ее основе.
Основной целью представленного исследования является разработка комплексного методологического подхода к визуальному представлению статистических данных в среде Jupyter Notebook. Данный подход включает многогранный анализ существующих методов визуализации с точки зрения их эффективности и наглядности, разработку оптимизированных цветовых схем и композиционных решений, создание интерактивных элементов для углубленного анализа данных, а также формулирование практических рекомендаций по выбору типа визуализации в зависимости от специфики данных и решаемых аналитических задач.
Jupyter Notebook представляет собой современную интерактивную веб-среду для работы с кодом и данными, которая открывает принципиально новые возможности для создания динамических и интерактивных визуализаций , . Его уникальность заключается в эффективном сочетании вычислительной мощности языков программирования (преимущественно Python) с интуитивно понятным интерфейсом, что делает данную платформу идеальным решением для исследовательской работы с данными различной сложности и объема.
2. Анализ современных методов визуализации статистических данных
Визуальное представление данных играет ключевую роль в современной аналитике, существенно облегчая процесс понимания и анализа сложных информационных массивов. Среди наиболее значимых преимуществ грамотной визуализации можно выделить несколько фундаментальных аспектов. Во-первых, она значительно упрощает восприятие сложной информации, преобразуя абстрактные числовые данные в наглядные графические образы
, . Во-вторых, визуализация позволяет мгновенно выявлять важные тенденции и закономерности, которые часто остаются незамеченными при работе с табличными представлениями данных. В-третьих, она обеспечивает эффективную поддержку процесса принятия решений. В-четвертых, качественная визуализация повышает вовлеченность аудитории, делая презентации и отчеты более интересными и запоминающимися. И наконец, она кардинально упрощает анализ больших данных, позволяя выявлять скрытые паттерны в огромных массивах информации.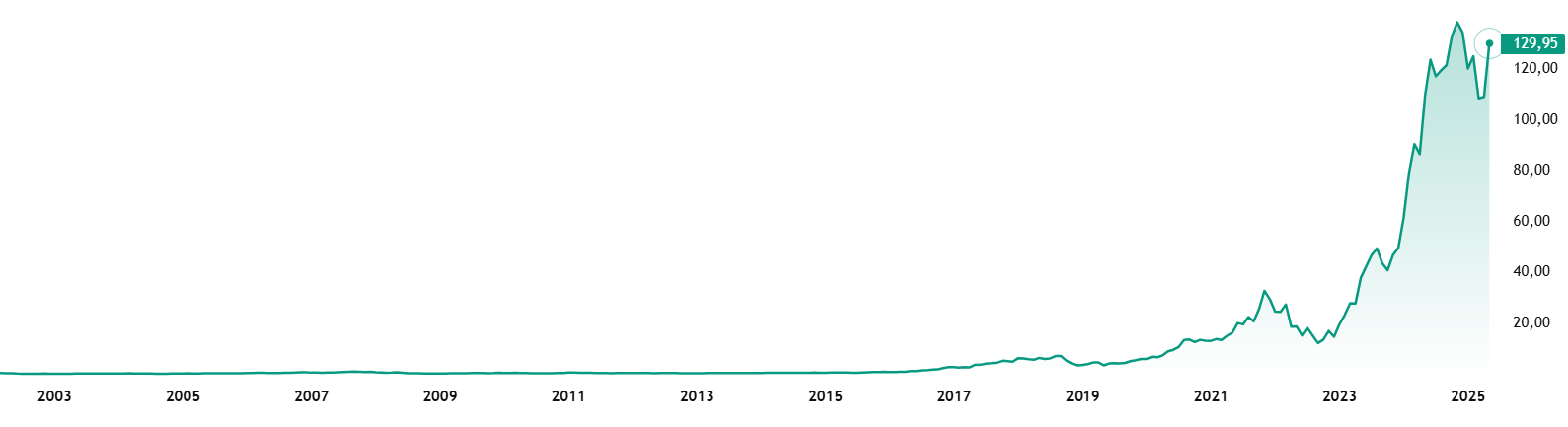
Рисунок 1 - Рост акций компании NVIDIA Corporation
Традиционно популярный Excel, несмотря на свою распространенность и привычный интерфейс, показывает серьезные ограничения при работе с большими объемами данных. При превышении порога в 600000 записей проявляются существенные проблемы: экспоненциальный рост времени обработки операций, частые сбои и зависания при выполнении фильтрации и агрегации данных, а также принципиальная невозможность построения сложных многоуровневых визуализаций. Эти ограничения делают Excel малопригодным для современной работы с большими данными, где требуются производительные и надежные инструменты анализа.
3. Принципы эффективной визуализации в Jupyter Notebook
Разработка эффективных визуализаций в Jupyter Notebook требует соблюдения ряда фундаментальных принципов, основанных на особенностях человеческого восприятия и когнитивной психологии. Логика визуализации должна начинаться с четкого определения цели — какой основной месседж необходимо донести до аудитории. Данные должны быть организованы таким образом, чтобы подчеркивать ключевые аспекты и выявлять наиболее важные закономерности, обеспечивая последовательное и логичное повествование
.Выбор цветовой палитры является критически важным аспектом эффективной визуализации. Цвета оказывают значительное влияние на восприятие информации и должны использоваться осмысленно и последовательно. Общепринятой практикой является использование зеленого цвета для обозначения положительных аспектов и красного — для отрицательных, однако важно учитывать культурные особенности целевой аудитории. Необходимо придерживаться единой цветовой схемы во всех элементах визуализации, чтобы избежать путаницы и обеспечить целостность восприятия. Правильное использование цвета может значительно улучшить наглядность и эффективность представления информации, в то время как неправильный выбор цветов может привести к серьезным искажениям восприятия и ошибочным выводам
, .
