АЛГОРИТМ АВТОМАТИЧЕСКОЙ СЕРИАЛИЗАЦИИ СО СЖАТИЕМ

Кравцов А.А.1, Тропченко А.А.2, Крихели А.М.3
1Магистр, 2Кандидат технических наук, доцент, 3Магистр, Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики
АЛГОРИТМ АВТОМАТИЧЕСКОЙ СЕРИАЛИЗАЦИИ СО СЖАТИЕМ
Аннотация
При передаче и хранении данных основными проблемами являются объем данных и скорость их передачи. При подготовке данных к передаче или хранению выполняется их сериализация. Производительность процесса передачи зависит от характеристик выбранного алгоритма сериализации (скорость сериализации, возможность сжатия данных, потребляемая память). Целью работы является исследование существующих алгоритмов автоматической сериализации и поиск возможных путей их оптимизации для выполнения специфических задач.
Ключевые слова: автоматическая сериализация, сжатие данных, сжатие числовых последовательностейKravtsov A.A.1, Tropchenko A.A.2, Krikheli A.M.3
1Master, 2PhD in Engineering, associate professor, 3Master, Saint-Petersburg National Research University of Information Technologies, Mechanics and Optics
AUTOMATIC SERIALIZATION AND COMPRESSION ALGORITHM
Abstract
In transmission and storage of data among the main problems is the amount of information transmitted and its transmission speed. In the preparation of objects for the transmission and storage performed their serialization. The performance of transmission process depends on characteristics of serialization algorithm (serialization speed, data compression ability, memory consumption). The objective is to analyze the existing algorithms of automatic serialization and finding possible ways of their optimization for specific tasks.
Keywords: automatic serialization; data compression; numeric sequence compression.Сериализация – это процесс перевода объекта в последовательность байт, который применяется для сохранения их состояния [1, С. 710]. В частности, она широко используется в таких технологиях, как REST, RPC и им подобных. Например, вызове удаленной процедуры, объекты, переданные как ее параметры, сериализуются в поток байт и отправляются на сервер вместе с информацией о вызываемой процедуре. В современных фреймворках междоменного взаимодействия (таких как WCF), описанный процесс происходит автоматически. Также сериализованный объект может быть сохранен в файл и позже восстановлен, как это часто бывает при сохранении конфигурации. Целью исследования был поиск возможных путей улучшения существующих решений для автоматической сериализации.
Общая концепция процесса состоит в следующем. Бизнес-объект является некоторой сущностью, моделирующей реальный объект. В большинстве случаев он состоит из логических типов, поэтому сохранение состояния такого объекта не представляется возможным. Для выполнения этой задачи создается data transfer object (DTO). Это объект, формирующийся в результате обхода дерева логических типов, и состоящий из его листьев – примитивных типов. На следующем этапе записывается полученный набор примитивных типов, согласно выбранному алгоритму. В рефлексивных языках, где доступна метаинформация о типах данных, возможна автоматическая сериализация, которая полезна в случае значительной ширины и глубины дерева типов бизнес-объекта. Также автоматическая сериализация применяется в динамически-типизированных языках, где структура типа часто изменяется, либо вообще не определена во время компиляции.
Существует множество готовых решений для автоматической сериализации объектов. По сравнению с ручной сериализацией, готовые решения обладают рядом существенных недостатков, таких как большее время работы и низкий коэффициент сжатия данных (значительно меньше единицы). Эти недостатки вызваны накладными расходами на запись метаданных, необходимых для десериализации объекта. Необходимость в обходе дерева типов с помощью инструментов рефлексии также негативно сказывается на времени работы средств автоматической сериализации.
Рассмотрим подробнее формат объекта, сериализованного стандартными средствами .NET [2]. Заголовок содержит описание контракта. За ним следует структура данных и сами данные. Этой метаинформации достаточно, чтобы восстановить исходный объект. Но метаинформация имеет значительный объем, поэтому было принято решение записывать только данные, а структуру данных и контракт предоставлять непосредственно в момент чтения или записи. Контрактом в таком случае служит порядок обхода полей объекта, а структура описывается структурой сериализуемого типа. Для дальнейшего уменьшения объема объектов используется сжатие последовательностей однотипных объектов. Таким образом, разработанный алгоритм сериализации имеет следующую структуру (Рис. 1).
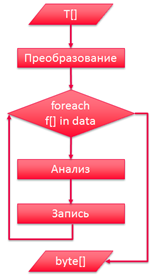
Рис. 1 - Сравнение результатов работы различных алгоритмов
На этапе преобразования происходит разбиение массива исходных объектов A[1..N] на несколько массивов примитивных типов P1[1..N]…Pm[1..N] (где N – количество элементов в исходном массиве, m – количество полей объекта), причем значения элементов массивов P1[x]…Pm[x] равны значениям соответствующих полей объекта A[x].