Рисунок 2 - Читаемость текста от расстояния
Рисунок 3 - Пример сложной визуализации
Рисунок 4 - Пример простой визуализаци
4. Функционал Jupyter Notebook: библиотеки Plotly и Matplotlib
Процесс работы в Jupyter Notebook начинается с загрузки данных из различных источников: CSV-файлов, таблиц Excel, баз данных SQL/PostgreSQL или веб-API. После загрузки данные проходят этапы очистки, преобразования и анализа с использованием специализированных библиотек, а конечным этапом является визуализация результатов для наглядного представления выявленных закономерностей
.Библиотека Plotly — это современный инструмент для интерактивной визуализации данных, который гармонично интегрируется в аналитический рабочий процесс Jupyter. Ключевое преимущество – возможность динамического взаимодействия с графиками непосредственно в ячейках, что значительно ускоряет исследовательский процесс. В отличие от статических решений, Plotly позволяет менять масштаб, скрывать/показывать элементы и выделять участки графиков, что особенно ценно при работе со сложными статистическими зависимостями (листинг 1, рис. 5).
Листинг 1. Код для построения линейного графика
1import numpy as np
2import plotly.express as px
3
4x = np.arange(0, 5, 0.1)
5
6def f(x):
7 return x**2
8
9px.scatter(x=x, y=f(x)).show()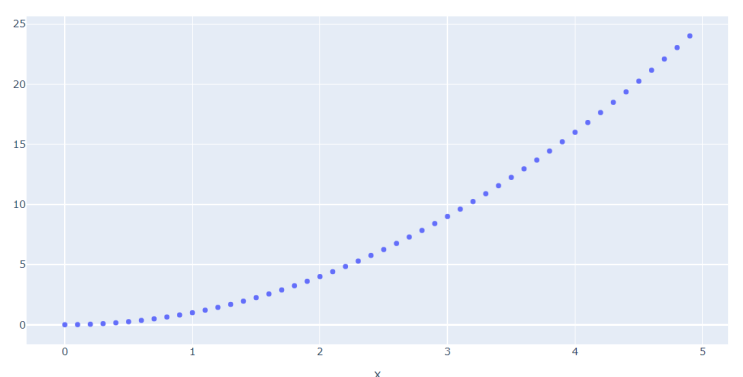
Рисунок 5 - Линейный график
Листинг 2. Код для построения сложного линейного графика
1import plotly.graph_objects as go
2
3fig = go.Figure()
4
5fig.add_trace(go.Scatter(x=x, y=f(x), mode='lines+markers', name='f(x)=x<sup>2</sup>'))
6fig.add_trace(go.Scatter(x=x, y=g(x), mode='markers', name='$g(x)=x$'))
7
8fig.update_layout(legend_orientation='h',legend=dict(x=.5, xanchor="center"),margin=dict(l=0,r=0,t=0,b=0))fig.update_traces(hoverinfo='x+y', r=0, t=0, b=0)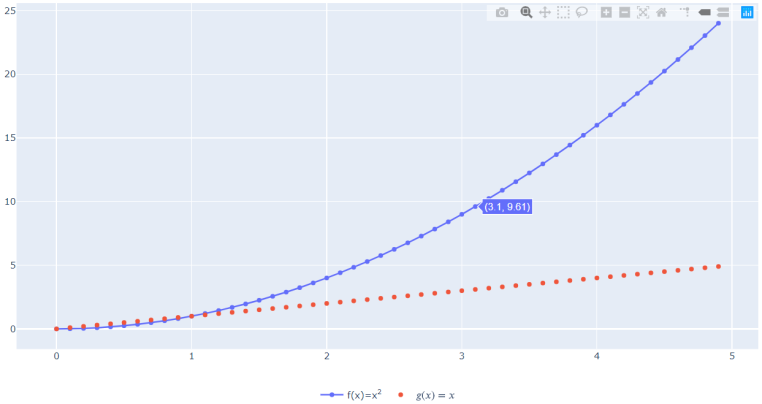
Рисунок 6 - Сложный интерактивный график
Листинг 3. Код для построения сложного линейного графика
1import plotly.graph_objects as go
2
3fig = go.Figure()
4fig.add_trace(go.Scatter(x=[x[0]], y=[f(x)[0]], mode='lines+markers', name='f(x)=x<sup>2</sup>'))
5frames = []
6for i in range(1, len(x)):
7 frames.append(go.Frame(data=[go.Scatter(x=x[:i+1], y=f(x[:i+1]))]))
8fig.frames = frames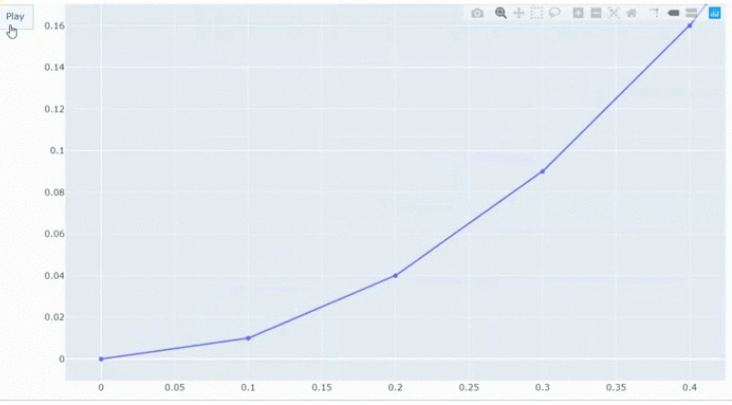
Рисунок 7 - Начальный фрейм
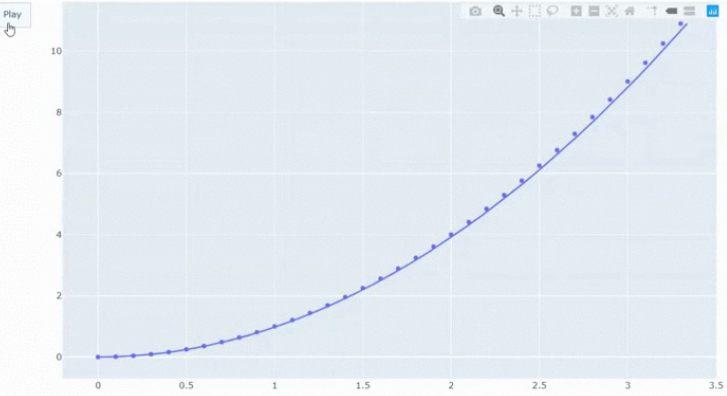
Рисунок 8 - Конечный фрейм
Листинг 4. Код для построения графика с исп. Seabon
1import pandas as pd
2import seaborn as sns
3import matplotlib.pyplot as plt
4
5# Import Data
6df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot.csv')
7df_select = df.loc[df.cyl.isin([4, 8]), :]
8
9# Plot
10sns.set_style("white")
11gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,
12 height=7, aspect=1.6, robust=True, palette="tab10",
13 scatter_kws=dict(s=60, linewidths=0.7, edgecolors='black'))
14
15# Decorations
16gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
17plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
18plt.show()Данный подход позволяет наглядно оценить различия в характере зависимостей между анализируемыми переменными для разных групп наблюдений, выявить аномальные значения, а также сравнить углы наклона регрессионных прямых (рис. 9).
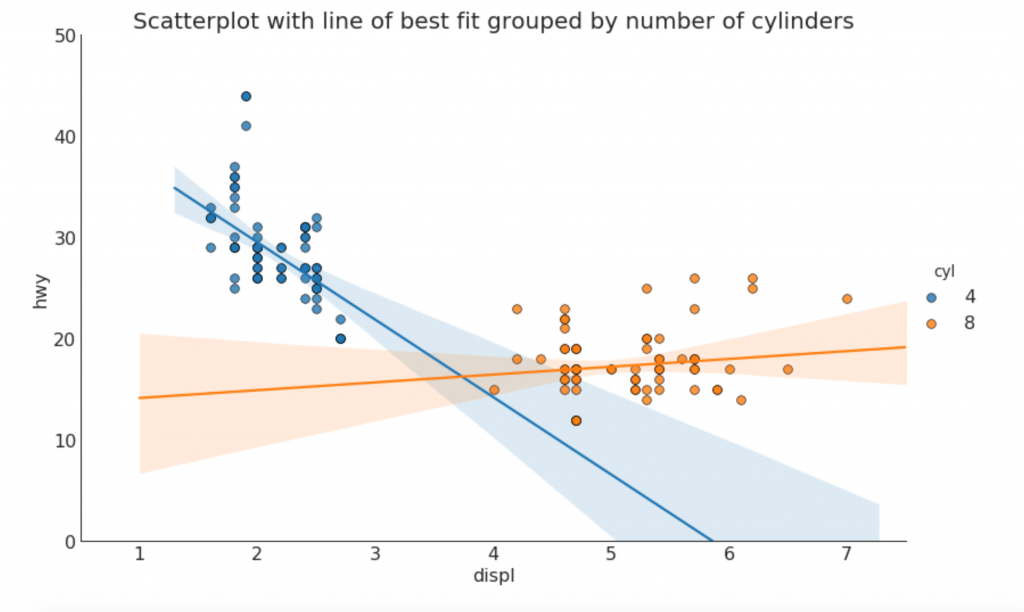
Рисунок 9 - График с использованием Seabon
Листинг 5. Код для подготовки данных
1import pandas as pd
2
3# Загрузка данных
4df_raw = pd.read_csv('https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv')
5df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
6df.reset_index(inplace=True)После подготовки данных можно приступить к построению гистограммы с использованием Matplotlib. Создается фигура и оси, после чего добавляется гистограмма с помощью метода bar (листинг 6, 7; рис. 10, 11).