Далее происходит сжатие каждого массива примитивных типов. Рассмотрим его на примере массива сообщений автомобильного датчика уровня топлива.
Пусть имеется некоторый массив сообщений, каждое из которых состоит из уровня топлива (целое число, отражающее объем топлива в баке в миллилитрах) и временной метки (целое число). Для простоты будет рассматриваться сжатие только показаний объема топлива.
Исходные данные выглядят следующим образом (Рис. 2)
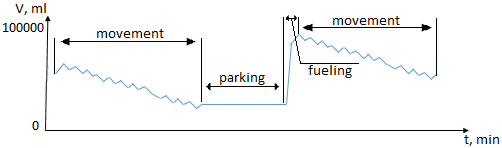
Рис. 2 - Временные периоды, когда машина находилась в движении, на стоянке и заправлялась и соответствующий уровень топлива
Анализ данных для сжатия проходит в три этапа.
На первом этапе весь массив разбивается на равные блоки [3, С. 6] (Рис. 3).
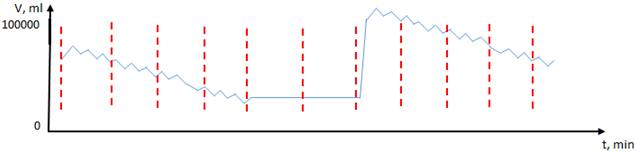
Рис. 3 - Разбиение на равные участки
На втором этапе (Рис. 4) для каждого блока выбирается лучшая стратегия сжатия, дающая на выходе наименьший объем информации. В текущей реализации выбор происходит между алфавитным кодированием, дифференциальным кодированием и записью без сжатия.
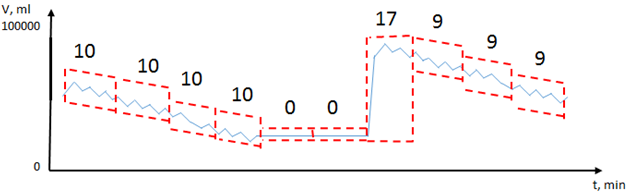
Рис. 4 - Блоки данных и минимальное количество информации, необходимое для записи одного сообщения в битах при кодировании по граничным значениям
На последнем этапе (Рис. 5) происходит слияние блоков, для которых выбрана одинаковая стратегия сжатия, а также одинаковое количество информации, что уменьшает количество заголовков. Если значения в блоке не изменялись, происходит кеширование заголовка. В этом случае записывается только заголовок с минимальным и максимальным значением (которые в данном случае равны), а данные блока не записываются. При чтении все данные блока будут равны минимальному значению из заголовка.
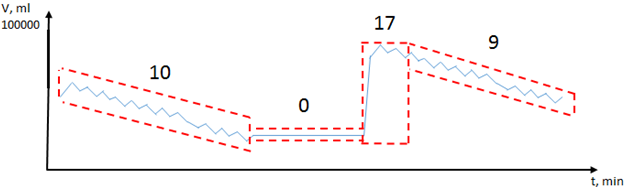
Рис. 5 - Макро-блоки, полученные слиянием нескольких исходных блоков
Полученные блоки данных имеют структуру, описанную на рис. 6.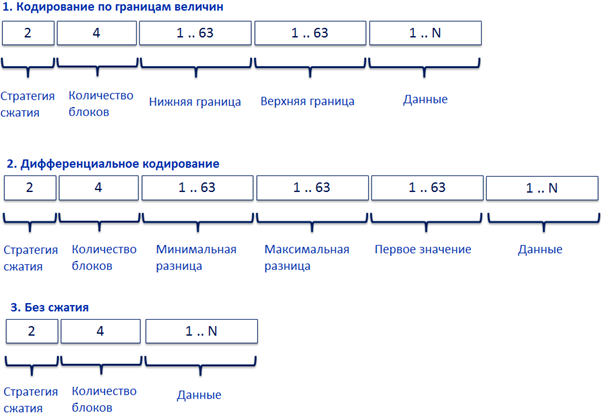
Рис. 6 – Структура заголовков блоков
Цифрами обозначено количество бит, которыми кодируется элемент заголовка. В заголовках присутствуют следующие поля:
- Стратегия сжатия. Присутствует во всех типах заголовков. Обозначает выбранную стратегию сжатия.