Листинг 6. Код для подготовки визуализации
1import matplotlib.pyplot as plt
2import matplotlib.patches as patches
3
4# Создание фигуры и осей
5fig, ax = plt.subplots(figsize=(16, 8), facecolor='White', dpi=80)
6
7# Вертикальные линии
8ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=2)
9
10# Аннотация текста
11for i, cty in enumerate(df.cty):
12 ax.text(i, cty+0.5, round(cty, 1), horizontalalignment='center')
13
14# Настройка заголовка, меток и тиков
15ax.set_title('Bar Chart for Highway Mileage', fontdict={'size': 22})
16ax.set_ylabel('Miles Per Gallon', y=0.8)
17ax.set_xticks(df.index)
18ax.set_xticklabels(df.manufacturer.str.upper(), rotation=60, horizontalalignment='center')Листинг 7. Добавление цветовых патчей
1import matplotlib.pyplot as plt
2import matplotlib.patches as patches
3
4# Добавление цветовых патчей
5p1 = patches.Rectangle((0.57, -0.005), width=0.33, height=0.13, alpha=0.1, facecolor='green')
6p2 = patches.Rectangle((1.124, -0.005), width=0.446, height=0.1, alpha=0.1, facecolor='green')
7
8fig.add_artist(p1)
9fig.add_artist(p2)
10
11# Отображение графика
12plt.show()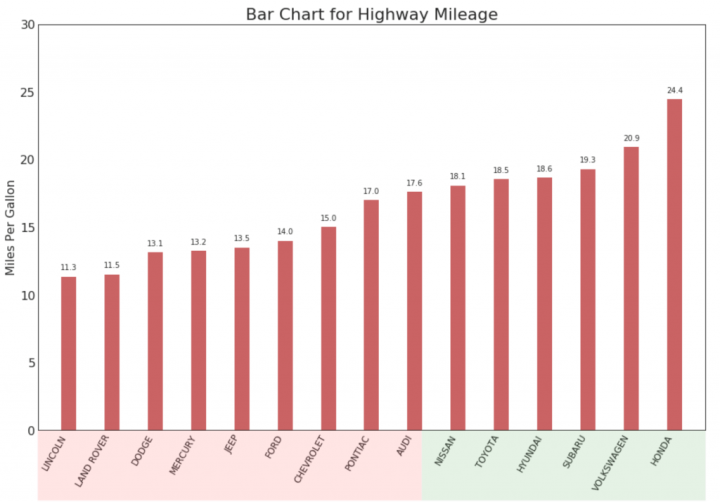
Рисунок 10 - Упорядоченная гистограмма
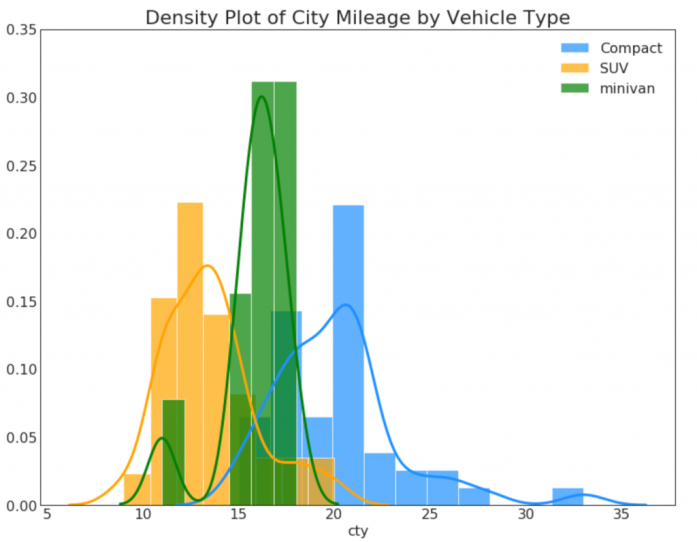
Рисунок 11 - Комбинированный график
5. Оптимизация работы с данными и визуализация больших массивов
Оптимизация работы с данными критически важна для повышения продуктивности, особенно при анализе больших наборов данных. Масштабируемость в Data Science напрямую связана с возможностью параллельной обработки данных, что позволяет распределять нагрузку между несколькими ядрами процессора.
В языке Python для параллельных вычислений обычно используется модуль multiprocessing, однако в Jupyter Notebook его применение нередко вызывает затруднения из-за конфликтов при управлении дочерними процессами. В таких случаях удобной альтернативой является библиотека Joblib, которая обеспечивает параллельное выполнение задач за счёт фоновых процессов, работающих независимо от основного процесса Jupyter
, .Для демонстрации анализа задач с длительным временем выполнения можно использовать алгоритмы с высокой временной сложностью, такие как «monkey sort» (или «bogosort») — крайне неэффективный метод сортировки. Алгоритм проверяет, отсортирован ли массив; если нет, случайным образом перемешивает элементы до достижения отсортированного порядка.
Средняя временная сложность составляет O((n+1)!) из-за вероятностной природы алгоритма, что означает факториальное количество операций для сортировки массива из n элементов. Фактическое время выполнения может варьироваться из-за случайного характера перемешивания
, .После загрузки необходимых библиотек реализуем алгоритм «monkey sort» на Python (листинг 8).
Листинг 8. Код алгоритма monkey sort
1import random
2
3def bogosort(arr):
4 def correct(arr, comparator=lambda x: x):
5 for i in range(1, len(arr)):
6 if comparator(arr[i - 1]) - comparator(arr[i]) > 0:
7 return False
8 return True
9
10 while not correct(arr):
11 random.shuffle(arr)
12 return arrДля проведения тестирования гипотез и анализа данных требуется создание набора тестовых данных. В данном исследовании генерируется двумерный массив, содержащий 1000 наборов данных, каждый из которых включает 8 случайно расположенных целочисленных значений (листинг 9).
Листинг 9. Набор тестовых данных
1import numpy as np
2# Создание массива случайных чисел
3bigdata = np.array([[np.random.randint(0, 100) for _ in range(1000)] for _ in range(1000)])
4
5# Вывод первых 5 элементов
6print(bigdata[:5])
7
8array([[24, 77, 45, 37, 47, 52, 80, 95],
9 [53, 40, 81, 24, 12, 20, 80, 42],
10 [34, 58, 90, 41, 85, 87, 80, 41],
11 [86, 17, 18, 60, 72, 89, 48, 28],
12 [ 1, 38, 44, 12, 97, 46, 52, 52]])Проверить работу алгоритма можно на этом наборе данных, для учета времени используем встроенную функцию Python%%time (рис. 12).
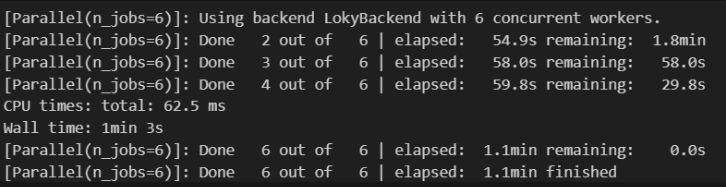
Рисунок 12 - Проверка результатов времени сортировки без параллелизма
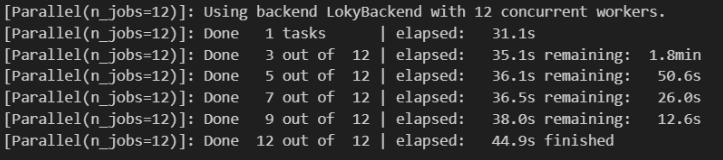
Рисунок 13 - Проверка результатов времени сортировки с параллелизмом
6. Визуализация больших данных в Jupyter Notebook
Рисунок 14 - Фрагмент файла Excel
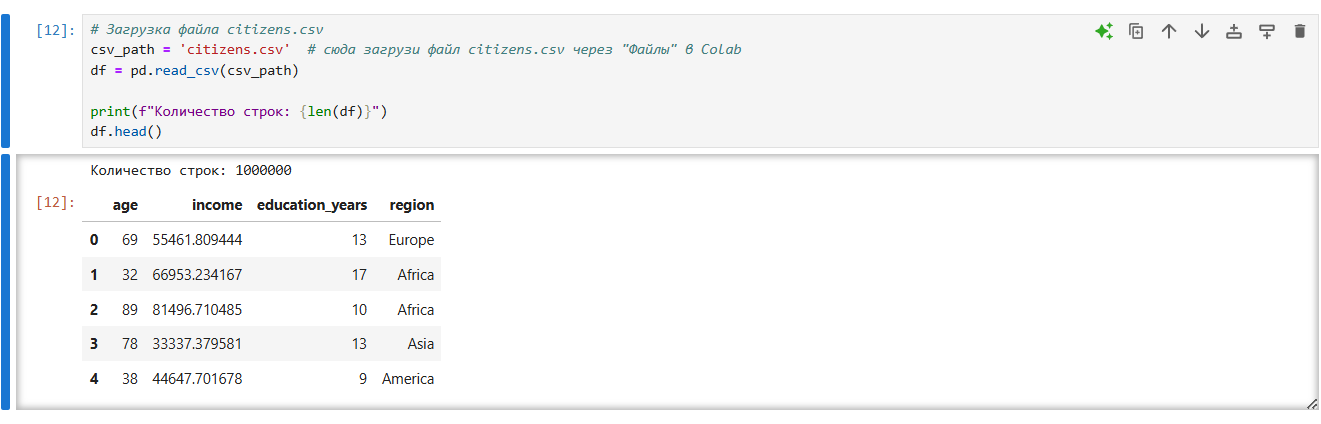
Рисунок 15 - Вывод неполной информации с файла Excel
Листинг 10. Подключение к PostgreSQL в Jupyter notebook
1import numpy as np
2
3# Подключение к PostgreSQL из Python
4
5[:] : !pip install psycopg2-binary
6from sqlalchemy import create_engine
7import pandas as pd
8
9# Создаем подключение
10engine = create_engine('postgresql://postgres:password@localhost:5432/citizen_db')Листинг 11. Подключение к PostgreSQL в Jupyter notebook.
1#Загрузка данных в PostgreSQL
2[:] : # Загрузка данных в базу данных (таблица citizens)
3df.to_sql('citizens', engine, if_exists='replace', index=False)В результате обработки данных удалось успешно построить график распределения возрастов, включающий все 1 миллион элементов. Процесс обработки и создания графика (рис. 16) занял всего одну минуту реального времени, что демонстрирует эффективность используемых методов и инструментов для работы с большими объемами данных.