- Количество блоков. Присутствует во всех типах заголовков. Обозначает количество блоков с этим заголовком. При формировании на этапе анализа всегда равно единице, может измениться на этапе слияния заголовков
- Нижняя граница. Специфична для алфавитного кодирования. Обозначает минимальное значение в блоке.
- Верхняя граница. Специфична для алфавитного кодирования. Обозначает максимальное значение в блоке.
- Минимальная разница. Специфична для дифференциального кодирования. Обозначает минимальную разницу между соседними значениями.
- Максимальная разница. Специфична для дифференциального кодирования. Обозначает максимальную разницу между соседними значениями.
- Первое значение. Специфично для дифференциального кодирования. Первое значение в блоке.
- Данные. Присутствует во всех типах заголовков. Содержит исходные данные, к которым не применялось сжатие.
Запись проводится с помощью битовых операций. Каждый байт заполняется по принципу FIFO, после чего отправляется в поток. Чтение происходит в обратном порядке. Такая организация записи даёт максимальную компактность данных, так как отсутствует избыточная информация. После проведения замеров получились следующие значения.
Таблица 1 - Сравнение результатов работы различных алгоритмов
| Алгоритм | Данные | Коэффициент сжатия | Время работы, с |
| Автоматическая сериализация | Числовые | 0.31 | 1.342 |
| Изображение | 0.18 | 1.356 | |
| Текст | 0.43 | 1.298 | |
| Ручная сериализация | Числовые | 0.97 | 0.121 |
| Изображение | 0.99 | 0.143 | |
| Текст | 0.99 | 0.107 | |
| Сериализация со сжатием (разработанный алгоритм) | Числовые | 4.71 | 0.534 |
| Изображение | 1.64 | 0.542 | |
| Текст | 1.37 | 0.517 |
По полученным результатам можно сделать следующие выводы:
- В отличие от ручной сериализации, и автоматических решений, полученный алгоритм производит сжатие данных.
- Сжатие рассчитано на обработку числовых последовательностей, вследствие чего коэффициент сжатия числовых объектов получается больше, чем у универсальных алгоритмов сжатия.
- Благодаря отсутствия метаинформации в полученном массиве данных, сериализация происходит быстрее.
Ввиду некоторой специфичности алгоритма появляются следующие ограничения и недостатки:
- Так как описание структуры объекта не записывается вместе с данными, она должна быть известна при чтении и записи. Это накладывает ограничения на использование алгоритма в динамически-типизируемых языках.
- Способ записи FIFO обеспечивает максимальную плотность данных, но при этом теряется возможность доступа к N-ному элементу, пока не будут прочитаны предыдущие [4, С. 198-202].
- При сжатии таких данных, как изображения, текст и звук коэффициент сжатия получается ниже, чем у специализированных алгоритмов сжатия без потерь.
Список литературы / References
- Рихтер Дж. CLR via С#. Программирование на платформе Microsoft .NET Framework0 на языке С# / Рихтер Дж. – 3-е изд. — СПб.: Питер — 2012. — 928 с.
- Serialization (C# and Visual Basic). [Электронный ресурс] // Microsoft. URL: https://msdn.microsoft.com/ru-ru/library/msaspx (дата обращения 15.12.2011);
- Ватолин Д. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Ватолин Д., Ратушняк А., Смирнов М. и др. — М.; ДИАЛОГ-МИФИ — 2003. – 384 с.
- Вирт Н. Алгоритмы + структуры данных = программы / Вирт Н. — 7-е изд. — М.; Вильямс — 2001. – 410 c.
Список литературы на английском языке / References in English
- Richter J. CLR via C#. Programmirovanie na platforme Microsoft .NET Framework 4.0 na jazyke C# [CLR via C#. Programming in Microsoft .NET Framework 4.0 platform in C#] / Richter J. – 3rd edition. — SPb.: Piter. — — 928 p. [in Russian]
- Serialization (C# and Visual Basic). [Electronic resource] // Microsoft. URL: https://msdn.microsoft.com/ru-ru/library/ms233843.aspx (accessed 15.12.2011). [in Russian]
- Vatolin D. Metody szhatija dannyh. Ustrojstvo arhivatorov, szhatie izobrazhenij i video [Data compression methods. Implementation of archivers, image and video compression] / Vatolin D., Ratushnjak A., Smirnov M. and others. — M.; DIALOG-MIFI — 2003. – 384 p. [in Russian]
- Wirth N. Algoritmy + struktury dannyh = programmy [Algorithms + data structures = programs] / Wirth N. — 7th edition. — ; Viljams — 2001. – 410 p. [in Russian]