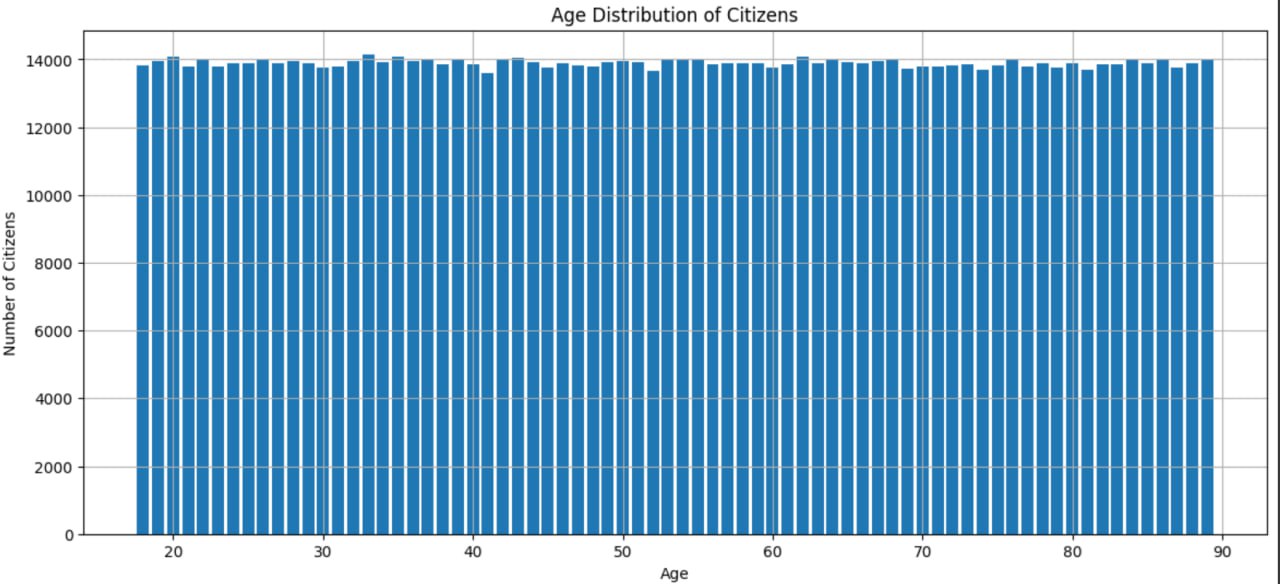
Рисунок 16 - График распределения возрастов
С помощью SQL-запроса были извлечены данные о возрасте, уровне образования и среднем доходе из таблицы citizens. Запрос включал группировку данных по возрасту и уровню образования, а также вычисление среднего дохода для каждой группы (листинг 12).
Листинг 12. Извлечение данных
1import plotly.graph_objects as go
2query = """
3SELECT age, education_years, AVG(income) as avg_income
4FROM citizens
5GROUP BY age, education_years
6"""
7df_3d = pd.read_sql(query, engine)Для визуализации данных был использован модуль plotly.graph_objects, который позволяет создавать интерактивные графики. В частности, был создан 3D-график рассеяния, где по осям X, Y и Z отображаются возраст, уровень образования и средний доход соответственно (листинг 13).
Листинг 13. Код для построения 3D графика
1df_3d = pd.read_sql(query, engine)
2
3fig = go.Figure(data=[go.Scatter3d(
4 x=df_3d['age'],
5 y=df_3d['education_years'],
6 z=df_3d['avg_income'],
7 mode='markers',
8 marker=dict(size=2)
9)])
10
11fig.update_layout(scene=dict(
12 xaxis_title='Age',
13 yaxis_title='Education Years',
14 zaxis_title='Average Income'),
15 margin=dict(l=0, r=0, b=0, t=0))
16
17fig.show()3D-график, отображающий распределение данных о возрасте, уровне образования и среднем доходе. График позволяет наглядно оценить взаимосвязь между этими параметрами и выявить возможные закономерности и тенденции. Использование интерактивных возможностей Plotly позволяет исследователям динамически взаимодействовать с графиком, изменяя угол обзора и масштаб, что значительно облегчает процесс анализа и интерпретации данных (рис. 17).
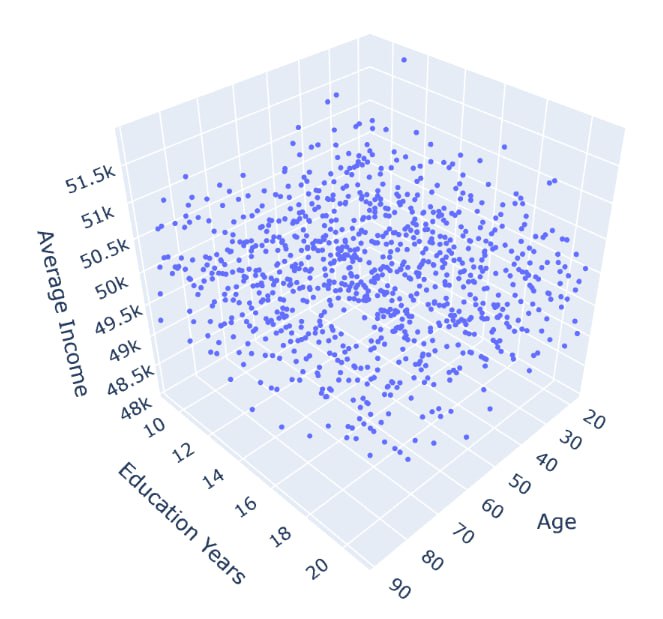
Рисунок 17 - 3D-график: возраст, образование, средний доход
7. Автоматизация отчетов и практическое применение методики
Jupyter Notebook поддерживает развитую систему экспорта результатов в различные форматы, что обеспечивает удобное и профессиональное представление данных для разных аудиторий. Инструмент nbconvert предоставляет широкие возможности преобразования файлов .ipynb в разнообразные выходные форматы, адаптированные под конкретные потребности и сценарии использования.
В академической и научной среде Jupyter Notebook зарекомендовал себя как незаменимый инструмент для подготовки воспроизводимых публикаций. Поддержка экспорта в форматы PDF и LaTeX позволяет исследователям создавать материалы, полностью соответствующие строгим требованиям рецензируемых научных журналов. Особую ценность представляет сохранение математических формул в нотации LaTeX, что обеспечивает корректное и профессиональное оформление сложных теоретических выкладок и математических моделей.
Для образовательных целей особенно востребован экспорт в HTML, который позволяет формировать интерактивные учебные материалы с сохранением визуализаций и возможностью демонстрации вычислительных процессов. При подготовке докладов и представлении результатов на научных конференциях формат Reveal.js открывает широкие возможности для создания динамичных веб-презентаций, объединяющих программный код, графические иллюстрации и пояснительный текст в едином интерактивном пространстве.
Для документирования аналитических моделей и методик особенно полезен экспорт в формат Markdown, который упрощает интеграцию с системами управления знаниями и обеспечивает возможность версионного контроля посредством платформ наподобие Git. В бизнес-среде востребован экспорт визуализаций в PNG и PDF форматы, что позволяет создавать высококачественные графики и диаграммы для отчетов и презентаций (рис. 18,19).
Рисунок 18 - Пример экспорта в формате png
Рисунок 19 - Пример экспорта в формате pdf
Для реализации задачи данные были преобразованы из исходного формата в Excel таблицу, а затем в CSV формат для последующей загрузки в Jupyter Notebook. Процесс обработки включал переименование столбцов для удобства работы, заполнение пропущенных значений и создание дополнительного параметра «сложность рекурсии» как суммы параметров m и n. Успешная загрузка данных подтвердила готовность к последующему анализу и визуализации.
Визуализация была реализована с использованием библиотеки Matplotlib, что позволило создать всеобъемлющий график, отображающий три ключевых параметра одновременно. По оси X отображался номер измерения, по оси Y — среднее время выполнения метода в наносекундах. Размер точек визуализировал объем выделенной памяти при конкретном вызове метода, вертикальные линии показывали стандартное отклонение, а цвет точек отражал суммарную «сложность рекурсии». Такое многомерное представление данных позволило наглядно продемонстрировать зависимость времени выполнения метода от числа рекурсивных вызовов и оценить влияние различных параметров на производительность и использование памяти.
8. Практическое применение: визуализация данных в Jupyter Notebook
Рисунок 20 - Данные в Excel в привычном виде
Листинг 14. Код для создания круговой диаграммы
1fig = go.Figure()
2
3fig.add_trace(go.Pie(values=sum_counts, labels=sum_counts.index, sort=False))
4
5fig.show()Этот фрагмент демонстрирует, насколько легко и удобно можно создавать и работать с круговыми диаграммами в Jupyter Notebook (рис. 21).
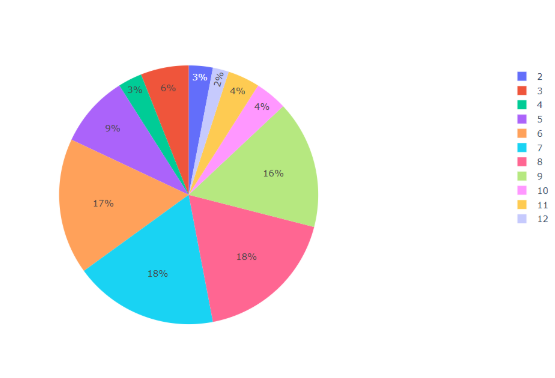
Рисунок 21 - Простая круговая диаграмма
Листинг 15. Код для создания круговой диаграммы с выделенным сектором
1fig = go.Figure()
2
3pull = [0]*len(sum_counts)
4pull[sum_counts.tolist().index(sum_counts.max())] = 0.2
5
6fig.add_trace(go.Pie(values=sum_counts, labels=sum_counts.index, pull=pull))
7
8fig.show()
Рисунок 22 - Круговая диаграмма с выделенным сектором
Листинг 16. Код для создания круговой диаграммы без центральной части
1fig = go.Figure()
2
3pull = [0]*len(sum_counts)
4pull[sum_counts.tolist().index(sum_counts.max())] = 0.2
5
6fig.add_trace(go.Pie(values=sum_counts, labels=sum_counts.index, pull=pull, hole=0.9))
7
8fig.show()
Рисунок 23 - Круговая диаграмма без центральной части
Листинг 17. Код для загрузки данных в Jupyter notebook
1import pandas as pd
2import matplotlib.pyplot as plt
3import seaborn as sns
4
5sns.set(style="whitegrid")
6
7# Загрузка CSV напрямую
8df = pd.read_csv(r'data2copy.csv')
9
10# Переименуем при необходимости
11rename_map = {
12 "RecCalls": "Recurse_calls",
13 "AllocMem_bytes": "Memory_allocated"
14}
15df.rename(columns=rename_map, inplace=True)
16
17# Заполняем пропуски
18df["Memory_allocated"] = df["Memory_allocated"].fillna(0)
19df["rec_complexity"] = df["m"] + df["n"]
20
21df.head()
Рисунок 24 - Положительный результат выполнения кода
Листинг 18. Код для создания основного графика
1plt.figure(figsize=(12, 8))
2scatter = plt.scatter(
3 df.index,
4 df["Mean_ns"],
5 s=df["Memory_allocated"] / 100,
6 c=df["rec_complexity"],
7 cmap="plasma",
8 alpha=0.7
9)
10for i in df.index:
11 plt.errorbar(
12 x=i,
13 y=df.loc[i, "Mean_ns"],
14 yerr=df.loc[i, "StdDev_ns"],
15 fmt='none',
16 ecolor='black',
17 capsize=3
18 )
19
20plt.colorbar(scatter, label='Число рекурсивных вызовов')
21plt.xlabel("Номер измерения")
22plt.ylabel("Среднее время (нс)")
23plt.title("Зависимость времени от числа рекурсивных вызовов, отклонение, память, рекурсия")
24plt.tight_layout()
25plt.show()В первом блоке создается точечная диаграмма с возможностью настраивать размер точек, их цвет, прозрачность. Второй блок добавляет вертикальные линии внутри точек (кругов). Завершающая часть кода реализует оформление, легенду графика, она включает в себя подписи осей и цветовое оформление. Функция plt.colorbar() создает цветную шкалу, которая визуально связывает градиентную палитру маркеров с соответствующими значениями сложности рекурсивных вычислений.
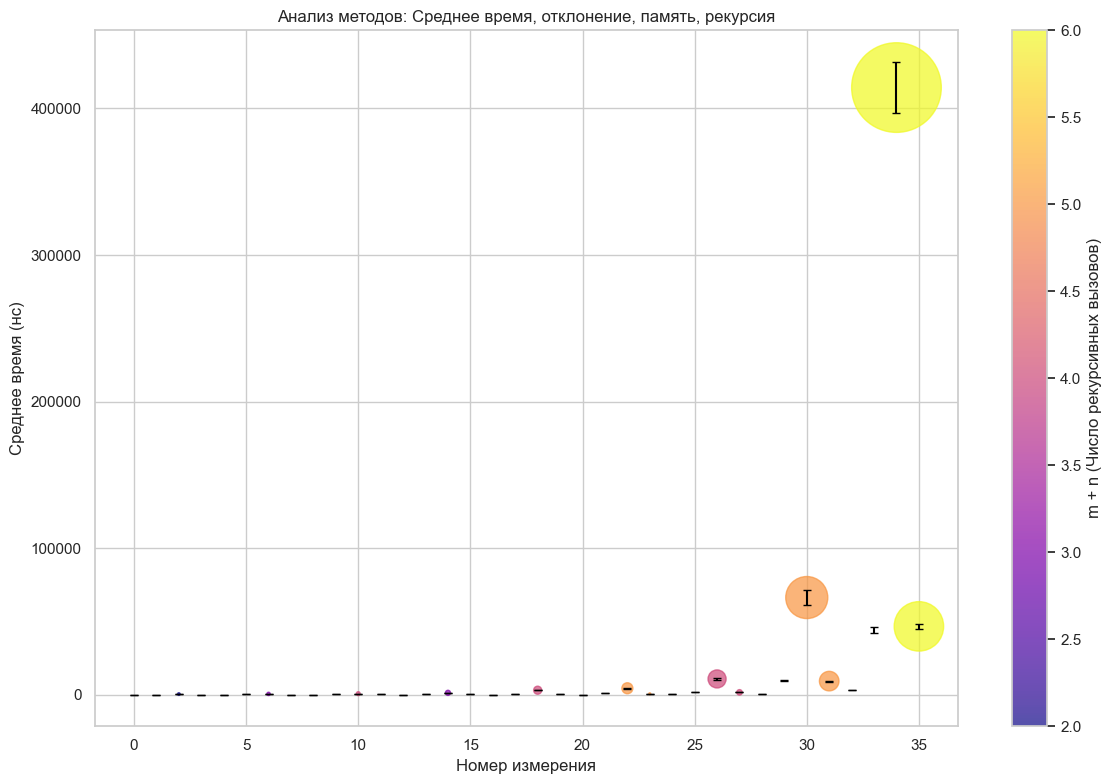
Рисунок 25 - Результат выполнения кода
1) среднее время выполнения (ось Y);
2) объем используемой памяти (размер точек);
3) сложность вычислений (цвет точек);
4) стандартное отклонение (вертикальные линии).
Такой подход демонстрирует преимущества Jupyter Notebook для работы со сложными многомерными данными по сравнению с традиционными инструментами.
9. Заключение
В результате проведенного исследования было показано, что Jupyter Notebook представляет собой универсальную и эффективную среду для визуализации статистических данных, позволяющую объединять вычислительные возможности Python с гибкими инструментами графического представления информации. Рассмотренные библиотеки Plotly и Matplotlib продемонстрировали высокую результативность как для статической научной графики, так и для создания интерактивных решений, что делает их совместное использование оптимальным для анализа данных различной сложности и объема. Особое внимание было уделено вопросам оптимизации работы с большими массивами, применению параллельных вычислений и интеграции с системами управления базами данных, что обеспечивает масштабируемость и надежность аналитических процессов.
Практическая значимость предложенного методологического подхода проявляется в его применимости для широкого спектра задач — от образовательных и исследовательских до бизнес-аналитики и индустриальных проектов. Экспорт визуализаций в разнообразные форматы, включая HTML, PDF, LaTeX и интерактивные презентации, открывает возможности для подготовки воспроизводимых публикаций, учебных материалов и профессиональных отчетов. Важным результатом является формирование принципов построения визуализаций, учитывающих когнитивные особенности восприятия и направленных на повышение точности интерпретации данных и качества принимаемых решений.
Перспективы дальнейшего развития работы связаны с расширением функционала Jupyter Notebook путем интеграции методов машинного обучения и искусственного интеллекта для автоматического выбора оптимальных способов визуализации в зависимости от структуры и характеристик данных. Представляется актуальным внедрение интеллектуальных рекомендательных систем, способных адаптировать цветовые схемы, масштабируемые графики и интерактивные элементы под конкретные задачи пользователя. Дополнительным направлением может стать развитие облачных решений и коллаборативных сервисов на основе Jupyter, что позволит организовать совместную работу исследователей и аналитиков в реальном времени. В долгосрочной перспективе внедрение описанного подхода способно повысить эффективность анализа данных, сделать визуализацию более доступной и интуитивно понятной, а также обеспечить новые возможности для научных исследований и прикладных разработок.